 【AI簡報20230728期】醫療領域中的AI大模型,詳解C++從零實現神經網絡
【AI簡報20230728期】醫療領域中的AI大模型,詳解C++從零實現神經網絡
1. 生成式AI如何在智能家居中落地?
原文:https://mp.weixin.qq.com/s/hW7z0GFYe3SMKRiBizSb0A
作為一種通過各種機器學習方法從數據中學習對象的組件,進而生成全新的、完全原創的內容(如文字、圖片、視頻)的AI。生成式AI近年來發展非常迅速,它可以實現新的應用和用途,創造新內容的能力為新的應用開辟了許多可能性,尤其在智能家居中,生成式AI更是大有可為。
通過生成式AI,智能家居可以學習家庭成員的行為模式,了解他們的喜好和需求,并根據這些信息來自主地控制家庭設備和環境,讓智能家居更好地為用戶服務。例如,生成式AI可以用于智能音箱、家庭陪護機器人等為代表的智能家居產品。
生成式AI如何賦能智能家居
盡管從2022年底的ChatGPT爆火以后,人們對于生成式AI已經不陌生,但大多數應用依然聚焦在文字應用或圖片創作上,想要將這種AI進行實際應用,業內還在探索中。為此,電子發燒友網采訪到了思必馳IoT產品總監任毫亮,探討如何讓生成式AI賦能智能家居。
生成式AI必然會對智能家居行業帶來不小的影響,任毫亮表示,思必馳正在從多方面設計和思考它在行業內的應用,目前主要集中在兩個方面。
一個是智能語音交互,生成式AI能夠更加智能地理解和回應用戶的語音指令,以更加智能和自然的方式與智能家居進行交互,實現更高效、便捷的控制和操作,在語音交互上會有顯著的提升。
另一個則是針對方案設計、產品設計,生成式AI能夠為用戶提供完整科學的智能家居方案,依據不同場景、不同設備以及用戶個性化偏好進行方案和產品設計,提升家居設計師的工作效率,精準匹配用戶需求,為用戶提供更加智能、便捷、安全和個性化的智能家居體驗。
7月12日,思必馳推出了自研對話式大模型DFM-2(Dialogue Foundation Model),中文直譯為“通用對話基礎模型”。未來將圍繞“云+芯”戰略,以對話式AI為核心,將DFM-2大模型技術與綜合全鏈路技術進行結合,不斷提升AI軟硬件產品的標準化能力和DUI平臺的規模化定制能力,快速滿足智能汽車、智能家居、消費電子,以及金融、軌交、政務等數字政企行業場景客戶的復雜個性化需求,打造行業語言大模型,賦能產業升級。
為進一步滿足市場的個性化需求,思必馳將DUI平臺與DFM-2大模型相結合,推出DUI 2.0,完成對話式AI全鏈路技術的升級,推進深度產業應用,未來也將繼續深入到智能家居等應用場景,解決行業問題。
解決智能家居智能化與個性化難題
想要將生成式AI徹底融入進智能家居體系當中,廠商們也做了許多思考。任毫亮認為,生成式AI主要可以解決智能家居中智能化與個性化難題。
在智能交互上,生成式AI能夠更加智能地理解用戶的內容,同時結合用戶的設備、場景、習慣等內容綜合分析判斷,給出更準確和個性化的回復;用戶可以輸入更長的文本、更個性化的內容,針對不同用戶、不同時間、不同內容,生成式AI會給出不同的回答、不同的音色;同時AI具有更強的學習能力,在使用中會感受到越來越懂你的AI管家。
任毫亮表示生成式AI會是更加智能更加專屬的AI管家;思必馳的DFM-2也給DUI帶來了2.0的升級,基于深度認知的泛化語義理解、外部資源增強的推理問答、基于文檔的知識問答、個性化的多人設交互、模糊語義自學習,會將以上特性應用在智能家居、智能家電、智能車載等解決方案中。
在智能識別場景中,生成式AI通過學習和分析大量數據,并根據識別結果進行自動化調節和控制,提供更加個性化和智能化的服務。同時,生成式AI還可以幫助智能家居系統進行能源消耗的優化管理,通過對居住者行為的學習和分析,系統可以自動調整能源使用模式,減少不必要的能源浪費,實現智能節能管理。
而在這些場景中,都是依靠AI的學習能力、理解能力以及越來越多傳感器數據的輸入與分析,來實現自動化的設備控制和場景控制,同時基于用戶的反饋機制,不斷提升主動智能的體驗,達到真正的全屋智能化。
小結
隨著未來Matter等通用協議將智能家居體系完全打通,生成式AI將為智能家居的體驗帶來飛躍式提升,包括在智能語音交互、智能化、個性化等方面。隨著AI技術的進一步增強,生成式AI也將成為智能家居未來重要的一環。
2. 高通:未來幾個月有望在終端側運行超100億參數的模型
原文:https://mp.weixin.qq.com/s/63Pm51oisGr03fl2bSoJ0w
日前,在2023世界半導體大會暨南京國際半導體博覽會上,高通全球副總裁孫剛發表演講時談到,目前高通能夠支持參數超過10億的模型在終端上運行,未來幾個月內超過100億參數的模型將有望在終端側運行。
大模型在終端側運行的重要性
生成式AI正在快速發展,數據顯示,2020年至2022年,生成式AI相關的投資增長425%,初步預估生成式AI市場規模將達到1萬億美元。
然而孫剛指出,云經濟難以支持生成式AI規模化拓展,為實現規模化拓展,AI處理的中心正在向邊緣轉移。比如XR、汽車、手機、PC、物聯網,生成式AI將影響各類終端上的應用。
高通在這方面展示出了領先的優勢,高通AI引擎由多個硬件和軟件組件組成,用于在驍龍移動平臺上為終端側AI推理加速。它采用異構計算架構,包括高通Hexagon處理器、Adreno GPU、Kryo CPU和傳感器中樞,共同支持在終端上運行AI應用程序。
在7月初的2023年世界人工智能大會上,高通就已經展示了全球首個在終端側運行生成式AI(AIGC)模型Stable Diffusion的技術演示,和全球最快的終端側語言-視覺模型(LVM)ControlNet運行演示。這兩款模型的參數量已經達到10億-15億,僅在十幾秒內就能夠完成一系列推理,根據輸入的文字或圖片生成全新的AI圖像。
今年7月18日,Meta官宣將發布其開源大模型LLaMA的商用版本,為初創企業和其他企業提供了一個強大的免費選擇,以取代OpenAI和谷歌出售的昂貴的專有模型。隨后,高通發布公告稱,從2024年起,Llama 2將能在旗艦智能手機和PC上運行。
高通技術公司高級副總裁兼邊緣云計算解決方案業務總經理Durga Malladi表示,為了有效地將生成式人工智能推廣到主流市場,人工智能將需要同時在云端和邊緣終端(如智能手機、筆記本電腦、汽車和物聯網終端)上運行。
在高通看來,和基于云端的大語言模型相比,在智能手機等設備上運行Llama 2 等大型語言模型的邊緣云計算具有許多優勢,不僅成本更低、性能更好,還可以在斷網的情況下工作,而且可以提供更個性化、更安全的AI服務。
如何讓大模型在終端規模化擴展
生成式AI進入未來生活的趨勢已經不可阻擋,為了讓生成式AI規模化擴展到更多終端設備中,高通提出了混合AI架構的運行方式,即在云端和設備終端的邊緣側之間分配算力,協同處理AI工作負載。
所謂混合AI,是指充分利用邊緣側終端算力支持生成式AI應用的方式,相比僅在云端運行的AI,前者能夠帶來高性能、個性化且更安全的體驗。
比如,如果模型、提示或生成內容的長度小于某個限定值,且精度足夠,推理就可以完全在終端側進行;如果任務相對復雜,則可以部分依靠云端模型;如果需要更多實時內容,模型也可以接入互聯網獲取信息。
在未來,不同的生成式AI用不同分流方式的混合AI架構,AI也能在此基礎上持續演進:?大量生成式AI的應用,比如圖像生成或文本創作,需求AI能夠進行實時響應。在這種任務上,終端可通過運行不太復雜的推理完成大部分任務。
在AI計算的實現上,軟件和硬件同樣重要,因為必須在端側做到運算更快,效率更高,并推動AI應用在廣泛終端上的部署和普及。
高通在2022年6月推出AI軟件棧(Qualcomm AI Stack),其支持包括TensorFlow、Pytorch和ONNX在內的所有主流開發框架,所有runtimes(運行時,即某門編程語言的運行環境)和操作系統。借助高通AI軟件棧,開發者在智能手機領域開發的軟件可以快速擴展至汽車、XR、可穿戴設備等其他產品線進行使用。
高通技術公司產品管理高級副總裁兼AI負責人Ziad Asghar表示,未來公司需要加大終端側技術上的研發,尤其是進一步提升量化的算法。例如服務器上訓練的模型一般采用32位浮點運算(FP32),而我們在手機端現在能夠支持INT4計算,這能大大提高端側的處理能力。
小結
不僅僅是大模型的訓練需要極大的算力和功耗,部署也同樣如此。如果要讓大模型在更多的領域實現落地應用,除了在云端部署之后,在終端側部署也很關鍵。目前已經有諸多廠商在該領域進行探索,包括高通,期待未來大模型能夠走進人們生活的方方面面。
3. AI大模型在醫療領域起飛
原文:https://mp.weixin.qq.com/s/yNRpRIVntYv2cmU9GOCLzg
ChatGPT等大型語言模型在語言理解、生成、知識推理等方面正展現出令人驚艷的能力。近段時間,各企業開始探索大模型在不同行業中的應用落地,并針對不同領域推出相對應的行業大模型,包括在醫療領域。
眾多企業宣布推出醫療大模型
日前,京東發布了京東言犀大模型、言犀AI開發計算平臺,同時基于京東言犀通用大模型,京東健康發布了“京醫千詢”醫療大模型,可快速完成在醫療健康領域各個場景的遷移和學習,實現產品和解決方案的全面AI化部署。
與通用大模型相比,京東言犀大模型融合70%通用數據與30% 數智供應鏈原生數據,具有“更高產業屬性、更強泛化能力、更多安全保障”的優勢。在醫療服務領域,京東言犀AI開發計算平臺為客戶的大模型開發和行業應用提供了定制化解決方案。
在2023京東全球科技探索者大會暨京東云峰會現場,京東演示了將通用大模型轉化為健康產業大模型的操作。通常來說,從數據準備、模型訓練到模型部署,客戶完成這套流程需要10余名科學家花費一周時間,而利用言犀AI開發計算平臺,只需要1-2名算法人員在數分鐘就能完成;通過平臺模型加速工具的優化,還能節省90%的推理成本。
在前不久的2023世界人工智能大會健康高峰論壇上,聯影智能聯席CEO周翔表示,醫療領域不同于其他垂直領域,目前通用的語言大模型還不能完全滿足醫療場景的精準需求。聯影智能正與復旦大學附屬中山醫院共同攜手開發多模態、多病種的“全病程智醫診療大模型”。
該款AI大模型匯聚中山醫院優質診療經驗,是覆蓋患者入院到出院的全生命周期的智能化輔助系統。在患者入院階段,該模型可基于醫生與患者的溝通對話、體格檢查及病史等信息,輔助生成醫療級結構化入院記錄,智能推薦術前檢查,并作出鑒別診斷建議及手術計劃初稿;在術中通過多模態信息整合完成手術記錄稿;在患者出院階段,可以起草出院記錄及術后隨訪計劃。目前該款大模型已完成第一階段的站點試用。
東軟也于近日表示面向醫療領域推出多款AI+醫療行業應用,包括添翼醫療領域大模型、飛標醫學影像標注平臺4.0、基于WEB的虛擬內窺鏡等。
添翼醫療領域大模型是東軟基于30多年的醫療行業積累,構建的醫療垂直領域大模型,全面融入醫療行業解決方案、產品與服務,賦能醫院高質量發展,引領醫療智能化轉型。面向醫生,添翼讓診療更高效。醫生通過自然語言與添翼交互,快速、精準地完成醫療報告與病歷、醫囑開立;面向患者,添翼讓問診更便捷,成為患者全天私人專屬醫生,提供全面的診后健康飲食、營養與運動建議等服務。添翼的多模態數據融合能力,也將為醫院管理者提供對話式交互與數據洞察,簡化數據利用,讓醫院管理更精細。
大模型在醫療領域的優勢和不足
大模型在醫療領域可以有很好的表現,此前,谷歌和DeepMind的科研人員在《自然》雜志上發表了一項研究,根據其研究結果,一組臨床醫生對谷歌和DeepMind團隊的醫療大模型Med-PaLM回答的評分高達92.6%,與現實中人類臨床醫生的水平(92.9%)相當。
此外谷歌醫療大模型Med- PaLM僅5.9%的答案被評為可能導致“有害”結果,與臨床醫生生成的答案(5.7%)的結果相似。
不過相較于其他領域,大模型在醫療領域的落地會面臨更加復雜的挑戰。比如,醫療行業的專業性更高,醫療場景對問題的容錯率較低,這對大語言模型有更高的要求,需要更專業的語料來給出更專業、更精準的醫療建議;不同模態的醫療數據之間,成像模式、圖像特征都有較大差異,醫療長尾問題紛繁復雜;醫療數據私密性、安全性要求高,滿足醫療機構本地環境部署要求也是大模型落地的重要考慮因素等。
針對各種問題,不少企業已經做了很多工作,比如商湯借助商湯大裝置的超大算力和醫療基礎模型群的堅實基礎,打造了醫療大模型工廠,基于醫療機構的特定需求幫助其針對下游臨床長尾問題高效訓練模型,輔助機構實現模型自主訓練。
商湯科技副總裁、智慧醫療業務負責人張少霆表示,該模式突破了醫療長尾問題數據樣本少、標注難度高的瓶頸,實現了針對不同任務的小數據、弱標注、高效率的訓練,同時顯著降低了大模型部署成本,滿足不同醫療機構個性化、多樣化的臨床診療需求。
小結
可以看到,當前大模型應用落地是業界探索的重點,而醫療行業成了眾多企業關注的垂直領域之一。研究顯示,大模型在醫療領域將會有著非常優秀的表現。同時醫療領域也不同于其他行業,它具有更強的專業性、安全性要求,這也是醫療大模型落地需要解決的問題。
4. GPT-4里套娃LLaMA 2!OpenAI創始成員周末爆改「羊駝寶寶」,GitHub一日千星
原文:https://mp.weixin.qq.com/s/Tp4q8VflEZ7o8FgpZfrNgQ
大神僅花一個周末訓練微型LLaMA 2,并移植到C語言。
推理代碼只有500行,在蘋果M1筆記本上做到每秒輸出98個token。
作者是OpenAI創始成員Andrej Karpathy,他把這個項目叫做Baby LLaMA 2(羊駝寶寶)。
雖然它只有1500萬參數,下載下來也只有58MB,但是已經能流暢講故事。

所有推理代碼可以放在C語言單文件上,沒有任何依賴,除了能在筆記本CPU上跑,還迅速被網友接力開發出了各種玩法。
llama.cpp的作者Georgi Gerganov搞出了直接在瀏覽器里運行的版本。

提示工程師Alex Volkov甚至做到了在GPT-4代碼解釋器里跑Baby LLaMA 2。
羊駝寶寶誕生記
據Karpathy分享,做這個項目的靈感正是來自llama.cpp。
訓練代碼來自之前他自己開發的nanoGPT,并修改成LLaMA 2架構。
推理代碼直接開源在GitHub上了,不到24小時就狂攬1500+星。
訓練數據集TinyStories則來自微軟前一陣的研究。
2023新視野數學獎得主Ronen Eldan、2023斯隆研究獎得主李遠志聯手,驗證了**1000萬參數以下的小模型,在垂直數據上訓練也可以學會正確的語法、生成流暢的故事、甚至獲得推理能力。**

此外,開發過程中還有一個插曲。
Karpathy很久不寫C語言已經生疏了,但是在GPT-4的幫助下,還是只用一個周末就完成了全部工作。
對此,英偉達科學家Jim Fan評價為:現象級。
最初,在CPU單線程運行、fp32推理精度下,Baby LLaMA 2每秒只能生成18個token。
在編譯上使用一些優化技巧以后,直接提升到每秒98個token。
優化之路還未停止。
有人提出,可以通過GCC編譯器的-funsafe-math-optimizations模式再次提速6倍。
除了編譯方面外,也有人提議下一步增加LoRA、Flash Attention等模型層面流行的優化方法。
Baby LLaMA 2一路火到Hacker News社區,也引發了更多的討論。
有人提出,現在雖然只是一個概念驗證,但本地運行的語言模型真的很令人興奮。
雖然無法達到在云端GPU集群上托管的大模型的相同功能,但可以實現的玩法太多了。
在各種優化方法加持下,karpathy也透露已經開始嘗試訓練更大的模型,并表示:
70億參數也許觸手可及。
GitHub:https://github.com/karpathy/llama2.c
在瀏覽器運行Baby LLaMA 2:https://ggerganov.com/llama2.c
參考鏈接:[1]https://twitter.com/karpathy/status/1683143097604243456[2]https://twitter.com/ggerganov/status/1683174252990660610[3]https://twitter.com/altryne/status/1683222517719384065[4]https://news.ycombinator.com/item?id=36838051
6. 對標Llama 2,OpenAI開源模型G3PO已在路上
原文:https://mp.weixin.qq.com/s/hXsKm1M_2utRmj_y9MOBzw
這一次,OpenAI 成了跟進者。
上個星期,Meta 在微軟大會上發布的 Llama 2 被認為改變了大模型的格局,由于開源、免費且可商用,新版羊駝大模型立刻吸引了眾多創業公司、研究機構和開發者的目光,Meta 開放合作的態度也獲得了業內的一致好評,OpenAI 面臨著回應 Meta 開源人工智能技術戰略的壓力。
GPT-4 雖然被一致認為能力領先,但 OpenAI 卻并不是唯一一個引領方向的公司。在大模型領域,開源預訓練模型一直被認為是重要的方向。
GPT-4 因為不提供開源版本而時常受到人們詬病,但 OpenAI 并不一定會堅持封閉的道路,其正在關注開源的影響。兩個月前,有消息稱該公司打算發布自己的開源模型以應對競爭。近日,據外媒 Information 報道,OpenAI 內部已有具體計劃,未來即將開源的大模型代號為「G3PO」。
此前,Meta 的開源策略在機器學習的很多領域取得了成功。起源于 Meta 的開源軟件項目包括 React、PyTorch、GraphQL 等。
在開源問題上,OpenAI 尚未準備好承諾發布自己的開源模型,并且內部尚未決定開源的時間表。
眾所周知,大模型領域最近的發展速度極快。OpenAI 雖然已經轉向,但并沒有快速出手回應 Llama 系列,Information 在此引用了兩個可能的驅動因素:
-
OpenAI 的團隊規模較小,并不專注于推出為客戶提供定制化大模型的商店。雖然這將是吸引開發者,并抵御 Meta 和 Google 的另一種途徑。
-
OpenAI 還希望打造個性化的 ChatGPT Copilot 助手。據消息人士透露,推出真正的「Copilot」將使 OpenAI 與微軟直接競爭,有一些左右互搏的意思,而且這一努力「可能需要數年時間」。
開源的 OpenAI 版大模型可能會在不久之后問世,但 OpenAI 仍然希望堅持「開發先進閉源模型和非先進開源模型」的思路,這將產生足夠收入,形成技術開發的正循環,并且更容易讓開發者傾向于為最先進模型付費。
不過正如 Llama 2 推出時人們所討論的,大模型的發展并不一定會朝著科技巨頭 + 高投入 + 閉源的方向一直前進下去,隨著利用 Llama 2 的商業應用程序開始傳播,大模型技術的世界可能會發生重組。
在 OpenAI 看來,開發人員快速采用開源模型已經被視為一種威脅,目前該公司也正在嘗試一系列方向。
最近,OpenAI 成立了一個新的小組 Superalignment,希望在四年內實現 AGI(通用人工智能)。此外,有傳言稱 OpenAI 可能很快就會推出應用程序商店和個性化版本的 ChatGPT。所以目前來說,G3PO 只是他們眾多未來項目之一。
誰將首先實現 AGI?看起來這個問題目前還沒有明確的答案。
7. 兩萬字長文詳解:如何用C++從零實現神經網絡
原文:https://mp.weixin.qq.com/s/FgRuI9nnC-Zh30ghO6q22w一、Net類的設計與神經網絡初始化既然是要用C++來實現,那么我們自然而然的想到設計一個神經網絡類來表示神經網絡,這里我稱之為Net類。由于這個類名太過普遍,很有可能跟其他人寫的程序沖突,所以我的所有程序都包含在namespace liu中,由此不難想到我姓劉。在之前的博客反向傳播算法資源整理中,我列舉了幾個比較不錯的資源。對于理論不熟悉而且學習精神的同學可以出門左轉去看看這篇文章的資源。這里假設讀者對于神經網絡的基本理論有一定的了解。
 在真正開始coding之前還是有必要交代一下神經網絡基礎,其實也就是設計類和寫程序的思路。簡而言之,神經網絡的包含幾大要素:
在真正開始coding之前還是有必要交代一下神經網絡基礎,其實也就是設計類和寫程序的思路。簡而言之,神經網絡的包含幾大要素:- 神經元節點
- 層(layer)
- 權值(weights)
- 偏置項(bias)
#ifndef NET_H #define NET_H #endif // NET_H #pragma once #include #include #include //#include #include"Function.h" namespace liu { class Net { public: std::vector<int> layer_neuron_num; std::vector<cv::Mat> layer; std::vector<cv::Mat> weights; std::vector<cv::Mat> bias; public: Net() {}; ~Net() {}; //Initialize net:genetate weights matrices、layer matrices and bias matrices // bias default all zero void initNet(std::vector<int> layer_neuron_num_); //Initialise the weights matrices. void initWeights(int type = 0, double a = 0., double b = 0.1); //Initialise the bias matrices. void initBias(cv::Scalar& bias); //Forward void forward(); //Forward void backward(); protected: //initialise the weight matrix.if type =0,Gaussian.else uniform. void initWeight(cv::Mat &dst, int type, double a, double b); //Activation function cv::Mat activationFunction(cv::Mat &x, std::string func_type); //Compute delta error void deltaError(); //Update weights void updateWeights(); }; } 說明:以上不是Net類的完整形態,只是對應于本文內容的一個簡化版,簡化之后看起來會更加清晰明了。成員變量與成員函數現在Net類只有四個成員變量,分別是:
- 每一層神經元數目(layerneuronnum)
- 層(layer)
- 權值矩陣(weights)
- 偏置項(bias)
- initNet():用來初始化神經網絡
- initWeights():初始化權值矩陣,調用initWeight()函數
- initBias():初始化偏置項
- forward():執行前向運算,包括線性運算和非線性激活,同時計算誤差
- backward():執行反向傳播,調用updateWeights()函數更新權值。
//Initialize net void Net::initNet(std::vector<int> layer_neuron_num_) { layer_neuron_num = layer_neuron_num_; //Generate every layer. layer.resize(layer_neuron_num.size()); for (int i = 0; i < layer.size(); i++) { layer[i].create(layer_neuron_num[i], 1, CV_32FC1); } std::cout << "Generate layers, successfully!" << std::endl; //Generate every weights matrix and bias weights.resize(layer.size() - 1); bias.resize(layer.size() - 1); for (int i = 0; i < (layer.size() - 1); ++i) { weights[i].create(layer[i + 1].rows, layer[i].rows, CV_32FC1); //bias[i].create(layer[i + 1].rows, 1, CV_32FC1); bias[i] = cv::zeros(layer[i + 1].rows, 1, CV_32FC1); } std::cout << "Generate weights matrices and bias, successfully!" << std::endl; std::cout << "Initialise Net, done!" << std::endl; }權值初始化initWeight()函數權值初始化函數initWeights()調用initWeight()函數,其實就是初始化一個和多個的區別。偏置初始化是給所有的偏置賦相同的值。這里用Scalar對象來給矩陣賦值。
//initialise the weights matrix.if type =0,Gaussian.else uniform. void Net::initWeight(cv::Mat &dst, int type, double a, double b) { if (type == 0) { randn(dst, a, b); } else { randu(dst, a, b); } } //initialise the weights matrix. void Net::initWeights(int type, double a, double b) { //Initialise weights cv::Matrices and bias for (int i = 0; i < weights.size(); ++i) { initWeight(weights[i], 0, 0., 0.1); } }偏置初始化是給所有的偏置賦相同的值。這里用Scalar對象來給矩陣賦值。
//Initialise the bias matrices. void Net::initBias(cv::Scalar& bias_) { for (int i = 0; i < bias.size(); i++) { bias[i] = bias_; } }至此,神經網絡需要初始化的部分已經全部初始化完成了。初始化測試我們可以用下面的代碼來初始化一個神經網絡,雖然沒有什么功能,但是至少可以測試下現在的代碼是否有BUG:
#include"../include/Net.h" // using namespace std; using namespace cv; using namespace liu; int main(int argc, char *argv[]) { //Set neuron number of every layer vector<int> layer_neuron_num = { 784,100,10 }; // Initialise Net and weights Net net; net.initNet(layer_neuron_num); net.initWeights(0, 0., 0.01); net.initBias(Scalar(0.05)); getchar(); return 0; }二、前向傳播與反向傳播前言前一章節中,大部分還是比較簡單的。因為最重要事情就是生成各種矩陣并初始化。神經網絡中的重點和核心就是本文的內容——前向和反向傳播兩大計算過程。每層的前向傳播分別包含加權求和(卷積?)的線性運算和激活函數的非線性運算。反向傳播主要是用BP算法更新權值。本文也分為兩部分介紹。前向過程如前所述,前向過程分為線性運算和非線性運算兩部分。相對來說比較簡單。線型運算可以用
Y = WX+b來表示,其中X是輸入樣本,這里即是第N層的單列矩陣,W是權值矩陣,Y是加權求和之后的結果矩陣,大小與N+1層的單列矩陣相同。b是偏置,默認初始化全部為0。不難推知,W的大小是(N+1).rows * N.rows。正如上一篇中生成weights矩陣的代碼實現一樣:weights[i].create(layer[i + 1].rows, layer[i].rows, CV_32FC1);非線性運算可以用
O=f(Y)來表示。Y就是上面得到的Y。O就是第N+1層的輸出。f就是我們一直說的激活函數。激活函數一般都是非線性函數。它存在的價值就是給神經網絡提供非線性建模能力。激活函數的種類有很多,比如sigmoid函數,tanh函數,ReLU函數等。各種函數的優缺點可以參考更為專業的論文和其他更為專業的資料。我們可以先來看一下前向函數forward()的代碼://Forward void Net::forward() { for (int i = 0; i < layer_neuron_num.size() - 1; ++i) { cv::Mat product = weights[i] * layer[i] + bias[i]; layer[i + 1] = activationFunction(product, activation_function); } }for循環里面的兩句就分別是上面說的線型運算和激活函數的非線性運算。激活函數
activationFunction()里面實現了不同種類的激活函數,可以通過第二個參數來選取用哪一種。代碼如下://Activation function cv::Mat Net::activationFunction(cv::Mat &x, std::string func_type) { activation_function = func_type; cv::Mat fx; if (func_type == "sigmoid") { fx = sigmoid(x); } if (func_type == "tanh") { fx = tanh(x); } if (func_type == "ReLU") { fx = ReLU(x); } return fx; }各個函數更為細節的部分在
Function.h和Function.cpp文件中。在此略去不表,感興趣的請君移步Github。需要再次提醒的是,上一篇博客中給出的Net類是精簡過的,下面可能會出現一些上一篇Net類里沒有出現過的成員變量。完整的Net類的定義還是在Github里。反向傳播過程反向傳播原理是鏈式求導法則,其實就是我們高數中學的復合函數求導法則。這只是在推導公式的時候用的到。具體的推導過程我推薦看看下面這一篇教程,用圖示的方法,把前向傳播和反向傳播表現的清晰明了,強烈推薦!Principles of training multi-layer neural network using backpropagation。一會將從這一篇文章中截取一張圖來說明權值更新的代碼。在此之前,還是先看一下反向傳播函數backward()的代碼是什么樣的://Backward void Net::backward() { calcLoss(layer[layer.size() - 1], target, output_error, loss); deltaError(); updateWeights(); }可以看到主要是是三行代碼,也就是調用了三個函數:
-
第一個函數
calcLoss()計算輸出誤差和目標函數,所有輸出誤差平方和的均值作為需要最小化的目標函數。 -
第二個函數
deltaError()計算delta誤差,也就是下圖中delta1*df()那部分。 -
第三個函數
updateWeights()更新權值,也就是用下圖中的公式更新權值。
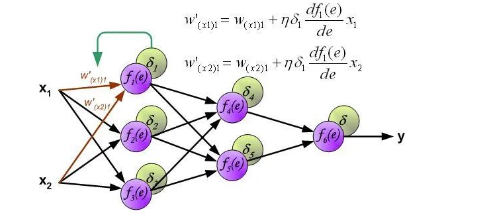 再看下updateWeights()函數的代碼:
再看下updateWeights()函數的代碼://Update weights void Net::updateWeights() { for (int i = 0; i < weights.size(); ++i) { cv::Mat delta_weights = learning_rate * (delta_err[i] * layer[i].t()); weights[i] = weights[i] + delta_weights; } }注意需要注意的就是計算的時候輸出層和隱藏層的計算公式是不一樣的。另一個需要注意的就是......難道大家沒覺得本系列文章的代碼看起來非常友好嗎至此,神經網絡最核心的部分已經實現完畢。剩下的就是想想該如何訓練了。這個時候你如果愿意的話仍然可以寫一個小程序進行幾次前向傳播和反向傳播。還是那句話,鬼知道我在能進行傳播之前到底花了多長時間調試!更加詳細的內容,請查看原文。 點擊閱讀原文進入官網
原文標題:【AI簡報20230728期】醫療領域中的AI大模型,詳解C++從零實現神經網絡
文章出處:【微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
-
RT-Thread
+關注
關注
31文章
1285瀏覽量
40093 -
AI大模型
+關注
關注
0文章
315瀏覽量
305
原文標題:【AI簡報20230728期】醫療領域中的AI大模型,詳解C++從零實現神經網絡
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于卷積神經網絡,這些概念你厘清了么~
pytorch中有神經網絡模型嗎
BP神經網絡和人工神經網絡的區別
人工神經網絡模型的分類有哪些
生成式AI與神經網絡模型的區別和聯系
神經網絡模型的原理、類型及應用領域
基于神經網絡算法的模型構建方法
人工神經網絡的模型及其應用有哪些
深度神經網絡模型有哪些
助聽器降噪神經網絡模型
利用神經網絡對腦電圖(EEG)降噪
NanoEdge AI的技術原理、應用場景及優勢
詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論