") 大模型訓(xùn)練中RM分?jǐn)?shù)越來越高,那訓(xùn)出來LLM的效果一定好嗎?
大模型訓(xùn)練中RM分?jǐn)?shù)越來越高,那訓(xùn)出來LLM的效果一定好嗎?
之前在文章大模型面試八股中提到一個(gè)問題,大模型訓(xùn)練中RM分?jǐn)?shù)越來越高,那訓(xùn)出來LLM的效果一定好嗎?
這么肯定的判斷肯定是有坑的,值得懷疑。
如果你動(dòng)手跑幾次ppo的過程就發(fā)現(xiàn)了,大模型的強(qiáng)化學(xué)習(xí)非常難以訓(xùn)練,難以訓(xùn)練不僅僅指的是費(fèi)卡,還是指的非常容易訓(xùn)崩。
第一,費(fèi)卡。假設(shè)你訓(xùn)llama 7b,SFT 和 RM 都用7B的模型,那么顯存耗費(fèi) = 2*7B(TRIAN MODE) + *7B(EVAL MODE), 分別對(duì)應(yīng) policy model / critic model,還有ref model/reward model
本來你能用幾張40GB A100的卡+deepspeed 做7b的全參數(shù)微調(diào),強(qiáng)化學(xué)習(xí)就得升級(jí)到80GB的A100了,勉勉強(qiáng)強(qiáng)能跑到7B。想跑更大的就得充錢了。
第二,容易崩。LLM訓(xùn)著訓(xùn)著就不聽你話了,要么變成停不下來的復(fù)讀機(jī),輸出到后面沒有邏輯直到maxlen,要么變成啞巴,直接一個(gè)eosid躺平。
RLHF中的問題其實(shí)在RL游戲訓(xùn)練里面很常見了,如果環(huán)境和參數(shù)設(shè)置不好的話,agent很容走極端,在 一頭撞死or循環(huán)鬼畜之間反復(fù)橫跳。
原始的ppo就是很難訓(xùn),對(duì)SFT基模型和RM的訓(xùn)練數(shù)據(jù)以及采樣prompt的數(shù)據(jù)要求很高,參數(shù)設(shè)置要求也很高。
自從openai帶了一波RLHF的節(jié)奏后,大家都覺得強(qiáng)化學(xué)習(xí)在對(duì)齊方面的無敵功力,但自己跑似乎又不是那么回事,這玩意也太有講究了吧。
更多的魔鬼在細(xì)節(jié)了,openai像拿了一個(gè)比賽的冠軍,告訴你了成功的solution,結(jié)果沒告訴你各個(gè)步驟的重要性和關(guān)鍵設(shè)置,更沒有告訴你失敗和無效的經(jīng)驗(yàn)。
在講trick之前,首先復(fù)旦-MOSS也對(duì)LLM的訓(xùn)練過程加了更多監(jiān)測(cè),其實(shí)這些都是實(shí)驗(yàn)中非常重要的監(jiān)控過程指標(biāo),能很清楚的發(fā)現(xiàn)你模型是否出現(xiàn)異常。
然后這個(gè)圖很好,非常清楚地講述了trick是如何作用在RLHF中的各個(gè)階段的,另外配套的開源代碼實(shí)現(xiàn)也非常清晰易懂,典型的面條代碼沒有什么封裝,一碼到底,易讀性和魔改都很方便。
下面我們看看這7個(gè)trick,對(duì)應(yīng)圖中右側(cè)畫星號(hào)的部分。
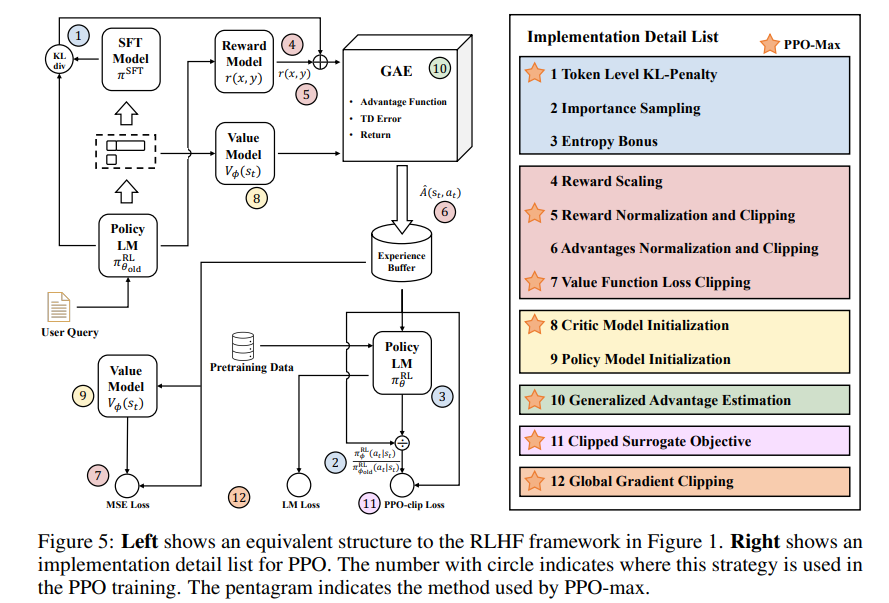
1, token級(jí)別的KL散度懲罰
kl_penalty = (-self.kl_penalty_weight * (logprobs - ref_logprobs)).cpu()
這一步主要解決的問題是訓(xùn)練穩(wěn)定性,防止步子太大扯著蛋,如果你輸出的和參考模型差別過大的話就減分。
2,Reward Normalization and Clipping
3,Value Function Loss Clipping
Clipping類似梯度裁剪,也是止步子太大扯著蛋,對(duì)一些異常的loss和reward做了限制,Normalization為了對(duì)reward做標(biāo)準(zhǔn)化。
這部分的代碼可以對(duì)應(yīng)開源中的這些設(shè)置仔細(xì)查看,原理大同小異
self.use_reward_clip: bool = opt.use_reward_clip self.use_reward_norm:bool=opt.use_reward_norm self.use_advantage_norm:bool=opt.use_advantage_norm self.use_advantage_clip: bool = opt.use_advantage_clip self.use_critic_loss_clip:bool=opt.use_critic_loss_clip self.use_policy_loss_clip:bool=opt.use_policy_loss_clip
4.Critic Model Initialization
用RM model初始化Critic可能不是一個(gè)必要的選擇,作者做了一些實(shí)驗(yàn)證明這個(gè)問題,推薦使用critic model pre-training。代碼里這部分還沒有,還是使用rm初始化的,后續(xù)跟進(jìn)一下這個(gè)問題。
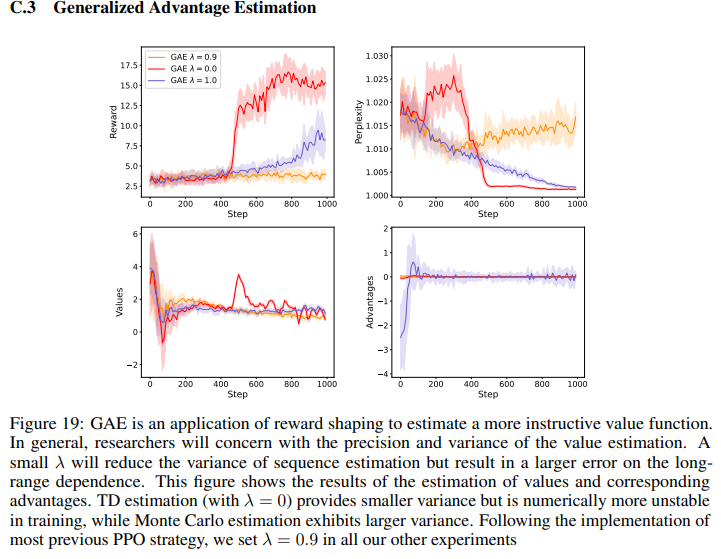
5. Generalized Advantage Estimation
附錄里C.3有GAE的調(diào)參實(shí)驗(yàn)。
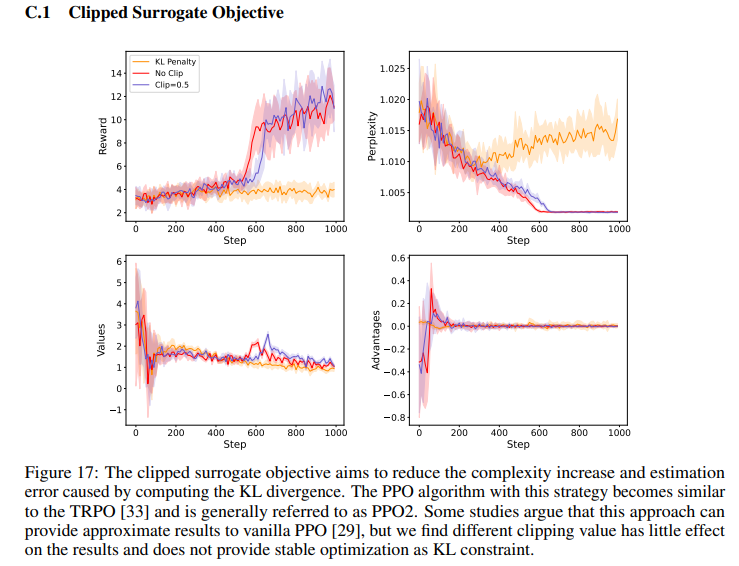
6.Clipped Surrogate Objective
這個(gè)也是一種正則化方法,防止步子太大扯著蛋,確保訓(xùn)練過程的中的穩(wěn)定性,這個(gè)方法比一般policy gradient處理的更為高效。
7.Global Gradient Clipping

原理還是同上,所有的Clipping無非都是砍掉太大的步子。
另外作者還用了一個(gè)instruct gpt里面用到的方案,增加了訓(xùn)練過程使用 llm_pretrain_loss,參考代碼
if self.use_entropy_loss:
loss1 = pg_loss + self.vf_loss_weight * vf_loss + self.entropy_loss_weight * entro_loss
else:
loss1 = pg_loss + self.vf_loss_weight * vf_loss
loss2 = self.ppo_pretrain_loss_weight * pretrain_loss
loss = loss1 + loss2
總結(jié)下,整體ppo-max的改進(jìn)主要集中在訓(xùn)練過程的穩(wěn)定性上,用的東西還是模型的老三樣,訓(xùn)練過程裁剪,初始化,loss改進(jìn),主要集中在如何能讓RLHF更好調(diào),推薦參考作者的源碼進(jìn)行一些實(shí)驗(yàn)。
另外,作者在論文里留了一個(gè)彩蛋,技術(shù)報(bào)告的第二部分預(yù)告主要是講Reward Model的成功和踩坑經(jīng)驗(yàn),目前還沒有發(fā)布,靜待作者更新。之前大家一直的爭(zhēng)論點(diǎn)用什么scale的RM,說要用遠(yuǎn)遠(yuǎn)大于SFT model的RM model,這到底是不是一個(gè)關(guān)鍵的問題,是不是deberta 和 65B都行,期待作者第二個(gè)技術(shù)報(bào)告里給一個(gè)實(shí)驗(yàn)~
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19259瀏覽量
229653 -
SFT
+關(guān)注
關(guān)注
0文章
9瀏覽量
6815 -
GAE
+關(guān)注
關(guān)注
0文章
5瀏覽量
6767
原文標(biāo)題:大模型RLHF的trick
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
ADAS比重越來越高 汽車電子或成半導(dǎo)體增長(zhǎng)重要?jiǎng)幽?/a>
研發(fā)投入越來越高 什么樣的工具才能保障變現(xiàn)?
LED展望:光效越來越高 價(jià)格越來越低
未來芯片的發(fā)展對(duì)FPGA的要求將會(huì)越來越高
新能源汽車在市場(chǎng)的普及度越來越高
動(dòng)力電池企業(yè)對(duì)工業(yè)相機(jī)的要求越來越高
中國芯呼聲越來越高,國內(nèi)EDA龍頭華大九天新突破
越來越高的帶寬需求要怎樣的通信衛(wèi)星來配合
基于一個(gè)完整的 LLM 訓(xùn)練流程

為何開關(guān)頻率要大于30kHz,且有越來越高的趨勢(shì)?
llm模型有哪些格式
llm模型訓(xùn)練一般用什么系統(tǒng)
如何訓(xùn)練自己的LLM模型
什么是大模型、大模型是怎么訓(xùn)練出來的及大模型作用

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論