 打破端到端自動駕駛感知和規劃的耦合障礙!
打破端到端自動駕駛感知和規劃的耦合障礙!
0. 筆者個人體會
端到端自動駕駛一直是研究的重點和熱點,輸入RGB圖像或雷達點云,輸出自車的控制信號或運動規劃。但目前很多工作都是只做感知或者只做規劃,很重要的一個原因是端到端模型訓練時間太長了,而且最終學習到的控制信號也未見得多好。現有的教師-學生范式還可能產生很嚴重的Causal Confusion問題。
今天要為大家介紹的就是ICCV 2023開源的工作DriveAdapter,解決了自動駕駛感知和規劃的耦合障礙,來源于上交和上海AI Lab,這里不得不慨嘆AI Lab實在高產,剛剛用UniAD拿了CVPR的Best Paper就又產出了新成果。
DriveAdapter的做法是,用學生模型來感知,用教師模型來規劃,并且引入新的適配器和特征對齊損失來打破感知和規劃的耦合障礙!想法很新穎!
1. 問題引出
最直接的端到端自動駕駛框架,就是輸入RGB圖,利用強化學習直接輸出控制信號(a)。但這樣做效率太低了,在使用預訓練模型的情況下甚至都需要20天才能收斂!
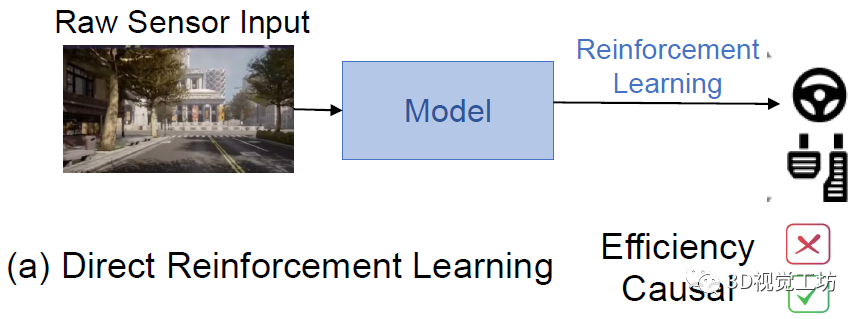
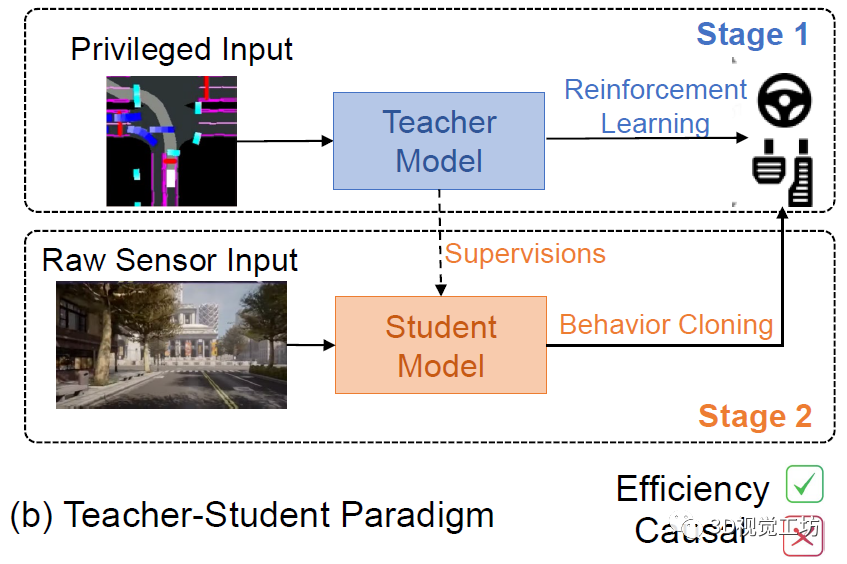
現在主流框架基本都是教師-學生模型,也就是說首先用強化學習訓練一個復雜的教師模型,然后用原始的傳感器數據讓小模型去模仿教師模型的行為(Behavior Cloning)。這種范式的效率非常高!但是仍然有很大的問題,也就是由行為克隆引發的因果混淆問題(Causal Confusion)。這里也推薦「3D視覺工坊」新課程《深度剖析面向自動駕駛領域的車載傳感器空間同步(標定)》。
聽起來很繞口,那么這到底是個啥?
舉個簡單例子:
當車輛位于十字路口時,自車的路徑實際上應該是根據信號燈來決定的。但是在圖像上信號燈很小,周圍車輛很大。所以學生模型從教師學習到的實際情況很可能是:根據其他車輛的行為來規劃自車。那么如果自車處在路口第一輛車的位置,很有可能自車會永遠不動!
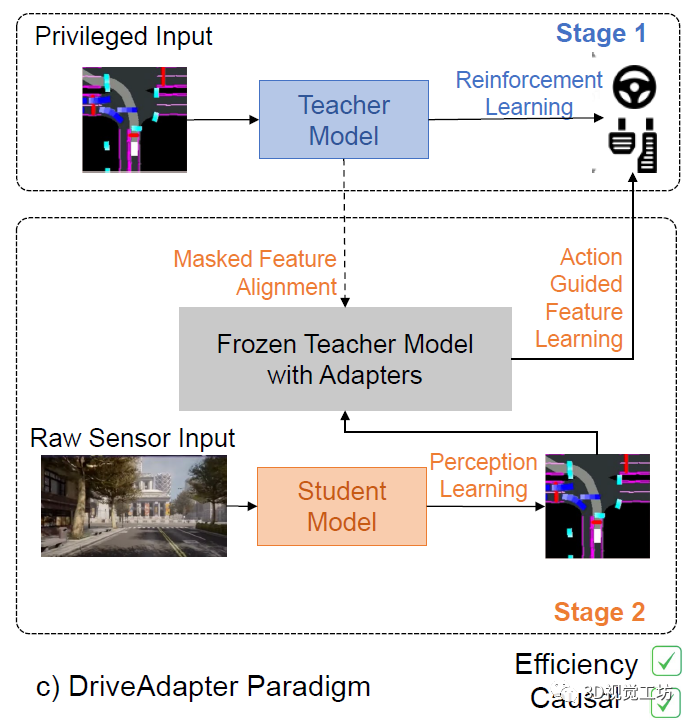
那么DriveAdapter這個方案打算怎么做呢?
簡單來說,它是解耦了學生和教師模型。學生負責進行感知,輸入RGB圖像,輸出BEV分割圖。然后BEV分割圖輸送給教師,進行自車的路徑規劃!
當然里面還有特別多的細節,下面我們一起來看具體的論文信息。
2. 論文信息
標題:DriveAdapter: Breaking the Coupling Barrier of Perception and Planning in End-to-End Autonomous Driving
作者:Xiaosong Jia, Yulu Gao, Li Chen, Junchi Yan, Patrick Langechuan Liu, Hongyang Li
機構:上海交通大學、上海AI Lab、北航、安克創新
原文鏈接:https://arxiv.org/abs/2308.00398
代碼鏈接:https://github.com/OpenDriveLab/DriveAdapter
3. 摘要
端到端的自動駕駛旨在構建一個以原始傳感器數據為輸入,直接輸出自車的規劃軌跡或控制信號的完全可微系統。最先進的方法通常遵循"教師-學生"范式。該模型使用權限信息(周圍智能體和地圖要素的真實情況)來學習駕駛策略。學生模型只具有獲取原始傳感器數據的權限,并對教師模型采集的數據進行行為克隆。通過在規劃學習過程中消除感知部分的噪聲,與那些耦合的工作相比,最先進的工作可以用更少的數據獲得更好的性能。
然而,在當前的教師-學生范式下,學生模型仍然需要從頭開始學習一個規劃頭,由于原始傳感器輸入的冗余和噪聲性質以及行為克隆的偶然混淆問題,這可能具有挑戰性。在這項工作中,我們旨在探索在讓學生模型更專注于感知部分的同時,直接采用強教師模型進行規劃的可能性。我們發現,即使配備了SOTA感知模型,直接讓學生模型學習教師模型所需的輸入也會導致較差的駕駛性能,這來自于預測的特權輸入與真實值之間的較大分布差距。
為此,我們提出了DriveAdapter,它在學生(感知)和教師(規劃)模塊之間使用具有特征對齊目標函數的適配器。此外,由于基于純學習的教師模型本身是不完美的,偶爾會破壞安全規則,我們針對那些不完美的教師特征提出了一種帶有掩碼的引導特征學習的方法,進一步將手工規則的先驗注入到學習過程中。DriveAdapter在多個基于CARLA的閉環仿真測試集上實現了SOTA性能。
4. 算法解析
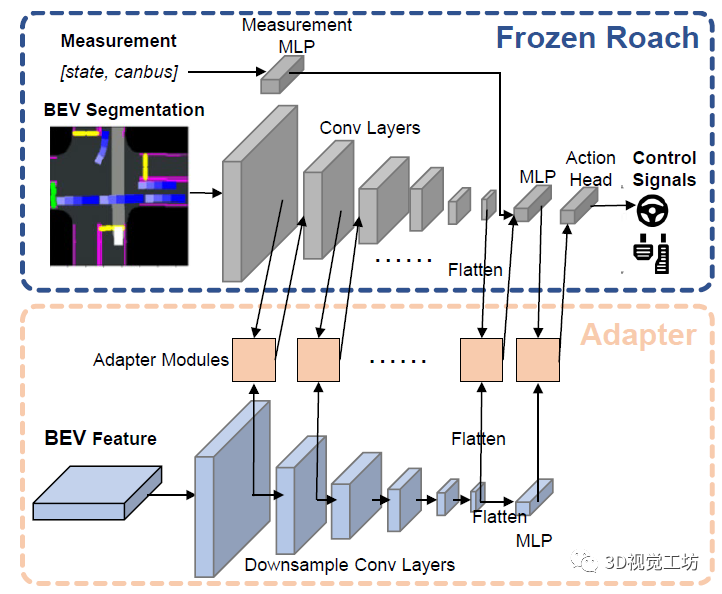
DriveAdapter整體的思路非常清晰,學生模型將原始傳感器數據作為輸入,并提取BEV特征以供BEV分割和適配器模塊使用。之后,預測的BEV分割圖被饋送到凍結的教師模型和適配器模塊中。最后,適配器模塊接收來自具有GT教師特征的監督,以及學生模型提供的BEV特征。對于教師模型引入規則的情況,對"對齊損失"應用掩碼,并且所有適配器模塊的監督來自動作損失的反向傳播。
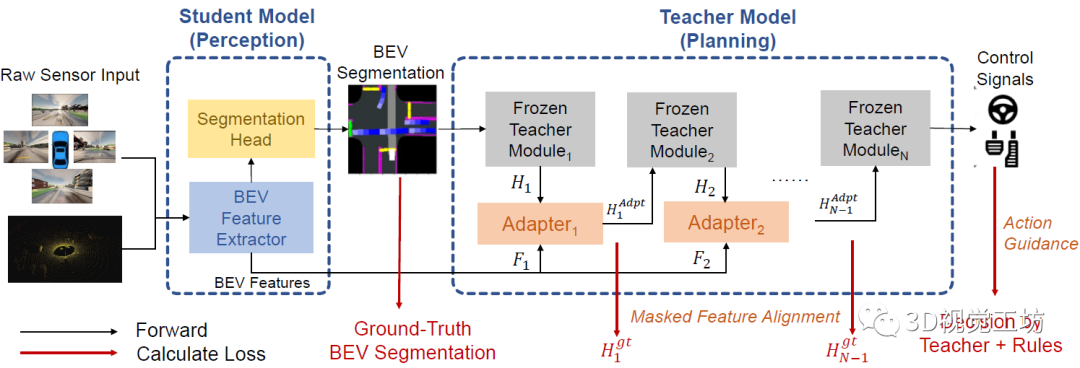
4.1 感知學習的學生模型
學生模型將4個相機圖像和1個雷達點云作為輸入,目的是生成BEV的語義分割圖。具體流程是,首先使用BEVFusion將原始傳感器數據轉換成2D的BEV特征,然后使用Mask2former執行語義分割。
但關鍵問題是,即使使用SOTA感知模塊,如果直接將預測的BEV分割饋送給教師模型,也并不會產生多好的預測和規劃效果。
這是因為啥呢?
首先就是語義分割的不準確問題。搞過語義分割的小伙伴肯定清楚,模型直接輸出的分割圖其實效果并不是太好,很多甚至需要經過復雜的后處理才可以使用,分割的路線、車輛和信號燈非常不準,直接用的話噪聲非常大。畢竟教師模型是用BEV分割的Ground Truth來訓練的,直接用學生模型輸出的BEV分割肯定是效果非常差。
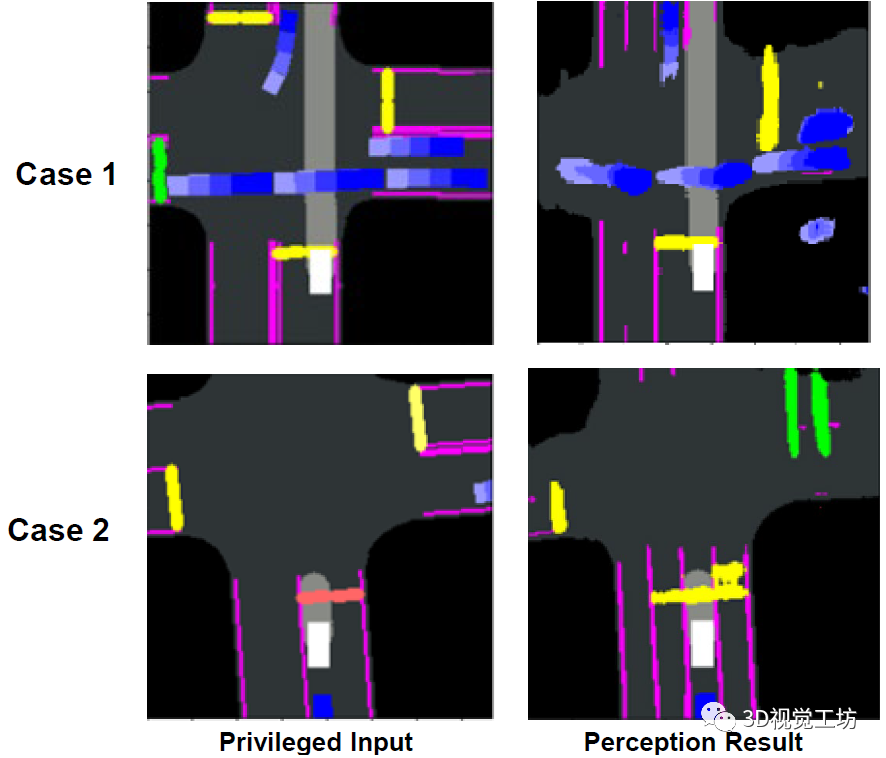
另一個原因就是教師模式的不完善。其實單獨使用教師模型來輸出運動規劃,其結果也是非常不準的,所以學術界很多做法都是加入一些手工設計的規則來進行二次約束,這樣來提高性能。
解耦教師和學生模型的思路確實很棒,但是這兩個問題也確實很尖銳。那么怎么解決這兩個問題呢?這就要涉及到DriveAdapter的另一個關鍵模塊:適配器。
4.2 適配器模塊
為了獲得更低的成本和更好的適應性,作者在學生和教師模型之間添加適配器。雖然感覺這個適配器長得有點像很多論文里提到的"即插即用"模塊?
適配器是分級插入的,第一層輸入是原始的BEV分割圖和學生模型的底層特征。之后,一方面不斷編碼BEV分割圖,另一方面使用卷積層來對BEV特征進行降采樣,來對其不同特征層之間的分辨率。
那么,具體怎么彌補BEV分割圖和GT之間的差距呢?這里是為每個適配器都設計了一個特征對齊目標函數。實際上,相當于每個適配器模塊都使用了一個額外的信息源,并且用原始BEV特征來恢復教師模型所需的GT特征。通過這種方式,可以以逐層監督的方式逐步縮小預測與真實特征之間的分布差距:
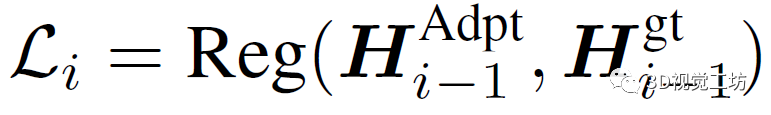
針對教師模型不完善的問題,作者是通過兩種方式將手工規則的先驗注入訓練過程:(1)特征對齊Mask:對于教師模型錯誤并被規則檢測的情況,由于教師模型中的原始特征導致錯誤的決策,就不讓適配器模塊恢復。(2)行動引導特征學習:計算模型預測和實際決策之間的損失,并通過凍結的教師模型和適配器模塊進行反向傳播。這里也推薦「3D視覺工坊」新課程《深度剖析面向自動駕駛領域的車載傳感器空間同步(標定)》。
5. 實驗結果
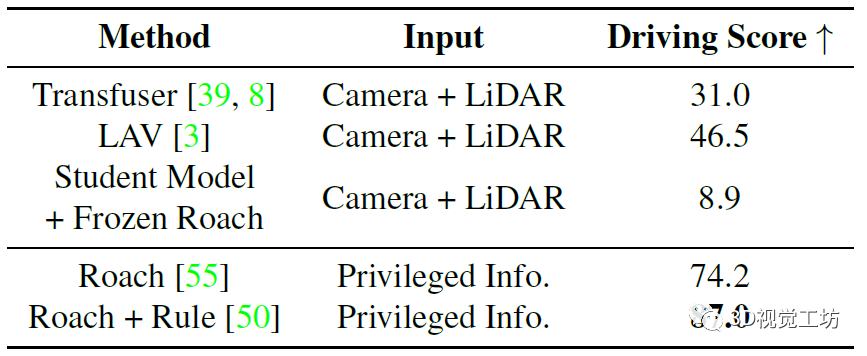
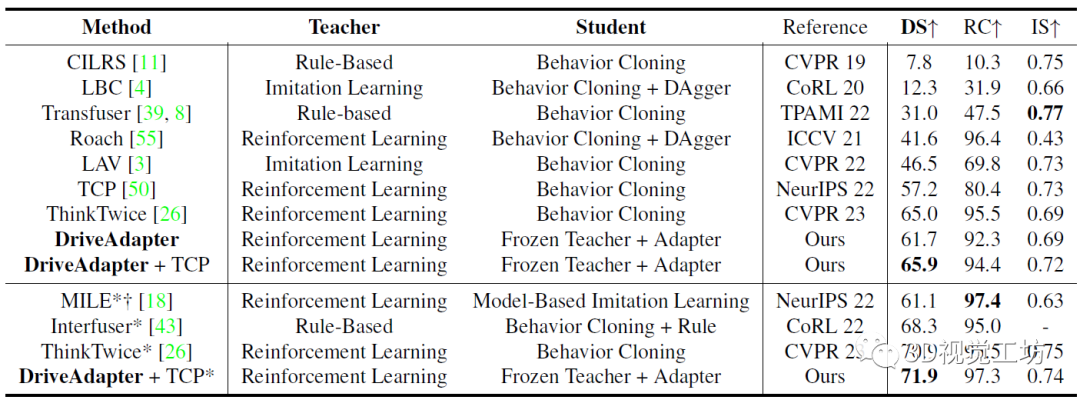
作者使用CARLA模擬器進行數據收集和閉環駕駛性能評估,每幀采集4臺相機和1臺激光雷達的原始數據。訓練是在Town01、Town03、Town04和Town06進行,總共189K幀。評估指標方面,用的是CARLA的官方指標,包括:**違規指數( IS )衡量沿途發生的違規行為數量,路徑完成度( RC )評估車輛完成路徑的百分比。駕駛得分( DS )**表示路線完成度和違規得分的乘積。
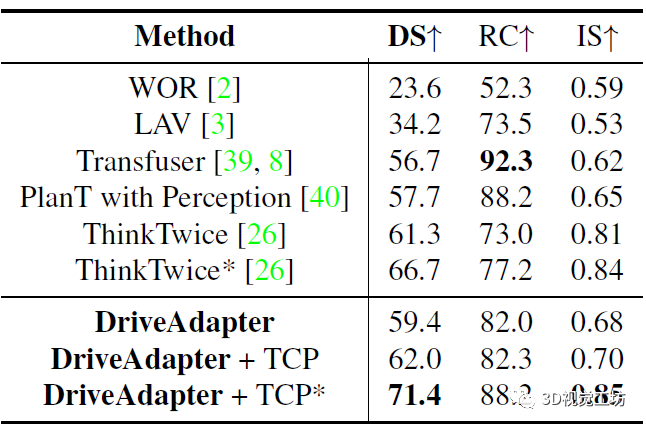
和其他SOTA方法的對比是在Town05 Long和Longest6序列上進行。可以發現,DriveAdapter甚至可以與經過10倍數據量訓練的模型相媲美,而在DriveAdapter也使用10倍數據以后,性能進一步提升,這其實是因為訓練更好得感知了紅燈。
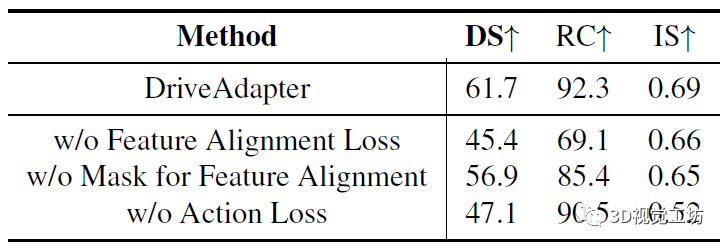
兩個消融實驗,一方面對比了特征對齊損失、特征對齊Mask、行為引導損失,一方面對比了適配器的各個階段:
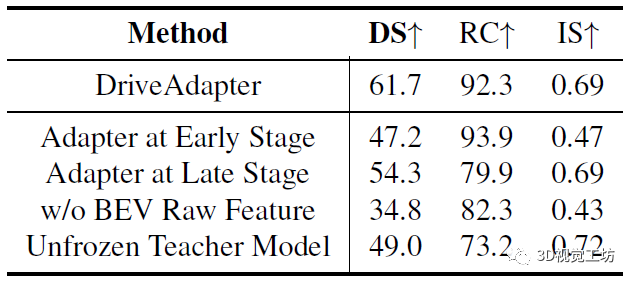
最后這個實驗很有意思,不知道讀者有沒有這樣的想法:"學生模型能不能不生成BEV分割,而是直接生成教師模型的中間特征圖,那么性能會不會不一樣?"。
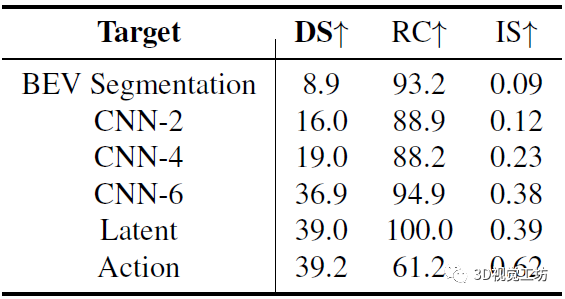
實際上,隨著學生模型的學習目標變深,整個駕駛性能是增加的。作者認為,將特征直接輸入到教師模型的更深層會遇到更少的累積誤差。但有個極端例外,就是只做行為克隆,也就相當于完全不使用教師模型,這樣會遇到嚴重的慣性問題,導致路徑完成度( RC )較低。
那既然學習目標變深以后,性能會變好,為啥還要生成BEV分割呢?作者主要是考慮到,早期階段的特征包含更多關于場景的詳細信息,可能會對教師模型決策很重要,并且適配器可以緩解累積誤差。另一方面,語義分割可以直觀得調試學生模型的感知情況。
6. 總結
今天給大家介紹的是ICCV 2023的開源工作DriveAdapter,它很好得解耦了自動駕駛感知和規劃的行為克隆,提出了一種新的端到端范式。直接利用通過RL學習的教師模型中的駕駛知識,并且克服了感知不完善和教師模型不完善的問題。筆者覺得更重要的是整篇文章分析問題的思路很通順,讀起來很舒服。算法剛剛開源,感興趣的小伙伴趕快試試吧。
-
傳感器
+關注
關注
2551文章
51163瀏覽量
754150 -
模型
+關注
關注
1文章
3254瀏覽量
48878 -
自動駕駛
+關注
關注
784文章
13838瀏覽量
166529
原文標題:ICCV 2023開源!打破端到端自動駕駛感知和規劃的耦合障礙!
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
細說關于自動駕駛那些事兒
自動駕駛的到來
即插即用的自動駕駛LiDAR感知算法盒子 RS-Box
自動駕駛技術的實現
自動駕駛綜述之定位、感知、規劃常見算法匯總

端到端自動駕駛到底是什么?
基于矢量化場景表征的端到端自動駕駛算法框架

理想汽車自動駕駛端到端模型實現









 工商網監
工商網監
評論