


傳統的云數據中心網絡一般是基于對外提供服務的流量模型而設計的,流量主要是從數據中心到最終客戶,即以南北向流量為主,云內部東西向流量為輔。承載 VPC 網絡的底層物理網絡架構,對于承載智算業務存在如下挑戰。
本文選自“智算中心網絡架構白皮書(2023)”“智能計算中心規劃建設指南”,對傳統網絡與智算網絡、兩層胖樹、三次胖樹及全面的分析對比,并介紹了組網最佳實踐。
有阻塞網絡:考慮到并非所有服務器都會同時對外產生流量,為了控制網絡建設成本, Leaf 交換機的下聯帶寬和上聯帶寬并非按照 1:1 設計,而是存在收斂比。一般上聯帶寬僅有下聯帶寬的三分之一。
云內部流量時延相對較高:跨 Leaf 交換機的兩臺服務器互訪需要經過 Spine 交換機,轉發路徑有 3 跳。
帶寬不夠大:一般情況下單物理機只有一張網卡接入 VPC 網絡,單張網卡的帶寬比較有限,當前較大范圍商用的網卡帶寬一般都不大于 200Gbps。
對于智算場景,當前比較好的實踐是獨立建一張高性能網絡來承載智算業務,滿足大帶寬,低時延,無損的需求。
大帶寬的設計
智算服務器可以滿配 8 張 GPU 卡,并預留 8 個 PCIe 網卡插槽。在多機組建 GPU 集群時,兩個 GPU 跨機互通的突發帶寬有可能會大于 50Gbps。因此,一般會給每個 GPU 關聯一個至少 100Gbps 的網絡端口。在這種場景下可以配置 4張 2*100Gbps 的網卡,也可以配置 8 張 1*100Gbps 的網卡,當然也可以配置 8 張單端口 200/400Gbps 的網卡。

無阻塞設計
無阻塞網絡設計的關鍵是采用 Fat-Tree(胖樹)網絡架構。交換機下聯和上聯帶寬采用 1:1 無收斂設計,即如果下聯有64 個 100Gbps 的端口,那么上聯也有 64 個 100Gbps 的端口。
此外交換機要采用無阻塞轉發的數據中心級交換機。當前市場上主流的數據中心交換機一般都能提供全端口無阻塞的轉發能力。
低時延設計 AI-Pool
在低時延網絡架構設計方面,百度智能云實踐和落地了基于導軌(Rail)優化的AI-Pool 網絡方案。在這個網絡方案中,8 個接入交換機為一組,構成一個 AI-Pool。以兩層交換機組網架構為例,這種網絡架構能做到同 AI-Pool 的不同智算節點的 GPU 互訪僅需一跳。
在 AI-Pool 網絡架構中,不同智算節點間相同編號的網口需要連接到同一臺交換機。如智算節點 1 的 1 號 RDMA 網口,智算節點 2 的 1 號 RDMA 網口直到智算節點 P/2 的 1 號 RDMA 網口都連到 1 號交換機。
在智算節點內部,上層通信庫基于機內網絡拓撲進行網絡匹配,讓相同編號的 GPU 卡和相同編號的網口關聯。這樣相同GPU 編號的兩臺智算節點間僅一跳就可互通。
不同GPU編號的智算節點間,借助NCCL通信庫中的Rail Local技術,可以充分利用主機內GPU間的NVSwitch的帶寬,將多機間的跨卡號互通轉換為跨機間的同GPU卡號的互通。
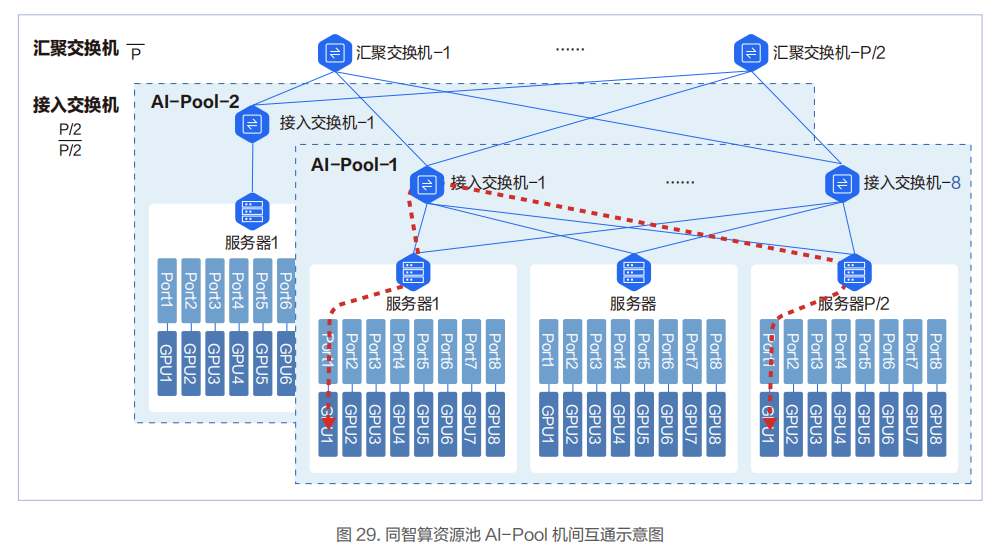
對于跨 AI-Pool 的兩臺物理機的互通,需要過匯聚交換機,此時會有 3 跳。
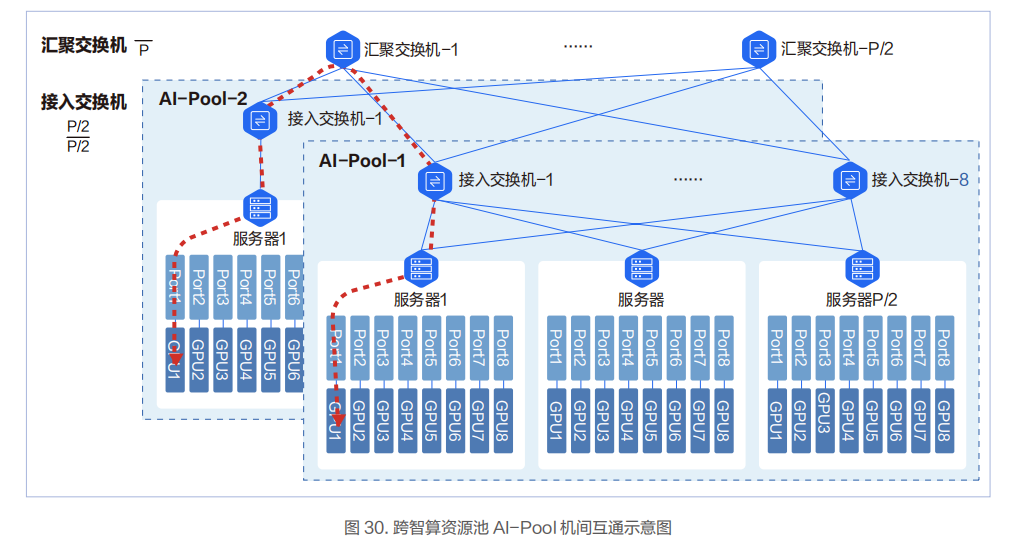
網絡可承載的 GPU 卡的規模和所采用交換機的端口密度、網絡架構相關。網絡的層次多,承載的 GPU 卡的規模會變大,但轉發的跳數和時延也會變大,需要結合實際業務情況進行權衡。
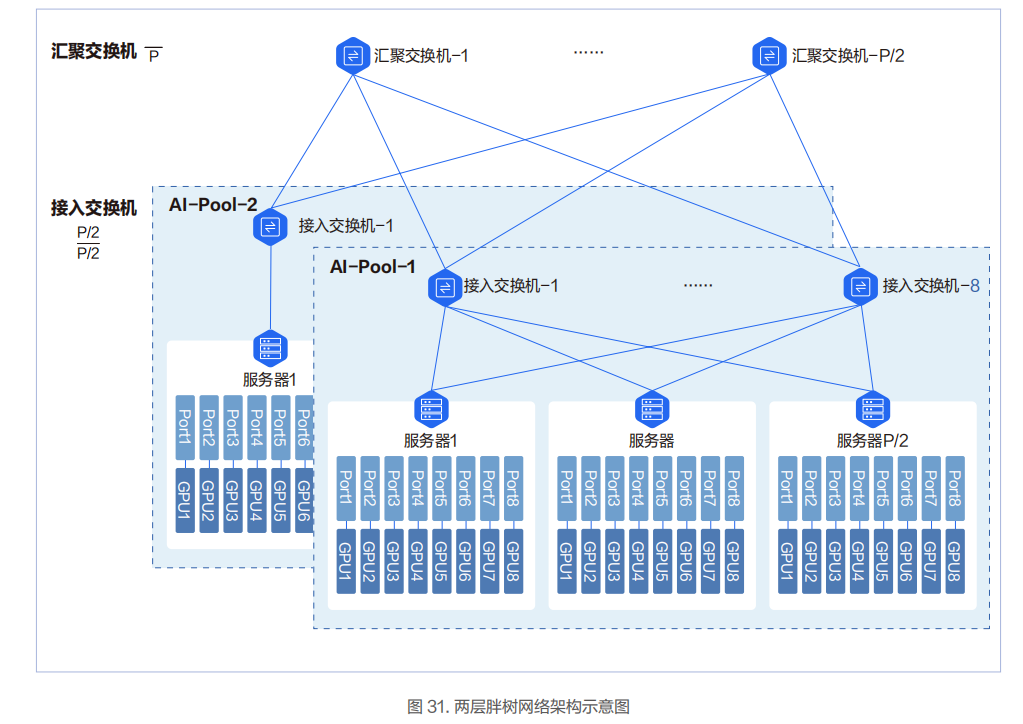
兩層胖樹架構
8 臺接入交換機組成一個智算資源池 AI-Pool。圖中 P 代表單臺交換機的端口數。單臺交換機最大可下聯和上聯的端口為P/2 個,即單臺交換機最多可以下聯 P/2 臺服務器和 P/2 臺交換機。兩層胖樹網絡可以接入 P*P/2 張 GPU 卡。
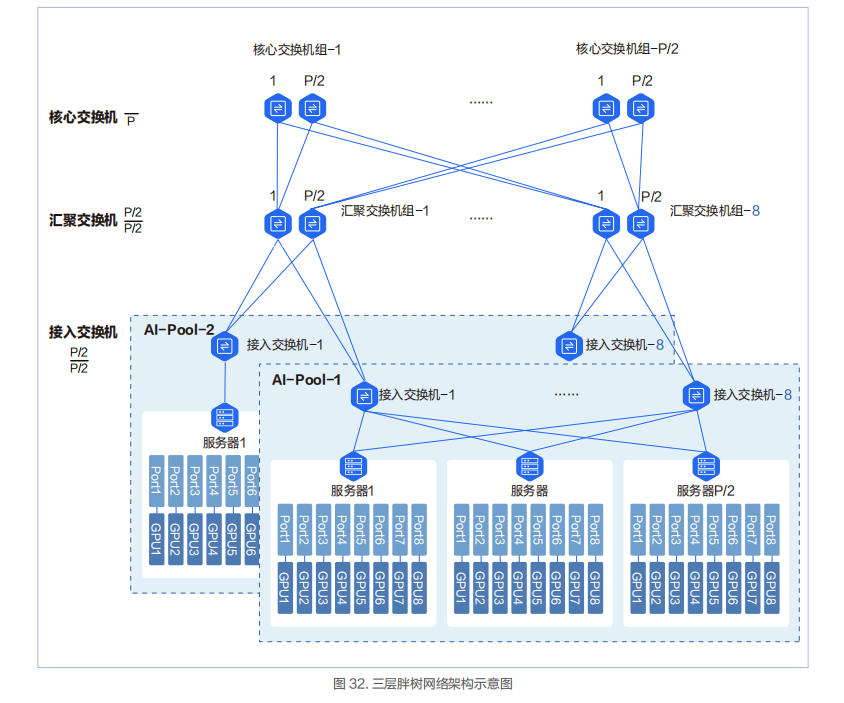
三層胖樹架構
三層網絡架構中會新增匯聚交換機組和核心交換機組。每個組里面的最大交換機數量為 P/2。匯聚交換機組最大數量為 8,核心交換機組的最大數量為 P/2。三層胖樹網絡可以接入 P*(P/2)*(P/2)=P*P*P/4 張 GPU 卡。
在三層胖樹組網中,InfiniBand 的 40 端口的 200Gbps HDR 交換機能容納的最多 GPU 數量是 16000。這個 16000GPU 卡的規模也是目前 InfiniBand 當前在國內實際應用的 GPU 集群的最大規模網絡,當前這個記錄被百度保持。
兩層和三層胖樹網絡架構的對比
可容納的 GPU 卡的規模
兩層胖樹和三層胖樹最重要的區別是可以容納的 GPU 卡的規模不同。在下圖中 N 代表 GPU 卡的規模,P 代表單臺交換機的端口數量。比如對于端口數為 40 的交換機,兩層胖樹架構可容納的 GPU 卡的數量是 800 卡,三層胖樹架構可容納的 GPU 卡的數量是 16000 卡。

轉發路徑
兩層胖樹和三層胖樹網絡架構另外一個區別是任意兩個節點的網絡轉發路徑的跳數不同。
對于同智算資源池 AI-Pool 的兩層胖樹架構,智算節點間同 GPU 卡號轉發跳數為 1 跳。智算節點間不同 GPU 卡號在沒有做智算節點內部 Rail Local 優化的情況下轉發跳數為 3 跳。
對于同智算資源池 AI-Pool 的三層胖樹架構,智算節點間同 GPU 卡號轉發跳數為 3 跳。智算節點間不同 GPU 卡號在沒有做智算節點內部 Rail Local 優化的情況下轉發跳數為 5 跳。

典型實踐
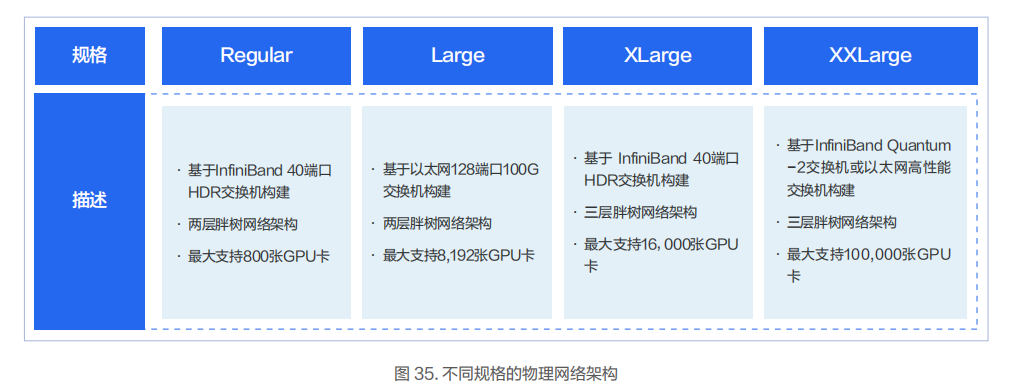
不同型號的 InfiniBand/RoCE 交換機和不同的網絡架構下所支持的 GPU 的規模不同。結合當前已成熟商用的交換機,我們推薦幾種物理網絡架構的規格供客戶選擇。
Regular:InfiniBand 兩層胖樹網絡架構,基于 InfiniBand HDR 交換機,單集群最大支持 800 張 GPU 卡。
Large:RoCE 兩層胖樹網絡架構,基于 128 端口 100G 數據中心以太交換機,單集群最大支持 8192 張 GPU 卡。
XLarge:InfiniBand 三層胖樹網絡架構,基于 InfiniBand HDR 交換機,單集群最大支持 16000 張 GPU 卡。
XXLarge:基于 InfiniBand Quantum-2 交換機或同等性能的以太網數據中心交換機,采用三層胖樹網絡架構,單集群最大支持 100000 張 GPU 卡。
Large智算物理網絡架構實踐
支撐上層創新應用和算法落地的關鍵環節之一是底層的算力,而支撐智算集群的算力發揮其最大效用的關鍵之一是高性能網絡。度小滿的單個智算集群的規模可達 8192 張 GPU 卡,在每個智算集群內部的智算資源池 AI-Pool 中可支持 512張 GPU 卡。通過無阻塞、低時延、高可靠的網絡設計,高效的支撐了上層智算應用的快速迭代和發展。
XLarge智算物理網絡架構實踐
為了實現更高的集群運行性能,百度智能云專門設計了適用于超大規模集群的 InfiniBand 網絡架構。該網絡已穩定運行多年,2021 年建設之初就直接采用了 200Gbps 的 InfiniBand HDR 交換機,單臺 GPU 服務器的對外通信帶寬為1.6Tbps。
責任編輯:彭菁
-
帶寬
+關注
關注
3文章
994瀏覽量
42217 -
服務器
+關注
關注
13文章
9802瀏覽量
88084 -
交換機
+關注
關注
22文章
2752瀏覽量
101977 -
數據中心
+關注
關注
16文章
5237瀏覽量
73562 -
智能計算
+關注
關注
0文章
191瀏覽量
16724
原文標題:智算中心網絡架構設計實踐(2023)
文章出處:【微信號:架構師技術聯盟,微信公眾號:架構師技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論