 Disruptor高性能隊列的原理
Disruptor高性能隊列的原理
來源:www.qin.news/disruptor/
介紹
Disruptor 是英國外匯交易公司 LMAX 開發的一個高性能隊列,研發的初衷是解決內存隊列的延遲問題(在性能測試中發現竟然與 I/O 操作處于同樣的數量級)。基于Disruptor 開發的系統單線程能支撐每秒 600 萬訂單,2010 年在 QCon 演講后,獲得了業界關注。2011 年,企業應用軟件專家 Martin Fowler 專門撰寫長文介紹。同年它還獲得了 Oracle 官方的 Duke 大獎。
這里所說的隊列是系統內部的內存隊列,而不是Kafka這樣的分布式隊列。
許多應用程序依靠隊列在處理階段之間交換數據。我們的性能測試表明,當以這種方式使用隊列時,其延遲成本與磁盤(基于RAID或SSD的磁盤系統)的IO操作成本處于同一數量級都很慢。如果在一個端到端的操作中有多個隊列,這將使整個延遲增加數百微秒。
測試表明,使用 Disruptor 的三階段流水線的平均延遲比基于隊列的同等方法低 3 個數量級。此外,在相同的配置下,Disruptor 處理的吞吐量約為 8 倍。
并發問題
在本文以及在一般的計算機科學理論中,并發不僅意味著兩個以上任務同時并行發生,而且意味著它們在訪問資源時相互競爭。爭用的資源可以是數據庫、文件、socket,甚至是內存中的一個位置。
代碼的并發執行涉及兩件事:互斥和內存可見性。互斥是關于如何管理保證某些資源的獨占式使用。內存可見性是關于控制內存更改何時對其他線程可見。如果你可以避免多線程競爭的去更新共享資源,那么就可以避免互斥。如果您的算法可以保證任何給定的資源只被一個線程修改,那么互斥是不必要的。讀寫操作要求所有更改對其他線程可見。但是,只有爭用的寫操作需要對更改進行互斥。
在任何并發環境中,最昂貴的操作是爭用寫訪問。要讓多個線程寫入同一資源,需要復雜而昂貴的協調。通常,這是通過采用某種鎖策略來實現的。
但是鎖的開銷是非常大的,在論文中設計了一個實驗:
這個測試程序調用了一個函數,該函數會對一個 64 位的計數器循環自增 5 億次。
機器環境:2.4G 6 核
運算:64 位的計數器累加 5 億次
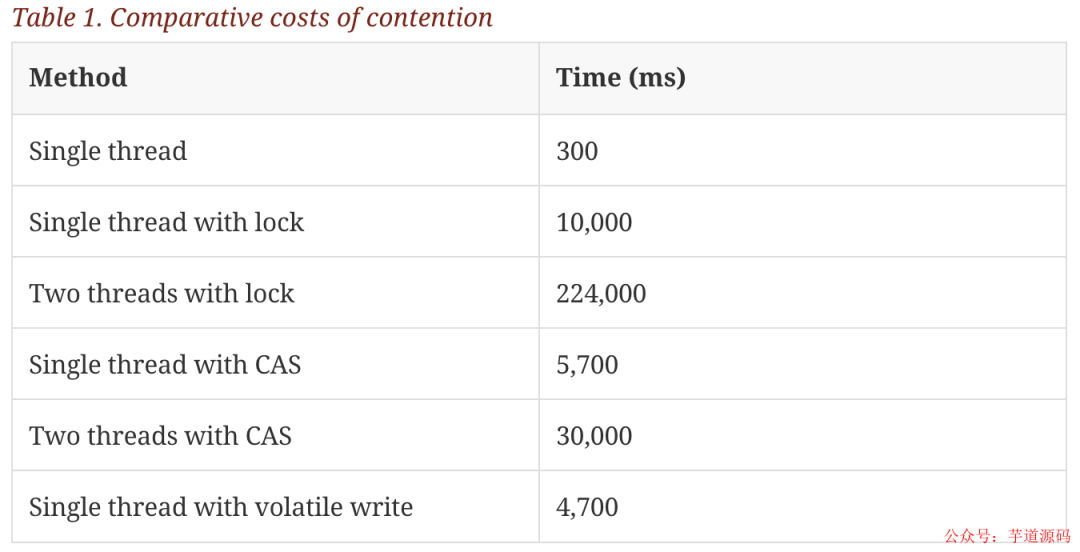
單線程情況下,不加鎖的性能 > CAS 操作的性能 > 加鎖的性能。
在多線程情況下,為了保證線程安全,必須使用 CAS 或鎖,這種情況下,CAS 的性能超過鎖的性能,前者大約是后者的 8 倍。
保證線程安全一般使用鎖或者原子變量。
采取加鎖的方式,默認線程會沖突,訪問數據時,先加上鎖再訪問,訪問之后再解鎖。通過鎖界定一個臨界區,同時只有一個線程進入。
原子變量能夠保證原子性的操作,意思是某個任務在執行過程中,要么全部成功,要么全部失敗回滾,恢復到執行之前的初態,不存在初態和成功之間的中間狀態。例如 CAS 操作,要么比較并交換成功,要么比較并交換失敗。由 CPU 保證原子性。
通過原子變量可以實現線程安全。執行某個任務的時候,先假定不會有沖突,若不發生沖突,則直接執行成功;當發生沖突的時候,則執行失敗,回滾再重新操作,直到不發生沖突。
CAS 操作是一種特殊的機器代碼指令,它允許將內存中的字有條件地設置為原子操作。比如對于前面的“遞增計數器實驗”例子,每個線程都可以在一個循環中自旋,讀取計數器,然后嘗試以原子方式將其設置為新的遞增值。
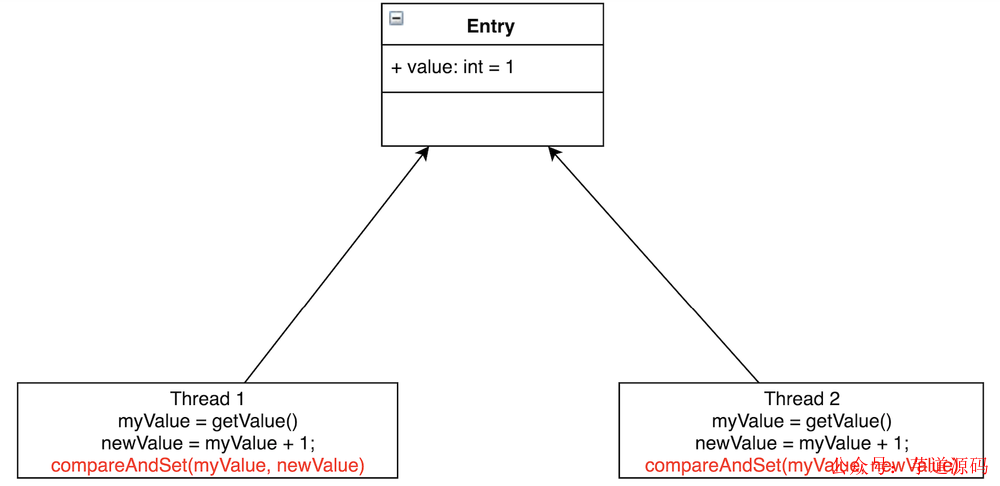
如圖所示,Thread1 和 Thread2 都要把 Entry 加 1。若不加鎖,也不使用 CAS,有可能 Thread1 取到了myValue=1,Thread2 也取到了 myValue=1,然后相加,Entry 中的 value 值為 2。這與預期不相符,我們預期的是 Entry 的值經過兩次相加后等于3。
CAS 會先把 Entry 現在的 value 跟線程當初讀出的值相比較,若相同,則賦值;若不相同,則賦值執行失敗。一般會通過 while/for 循環來重新執行,直到賦值成功。CAS無需線程進行上下文切換到內核態去執行,在用戶態執行了 CPU 的原語指令 cmpxchg,CAS 相當于在用戶態代碼里邊插入了一個 cmpxchg 指令,這樣 CPU 一直在用戶態執行,執行到 cmpxchg 指令就開始執行內核態內存空間的操作系統的代碼。執行指令要比上下文切換的開銷要小,所以 CAS 要比重量級互斥鎖性能要高。(用戶態和內核態沒有切換)
如果程序的關鍵部分比計數器的簡單增量更復雜,則可能需要使用多個CAS操作的復雜狀態機來編排爭用。使用鎖開發并發程序是困難的;而使用 CAS 操作和內存屏障開發無鎖算法要更加復雜多倍,而且難于測試和證明正確性。
內存屏障和緩存問題
出于提升性能的原因,現代處理器執行指令、以及內存和執行單元之間數據的加載和存儲都是不保證順序的。不管實際的執行順序如何,處理器只需保證與程序邏輯的順序產生相同的結果即可。這在單線程的程序中不是一個問題。但是,當線程共享狀態時,為了確保數據交換的成功與正確,在需要的時候、內存的改變能夠以正確的順序顯式是非常重要的。處理器使用內存屏障來指示內存更新順序很重要的代碼部分。它們是在線程之間實現硬件排序和更改可見性的方法。
內存屏障(英語:Memory barrier),也稱內存柵欄,內存柵障,屏障指令等,是一類同步屏障指令,它使得 CPU 或編譯器在對內存進行操作的時候, 嚴格按照一定的順序來執行, 也就是說在內存屏障之前的指令和之后的指令不會由于系統優化等原因而導致亂序。
大多數處理器提供了內存屏障指令:
完全內存屏障(full memory barrier)保障了早于屏障的內存讀寫操作的結果提交到內存之后,再執行晚于屏障的讀寫操作。
內存讀屏障(read memory barrier)僅確保了內存讀操作;
內存寫屏障(write memory barrier)僅保證了內存寫操作。
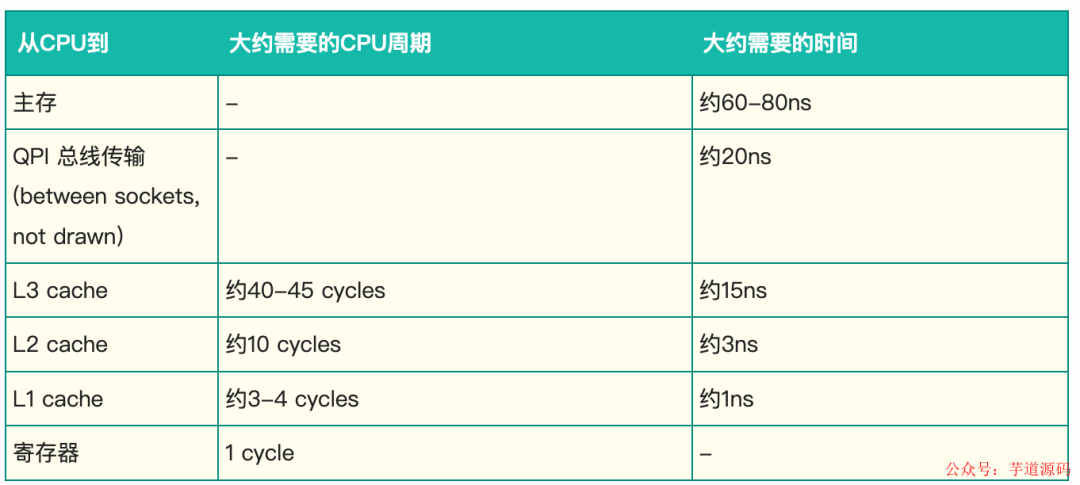
現代的 CPU 現在比當前一代的內存系統快得多。為了彌合這一鴻溝,CPU 使用復雜的高速緩存系統,這些系統是有效的快速硬件哈希表,無需鏈接。這些緩存通過消息傳遞協議與其他處理器緩存系統保持一致。此外,處理器還具有“存儲緩沖區”(store buffer/load buffer,比 L1 緩存更靠近 CPU,跟寄存器同一個級別,用來當作 CPU 與高速緩存之間的緩沖。畢竟高速緩存由于一致性的問題也會阻塞)來緩沖對這些緩存的寫入,以及作為“失效隊列”,以便緩存一致性協議能夠在即將發生寫入時快速確認失效消息,以提高效率。
這對數據意味著,任何值的最新版本在被寫入后的任何階段都可以位于寄存器、存儲緩沖區、L1/L2/L3 緩存之一或主內存中。如果線程要共享此值,則需要以有序的方式使其可見,這是通過協調緩存一致性消息的交換來實現的。這些信息的及時產生可以通過內存屏障來控制。
L1、L2、L3 分別表示一級緩存、二級緩存、三級緩存,越靠近 CPU 的緩存,速度越快,容量也越小。所以 L1 緩存很小但很快,并且緊靠著在使用它的 CPU 內核;L2 大一些,也慢一些,并且仍然只能被一個單獨的 CPU 核使用;L3 更大、更慢,并且被單個插槽上的所有 CPU 核共享;最后是主存,由全部插槽上的所有 CPU 核共享。
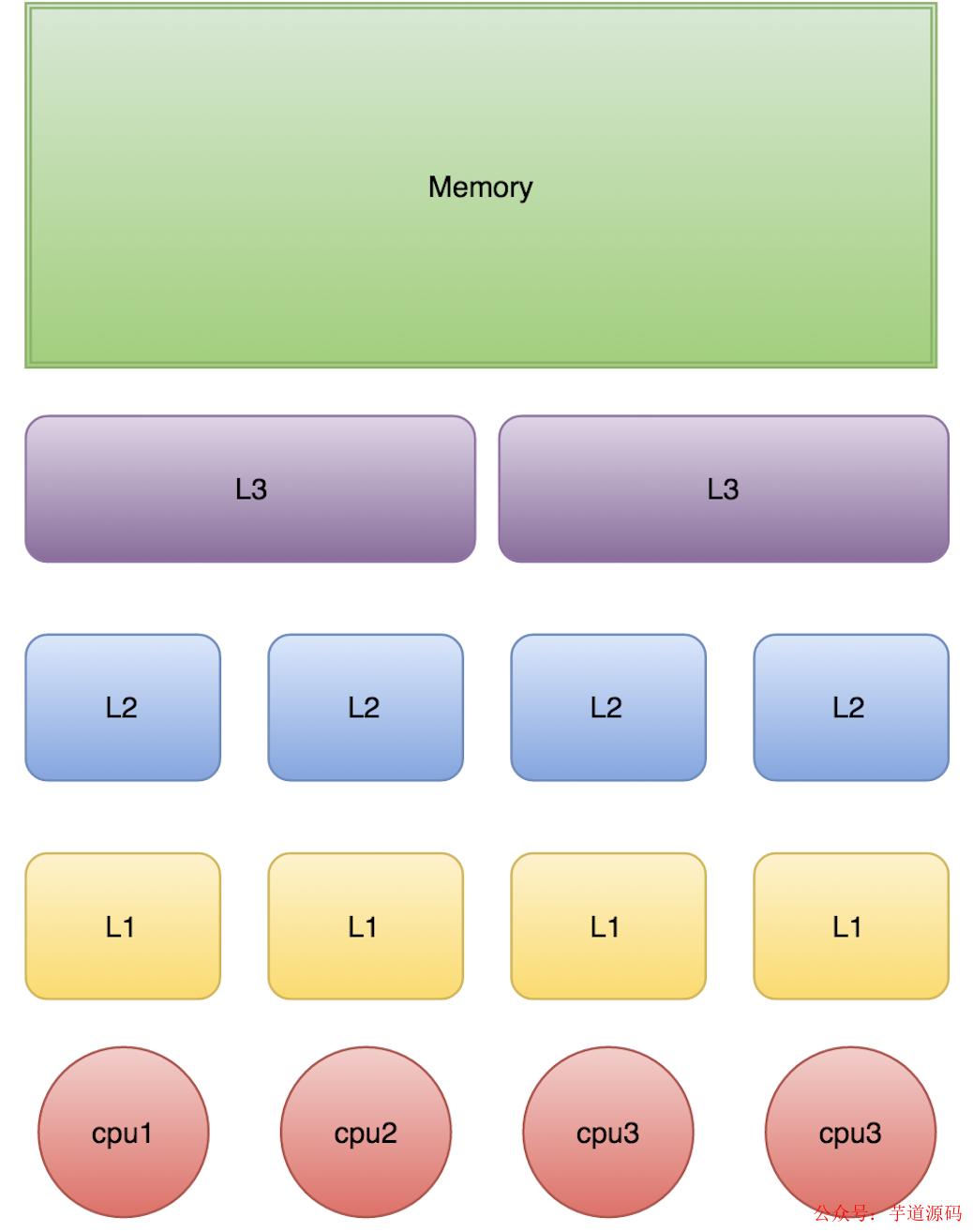
當 CPU 執行運算的時候,它先去 L1 查找所需的數據、再去 L2、然后是 L3,如果最后這些緩存中都沒有,所需的數據就要去主內存拿。走得越遠,運算耗費的時間就越長。所以如果你在做一些很頻繁的事,你要盡量確保數據在 L1 緩存中。
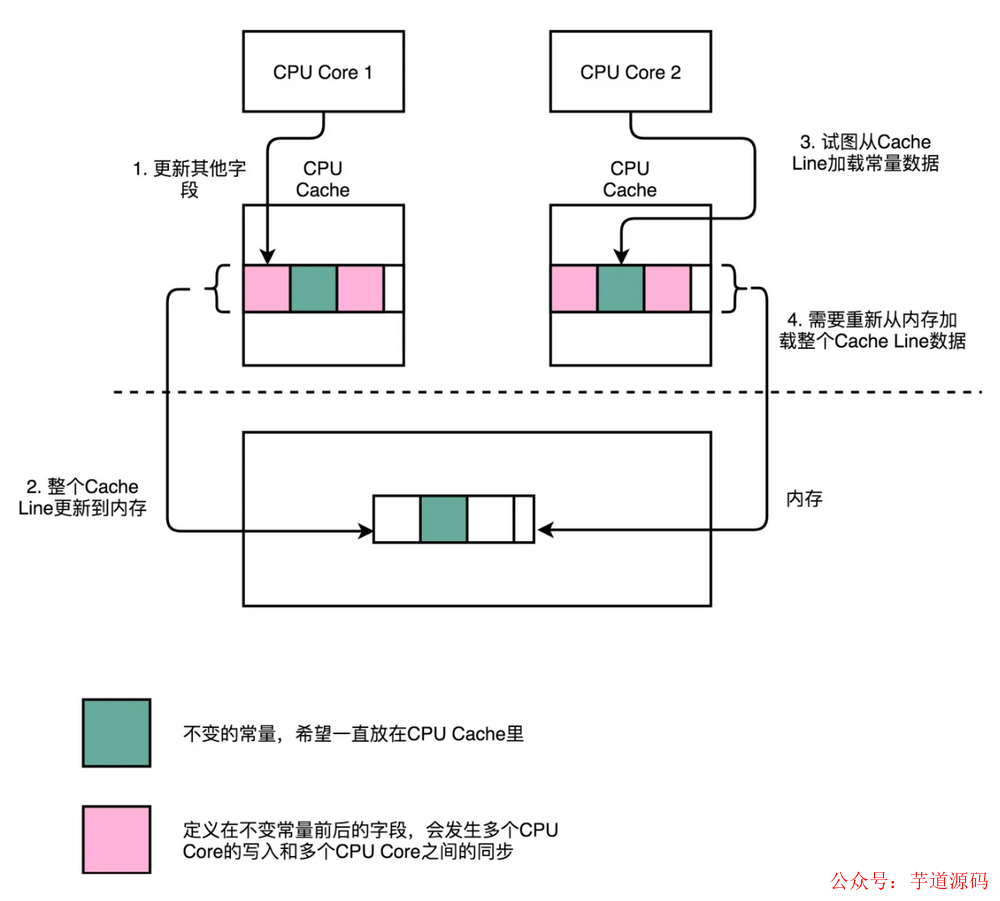
另外,線程之間共享一份數據的時候,需要一個線程把數據寫回內存,而另一個線程訪問內存中相應的數據。
如果你用一種能被預測的方式訪問內存的話,CPU 可以預測下個可能訪問的值從內存先緩存到緩存中,來降低下次訪問的延遲。但是如果是一些非順序的、步長無法預測的結構,讓 CPU 只能訪問內存,性能上與訪問緩存差很多。所以為了有效利用 CPU 高速緩存的特性,我們應當盡量使用順序存儲結構。
隊列的問題
隊列通常使用鏈表或數組作為元素的底層存儲。如果允許內存中的隊列是無界的,那么對于許多類的問題,它可以不受約束地增長,直到耗盡內存而達到災難性的后果,當生產者超過消費者時就會發生這種情況。無界隊列在可以在生產者可以保證不超過消費者的系統中使用,因為內存是一種寶貴的資源,但是如果這種假設不成立,而隊列增長沒有限制,那么總是有風險的。為了避免這種災難性的結果,隊列的大小通常要受到限制(有界)。要使隊列保持有界,就需要對其底層選擇數組結構或主動跟蹤其大小。
隊列的實現往往要在 head、tail 和 size 變量上有寫爭用。在使用時,由于消費者和生產者之間的速度差異,隊列通常總是接近于滿或接近于空。它們很少在生產和消費速率均衡的中間地帶運作。這種總是滿的或總是空的傾向會導致高級別的爭用、和/或昂貴的緩存一致性。問題在于,即使 head 和 tail 使用不同的并發對象(如鎖或CAS變量)來進行讀寫鎖分離,它們通常也占用相同的 cacheline。
管理生產者申請隊列的 head,消費者申請隊列的 tail,以及中間節點的存儲,這些問題使得并發實現的設計非常復雜,除了在隊列上使用一個粗粒度的鎖之外,還難以管理。對于 put 和 take 操作,使用整個隊列上的粗粒度鎖實現起來很簡單,但對吞吐量來說是一個很大的瓶頸。如果并發關注點在隊列的語義中被分離開來,那么對于除單個生產者-單個消費者之外的任何場景,實現都變得非常復雜。
而使用相同的 cacheline 會產生偽共享問題。比如 ArrayBlockingQueue 有三個成員變量:
takeIndex:需要被取走的元素下標;
putIndex:可被元素插入的位置的下標;
count:隊列中元素的數量;
這三個變量很容易放到一個緩存行中,但是之間修改沒有太多的關聯。所以每次修改,都會使之前緩存的數據失效,從而不能完全達到共享的效果。
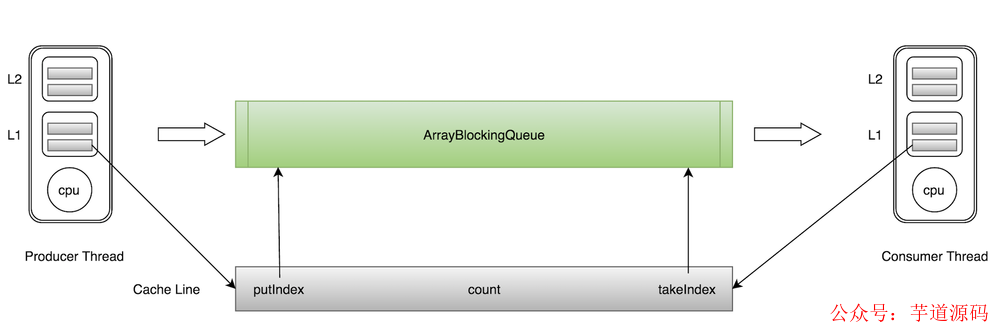
如上圖所示,當生產者線程 put 一個元素到 ArrayBlockingQueue 時,putIndex 會修改,從而導致消費者線程的緩存中的緩存行無效,需要從主存中重新讀取。一般的解決方案是,增大數組元素的間隔使得由不同線程存取的元素位于不同的緩存行上,以空間換時間。
Disruptor 解決思路
啟動時,將預先分配環形緩沖區的所有內存。環形緩沖區可以存儲指向 entry 的指針數組,也可以存儲表示 entry 的結構數組。這些 entry 中的每一個通常不是傳遞的數據本身,類似對象池機制,而是它的容器。這種 entry 的預分配消除了支持垃圾回收的語言中的問題,因為 entry 將被重用,并在整個 Disruptor 實例存活期間都有效。這些 entry 的內存是同時分配的。
一般的數據結構是像下面這樣的:
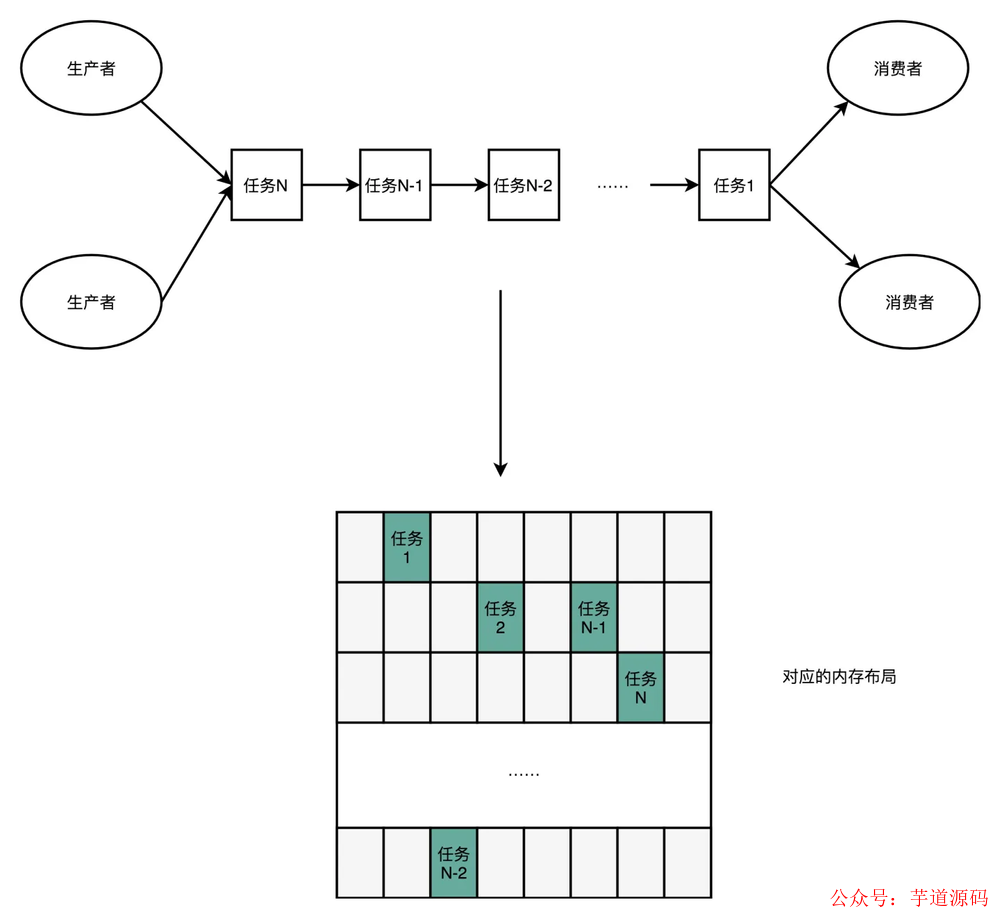
我們可以使用一個環狀的數組結構改進成下面這樣:
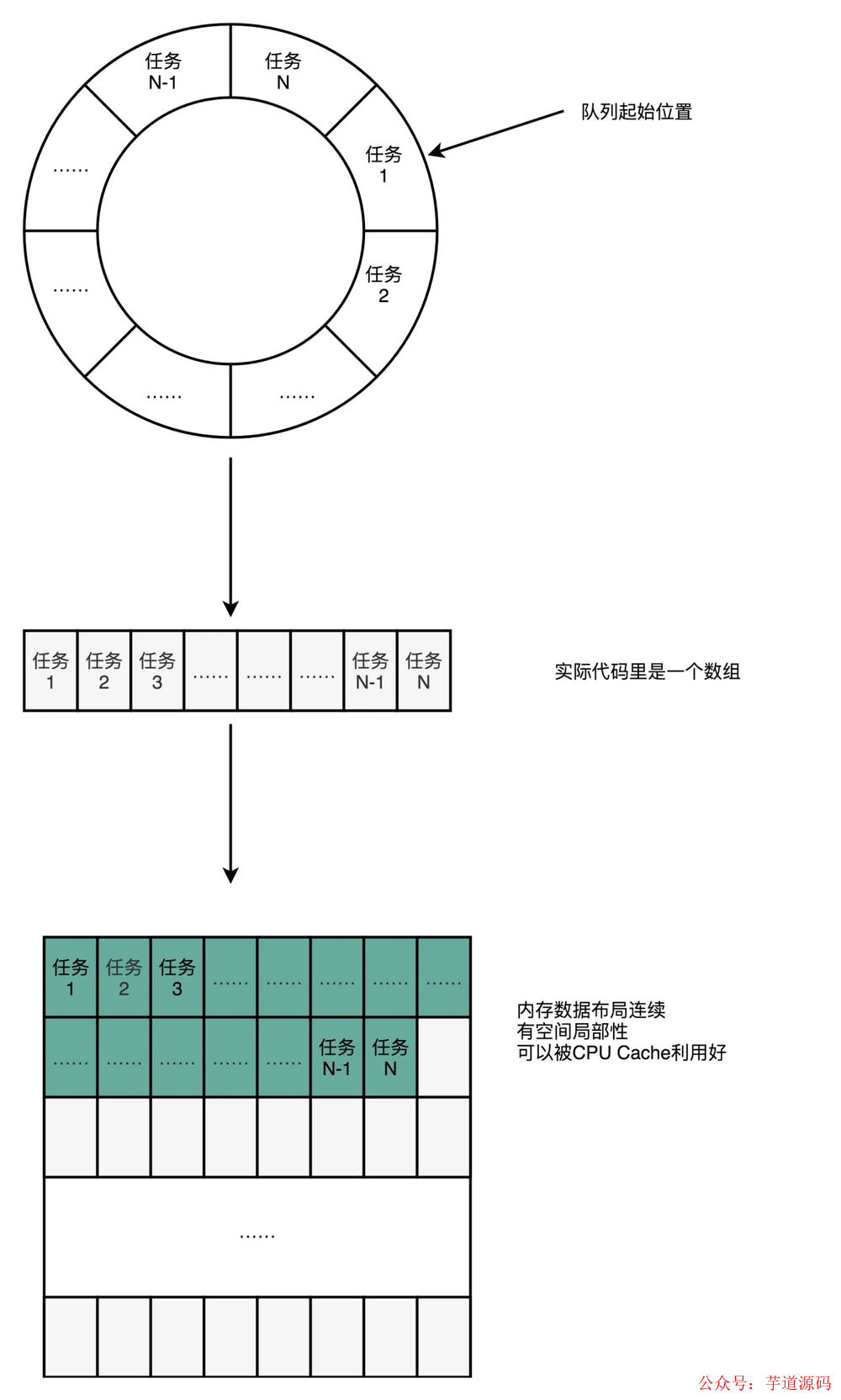
數組的連續多個元素會一并加載到 CPU Cache 里面來,所以訪問遍歷的速度會更快。而鏈表里面各個節點的數據,多半不會出現在相鄰的內存空間,自然也就享受不到整個 Cache Line 加載后數據連續從高速緩存里面被訪問到的優勢。遍歷訪問時 CPU 層面的分支預測會很準確。這可以使得我們更有效地利用了 CPU 里面的多級流水線,我們的程序就會跑得更快。
在像 Java 這樣的托管運行時環境中開發低延遲系統時,垃圾收集機制可能會帶來問題。分配的內存越多,給垃圾收集器帶來的負擔就越大。當對象的壽命很短或實際上是常駐的時候,垃圾收集器工作得最好。在環形緩沖區中預先分配 entry 意味著它對于垃圾收集器來說是常駐內存的,垃圾回收的負擔就很輕。同時,數組結構對處理器的緩存機制更加友好。數組長度 2^n,通過位運算,加快定位的速度。下標采取遞增的形式。不用擔心 index 溢出的問題。index 是 long 類型,即使 100 萬 QPS 的處理速度,也需要 30 萬年才能用完。
一般的 Cache Line 大小在 64 字節左右,然后 Disruptor 在非常重要的字段前后加了很多額外的無用字段。可以讓這一個字段占滿一整個緩存行,這樣就可以避免未共享導致的誤殺。
每個生產者或者消費者線程,會先申請可以操作的元素在數組中的位置,申請到之后,直接在該位置寫入或者讀取數據。
下面用非環形的結構模擬無鎖讀寫。
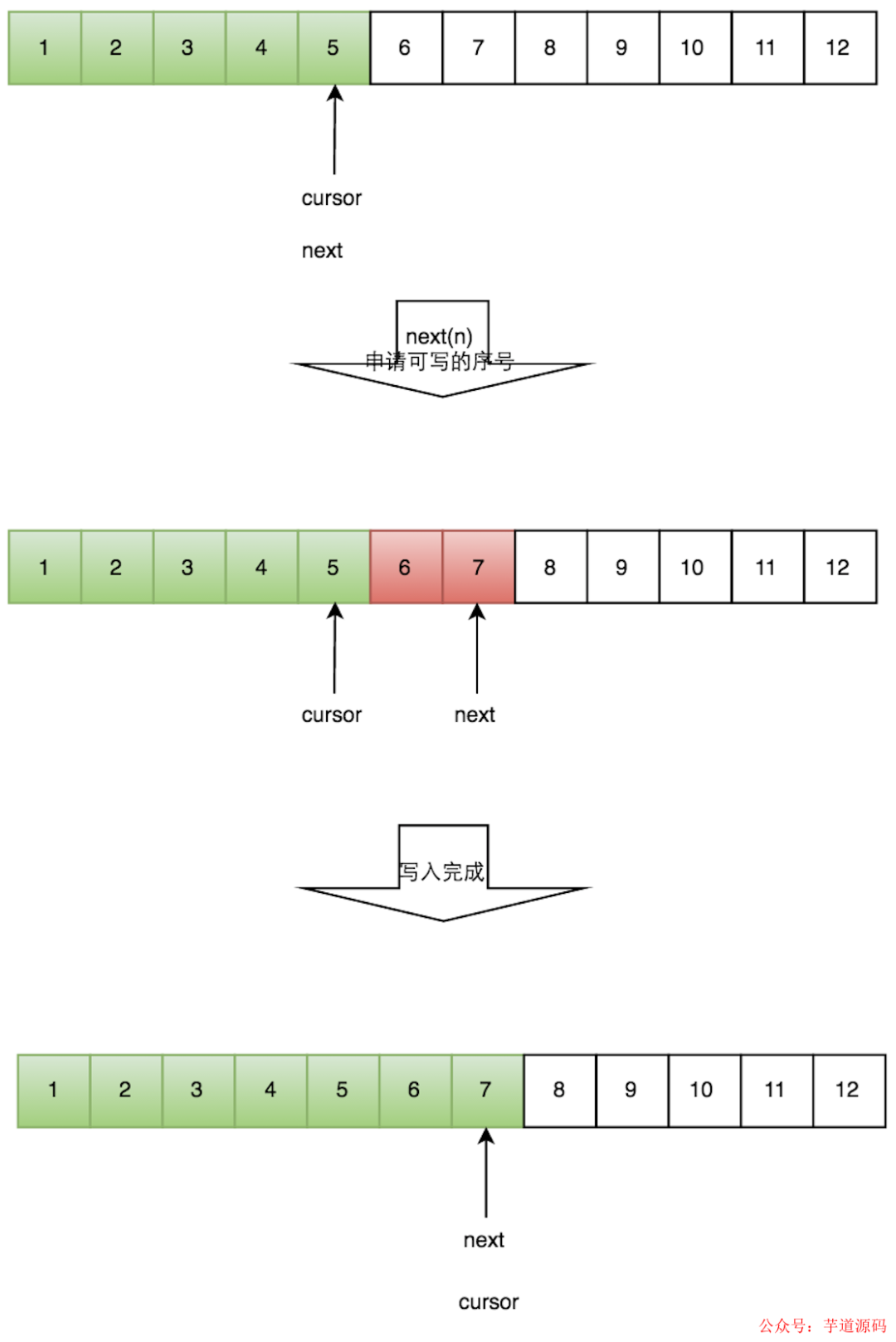
一個生產者的流程
申請寫入m個元素;
若是有m個元素可以入,則返回最大的序列號。這兒主要判斷是否會覆蓋未讀的元素;
若是返回的正確,則生產者開始寫入元素。
多個生產者流程
多個生產者的情況下,會遇到“如何防止多個線程重復寫同一個元素”的問題。Disruptor 的解決方法是,每個線程獲取不同的一段數組空間進行操作。這個通過 CAS 很容易達到。只需要在分配元素的時候,通過 CAS 判斷一下這段空間是否已經分配出去即可。
但如何防止讀取的時候,讀到還未寫的元素。Disruptor 在多個生產者的情況下,引入了一個與 Ring Buffer 大小相同的 buffer,Available Buffer。當某個位置寫入成功的時候,便把 Availble Buffer 相應的位置置位,標記為寫入成功。讀取的時候,會遍歷 Available Buffer,來判斷元素是否已經就緒。
讀數據流程
生產者多線程寫入的情況會復雜很多:
申請讀取到序號n;
若 writer cursor >= n,這時仍然無法確定連續可讀的最大下標。從 reader cursor 開始讀取 available Buffer,一直查到第一個不可用的元素,然后返回最大連續可讀元素的位置;
消費者讀取元素。
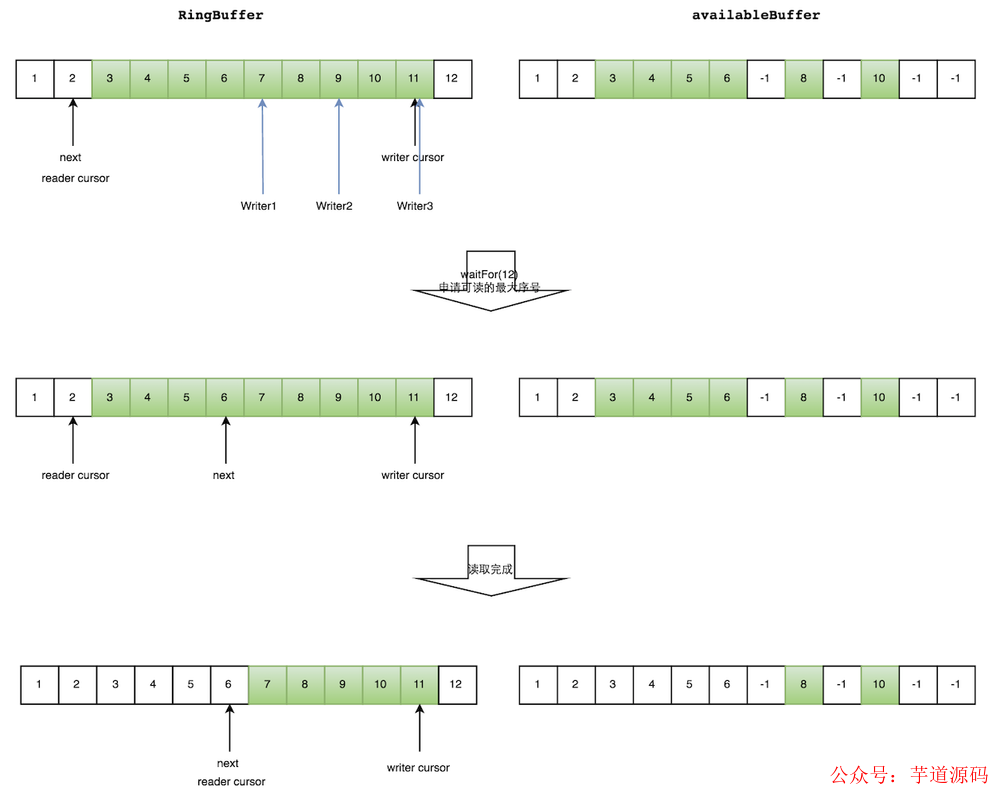
如下圖所示,讀線程讀到下標為 2 的元素,三個線程 Writer1/Writer2/Writer3 正在向 RingBuffer 相應位置寫數據,寫線程被分配到的最大元素下標是 11。
讀線程申請讀取到下標從3到11的元素,判斷 writer cursor>=11。然后開始讀取 availableBuffer,從 3 開始,往后讀取,發現下標為7的元素沒有生產成功,于是WaitFor(11)返回6。
然后,消費者讀取下標從 3 到 6 共計 4 個元素(多個生產者情況下,消費者消費過程示意圖)。
寫數據流程
多個生產者寫入的時候:
申請寫入 m 個元素;
若是有 m 個元素可以寫入,則返回最大的序列號。每個生產者會被分配一段獨享的空間;
生產者寫入元素,寫入元素的同時設置 available Buffer 里面相應的位置,以標記自己哪些位置是已經寫入成功的。
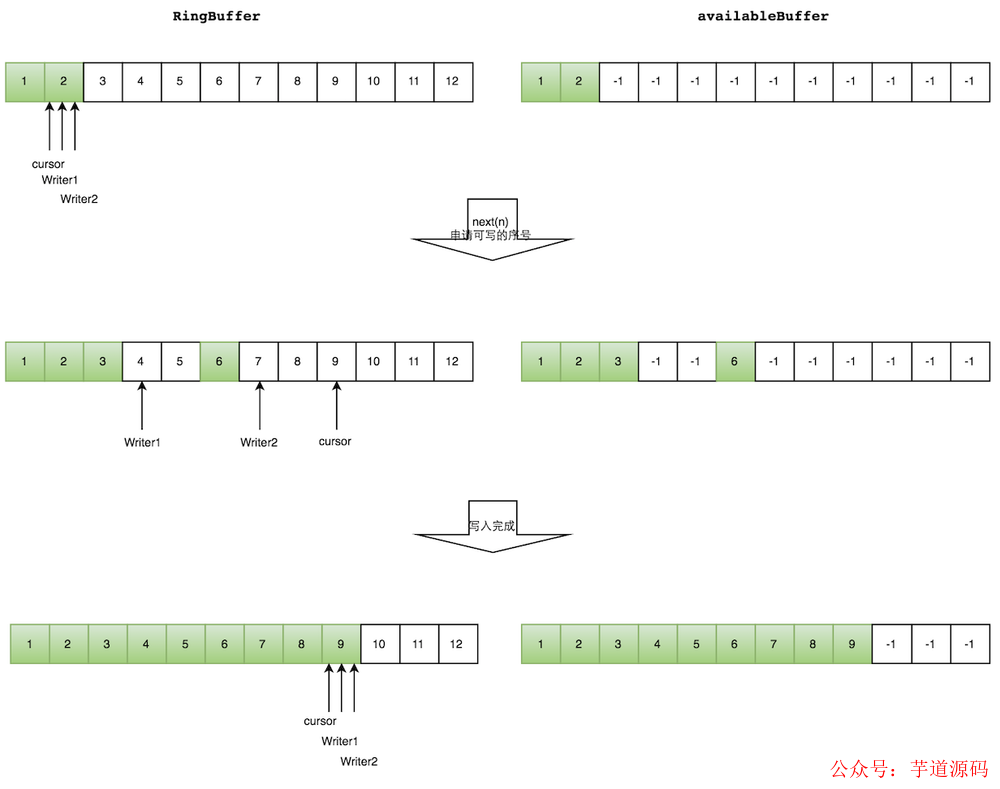
如下圖所示,Writer1 和 Writer2 兩個線程寫入數組,都申請可寫的數組空間。Writer1 被分配了下標 3 到下表 5 的空間,Writer2 被分配了下標 6 到下標 9 的空間。
Writer1 寫入下標 3 位置的元素,同時把 available Buffer 相應位置置位,標記已經寫入成功,往后移一位,開始寫下標 4 位置的元素。Writer2 同樣的方式。最終都寫入完成。
總結
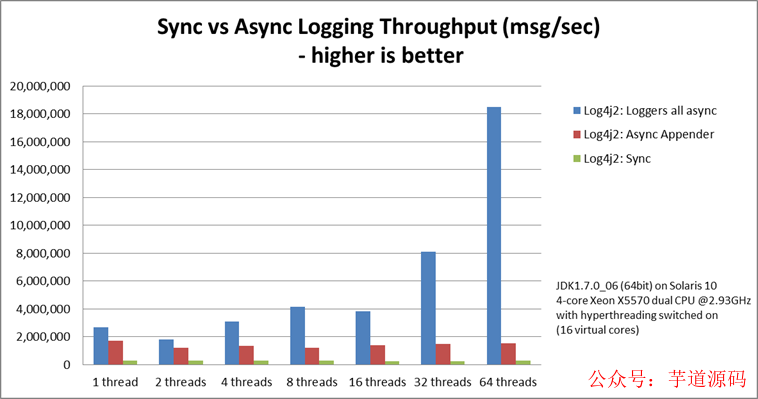
整體上來看 Disruptor 在提高吞吐量、減少并發執行損耗上做出了很大貢獻,通過貼合硬件機制的方式進行設計,消除寫爭用,最小化讀爭用,并確保代碼與現代處理器使用的 Cache 特性良好配合。我們可以看下 Log4j 2 的性能數據,Log4j 2 的 Loggers all async 就是基于 Disruptor 的。
總結來說 Disruptor 是性能極高的無鎖隊列,提供了一種很好的利用硬件特性實現盡可能從緩存讀取來加速訪問的無鎖方案。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19259瀏覽量
229653 -
計數器
+關注
關注
32文章
2256瀏覽量
94478 -
SSD
+關注
關注
21文章
2857瀏覽量
117370 -
RAID技術
+關注
關注
0文章
7瀏覽量
6226 -
CAS
+關注
關注
0文章
34瀏覽量
15201
原文標題:Disruptor 高性能隊列原理淺析
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦









可擴展的高性能RISC-V 內核IP
解密方舟的高性能內存回收技術——HPP GC
消息總線和消息隊列的區別是什么?






 工商網監
工商網監
評論