


存算一體技術產業發展研究
摘要:基于存算一體技術產業發展實際情況,結合人工智能算力快速發展的背景,從基礎硬件、計算架構、技術挑戰等維度分析存算一體技術發展現狀和趨勢,研究存算一體產業結構、主要應用、產業發展面臨的機遇和挑戰,最后根據我國算力技術產業發展實際情況,提出存算一體發展策略。
關鍵詞:內存計算;存算一體;非易失性存儲器件;人工智能
00.引言
隨著人工智能技術產業的演進和向云端、邊緣側的深入,多種依托人工智能算力的新應用、新業態不斷涌現。其中,以ChatGPT等大模型訓練推理為代表的一系列高算力人工智能應用掀起了算力競賽浪潮,使得突破經典馮·諾依曼架構,探索新算力再次成為計算技術突破的重大議題。存算一體技術具備高能效比、可快速進行矩陣運算等特點,是實現人工智能算力提升的重要候選架構。筆者重點對存算一體技術的產生背景、發展歷程、核心技術發展態勢、產業和應用發展態勢等方面進行分析和研究,以期為我國存算一體技術產業發展提出建設性意見。
01.存算一體技術背景及發展歷程
1.1 存算一體技術背景
1.1.1 “馮·諾依曼瓶頸”問題
在馮·諾依曼架構中,數據從存儲單元外的存儲器獲取,處理完畢后再寫回存儲器,計算核心與存儲器之間有限的總帶寬直接限制了交換數據的速度,計算核心處理速度和訪問存儲器速度的差異進一步減緩處理速度,即“馮·諾依曼瓶頸”[1-2]。
一方面,處理器和存儲器二者的需求、工藝不同,性能差距也就越來越大。存儲器數據訪問速度遠低于中央處理器(Central Processing Unit,CPU)的數據處理速度,即“存儲墻”問題。另一方面,數據搬運的能耗比浮點計算高1~2 個數量級[3]。芯片內一級緩存功耗達25 pJ/bit,動態隨機存取內存(Dynamic Random Access Memory,DRAM)訪問功耗達1.3~2.6 nJ/bit[4],是芯片內緩存功耗的50~100 倍,進一步增加了數據訪問能耗。數據訪問和存儲已成為算力使用的最大能耗,即“功耗墻”問題。
此外,摩爾定律放緩,工藝尺寸微縮變得越來越困難,甚至趨近極限;傳統架構提升使得性能增長速度也在變緩,人們試圖尋找一種新的計算范式來取代現有計算范式以跳出馮·諾依曼架構和摩爾定律的圍墻,并進行多種路徑嘗試。
1.1.2 高算力需求的挑戰
當前,算力需求快速增長與算力提升放緩形成尖銳矛盾。以人工智能為例,從1960年到2010年算力需求每兩年提升一倍,而從2012年Alexnet使用圖形處理器(Graphics Processing Unit,GPU)進行訓練開始,算力每3~4個月提升一倍[5]。谷歌AlphaGo在與李世石對弈中僅需要使用1 920 個CPU和280 個GPU[6];而谷歌GPT-3開源人工智能模型有1 746 億個參數,按照訓練10天估算,需要3 000~5 000 塊英偉達A100 GPU;GPT-3.5訓練顯卡數量進一步增至2 萬塊;預計GPT-4訓練參數在萬億的數量級[7],是GPT-3的6倍以上,運行成本和算力需求將大幅高于GPT-3.5。
1.2 存算一體技術解決方案
1.2.1 高帶寬數據通信
高帶寬數據通信主要包括光互聯技術和2.5D/3D堆疊技術。其中光互聯技術具有高帶寬、長距離、低損耗、無串擾和電磁兼容等優勢,但是光互聯器件難以在芯片內布設,且光交換重新連接開銷和延遲較大,實用化成本較高,難以大規模應用。
2.5 D/3D堆疊技術通過增大并行帶寬或利用串行傳輸提升存儲帶寬,簡化系統存儲控制設計難度,具有高集成度、高帶寬、高能效等性能優勢。但是目前2.5D/3D堆疊技術僅對分立器件或芯片內部進行優化設計,“存”和“算”從本質上依然是分離的,難以彌合“存—算”之間的鴻溝。
1.2.2 緩解訪存延遲和功耗的內存計算
為了逾越“存—算”之間的巨大鴻溝,內存計算的概念應運而生。內存計算有兩種技術類型,一種是橫向擴展(Scale-out),主要是分布式內存計算,典型代表有Spark架構,是一種軟件的方案;另一種是縱向擴展(Scale-up),又分為兩種,一種是近數據端處理(Near Data Processing,NDP),包括近存儲計算和近內存計算,另一種是存算一體,依賴經典存儲器件或新型的存算器件,如圖1所示。
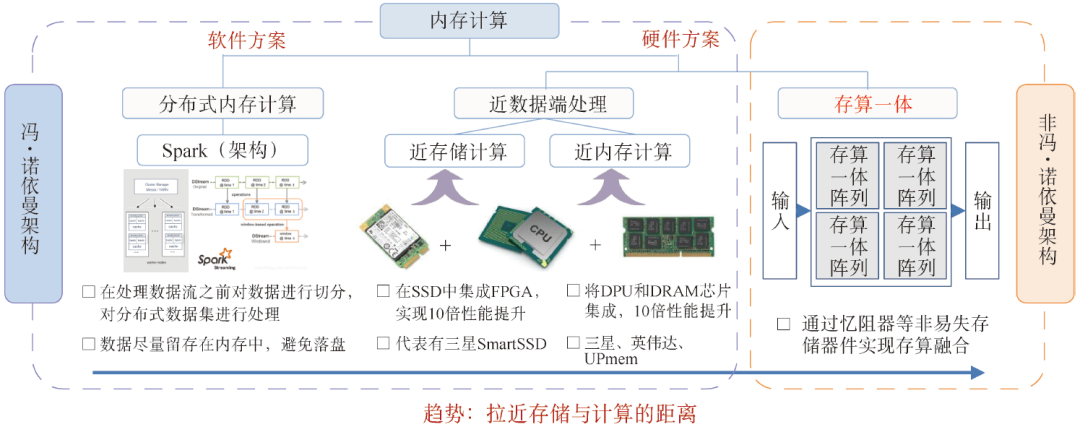
圖1 內存計算體系
分布式內存計算是較早前誕生的基于軟件的內存計算方案。2003年谷歌公司提出的MapReduce計算框架,能夠處理TB級數據量,是一種“分而治之再規約”的計算模型,用多個計算節點來計算。但缺點是在反復迭代計算過程中,數據要落盤,從而影響數據計算速度。2010年,美國加州大學伯克利分校AMP實驗室提出的分布式計算框架Spark,能夠充分利用內存高速的數據傳輸速率,同時某些數據集已經能全部放在內存中進行計算,數據盡量留存在內存中,從而避免落盤,隨著內存容量持續增長,Spark依然活躍在工業界。
近數據端處理又分為兩種,一種是近存儲計算(In-Storage Computing,ISC),即在非易失存儲模塊中(固態硬盤等)加入現場可編程邏輯門陣列(Field Programmable Gate Array,FPGA)、ARM處理器核等計算單元。三星在2019年展示產品Smart SSD(PM1725),集成了數字數據處理器(Numeric Data Processor,NDP),可以通過一些編程模型、庫和編譯器進行程序編譯后在硬盤內計算。近數據端計算的另一種方式是近內存計算(In-Memory Computing,IMC),數據直接在內存中計算后返回,通過將存儲層和邏輯層堆疊實現大通道計算,目前業界有三星、英偉達、UPMem等企業跟進。
以上基于軟件的分布式內存計算和拉近存儲與計算距離的近數據端處理,依然保留了經典馮·諾依曼架構的數據處理特點,而基于器件層面實現的存算一體是真正打破了存算分離架構壁壘的非馮·諾依曼架構。一方面,存算一體將計算和訪存融合,在存儲單元內實現計算,從體系結構上消除了訪存操作,從而避免了訪存延遲和訪存功耗,解決了“馮·諾依曼瓶頸”。另一方面,存算一體恰好能滿足人工智能算法的訪存密集、規則運算、低精度特性。因此,存算一體是解決“存儲墻”“功耗墻”問題的有效方案之一。
02.存算一體核心技術發展態勢
存算一體技術體系包含基礎理論、基礎硬件、計算架構、軟件算法和應用五部分。其中基礎理論包含近存儲計算、計算型存儲、歐姆定律、基爾霍夫定律等;基礎硬件又包含非易失性存儲和易失性存儲兩大類,非易失性存儲又包含基于傳統浮柵器件/閃存的存算一體和基于新型非易失性存儲器件(Non-Volatile Memory,NVM),包括基于相變存儲器(Phase-Change Memory,PCM)的存算一體、基于阻變存儲器(Resistive Random Access Memory,ReRAM)的存算一體和基于自旋轉移矩磁存儲器(Spin-Transfer Torque Magnetoresistence Random Access Menory,STT-MRAM,簡稱“MRAM”)的存算一體;易失性存儲計算則主要基于靜態隨機存取存儲器(Static Random-Access Memory,SRAM)和DRAM兩類器件。計算架構方面包括邏輯計算、模擬計算、搜索計算三大類型;軟件算法包括TensorFlow、卷積神經網絡框架(Convolutional Architecture for Fast Feature Embeddin,Caffe)、卷積神經網絡(Convolutional Neural Networks,CNN)、深度神經網絡(Deep-Learning Neural Network,DNN)、長短期記憶(Long Short-Term Memory,LSTM)等人工智能相關軟件和算法;應用主要包括人工智能、智能物聯網(Artificial Intelligence & Internet of Things,AIoT)、圖計算、感存算一體等(如圖2所示)。
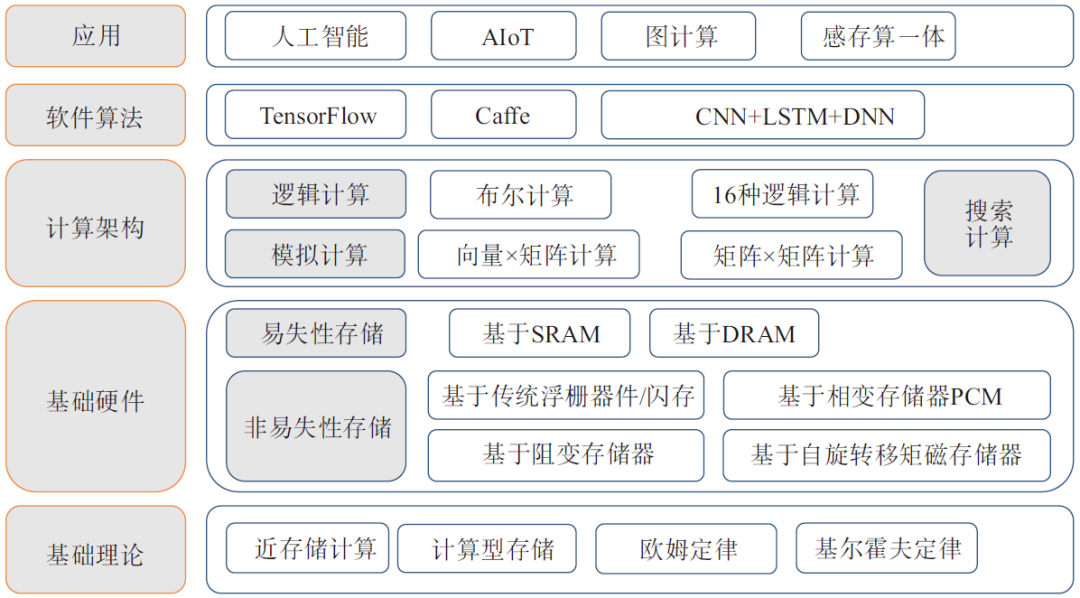
圖2 存算一體技術體系
2.1 存算一體基礎硬件
2.1.1 易失性存儲器件:運算較快,但難以實現大規模擴展
存算一體器件與一般MOSFET器件的區別在于能“存”,“存”又包括易失性存儲和非易失性存儲,其中易失性存儲的SRAM和DRAM成為人們優先嘗試的對象。
SRAM二值MAC運算可以把網絡權重存儲于SRAM單元中,利用外圍電路可以快速實現異或非(XNOR)累加運算,且能夠實現二值神經網絡運算[8]。DRAM則利用單元之間的電荷共享機制來實現存算一體,實現較快的運算速度,但是計算對數據具有破壞性,且功耗較大,以上兩種存算一體架構均難以在實現大陣列運算的同時保證計算精度。
總的來說,基于易失性存儲器件SRAM或者DRAM存儲器的存算一體架構可以實現較快的運算速度,但是難以實現大陣列擴展運算。此外,基于DRAM存儲器的存算一體架構對數據具有破壞性,并帶來顯著的功耗問題。
2.1.2 浮柵器件/閃存:工藝成熟,率先應用于存算一體芯片
浮柵器件工藝成熟,編程時間10~1 000 ns,可編程次數達105 次,存儲陣列大,可實現量產,運算精度高、密度大、效率高、成本低[9]。NAND Flash用于存算一體最大的難點是地址和命令只能在I/O上傳遞,不能直接使用,需要十分復雜的技術才能實現模擬計算的功能。因此目前主要使用Nor Flash來制造存算一體芯片。
2.1.3 相變存儲器:成本及功耗高,已應用于存儲級內存中
相變存儲器是基于硫屬化物玻璃材料,施加合適電流將介質從晶態變為非晶態并再變回晶態,基于材料導電性差異存儲數據,如圖3所示。非晶態相變材料電阻率高、阻值大;多晶態相變材料的電阻率低、阻值小。通過控制脈沖電壓幅度產生熱量可以實現非晶體和多晶態間轉換,從而控制阻值大小,實現存儲(阻值態)和計算。優點是高讀寫速度、壽命長、工藝簡單、可以進行多態存儲和多層存儲;缺點主要是單bit成本高、發熱量大功耗高、電路設計不完善[10]。
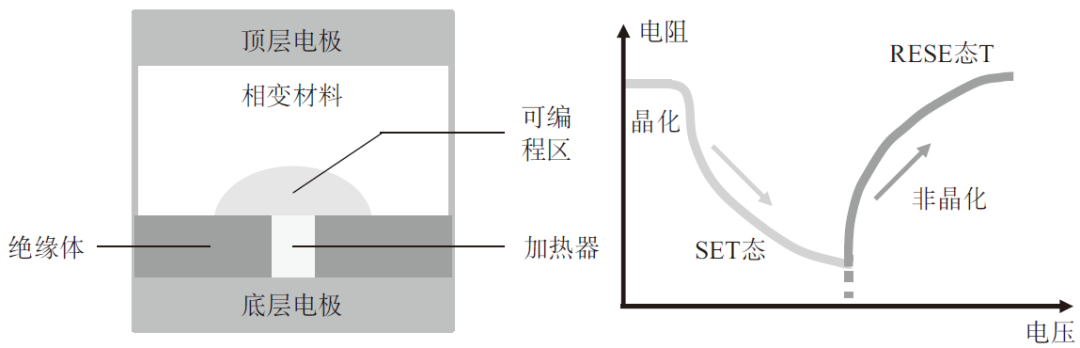
圖3 PCM器件結構和R-V特性
2.1.4 阻變存儲器:契合存算一體對器件的需求
ReRAM是“三明治”結構,包含了上下金屬電極和中間的阻變絕緣體層,初始狀態為高阻態,需要在兩端施加大的電壓脈沖“激活”,通過正向/反向電壓“擊穿”金屬氧化層形成導電細絲/氧原子復位,完成在低阻態與高阻態間的轉換(如圖4所示)。優點主要包括可高速讀寫編程、壽命長、具備多位存儲能力、與CMOS工藝兼容、功耗低、可3D集成;缺點主要有絲狀電阻擴展難、相鄰單元串擾和器件微縮能力難以兼顧。在商業化上,Crossbar、昕原半導體、松下、Adesto、Elpida、東芝、索尼、海力士、富士通等廠商都在開展ReRAM的研究和生產。
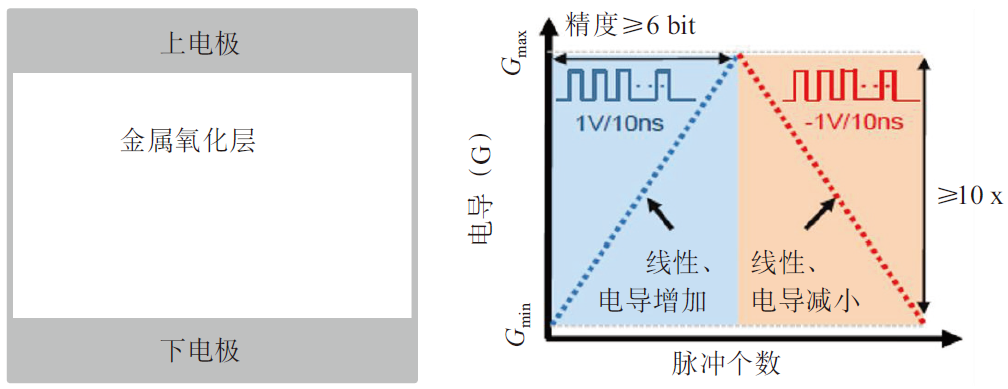
圖4 ReRAM器件結構和脈沖響應特性
2.1.5 自旋轉移矩磁存儲器:容量提升有待進一步突破
MRAM基本結構包含三層,其中底層磁化的方向不變,稱為參考層;頂層磁化方向可被編程發生變化,稱為自由層;中間層稱為隧道層。由于隧道磁阻效應,參考層和自由層的相對磁化方向決定了磁效應憶阻器的阻值大小。參考層和自由層的磁化方向一致時(P態),磁效應憶阻器的阻值最小;如果磁化方向不一致時(AP態),磁效應憶阻器的阻值最大(如圖5所示)。優點主要是讀寫高速、壽命長,和邏輯芯片整合度高、功耗低;缺點包括臨近存儲單元之間存在磁場疊加,互相干擾嚴重。
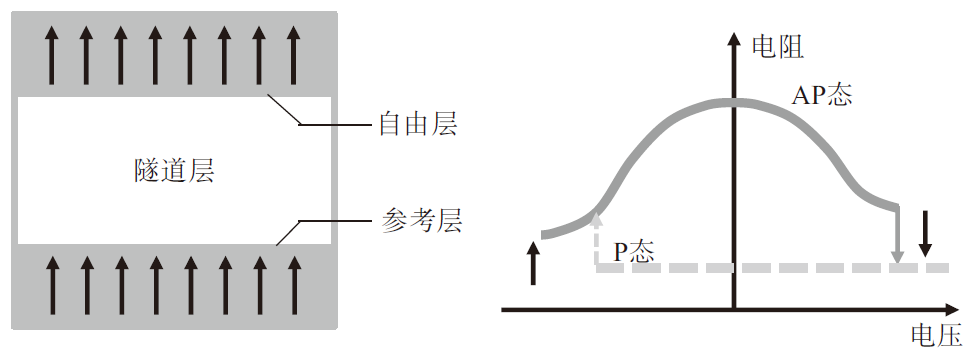
圖5 MRAM器件結構和R-V特性
2.1.6 小結
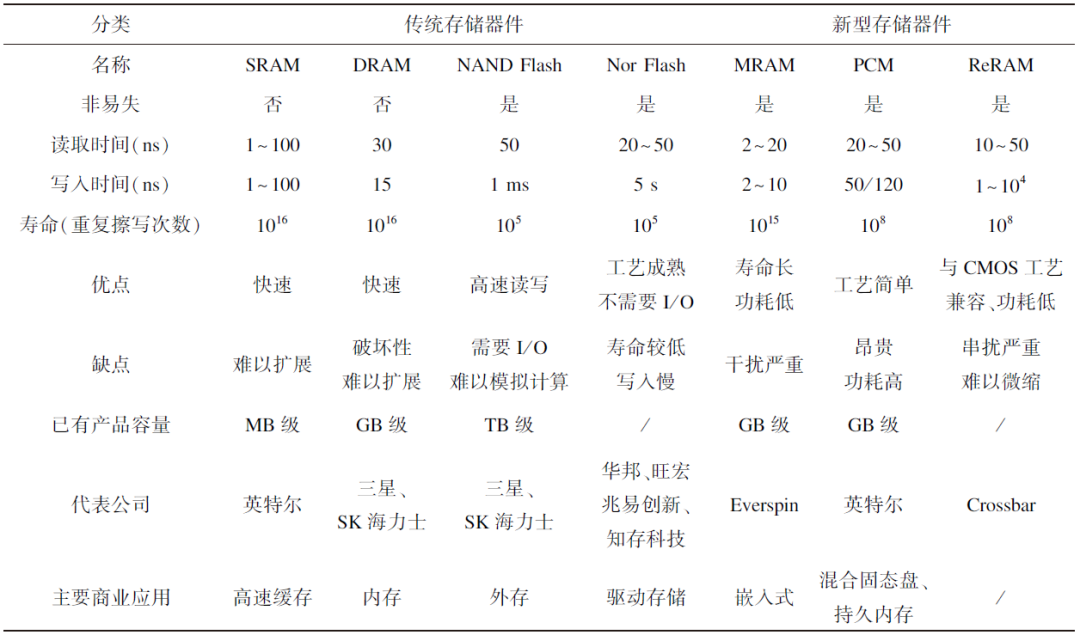
Nor Flash工藝成熟,已率先應用于存算一體芯片。SRAM制作工藝、研發工具都更加成熟穩定,具有耐久性強且操作速度快的特點,可以實時在存算單元中刷新計算數據,具備大算力場景應用潛力。ReRAM工藝可以與互補金屬氧化物半導體(Complementary Metal-Oxide-Semiconductor,CMOS)兼容,具有高速讀出、壽命長、功耗低、可3D集成等優點,初具產業化潛力,其相關性能如表1所示。臺積電正開展MRAM攻關,未來有望實現突破。但是新型非易失存儲器在存算一體技術的應用還存在諸多問題,從實驗室到產業化還有一定差距。
表1 存儲器件相關性能總結
2.2 存算一體技術計算架構
2.2.1 邏輯計算:二值憶阻器可以實現完備的布爾邏輯
基于新型憶阻器的存算一體技術架構可實現完備的布爾邏輯計算。如圖6所示,在R-R邏輯運算中,基于歐姆定律和基爾霍夫電壓電流定律,根據輸入將兩個憶阻器件寫到對應高低阻態,分別施加電壓,輸出結果存在X2。在V-R邏輯運算中,輸入是通過施加在單個憶阻器兩端的電壓幅值X1、X2來表示,而邏輯輸出Y則由高低阻態來表示。在V-V邏輯運算中,根據歐姆定律,輸入和輸出通過電壓幅值低高來分別表示邏輯0和1,需要額外的比較器設計,構成與、或、非3類邏輯[10]。
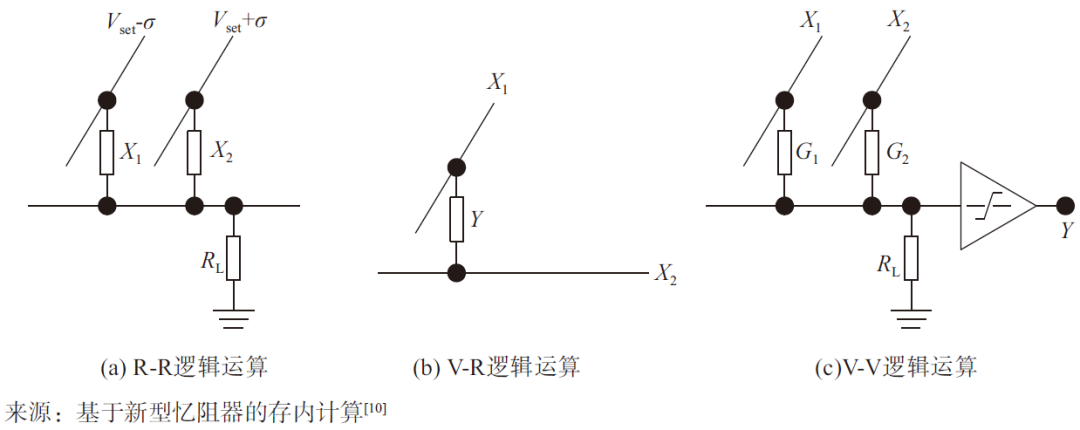
圖6 R-R、V-R和V-V三種邏輯運算電路
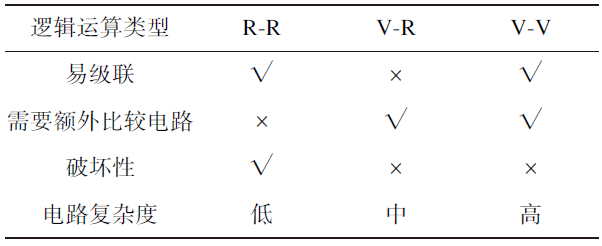
破壞性是指是否會擦除輸入的初態。如表2所示,只有R-R因為輸入輸出都是憶阻器的阻值,所以輸出后原阻值會被擦除,所以具有破壞性;但是電路簡單且易級聯。V-R電路具有非破壞性的優點,但是需要額外比較電路,電路復雜度上升。V-V電路復雜度最高。綜合考慮級聯性、電路復雜性、破壞性等特性,目前R-R和V-R更具實用價值。
表2 R-R、V-R和V-V三種邏輯運算電路的比較
2.2.2 模擬計算:行列式與矩陣乘運算
基于新型憶阻器的存算一體技術架構,利用歐姆定律和基爾霍夫定律,通過網絡陣列可進行矩陣向量乘法運算,如圖7所示。單個存儲單元即可完成8 bit乘加法運算(原需2 500 個晶體管),可并行完成整個矩陣的運算,效率提高50~100 倍。適用于人工智能訓練(超過90%的運算為矩陣運算)等大數據、低精度、簡單乘加運算等場景[1]。
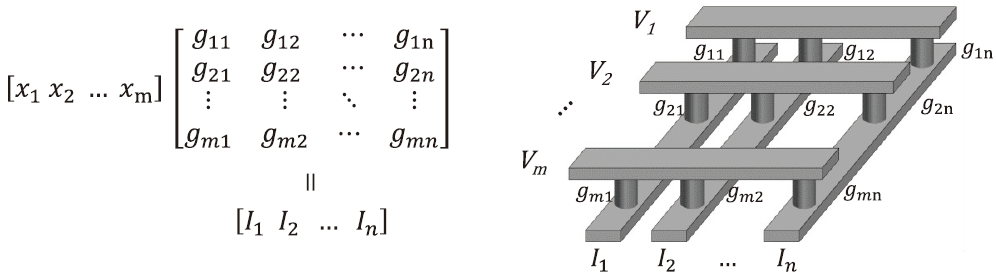
圖7 基于新型憶阻器的向量矩陣乘法
2.2.3 搜索計算:特殊搜索問題具有較高的效能
清華大學的SQL-PIM是基于存算一體技術的搜索計算。SQL-PIM能在不改變結構化存儲的前提下支持增、刪、改、查操作。針對數據量大的數據庫表,SQL-PIM利用一種特殊的關聯分割方法,將大表存儲在多個存內計算陣列中,同時減少每個計算陣列之間的相互通信。與傳統的數據庫相比,SQL-PIM能節約4~6 個數量級的能耗[11]。但是整體而言,存算一體技術應用于搜索運算還停留在實驗室階段,尚未實現產業化或商業化應用。
2.3 存算一體技術挑戰
2.3.1 器件特性難以滿足全部需求
存算一體技術功能器件紛繁多樣,然而目前尚未有一種器件的性能能滿足全部應用需求。器件存在均一性差、循環耐久性差、器件狀態漂移等問題,目前已有一些優化和解決的方法,但尚未根本解決上述問題。
2.3.2 陣列存在泄露路徑、寫串擾以及寄生電容電阻問題
存算一體芯片網格陣列面臨泄露路徑、寫串擾以及寄生電容電阻三大問題。在讀取器件阻值時,泄露路徑的存在引入了并聯的電流通路,可能造成錯誤的讀取結果。泄露路徑還會帶來額外的功耗,并隨著陣列規模的擴大而變得更加嚴重。由于陣列高度并行性帶來的寫串擾問題會使未被選中器件的阻值受到一定影響。寄生電容、電阻會使電路延遲增加,使遠端器件工作異常[12]。
2.3.3 現有集成電路設計與集成技術難以滿足需求
控制輔助電路面積和功耗占比太高,外圍的器件比存算的部分大很多,外圍功耗也會減少存算一體的收益。設計方面,CMOS走在前沿,與存儲存在工藝差距,而統一制程將增加硬件開銷,獨立制程又將增加系統復雜度。3D異質集成是可行的路徑。
2.3.4 架構設計與開發工具有待標準化
計算的多樣性與計算定制性之間存在矛盾。不同計算網絡需要定制化的存算一體架構,而全定制又不利于推廣。軟件和開發工具方面,缺少標準化的異構編程框架;數據映射、數據流配置缺少工具;模擬計算的“模糊/隨機性”還需要進行圖靈完備性的檢驗。
03.存算一體技術產業和應用發展態勢
3.1 產業發展現狀
3.1.1 科研巨頭加速布局
IBM公司重點布局PCM。2018年IBM公司通過PCM實現在數據存儲的位置執行計算來加速全連接神經網絡訓練,該芯片的能效比是傳統GPU的280 倍,單位面積算力是傳統GPU的100 倍[13]。
三星集團重點布局DRAM和MRAM。2017年,三星電子存儲部門聯合加州大學圣巴巴拉分校推出DRISA架構,實現了卷積神經網絡的計算功能,在提供大規模片上存儲的同時也具備較高的計算性能。2022年初,三星電子在《Nature》上發表了首個基于MRAM的存算一體芯片,三星電子采用28 nm CMOS工藝重新構建MRAM陣列結構,以“電阻總和”(Resistance Sum)的存內計算結構代替了傳統的“電流總和”(Current Sum),或電荷共享式的存內計算架構,通過測試分類識別等算法,得到98%的準確率[14]。
英特爾公司重點布局SRAM。英特爾公司聯合美國密歇根州立大學從2016年開始展開基于SRAM的計算型存儲/存算一體技術研究。2016年,基于SRAM實現了支持邏輯操作的存儲器,并在此基礎上實現了支持無進位乘法運算的計算型緩存[15]。2018年英特爾公司發布了面向深度學習算法的神經緩存,可以實現加法、乘法和減法操作[16]。
3.1.2 初創企業涌現,投融資進入活躍期,迎來產業化轉折點
存算一體初創公司蓬勃發展,在北美和我國先后涌現多家初創公司。較早成立的初創公司傾向于采用較為成熟的Nor Flash器件,知存科技等多家企業在2021年實現Nor Flash存算一體芯片量產,2021年成為存算一體產業化元年。近幾年,初創企業加快布局SRAM領域,但是ReRAM等新型非易失存儲器件還只在初創企業的藍圖中,尚未實現流片量產。
存算一體技術近年來受到資本市場高度關注,在中美兩國涌現的初創企業均獲得投融資機會。從2021年開始,在我國半導體產業政策和基金雙重助力下,存算一體領域投融資尤為活躍,多家初創企業獲得上億元融資。
3.1.3 存算一體技術與類腦計算具有深度關聯
存算一體技術是大腦最主要的特征之一,也是實現高算力、高能效計算的一項關鍵技術。以清華大學為代表的涉及憶阻器領域的科研院校同時進行存算一體技術和類腦計算研究,在材料、器件研發、芯片設計、性能測試等方面深度關聯。
存算一體技術和類腦計算具有相同點和不同點。相同點是器件方面均采用憶阻器作為核心器件;應用都主要面向人工智能。不同點是類腦計算的神經形態器件更復雜,而存算一體器件較為基礎;類腦芯片主要采用脈沖神經網絡的架構,具有專用性,存算一體技術主要是矩陣結構,具有通用性。
3.2 存算一體技術應用
3.2.1 AI訓練和推理:圖像識別、大模型訓練推理
2017年,清華大學團隊制備了128×8的多值憶阻器陣列,對包含320(20×16)個像素點的人臉圖像進行訓練和識別。單幅圖像識別耗能可低達61.16 nJ,識別速度可高達34.8 ms,識別率超過85%[17]。
2023年3月,南京大學王欣然教授團隊與清華大學吳華強教授團隊合作,提出基于二維半導體鐵電晶體管的新型存內計算器件架構,通過調節鐵電勢阱,實現了同時滿足AI訓練和推理需求的底層器件,并展現了高達103 TOPS/W級別的能效潛力。該成果突破了邊緣端人工智能硬件的關鍵瓶頸之一[18]。
由于GPT等大模型訓練中占比80%~85%的線性計算(Linear)、前饋計算(Feed Forward)、歸一化(Layer Norm)以及參數變量乘積等計算流程在進行分解后都可以通過存算一體技術完成,因此存算一體技術在大模型訓練方面有望取得應用突破。
與此同時,存算一體計算精度會受到模擬計算低信噪比的影響,通常精度上限在8 bit左右,難以實現精準的浮點數計算。現階段GPT大模型訓練也主要依賴H100/A100等英偉達GPU的絕對算力,短期內對能效比等因素不敏感。產業界目前使用的Nor Flash、SRAM為主導的存算一體芯片僅在能效比方面擁有優勢,在絕對算力方面難以滿足智能計算算力需求,難以應用于智能計算中心。
3.2.2 AIoT:終端應用、無人駕駛
隨著AIoT的快速發展,針對時延、帶寬、功耗、隱私/安全性等特殊應用需求,驅動邊緣側和端側智能應用場景爆發。借助邊緣端/終端有限的處理能力,可以過濾掉大部分無用數據,從而大幅度提高用戶體驗。存算一體技術具有低功耗和適用于低精度AI的特性,能夠作為協處理器應用于智能終端等AIoT場景。
AIoT是存算一體技術目前布局的重點領域。知存科技重點布局語言喚醒語音活動檢測(Voice Activity Detection,VAD)、語音識別、通話降噪、聲紋識別等,可以應用在很多嵌入式領域中,包括健康監測以及較低功耗(毫安級)的視覺識別;九天睿芯產品主要用于語音喚醒,或者時間序列傳感器信號計算處理;定位推廣可穿戴及超低功耗IoT設備;后摩智能相關芯片應用于無人車邊緣端以及云端推理和培訓等場景,2022年5月,后摩智能自主研發的存算一體技術大算力AI芯片跑通智能駕駛算法模型。
存算一體技術在向邊緣側延伸過程中面臨專用集成電路(Application Specific Integrated Circuit,ASIC)、微控制單元(Microcontroller Unit,MCU)以及邊緣計算中心的競爭壓力,尚未成為低功耗場景的唯一方案。在語音喚醒等場景中,MCU足以滿足低功耗需求,存算一體芯片不具備優勢。隨著5G等技術的發展,數據處理不再拘泥于本地,邊緣計算中心成為端側智能計算的新路徑,存算一體技術面臨新的競爭。隨著無線充電等新技術的崛起,依賴極低功耗的高續航已經不再是剛需,存算一體芯片低功耗優勢場景面臨進一步壓縮。
3.2.3 感存算一體:在科研領域已取得諸多進展
感存算一體包括觸覺/壓力感存算一體、視覺/光學感存算一體和嗅覺/氣體感存算一體三大類。觸覺/壓力感存算一體方面,2016年,新加坡南洋理工大學將阻變壓力傳感器和阻變存儲器串聯起來形成觸覺記憶單元。視覺/光學感存算一體方面,2019年,中國香港理工大學提出的Pd/MoOx/ITO雙端光電阻存儲器件(ORRAM),不僅可以進行圖像感知和記憶,而且實現了降低圖像背景噪聲等圖像預處理功能。嗅覺/氣體感存算一體方面,2017年,美國斯坦福大學團隊將100多萬個憶阻器與200多萬個碳納米管晶體管(Carbon-Nanotube Field-Effect Transistors,CNTFET)集成感知周圍氣體,并轉化為電信號存儲在ReRAM中。與之前訓練學習的氣體數據進行對比,從而識別出所檢測的氣體種類[19]。
3.2.4 矩陣與搜索:圖計算和基因工程
圖計算中大量操作都可以轉換成矩陣乘的形式,因此可以用存算一體技術來處理,在預處理、稀疏矩陣的分隔和映射、硬件控制和數據流設計等環節能夠實現超過傳統計算的能效比。生物數據的暴增給諸如基因序列查找/匹配的應用帶來了很大的挑戰。基于存算一體技術的搜索計算能級能夠提供高硬件并行度,適用于大規模生物數據處理[11]。
04.結束語
存算一體技術應作為我國先進計算產業發展的重點之一,需保持長期關注,要做好中長期路線制定,在支持現有Nor Flash的基礎上加強對ReRAM等新型非易失存儲的研究,并對存算一體相關基礎材料、設計工具等加強研發。但是也要明確其短期內難以為我國基礎算力技術產業發展發揮巨大作用,因此要向領先國家和企業吸取相關經驗教訓,避免超前投入。此外,要加快推進存算一體應用融合,在未來3~5年內通過自主創新開發專門的存算一體芯片設計工具等基礎性產品,提升綜合性能,加強“器件—芯片—算法—應用”跨層協同,構建存算一體芯片的產業化應用與生態。
-
半導體
+關注
關注
335文章
28943瀏覽量
238490 -
晶體管
+關注
關注
77文章
10020瀏覽量
141805 -
矩陣
+關注
關注
1文章
434瀏覽量
35262
原文標題:從基礎硬件、計算架構到技術挑戰,詳解存算一體技術發展現狀與趨勢
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
SRAM存算一體芯片的研究現狀和發展趨勢
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究


寬帶無線移動通信技術發展現狀及趨勢
2023年存算一體是芯片設計的技術趨勢
深度解讀工控安全技術發展現狀與應用趨勢


存算一體化與邊緣計算:重新定義智能計算的未來






 工商網監
工商網監

評論