 BP神經網絡算法 BP算法之一種直觀的解釋
BP神經網絡算法 BP算法之一種直觀的解釋
0. 前言
之前上模式識別課程的時候,老師也講過 MLP 的 BP 算法, 但是 ppt 過得太快,只有一個大概印象。后來課下自己也嘗試看了一下stanford deep learning的 wiki, 還是感覺似懂非懂,不能形成一個直觀的思路。趁著這個機會,我再次 revisit 一下。
1. LMS 算法
故事可以從線性 model 說起(順帶復習一下)~在線性 model 里面,常見的有感知機學習算法、 LMS 算法等。感知機算法的損失函數是誤分類點到 Target 平面的總距離,直觀解釋如下:當一個實例點被誤分,則調整 w, b 的值,使得分離超平面向該誤分類點的一側移動,以減少該誤分類點與超平面的距離,在 Bishop 的 PRML一書中,有一個非常優雅的圖展現了這個過程。但是了解了 MLP 的 BP 算法之后,感覺這個算法與 LMS 有點相通之處。雖然從名字上 MLP 叫做多層感知機,感知機算法是單層感知機。
LMS (Least mean squares) 算法介紹比較好的資料是 Andrew Ng cs229 的Lecture Notes。假設我們的線性 model 是這樣的:
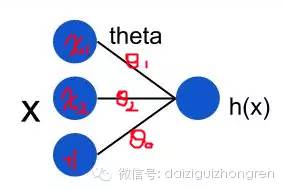
在上面這個模型中,用公式可以表達成:
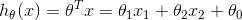
如何判斷模型的好壞呢?損失函數定義為輸出值 h(x) 與目標值 y 之間的“二乘”:
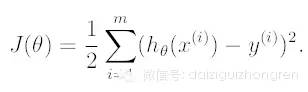
對偏導進行求解,可以得到:
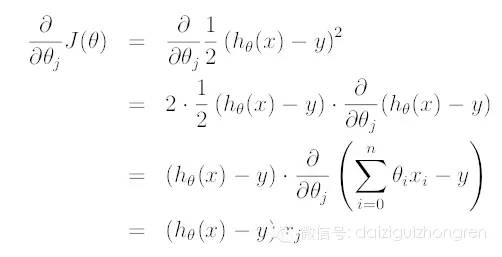
如果要利用 gradient descent 的方法找到一個好的模型,即一個合適的 theta 向量,迭代的公式為:
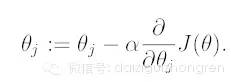
所以,對于一個第 i 個單獨的訓練樣本來說,我們的第 j 個權重更新公式是:
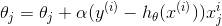
這個更新的規則也叫做 Widrow-Hoff learning rule, 從上到下推導下來只有幾步,沒有什么高深的理論,但是,仔細觀察上面的公式,就可以發現幾個 natural and intuitive 的特性。
首先,權重的更新是跟 y - h(x) 相關的,如果訓練樣本中預測值與 y 非常接近,表示模型趨于完善,權重改變小。反之,如果預測值與 y 距離比較遠,說明模型比較差,這時候權重變化就比較大了。
權重的變化還與 xi 也就是輸入節點的值相關。也就是說,在同一次 train 中,由于 y - h(x) 相同, 細線上的變化與相應的輸入節點 x 的大小是成正比的(參考最上面的模型圖)。這中間體現的直觀印象就是:殘差的影響是按照 xi 分配到權重上去滴,這里的殘差就是 h(x) - y。
LMS 算法暫時先講到這里,后面的什么收斂特性、梯度下降之類的有興趣可以看看 Lecture Notes。
2. MLP 與 BP 算法
前面我們講過logistic regression, logistic regression 本質上是線性分類器,只不過是在線性變換后通過 sigmoid 函數作非線性變換。而神經網絡 MLP 還要在這個基礎上加上一個新的nonlinear function, 為了討論方便,這里的 nonlinear function 都用 sigmoid 函數,并且損失函數忽略 regulization term, 那么, MLP 的結構就可以用下面這個圖來表示:
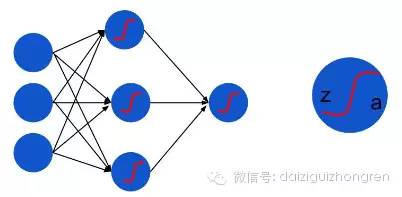
z: 非線性變換之前的節點值,實際上是前一層節點的線性變換
a: 非線性變換之后的 activation 值
a=f(z): 這里就是 sigmoid function
現在我們要利用 LMS 中的想法來對這個網絡進行訓練。
假設在某一個時刻,輸入節點接受一個輸入, MLP 將數據從左到右處理得到輸出,這時候產生了殘差。在第一小節中,我們知道, LMS 殘差等于 h(x) - y。MLP 的最后一層和 LMS 線性分類器非常相似,我們不妨先把最后一層的權重更新問題解決掉。在這里輸出節點由于增加了一個非線性函數,殘差的值比 LMS 的殘差多了一個求導 (實際上是數學上 chain rule 的推導):
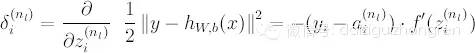
得到殘差,根據之前猜想出來的規律( - -!), 殘差的影響是按照左側輸入節點的 a 值大小按比例分配到權重上去的,所以呢,就可以得到:
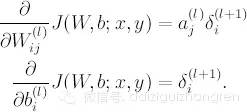
如果乘以一個 learning rate, 這就是最后一層的權重更新值。
我們在想,要是能得到中間隱層節點上的殘差,問題就分解成幾個我們剛剛解決的問題。關鍵是:中間隱層的殘差怎么算?
實際上就是按照權重與殘差的乘積返回到上一層。完了之后還要乘以非線性函數的導數( again it can be explained by chain rule):
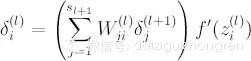
得到隱層的殘差,我們又可以得到前一層權重的更新值了。這樣問題就一步一步解決了。
最后我們發現,其實咱們不用逐層將求殘差和權值更新交替進行,可以這樣:
先從右到左把每個節點的殘差求出來(數學上表現為反向傳導過程)
然后再求權重的更新值
更新權重
Q:這是在 Ng 教程中的計算過程, 但是在有些資料中,比如參考資料 [2],殘差和權值更新是逐層交替進行的,那么,上一層的殘差等于下一層的殘差乘以更新后的權重,明顯,Ng 的教程是乘以沒有更新的權重,我覺得后者有更好的數學特性,期待解疑!
用一張粗略的靜態圖表示殘差的反向傳播:
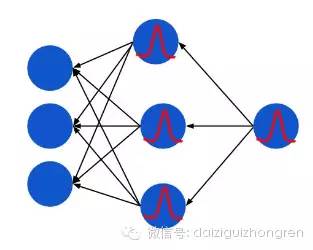
紅色的曲線就是對 sigmoid function 的求導,和高斯分布非常相似。
用一張動態圖表示前向(FP)和后向(BP)傳播的全過程:
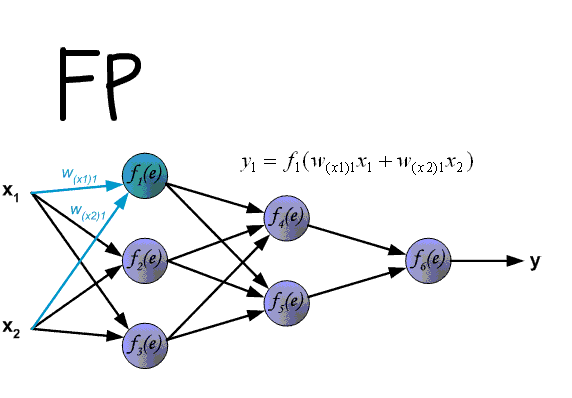
OK,現在 BP 算法有了一個直觀的思路,下面,將從反向傳導的角度更加深入地分析一下 BP 算法。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100720 -
變換器
+關注
關注
17文章
2097瀏覽量
109272 -
LMS算法
+關注
關注
1文章
19瀏覽量
10252 -
線性分類器
+關注
關注
0文章
3瀏覽量
1428 -
MLP
+關注
關注
0文章
57瀏覽量
4241
原文標題:[干貨]BP 算法之一種直觀的解釋
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何設計BP神經網絡圖像壓縮算法?
一種改進的自適應遺傳算法優化BP神經網絡






 工商網監
工商網監
評論