


本文為你列舉了統計學派中18種經典的數據分析法。
Part1 描述統計
描述統計是通過圖表或數學方法,對數據資料進行整理、分析,并對數據的分布狀態、數字特征和隨機變量之間關系進行估計和描述的方法。描述統計分為集中趨勢分析和離中趨勢分析和相關分析三大部分。
集中趨勢分析:集中趨勢分析主要靠平均數、中數、眾數等統計指標來表示數據的集中趨勢。例如被試的平均成績多少?是正偏分布還是負偏分布?
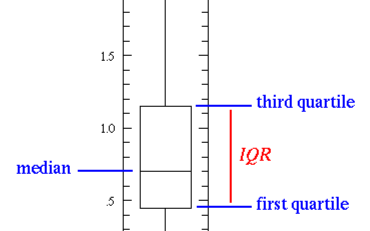
離中趨勢分析:離中趨勢分析主要靠全距、四分差、平均差、方差(協方差:用來度量兩個隨機變量關系的統計量)、標準差等統計指標來研究數據的離中趨勢。例如,我們想知道兩個教學班的語文成績中,哪個班級內的成績分布更分散,就可以用兩個班級的四分差或百分點來比較。
相關分析:相關分析探討數據之間是否具有統計學上的關聯性。這種關系既包括兩個數據之間的單一相關關系——如年齡與個人領域空間之間的關系,也包括多個數據之間的多重相關關系——如年齡、抑郁癥發生率、個人領域空間之間的關系;既包括A大B就大(小),A小B就小(大)的直線相關關系,也可以是復雜相關關系(A=Y-B*X);既可以是A、B變量同時增大這種正相關關系,也可以是A變量增大時B變量減小這種負相關,還包括兩變量共同變化的緊密程度——即相關系數。實際上,相關關系唯一不研究的數據關系,就是數據協同變化的內在根據——即因果關系。獲得相關系數有什么用呢?簡而言之,有了相關系數,就可以根據回歸方程,進行A變量到B變量的估算,這就是所謂的回歸分析,因此,相關分析是一種完整的統計研究方法,它貫穿于提出假設,數據研究,數據分析,數據研究的始終。
例如,我們想知道對監獄情景進行什么改造,可以降低囚徒的暴力傾向。我們就需要將不同的囚舍顏色基調、囚舍綠化程度、囚室人口密度、放風時間、探視時間進行排列組合,然后讓每個囚室一種實驗處理,然后用因素分析法找出與囚徒暴力傾向的相關系數最高的因素。假定這一因素為囚室人口密度,我們又要將被試隨機分入不同人口密度的十幾個囚室中生活,繼而得到人口密度和暴力傾向兩組變量(即我們討論過的A、B兩列變量)。然后,我們將人口密度排入X軸,將暴力傾向分排入Y軸,獲得了一個很有價值的圖表,當某典獄長想知道,某囚舍擴建到N人/間囚室,暴力傾向能降低多少。我們可以當前人口密度和改建后人口密度帶入相應的回歸方程,算出擴建前的預期暴力傾向和擴建后的預期暴力傾向,兩數據之差即典獄長想知道的結果。
Part2 推論統計
推論統計是統計學乃至于心理統計學中較為年輕的一部分內容。它以統計結果為依據,來證明或推翻某個命題。具體來說,就是通過分析樣本與樣本分布的差異,來估算樣本與總體、同一樣本的前后測成績差異,樣本與樣本的成績差距、總體與總體的成績差距是否具有顯著性差異。例如,我們想研究教育背景是否會影響人的智力測驗成績。可以找100名24歲大學畢業生和100名24歲初中畢業生。采集他們的一些智力測驗成績。用推論統計方法進行數據處理,最后會得出類似這樣兒的結論:“研究發現,大學畢業生組的成績顯著高于初中畢業生組的成績,二者在0.01水平上具有顯著性差異,說明大學畢業生的一些智力測驗成績優于中學畢業生組。”
其中,如果用EXCEL 來求描述統計。其方法是:工具-加載宏-勾選"分析工具庫",然后關閉Excel然后重新打開,工具菜單就會出現"數據分析"。描述統計是“數據分析”內一個子菜單,在做的時候,記得要把方格輸入正確。最好直接點選。
Part3 正態性檢驗
很多統計方法都要求數值服從或近似服從正態分布,所以之前需要進行正態性檢驗。常用方法:非參數檢驗的K-量檢驗、P-P圖、Q-Q圖、W檢驗、動差法。
Part4 假設檢驗
參數檢驗
參數檢驗是在已知總體分布的條件下(一股要求總體服從正態分布)對一些主要的參數(如均值、百分數、方差、相關系數等)進行的檢驗。
U檢驗:使用條件:當樣本含量n較大時,樣本值符合正態分布
T檢驗:使用條件:當樣本含量n較小時,樣本值符合正態分布
單樣本t檢驗:推斷該樣本來自的總體均數μ與已知的某一總體均數μ0 (常為理論值或標準值)有無差別;
配對樣本t檢驗:當總體均數未知時,且兩個樣本可以配對,同對中的兩者在可能會影響處理效果的各種條件方面扱為相似;
兩獨立樣本t檢驗:無法找到在各方面極為相似的兩樣本作配對比較時使用。
非參數檢驗
非參數檢驗則不考慮總體分布是否已知,常常也不是針對總體參數,而是針對總體的某些一股性假設(如總體分布的位罝是否相同,總體分布是否正態)進行檢驗。
適用情況:順序類型的數據資料,這類數據的分布形態一般是未知的。
雖然是連續數據,但總體分布形態未知或者非正態;
體分布雖然正態,數據也是連續類型,但樣本容量極小,如10以下;
主要方法包括:卡方檢驗、秩和檢驗、二項檢驗、游程檢驗、K-量檢驗等。
Part5 信度分析
信度(Reliability)即可靠性,它是指采用同樣的方法對同一對象重復測量時所得結果的一致性程度。信度指標多以相關系數表示,大致可分為三類:穩定系數(跨時間的一致性),等值系數(跨形式的一致性)和內在一致性系數(跨項目的一致性)。信度分析的方法主要有以下四種:重測信度法、復本信度法、折半信度法、α信度系數法。
方法
重測信度法:這一方法是用同樣的問卷對同一組被調查者間隔一定時間重復施測,計算兩次施測結果的相關系數。顯然,重測信度屬于穩定系數。重測信度法特別適用于事實式問卷,如性別、出生年月等在兩次施測中不應有任何差異,大多數被調查者的興趣、愛好、習慣等在短時間內也不會有十分明顯的變化。如果沒有突發事件導致被調查者的態度、意見突變,這種方法也適用于態度、意見式問卷。由于重測信度法需要對同一樣本試測兩次,被調查者容易受到各種事件、活動和他人的影響,而且間隔時間長短也有一定限制,因此在實施中有一定困難。
復本信度法:讓同一組被調查者一次填答兩份問卷復本,計算兩個復本的相關系數。復本信度屬于等值系數。復本信度法要求兩個復本除表述方式不同外,在內容、格式、難度和對應題項的提問方向等方面要完全一致,而在實際調查中,很難使調查問卷達到這種要求,因此采用這種方法者較少。
折半信度法:折半信度法是將調查項目分為兩半,計算兩半得分的相關系數,進而估計整個量表的信度。折半信度屬于內在一致性系數,測量的是兩半題項得分間的一致性。這種方法一般不適用于事實式問卷(如年齡與性別無法相比),常用于態度、意見式問卷的信度分析。在問卷調查中,態度測量最常見的形式是5級李克特(Likert)量表(李克特量表(Likert scale)是屬評分加總式量表最常用的一種,屬同一構念的這些項目是用加總方式來計分,單獨或個別項目是無意義的。它是由美國社會心理學家李克特于1932年在原有的總加量表基礎上改進而成的。該量表由一組陳述組成,每一陳述有"非常同意"、"同意"、"不一定"、"不同意"、"非常不同意"五種回答,分別記為5、4、3、2、1,每個被調查者的態度總分就是他對各道題的回答所得分數的加總,這一總分可說明他的態度強弱或他在這一量表上的不同狀態。)。進行折半信度分析時,如果量表中含有反意題項,應先將反意題項的得分作逆向處理,以保證各題項得分方向的一致性,然后將全部題項按奇偶或前后分為盡可能相等的兩半,計算二者的相關系數(rhh,即半個量表的信度系數),最后用斯皮爾曼-布朗(Spearman-Brown)公式:求出整個量表的信度系數(ru)。
α信度系數法:Cronbach
α信度系數是目前最常用的信度系數,其公式為:
α=(k/(k-1))*(1-(∑Si^2)/ST^2)
其中,K為量表中題項的總數, Si^2為第i題得分的題內方差, ST^2為全部題項總得分的方差。從公式中可以看出,α系數評價的是量表中各題項得分間的一致性,屬于內在一致性系數。這種方法適用于態度、意見式問卷(量表)的信度分析。
總量表的信度系數最好在0.8以上,0.7-0.8之間可以接受;分量表的信度系數最好在0.7以上,0.6-0.7還可以接受。Cronbach 's alpha系數如果在0.6以下就要考慮重新編問卷。
檢査測量的可信度,例如調查問卷的真實性。
分類
外在信度:不同時間測量時量表的一致性程度,常用方法重測信度。
內在信度:每個量表是否測量到單一的概念,同時組成兩表的內在體項一致性如何,常用方法分半信度。
Part6 列聯表分析
列聯表是觀測數據按兩個或更多屬性(定性變量)分類時所列出的頻數表。
簡介
一般,若總體中的個體可按兩個屬性A、B分類,A有r個等級A1,A2,…,Ar,B有c個等級B1,B2,…,Bc,從總體中抽取大小為n的樣本,設其中有nij個個體的屬性屬于等級Ai和Bj,nij稱為頻數,將r×c個nij排列為一個r行c列的二維列聯表,簡稱r×c表。若所考慮的屬性多于兩個,也可按類似的方式作出列聯表,稱為多維列聯表。
列聯表又稱交互分類表,所謂交互分類,是指同時依據兩個變量的值,將所研究的個案分類。交互分類的目的是將兩變量分組,然后比較各組的分布狀況,以尋找變量間的關系。
用于分析離散變量或定型變量之間是否存在相關。
列聯表分析的基本問題是,判明所考察的各屬性之間有無關聯,即是否獨立。如在前例中,問題是:一個人是否色盲與其性別是否有關?在r×с表中,若以pi、pj和pij分別表示總體中的個體屬于等級Ai,屬于等級Bj和同時屬于Ai、Bj的概率(pi,pj稱邊緣概率,pij稱格概率),“A、B兩屬性無關聯”的假設可以表述為H0:pij=pi·pj,(i=1,2,…,r;j=1,2,…,с),未知參數pij、pi、pj的最大似然估計(見點估計)分別為行和及列和(統稱邊緣和)。
n為樣本大小。根據K.皮爾森(1904)的擬合優度檢驗或似然比檢驗(見假設檢驗),當h0成立,且一切pi>0和pj>0時,統計量的漸近分布是自由度為(r-1)(с-1) 的Ⅹ分布,式中Eij=(ni·nj)/n稱為期望頻數。當n足夠大,且表中各格的Eij都不太小時,可以據此對h0作檢驗:若Ⅹ值足夠大,就拒絕假設h0,即認為A與B有關聯。在前面的色覺問題中,曾按此檢驗,判定出性別與色覺之間存在某種關聯。
需要注意
若樣本大小n不是很大,則上述基于漸近分布的方法就不適用。對此,在四格表情形,R.A.費希爾(1935)提出了一種適用于所有n的精確檢驗法。其思想是在固定各邊緣和的條件下,根據超幾何分布(見概率分布),可以計算觀測頻數出現任意一種特定排列的條件概率。把實際出現的觀測頻數排列,以及比它呈現更多關聯跡象的所有可能排列的條件概率都算出來并相加,若所得結果小于給定的顯著性水平,則判定所考慮的兩個屬性存在關聯,從而拒絕h0。
對于二維表,可進行卡方檢驗,對于三維表,可作Mentel-Hanszel分層分析。
列聯表分析還包括配對計數資料的卡方檢驗、行列均為順序變量的相關檢驗。
Part7 相關分析
研究現象之間是否存在某種依存關系,對具體有依存關系的現象探討相關方向及相關程度。 單相關:兩個因素之間的相關關系叫單相關,即研究時只涉及一個自變量和一個因變量; 復相關:三個或三個以上因素的相關關系叫復相關,即研究時涉及兩個或兩個以上的自變量和因變量相關; 偏相關:在某一現象與多種現象相關的場合,當假定其他變量不變時,其中兩個變量之間的相關關系稱為偏相關。
Part8 方差分析
使用條件:各樣本須是相互獨立的隨機樣本;各樣本來自正態分布總體;各總體方差相等。
分類
單因素方差分析:一項試驗只有一個影響因素,或者存在多個影響因素時,只分析一個因素與響應變量的關系
多因素有交互方差分析:一頊實驗有多個影響因素,分析多個影響因素與響應變量的關系,同時考慮多個影響因素之間的關系
多因素無交互方差分析:分析多個影響因素與響應變量的關系,但是影響因素之間沒有影響關系或忽略影響關系
協方差分祈:傳統的方差分析存在明顯的弊端,無法控制分析中存在的某些隨機因素,使之影響了分祈結果的準確度。協方差分析主要是在排除了協變量的影響后再對修正后的主效應進行方差分析,是將線性回歸與方差分析結合起來的一種分析方法。
Part9 回歸分析
分類
一元線性回歸分析:只有一個自變量X與因變量Y有關,X與Y都必須是連續型變量,因變量y或其殘差必須服從正態分布。
多元線性回歸分析
使用條件:分析多個自變量與因變量Y的關系,X與Y都必須是連續型變量,因變量y或其殘差必須服從正態分布 。
殘差檢驗:觀測值與估計值的差值要艱從正態分布
強影響點判斷:尋找方式一般分為標準誤差法、Mahalanobis距離法
共線性診斷
診斷方式:容忍度、方差擴大因子法(又稱膨脹系數VIF)、特征根判定法、條件指針CI、方差比例
處理方法:增加樣本容量或選取另外的回歸如主成分回歸、嶺回歸等
變呈篩選方式:選擇最優回歸方程的變里篩選法包括全橫型法(CP法)、逐步回歸法,向前引入法和向后剔除法
橫型診斷方法
Logistic回歸分析
線性回歸模型要求因變量是連續的正態分布變里,且自變量和因變量呈線性關系,而Logistic回歸模型對因變量的分布沒有要求,一般用于因變量是離散時的情況
分類:Logistic回歸模型有條件與非條件之分,條件Logistic回歸模型和非條件Logistic回歸模型的區別在于參數的估計是否用到了條件概率。
其他回歸方法
非線性回歸、有序回歸、Probit回歸、加權回歸等
Part10 聚類分析
聚類與分類的不同在于,聚類所要求劃分的類是未知的。
聚類是將數據分類到不同的類或者簇這樣的一個過程,所以同一個簇中的對象有很大的相似性,而不同簇間的對象有很大的相異性。
從統計學的觀點看,聚類分析是通過數據建模簡化數據的一種方法。傳統的統計聚類分析方法包括系統聚類法、分解法、加入法、動態聚類法、有序樣品聚類、有重疊聚類和模糊聚類等。采用k-均值、k-中心點等算法的聚類分析工具已被加入到許多著名的統計分析軟件包中,如SPSS、SAS等。
從機器學習的角度講,簇相當于隱藏模式。聚類是搜索簇的無監督學習過程。與分類不同,無監督學習不依賴預先定義的類或帶類標記的訓練實例,需要由聚類學習算法自動確定標記,而分類學習的實例或數據對象有類別標記。聚類是觀察式學習,而不是示例式的學習。
聚類分析是一種探索性的分析,在分類的過程中,人們不必事先給出一個分類的標準,聚類分析能夠從樣本數據出發,自動進行分類。聚類分析所使用方法的不同,常常會得到不同的結論。不同研究者對于同一組數據進行聚類分析,所得到的聚類數未必一致。
從實際應用的角度看,聚類分析是數據挖掘的主要任務之一。而且聚類能夠作為一個獨立的工具獲得數據的分布狀況,觀察每一簇數據的特征,集中對特定的聚簇集合作進一步地分析。聚類分析還可以作為其他算法(如分類和定性歸納算法)的預處理步驟。
定義
依據研究對象(樣品或指標)的特征,對其進行分類的方法,減少研究對象的數目。
各類事物缺乏可靠的歷史資料,無法確定共有多少類別,目的是將性質相近事物歸入一類。
各指標之間具有一定的相關關系。
聚類分析(cluster analysis)是一組將研究對象分為相對同質的群組(clusters)的統計分析技術。聚類分析區別于分類分析(classification analysis) ,后者是有監督的學習。
變量類型:定類變量、定量(離散和連續)變量
樣本個體或指標變量按其具有的特性進行分類,尋找合理的度量事物相似性的統計量。 性質分類
Q型聚類分析:對樣本進行分類處理,又稱樣本聚類分祈使用距離系數作為統計量衡量相似度,如歐式距離、極端距離、絕對距離等
R型聚類分析:對指標進行分類處理,又稱指標聚類分析使用相似系數作為統計量衡量相似度,相關系數、列聯系數等
方法分類
系統聚類法:適用于小樣本的樣本聚類或指標聚類,一般用系統聚類法來聚類指標,又稱分層聚類
逐步聚類法:適用于大樣本的樣本聚類
其他聚類法:兩步聚類、K均值聚類等
Part11 判別分析
判別分析:根據已掌握的一批分類明確的樣品建立判別函數,使產生錯判的事例最少,進而對給定的一個新樣品,判斷它來自哪個總體。
與聚類分析區別
聚類分析可以對樣本逬行分類,也可以對指標進行分類;而判別分析只能對樣本
聚類分析事先不知道事物的類別,也不知道分幾類;而判別分析必須事先知道事物的類別,也知道分幾類
聚類分析不需要分類的歷史資料,而直接對樣本進行分類;而判別分析需要分類歷史資料去建立判別函數,然后才能對樣本進行分類
分類
Fisher判別分析法
以距離為判別準則來分類,即樣本與哪個類的距離最短就分到哪一類,適用于兩類判別;
以概率為判別準則來分類,即樣本屬于哪一類的概率最大就分到哪一類,適用于多類判別。
BAYES判別分析法
BAYES判別分析法比FISHER判別分析法更加完善和先進,它不僅能解決多類判別分析,而且分析時考慮了數據的分布狀態,所以一般較多使用;
Part12 主成分分析
主成分分析(Principal Component Analysis,PCA), 是一種統計方法。通過正交變換將一組可能存在相關性的變量轉換為一組線性不相關的變量,轉換后的這組變量叫主成分。
在實際課題中,為了全面分析問題,往往提出很多與此有關的變量(或因素),因為每個變量都在不同程度上反映這個課題的某些信息。
主成分分析首先是由K.皮爾森(Karl Pearson)對非隨機變量引入的,爾后H.霍特林將此方法推廣到隨機向量的情形。信息的大小通常用離差平方和或方差來衡量。
將彼此梠關的一組指標變適轉化為彼此獨立的一組新的指標變量,并用其中較少的幾個新指標變量就能綜合反應原多個指標變量中所包含的主要信息。
原理
在用統計分析方法研究多變量的課題時,變量個數太多就會增加課題的復雜性。人們自然希望變量個數較少而得到的信息較多。在很多情形,變量之間是有一定的相關關系的,當兩個變量之間有一定相關關系時,可以解釋為這兩個變量反映此課題的信息有一定的重疊。主成分分析是對于原先提出的所有變量,將重復的變量(關系緊密的變量)刪去多余,建立盡可能少的新變量,使得這些新變量是兩兩不相關的,而且這些新變量在反映課題的信息方面盡可能保持原有的信息。
設法將原來變量重新組合成一組新的互相無關的幾個綜合變量,同時根據實際需要從中可以取出幾個較少的綜合變量盡可能多地反映原來變量的信息的統計方法叫做主成分分析或稱主分量分析,也是數學上用來降維的一種方法。
缺點
在主成分分析中,我們首先應保證所提取的前幾個主成分的累計貢獻率達到一個較高的水平(即變量降維后的信息量須保持在一個較高水平上),其次對這些被提取的主成分必須都能夠給出符合實際背景和意義的解釋(否則主成分將空有信息量而無實際含義)。
主成分的解釋其含義一般多少帶有點模糊性,不像原始變量的含義那么清楚、確切,這是變量降維過程中不得不付出的代價。因此,提取的主成分個數m通常應明顯小于原始變量個數p(除非p本身較小),否則維數降低的“利”可能抵不過主成分含義不如原始變量清楚的“弊”。
Part13 因子分析
一種旨在尋找隱藏在多變量數據中、無法直接觀察到卻影響或支配可測變量的潛在因子、并估計潛在因子對可測變量的影響程度以及潛在因子之間的相關性的一種多元統計分析方法。
與主成分分析比較
相同:都能夠起到治理多個原始變量內在結構關系的作用
不同:主成分分析重在綜合原始變適的信息.而因子分析重在解釋原始變量間的關系,是比主成分分析更深入的一種多元統計方法
用途
減少分析變量個數
通過對變量間相關關系探測,將原始變量進行分類
Part14 時間序列分析
動態數據處理的統計方法,研究隨機數據序列所遵從的統計規律,以用于解決實際問題;時間序列通常由4種要素組成:趨勢、季節變動、循環波動和不規則波動。
主要方法
移動平均濾波與指數平滑法、ARIMA橫型、量ARIMA橫型、ARIMAX模型、向呈自回歸橫型、ARCH族模型。
時間序列是指同一變量按事件發生的先后順序排列起來的一組觀察值或記錄值。構成時間序列的要素有兩個:其一是時間,其二是與時間相對應的變量水平。實際數據的時間序列能夠展示研究對象在一定時期內的發展變化趨勢與規律,因而可以從時間序列中找出變量變化的特征、趨勢以及發展規律,從而對變量的未來變化進行有效地預測。
時間序列的變動形態一般分為四種:長期趨勢變動,季節變動,循環變動,不規則變動。
時間序列預測法的應用
系統描述:根據對系統進行觀測得到的時間序列數據,用曲線擬合方法對系統進行客觀的描述;
系統分析:當觀測值取自兩個以上變量時,可用一個時間序列中的變化去說明另一個時間序列中的變化,從而深入了解給定時間序列產生的機理;
預測未來:一般用ARMA模型擬合時間序列,預測該時間序列未來值;
決策和控制:根據時間序列模型可調整輸入變量使系統發展過程保持在目標值上,即預測到過程要偏離目標時便可進行必要的控制。
特點
假定事物的過去趨勢會延伸到未來;預測所依據的數據具有不規則性;撇開了市場發展之間的因果關系。
1、時間序列分析預測法是根據市場過去的變化趨勢預測未來的發展,它的前提是假定事物的過去會同樣延續到未來。事物的現實是歷史發展的結果,而事物的未來又是現實的延伸,事物的過去和未來是有聯系的。市場預測的時間序列分析法,正是根據客觀事物發展的這種連續規律性,運用過去的歷史數據,通過統計分析,進一步推測市場未來的發展趨勢。市場預測中,事物的過去會同樣延續到未來,其意思是說,市場未來不會發生突然跳躍式變化,而是漸進變化的。 時間序列分析預測法的哲學依據,是唯物辯證法中的基本觀點,即認為一切事物都是發展變化的,事物的發展變化在時間上具有連續性,市場現象也是這樣。市場現象過去和現在的發展變化規律和發展水平,會影響到市場現象未來的發展變化規律和規模水平;市場現象未來的變化規律和水平,是市場現象過去和現在變化規律和發展水平的結果。 需要指出,由于事物的發展不僅有連續性的特點,而且又是復雜多樣的。因此,在應用時間序列分析法進行市場預測時應注意市場現象未來發展變化規律和發展水平,不一定與其歷史和現在的發展變化規律完全一致。隨著市場現象的發展,它還會出現一些新的特點。因此,在時間序列分析預測中,決不能機械地按市場現象過去和現在的規律向外延伸。必須要研究分析市場現象變化的新特點,新表現,并且將這些新特點和新表現充分考慮在預測值內。這樣才能對市場現象做出既延續其歷史變化規律,又符合其現實表現的可靠的預測結果。 2、時間序列分析預測法突出了時間因素在預測中的作用,暫不考慮外界具體因素的影響。時間序列在時間序列分析預測法處于核心位置,沒有時間序列,就沒有這一方法的存在。雖然,預測對象的發展變化是受很多因素影響的。但是,運用時間序列分析進行量的預測,實際上將所有的影響因素歸結到時間這一因素上,只承認所有影響因素的綜合作用,并在未來對預測對象仍然起作用,并未去分析探討預測對象和影響因素之間的因果關系。因此,為了求得能反映市場未來發展變化的精確預測值,在運用時間序列分析法進行預測時,必須將量的分析方法和質的分析方法結合起來,從質的方面充分研究各種因素與市場的關系,在充分分析研究影響市場變化的各種因素的基礎上確定預測值。 需要指出的是,時間序列預測法因突出時間序列暫不考慮外界因素影響,因而存在著預測誤差的缺陷,當遇到外界發生較大變化,往往會有較大偏差,時間序列預測法對于中短期預測的效果要比長期預測的效果好。因為客觀事物,尤其是經濟現象,在一個較長時間內發生外界因素變化的可能性加大,它們對市場經濟現象必定要產生重大影響。如果出現這種情況,進行預測時,只考慮時間因素不考慮外界因素對預測對象的影響,其預測結果就會與實際狀況嚴重不符。
Part15 生存分析
用來研究生存時間的分布規律以及生存時間和相關因索之間關系的一種統計分析方法
包含內容
描述生存過程,即研究生存時間的分布規律
比較生存過程,即研究兩組或多組生存時間的分布規律,并進行比較
分析危險因素,即研究危險因素對生存過程的影響
建立數學模型,即將生存時間與相關危險因素的依存關系用一個數學式子表示出來。
方法
統計描述:包括求生存時間的分位數、中數生存期、平均數、生存函數的估計、判斷生存時間的圖示法,不對所分析的數據作出任何統計推斷結論
非參數檢驗:檢驗分組變量各水平所對應的生存曲線是否一致,對生存時間的分布沒有要求,并且檢驗危險因素對生存時間的影響。
乘積極限法(PL法)
壽命表法(LT法)
半參數橫型回歸分析:在特定的假設之下,建立生存時間隨多個危險因素變化的回歸方程,這種方法的代表是Cox比例風險回歸分析法
參數模型回歸分析:已知生存時間服從特定的參數橫型時,擬合相應的參數模型,更準確地分析確定變量之間的變化規律
Part16 典型相關分析
相關分析一般分析兩個變量之間的關系,而典型相關分析是分析兩組變量(如3個學術能力指標與5個在校成績表現指標)之間相關性的一種統計分析方法。
典型相關分析的基本思想和主成分分析的基本思想相似,它將一組變量與另一組變量之間單變量的多重線性相關性研究轉化為對少數幾對綜合變量之間的簡單線性相關性的研究,并且這少數幾對變量所包含的線性相關性的信息幾乎覆蓋了原變量組所包含的全部相應信息。
Part17 R0C分析
R0C曲線是根據一系列不同的二分類方式(分界值或決定閾).以真陽性率(靈敏度)為縱坐標,假陽性率(1-特異度)為橫坐標繪制的曲線。
用途
R0C曲線能很容易地査出任意界限值時的對疾病的識別能力;
選擇最佳的診斷界限值。R0C曲線越靠近左上角,試驗的準確性就越高;
兩種或兩種以上不同診斷試驗對疾病識別能力的比較,一股用R0C曲線下面積反映診斷系統的準確性。
Part18 其他分析方法
多重響應分析、距離分祈、項目分祈、對應分祈、決策樹分析、神經網絡、系統方程、蒙特卡洛模擬等。
決策樹分析與隨機森林
盡管有剪枝等等方法,一棵樹的生成肯定還是不如多棵樹,因此就有了隨機森林,解決決策樹泛化能力弱的缺點。(可以理解成三個臭皮匠頂過諸葛亮) 1、決策樹(Decision Tree):是在已知各種情況發生概率的基礎上,通過構成決策樹來求取凈現值的期望值大于等于零的概率,評價項目風險,判斷其可行性的決策分析方法,是直觀運用概率分析的一種圖解法。由于這種決策分支畫成圖形很像一棵樹的枝干,故稱決策樹。在機器學習中,決策樹是一個預測模型,他代表的是對象屬性與對象值之間的一種映射關系。Entropy = 系統的凌亂程度,使用算法ID3, C4.5和C5.0生成樹算法使用熵。這一度量是基于信息學理論中熵的概念。 決策樹是一種樹形結構,其中每個內部節點表示一個屬性上的測試,每個分支代表一個測試輸出,每個葉節點代表一種類別。 2、分類樹(決策樹):是一種十分常用的分類方法。他是一種監督學習,所謂監督學習就是給定一堆樣本,每個樣本都有一組屬性和一個類別,這些類別是事先確定的,那么通過學習得到一個分類器,這個分類器能夠對新出現的對象給出正確的分類。這樣的機器學習就被稱之為監督學習。
優點:決策樹易于理解和實現,人們在在學習過程中不需要使用者了解很多的背景知識,這同時是它的能夠直接體現數據的特點,只要通過解釋后都有能力去理解決策樹所表達的意義。
對于決策樹,數據的準備往往是簡單或者是不必要的,而且能夠同時處理數據型和常規型屬性,在相對短的時間內能夠對大型數據源做出可行且效果良好的結果。易于通過靜態測試來對模型進行評測,可以測定模型可信度;如果給定一個觀察的模型,那么根據所產生的決策樹很容易推出相應的邏輯表達式。
缺點:對連續性的字段比較難預測;對有時間順序的數據,需要很多預處理的工作;當類別太多時,錯誤可能就會增加的比較快;一般的算法分類的時候,只是根據一個字段來分類。
-
數據
+關注
關注
8文章
7263瀏覽量
92340 -
數據分析
+關注
關注
2文章
1474瀏覽量
35202
原文標題:統計學派 18 種經典數據分析方法!
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
數據分析需要的技能
成為Python數據分析師,需要掌握哪些技能
成為Python數據分析師,需要掌握哪些技能
數據分析、數據挖掘和數據統計的概念與主要區別及其舉例分析
數據分析師應當了解的五個統計基本概念





 工商網監
工商網監

評論