 為什么Uber的底層存儲從Postgres換成MySQL了呢?
為什么Uber的底層存儲從Postgres換成MySQL了呢?
來源:www.infoq.cn/article/underlying -storage-of-uber-change-from-mysql -to-postgres
背景
早期的 Uber 后臺軟件由 Python 寫成,數據存儲使用 Postgres。后期隨著業務的飛速發展后臺架構也變化巨大,演進成了微服務加數據平臺。數據存儲也由 Postgres 變成了 Schemalesshttps://eng.uber.com/schemaless-part-one/——Uber 自主研發的以 MySQL 做為底層的高可用數據庫。Uber 的數據庫主要存儲的是 Trip 數據,就是一個叫車訂單從下單起,到上車、下車、付費等的全過程跟蹤及處理。從 2014 年初起,由于業務增長迅猛,Uber 的原有基礎架構已經無法繼續支撐業務。改進的項目花了將近一年時間。
對于新的數據庫存儲系統,Uber 的主要關鍵需求是:
要有能力通過增加服務器而線性地增加容量。增加服務器不但要增加可用的硬盤容量,還要減少系統的響應時間。
需要有寫緩沖能力,萬一持久化到數據庫失敗時,仍可以稍后重試。
需要通知下游依賴關系的方式,數據變更要能無損的通知出去。
需要二級索引。
系統要足夠健壯,可以支持 7*24 服務。
在調查對比了 Cassandra、Riak 和 MongoDB 等等之后,Uber 技術團隊沒有發現能完全滿足需求的現成解決方案。而再考慮到數據可靠性、對技術的把握能力等因素,他們決定自己開發一套數據庫管理系統——Schemaless,一個鍵值型存儲庫,可以存放 JSON 數據而無需嚴格的模式驗證,是完全的無模式風格。用 MySQL 作底層存儲,其中只有順序寫入,在 MySQL 主庫故障時支持寫入緩沖。并有一個數據變更通知的發布 - 訂閱功能(命名為 trigger),支持數據的全局索引。
Schemaless 的強大與簡單更多是因為我們在存儲節點中使用了 MySQL。Schemaless 本身是在 MySQL 之上相對較薄的一層,負責將路由請求發送給正確的數據庫。借助于 MySQL 第二索引及 InnoDB 的 BufferPool,Schemaless 的查詢性能很高。
寫入效率不高
數據主從復制效率不高
表損壞問題
難于升級到新版本
在 Postgres 的底層設計中,它的行數據是不可修改的,每個不可修改的行都叫做“元組”,每個唯一的元組都由一個唯一的 標志,ctid 也就實際指出了這個元組在磁盤上的物理偏移量。這樣對于一行修改過的數據來說,就會對應著在物理上有多個元組。表是有索引的,主鍵索引和第二索引都以 B 樹組織,都直接指向 ctid。
除了 ctid 之外還有一個關鍵字段 prev,它的默認值為 null,但對于有數據修改的記錄,新的元組里面的 prev 字段里存儲的就是舊元組的 ctid 值。
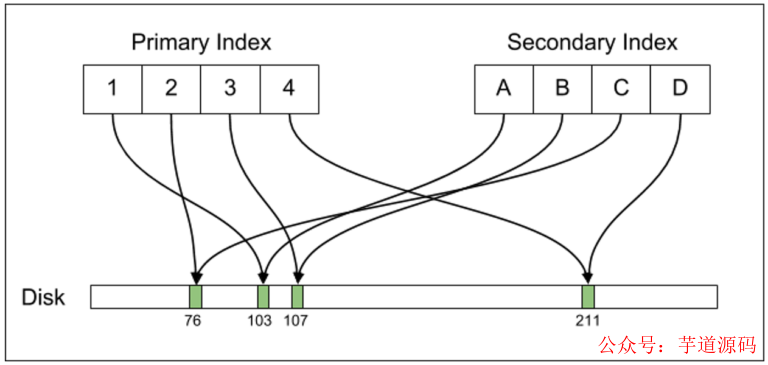
與 Postgres 相對應的是,MySQL 的 InnoDB 引擎主鍵索引和第二也都以 B 樹組織,但是索引指向的是主鍵,而主鍵才真正指向數據記錄。而且,InnoDB 的數據是可以修改的。兩者實現 MVCC 的機制不同,MySQL 依靠 UNDO 空間中的回滾段,而不是象Postgres 依靠在數據表空間對同一條數據保持多份。
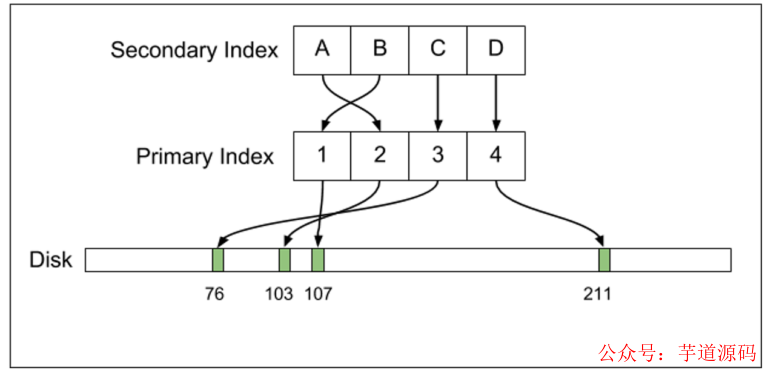
Postgres 和 InnoDB 都通過 WAL來保證數據可以在數據庫上安全寫入,但對于主從庫的數據復制實現原理并不同。Postgres 會直接把 WAL 發送到從庫上,讓從庫也執行 WAL 來復制數據。而 MySQL 則是發送 Binlog,在從庫上應用 Binlog。
由此,再來看看 Uber 對于 Postgres 有哪些不滿意:
寫放大
一般來說大家介意寫放大https://en.wikipedia.org/wiki/Write_amplification的問題是由于對SSD 磁盤的使用。SSD 磁盤是有壽命的,它的寫入次數是有限的(雖然數字很大)。這樣如果應用層只是想寫入少量數據而已,但數據落入磁盤時卻變大了許多倍,那大家就會比較介意了。比如你只是想寫入1K 的數據,可是最終卻有10K 數據落盤。
Postgres 的寫放大問題主要表現在對有索引的表進行數據更新上。因為 Postgres 的索引都是指向元組的 ctid,而元組又是不可更新的,所以當你更新一條記錄時,它會創建一個新的元組存入磁盤,并且要針對所有的索引,為每個索引都創建一條新記錄來指向新的元組,不管你更改的字段和這個索引有沒有關系。這樣對于 WAL 來說,Postgres 更改一條記錄操作會寫入新的完整記錄,再加上多條索引記錄。
「作者注」 :不過 MySQL 的 InnoDB 其實也是有寫放大問題的。InnoDB 是以數據頁的形式組織數據的,Linux 上默認數據頁的大小是 16K。這樣當你更改了一條記錄時,最終會把這條記錄所在的數據頁整頁刷回磁盤,設想一下你可能只是改了一個小字段,也許只有 4 個字節,可是最終卻會導致 16K 字節的寫入。
另外,Postgres 的這個設計也是有其好處的,它的第二索引直接指向元組的 ctid,這樣在讀取數據時效率就非常高。相對應地,通過 MySQL 的第二索引去讀數據會經歷“第二索引——主鍵——數據”的過程,MySQL 的讀效率不如 Postgres。這是一個經典的讀寫性能權衡問題,在此 Evan 沒有給出具體的數字讓我們體會他們的業務特征。
主從復制
Postgres 的寫放大問題最終也反應在了主從復制的日志傳輸上,變成了流量放大問題。Postgres 的主從復制傳輸的是 WAL 日志,所以對于一條數據更新來說,它要傳輸新的數據,還要傳輸這張表上每一條索引修改的日志。這樣的流量放大在同一機房內還稍可接受,但對于跨機房的情況,傳輸速度和價格等問題讓 Uber 產生了顧慮。Uber 是有跨機房從庫的,一方面是容災,另一方面是 WAL 的備份,以備有時需要靠它來搭建新的從庫。
MySQL 的確沒有引起流量放大。MySQL 的主從復制依靠的是 Binlog,它只是記錄這條數據的修改,而不在乎這張表上到底有多少索引,所以可以認為與 Postgres 相比,它的 Binlog 是一種對數據修改的“邏輯”描述。MySQL 從庫上應用 Binlog 日志時,如果有第二索引涉及了改動的字段,那就更新第二索引,否則第二索引壓根不需要修改。而且,MySQL 有三種不同的 Binlog 格式,包含了不同數量的信息來供使用者選擇:
Statement:只傳輸 DML 的 SQL 語句,如:UPDATE users SET birth_year=770 WHERE id = 4。這種模式日志量最小,但在某些場景下和對某些字段來說容易出錯。
Row:對于更改了的數據,會把修改前和修改后的所有字段值都打印在 Binlog 中。這種模式日志量最大,但也最嚴謹,越來越多的公司在轉向這種日志格式。很多日志解析工具更是只工作在這種模式下。
Mixed:上面兩種的結合體,MySQL 會根據不同的語句來自行判斷。這種模式日志量居中。
數據損壞
Uber 使用 Postgres 9.2 時曾經因為一個 BUG 導致了很大的故障。當時由于硬件升級的原因他們做了主從切換,結果就引發了這個 BUG 導致各個從庫的數據全都亂掉了,而且還沒有辦法判斷哪個從庫的哪些數據是正確的或者亂的。最終他們確認了新的主庫上的數據全部正確后,用新主庫的數據把所有從庫數據全覆蓋了一遍,才算過了這一關。可是一朝被蛇咬十年怕井繩,他們最后用的版本仍是 Postgres 9.2,原因之一是不想再去踩別的版本的坑了。
「作者注」 :以這個作為拋棄 Postgres 的理由就太容易引起爭議、令人質疑 Uber 技術團隊的技術水平了。在社區的口碑中,Postgres 的穩定性恰恰是高于 MySQL 的,如果因為害怕碰上 Postgres 的 BUG 而轉用 MySQL,那……我們只好祝福 Uber 了。
從庫上的 MVCC 支持不好
Postgres 的從庫上并沒有真正的 MVCC,它的數據表空間、表空間文件內容和主庫是完全一樣的,在從庫上就是依次應用 WAL。可如果從庫上有一個正在進行中的事務的話,它就會擋住 WAL 的應用,從而導致看起來主從同步延遲很大。Postgres 實現了一個機制,如果某個業務程序的事務擋住同步線程太久的話,就直接將那個事務殺掉。所以如果在從庫上有一些比較大的事務在運行的話,你可能就會經常看見莫名其妙的主從同步就延遲了,也會看見自己的操作運行了一段時間就不知被誰殺掉了。并不是每個程序員都很熟悉數據庫的底層工作機制,所以這些現象會讓大家覺得很詭異。
「作者注」 :這一點的確是的。相比來說對于這個 Postgres 的復制過程,MySQL 的主從復制并不會殺死從庫上的事務。
Postgres 數據庫的升級
Postgres 的數據復制是物理級的,主從數據文件完全一致,所以不能支持不同版本之間的主從復制,比如主庫使用 9.2 從庫使用 9.3,或者相反,等等。Uber 最初使用的是 Postgres 9.1,他們成功的升級成了 9.2,但升級耗費了相當長的時間,再加上后來業務爆發式增長,讓他們再也沒能安排下一次升級。而且 Postgres 直到 9.4 之后才有了工具 pglogical來幫助減少升級耗時,可是 pglogical 又不在 Postgres 主分支里,讓使用舊版本的人無所適從。
「作者注」 :有消息 Postgres 的 WAL 日志也將變成邏輯型了,在這樣的功能推出之后,就可以支持不同版本間的數據復制了。
MySQL 的其他優點
除了上文所述的幾點,MySQL 還有幾個其他 Postgres 不具備的優點:
BufferPoolhttps://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html:雖然 Postgres 在內部有比較小的緩存,但和現在動輒幾百 G 的服務器內存比起來,它的緩存還是太小,對硬件利用率太低了。InnoDB 則有 BufferPool,可以同時用于寫緩沖和讀緩存,用 LRU 管理,大小可配,這樣就把硬件資源充分合理的利用起來了。
連接管理:MySQL 的連接管理是每個連接一個線程,每個線程消耗的資源都很有限,所以 MySQL 可以輕松支持 10000 個以上的連接。可是 Postgres 是每個連接一個進程的,進程之間通信和共享資源復雜,消耗資源嚴重,而且對多連接支持不好。Uber 的業務已經需要極大的增加數據庫連接數,Postgres 已經無法滿足需要。
Evan Klitzke 總結說:
在初期 Postgres 還是工作得很好的,但業務擴展時我們就碰上了非常嚴重的問題。現在我們還是在用著一些 Postgres 數據庫,但是主要的數據已經挪到了 Schemaless 上,有些特別的業務也用了 Cassandra 等 NoSQL 數據庫。我們現在用 MySQL 用得很好,我們也會寫更多的博客來分享更多關于 MySQL 在 Uber 的使用內容。
審核編輯:劉清
-
存儲器
+關注
關注
38文章
7484瀏覽量
163769 -
緩沖器
+關注
關注
6文章
1922瀏覽量
45473 -
python
+關注
關注
56文章
4793瀏覽量
84631 -
MYSQL數據庫
+關注
關注
0文章
96瀏覽量
9389 -
MVCC
+關注
關注
0文章
13瀏覽量
1465
原文標題:為什么Uber的底層存儲從Postgres換成MySQL了?
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MySQL數據庫索引的底層是怎么實現的
什么是Postgres?Postgres是什么意思
Uber為什么從Postgres遷移到MySQL
怎樣選擇存儲引擎?MySQL存儲引擎怎么樣?
MySQL數據庫:理解MySQL的性能優化、優化查詢

MySQL的底層原理和技術學習
如何使用WINDAQ MySQL存儲數據
Neon--AWS Aurora Postgres的無服務器開源替代品
GitHub底層數據庫無縫升級到MySQL 8.0的經驗





 工商網監
工商網監
評論