


前言
今天在網上看筆試題發現有個設計浮點累加器的題目,看了下題目說明感覺不太清楚,恰好記得之前做過浮點數的加法運算的設計,索性就改了下題目需求,作為一個小練習在重新設計一遍。具體設計要求如下:
設計需求
設計一個32bit浮點的加法器,out = A + B,假設AB均為無符號位,或者換個說法都為正數。
clk為系統時鐘;rst_n為系統復位,低有效;en信號控制數據輸入;busy指示模塊工作狀態,busy拉高時,輸入無效;aIn和bIn是數據輸入,out_vld,指示輸出數據有效。
設計的信號列表如下:
module float_adder(
input clk,
input rst_n,
input en,
input [31:0] aIn,
input [31:0] bIn,
output reg busy,
output reg out_vld,
output reg [31:0] out
);32bit的浮點格式
EE標準754規定了三種浮點數格式:單精度、雙精度、擴展精度。前兩者正好對應C語言里頭的float、double或者FORTRAN里頭的real、double精度類型。本文設計實現的為單精度。
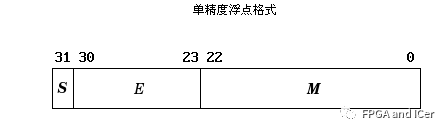 單精度格式
單精度格式單精度:N共32位,其中S占1位,E占8位,M占23位。
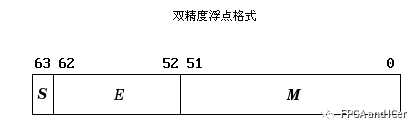 雙精度格式
雙精度格式雙精度:N共64位,其中S占1位,E占11位,M占52位。
浮點數的加法過程
運算過程:對階、尾數求和、規格化、舍入、溢出判斷
對階:
和定點數不相同的是,浮點數的指數量級不一定是一樣的,所以這也就意味著,尾數直接進行加法運算時會存在問題,也就需要首先對階數進行處理。該過程有點像科學計數法的加法處理,把科學計數法的指數化為一致,求出來指數相差多少,然后移位處理后再進行加法減法。所以這里處理也要先求階差。
如果把階碼大的向階碼小的看齊,就要把階碼大的數的尾數部分左移,階碼減小。這個操作有可能在移位過程中把尾數的高位部分移掉,這樣就引發了數據的錯誤,所以,尾數左移在計算機運算中不可取。
如果把階碼小的向階碼大的看齊,在移位過程中如果發生數據丟失,也是最右邊的數據位發生丟失,最右邊的數據位丟失,只會影響數據的精度,不會影響數據的大小。
尾數求和:
這里就是常規的補碼加法。
規格化:
右規(尾數的絕對值太大時,右規)尾數右移一位,階碼加1。當尾數溢出( >1 )時,需要右規。是否溢出,可以通過兩位的符號位得出:即尾數出現01.xx…xx或10.xx…xx(兩位符號位不同)
提高浮點數的表示精度,這里設計考慮比較簡單,我只考慮了同號數據相加的情況,所以這里只設計了右規的情況,不考慮符號位。
舍入判斷:
這里直接用截斷處理的方式,針對數據相加上溢的情況,規定了運算后上溢后將數據規定為最大值。
實現代碼
module float_adder(
input clk,
input rst_n,
input en,
input [31:0] aIn,
input [31:0] bIn,
output reg busy,
output reg out_vld,
output reg [31:0] out
);
//運算過程:對階、尾數求和、規格化、舍入、溢出判斷
//分離階數、尾數
wire signal_bit = aIn[31];
wire [7:0] pow_a = aIn[30:23];
wire [7:0] pow_b = bIn[30:23];
wire [22:0] val_a = aIn[22:0];
wire [22:0] val_b = bIn[22:0];
//找到輸入指數階數較大,和階數差
//對階:在計算機中,采用小階向大階看齊的方法,實現對階。即右移
reg [22:0] pow_max ;
reg [23:0] pow_dif ;
reg [22:0] val_max ;
reg [22:0] val_min ;
reg en_dly0;
always @(posedge clk or negedge rst_n) begin
if(rst_n==0)begin
pow_max <= 'd0;
val_max <= 'd0;
val_min <= 'd0;
pow_dif <= 'd0;
en_dly0 <= 'd0;
end
else if( en == 1 && busy == 0)begin
if(pow_a >= pow_b)begin
pow_max <= pow_a;
val_max <= val_a;
val_min <= val_b;
en_dly0 <= 'd1;
if ( pow_a - pow_b > 'd23) begin
pow_dif <= 'd23;
end
else begin
pow_dif <= pow_a - pow_b;
end
end
else begin
pow_max <= pow_b;
val_max <= val_b;
val_min <= val_a;
en_dly0 <= 'd1;
if ( pow_b - pow_a > 'd23) begin
pow_dif <= 'd23;
end
else begin
pow_dif <= pow_b - pow_a;
end
end
end
else begin
pow_max <= pow_max;
val_max <= val_max;
val_min <= val_min;
pow_dif <= pow_dif;
en_dly0 <= 'd0;
end
end
//移位忙指示信號
reg shift_busy;
reg [4:0] shift_cnt;
always @(posedge clk or negedge rst_n) begin
if (rst_n==0) begin
shift_busy<='d0;
end
else if(en_dly0 == 1 )begin
shift_busy <='d1;
end
else if(shift_cnt == pow_dif)begin
shift_busy <= 0;
end
end
//移位計數
always @(posedge clk or negedge rst_n) begin
if(rst_n == 0)begin
shift_cnt <= 'd0;
end
else if (shift_busy ==1) begin
if (shift_cnt == pow_dif) begin
shift_cnt <= shift_cnt;
end
else begin
shift_cnt <= shift_cnt + 1'b1;
end
end
else begin
shift_cnt <= 'd0;
end
end
reg [22:0] val_shift;
always @(posedge clk or negedge rst_n) begin
if(rst_n == 0)begin
val_shift <= 'd0;
end
else if (en_dly0==1'b1) begin
val_shift <= val_min;
end
else if (shift_busy == 1) begin
val_shift <= {1'b0,val_shift[22:1]};
end
else begin
val_shift <= val_shift;
end
end
//尾數求和
wire val_add_flag = (shift_cnt == pow_dif)&&(shift_busy ==1);
reg [23:0] val_sum;
reg val_sum_vld;
always @(posedge clk or negedge rst_n) begin
if (rst_n==0) begin
val_sum<='d0;
val_sum_vld<='d0;
end
else if(val_add_flag == 1)begin
val_sum <= val_max + val_shift;
val_sum_vld<='d1;
end
else begin
val_sum <= val_sum;
val_sum_vld<='d0;
end
end
//規范
always @(posedge clk or negedge rst_n) begin
if (rst_n==0) begin
out<='d0;
out_vld<='d0;
end
else if(val_sum_vld == 1)begin
//尾數求和有溢出
out_vld<='d1;
out[31]<= signal_bit;
if(val_sum[23] == 1 && out[30:23] == 8'hFF)begin
out[30:23]<= 8'hFF;
out[22:0] <= 23'h7F_FFFF;
end
else if(val_sum[23] == 1)begin
out[30:23]<= pow_max + 1;
out[22:0] <= val_sum[23:1];
end
else begin
out[30:23]<= pow_max;
out[22:0] <= val_sum[22:0];
end
end
else begin
out <= out;
out_vld<='d0;
end
end
//運算忙指示
always @(posedge clk or negedge rst_n) begin
if (rst_n==0) begin
busy<='d0;
end
else if(en == 1 && busy == 0)begin
busy<='d1;
end
else if(out_vld == 1 )begin
busy<='d0;
end
else begin
busy <= busy;
end
end
endmodule
仿真代碼
這里簡單測試了下代碼的功能,模擬了連續輸入多個數據,核查是否數據會影響正常計算過程。
`timescale 1ns/1ps
module float_adder_tb;
// Parameters
// Ports
reg clk = 1;
reg rst_n = 0;
reg en = 0;
reg [31:0] aIn;
reg [31:0] bIn;
wire busy;
wire out_vld;
wire [31:0] out;
float_adder float_adder_dut (
.clk (clk ),
.rst_n (rst_n ),
.en (en ),
.aIn (aIn ),
.bIn (bIn ),
.busy (busy ),
.out_vld (out_vld ),
.out ( out)
);
always
#5 clk = ! clk ;
initial begin
rst_n = 0;
#100;
rst_n = 1;
#100;
aIn = {1'b0,8'd2,23'd7};
bIn = {1'b0,8'd2,23'd8};
en = 1 ;
#10;
aIn = {1'b0,8'd0,23'd7};
bIn = {1'b0,8'd2,23'd8};
en = 1 ;
#1000;
$finish;
end
endmodule
仿真測試
從仿真測試中可以看出,當輸入信號連續輸入兩個浮點數時,在busy拉高狀態下,第二次輸入的數據無效,數據使能信號常為1,也不會影響正常模塊運算過程,只有在該次運算完成busy拉低后數據可重新加載。
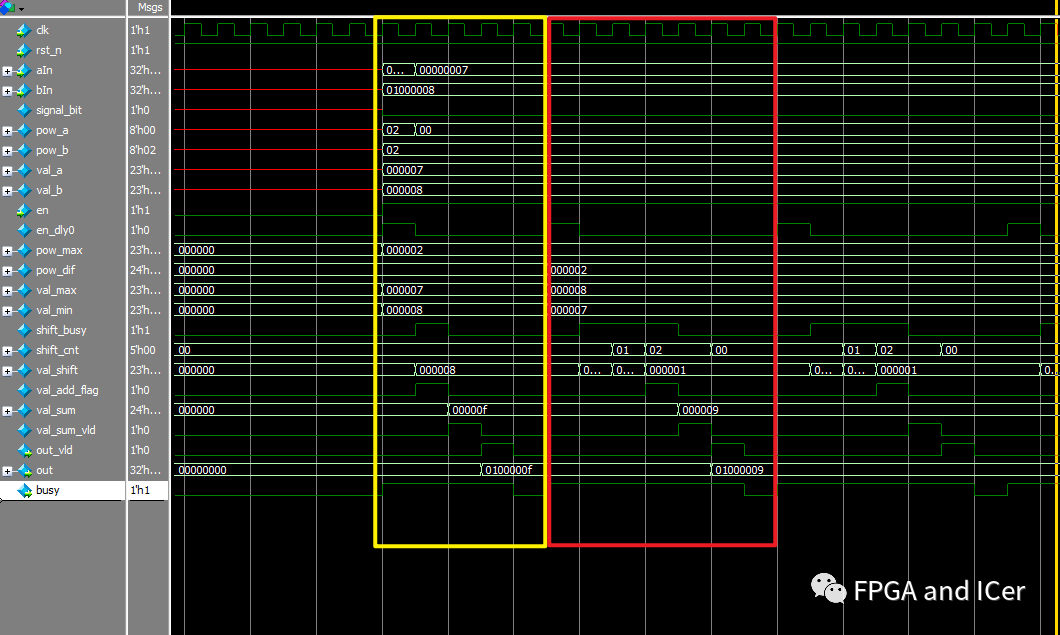 仿真截圖
仿真截圖小結
本文的設計方法對于對階移位的操作需要循環操作,也即當階數相差較小時,結果輸出延遲較小,在極端情況下,比如階數差大于10,輸出延時會比階數差為0時,多10個周期,上限為23。如在實際使用時,對延時要求較小的情況,可針對移位操作部分,使用更多的資源來換取性能的提升。可使用case語句對具體情況進行遍歷。
針對原始題目中的累加操作,可將任意一個輸入和輸出相接,即可實現累加操作。此外,如果要實現異號加法情況,則需要仔細考慮對階,規格化等情況進行進一步設計。
-
模塊
+關注
關注
7文章
2789瀏覽量
50527 -
數據
+關注
關注
8文章
7259瀏覽量
92027 -
加法器
+關注
關注
6文章
183瀏覽量
30797
原文標題:小結
文章出處:【微信號:處芯積律,微信公眾號:處芯積律】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
McASP采集這樣的時序,是按照16bit采集,還是32bit采集?從Linux用戶空間看,采集進來的數據是16bit還是32bit?
32bit MCU與16bit MCU的區別是什么
華邦針對SiP市場推出32bit SDR/DDR利基型內存
淘汰32bit不只iOS 11 明年開始擴展至Mac 32bit應用程序
32bit MCU 與 16bit MCU 的 區別

單片機里面“”32bit地址“”與所指向的“8bit數據“的關系
8bit 8051/32bit Cortex-M0 Flash單片機產品選型手冊
RABPS 32bit by 3dmaniack 3dtoday (ARM BluePill Shield)已修復
使用STM32C0輕松實現從8bit到32bit的平臺升級
毫米波雷達半精度浮點存儲格式分析





 工商網監
工商網監

評論