 英偉達超級芯片更新 首度引入H3Be
英偉達超級芯片更新 首度引入H3Be
近年來人工智能的火熱,已經對算力的需求,已經不再是什么新鮮事了。
而圍繞著這個市場,除了有幾無敵手的英偉達GPU外,還有Graphcore、Cerebra、Sambanova和Tenstorrent等芯片新入者攜帶著各自打造的“武器”躍躍欲試,以求占有一席之地。
此外,AMD和Intel這些傳統芯片巨頭也不甘人后,紛紛加碼這個賽道。他們一方面升級自己原有的CPU產品,與此同時還在升級GPU產品,其中英特爾甚至還通過對Habana的收購,通過多路進攻的方式押注人工智能。
進來,他們又更新了“武器庫”,為新一輪的AI芯片競賽做好準備。
英偉達超級芯片更新,首度引入H3Be
作為AI市場迄今為止最大的贏家,遙遙領先的英偉達雖然不至于被突然擊敗,但面對咄咄逼人的競爭對手,他們應該還是有點危機感。于是,在昨晚,英偉達CEO黃仁勛又帶來了公司全新的 GH200“superchip”的新變體——世界上第一個配備 HBM3e 內存的 GPU 芯片。
因為人工智能對數據“搬運”的需求,HBM在過去幾個月里已經成為產業關注的重中之重,也成為了限制GPU產能的關鍵因素之一。為此三星和SK海力士等廠商除了在提高HBM產能之余,也在升級其HBM技術,而HBM 3e就是他們正在最新推動的產品。
關于這個尚未敲定的標準,其很多參數也沒有定論。但按照集邦咨詢所說,HBM3e將采用24Gb單晶芯片堆疊,在8層(8Hi)基礎下,單個HBM3e的容量將躍升至24GB。集邦認為,主要制造商預計將在 2024 年第一季度發布 HBM3e 樣品,并計劃在 2024 年下半年實現量產。而英偉達的GH200“superchip”的新變體計劃于明年二季度發貨,這體現了AI芯片巨頭在其上的迫切。
自 2021 年該公司披露初步細節以來,Grace Hopper superchip一直是 Nvidia 首席執行官黃仁勛的一個大話題。Superchip集成了廣泛應用于移動設備、可與英特爾和AMD的基于x86的芯片競爭Arm架構。而之所以Nvidia 稱其為“Superchip”,是因為它將基于 Arm 的 Nvidia Grace CPU 與 Hopper GPU 架構結合在一起。而這個芯片在早幾個月的發布,已經引起了市場的廣泛討論。
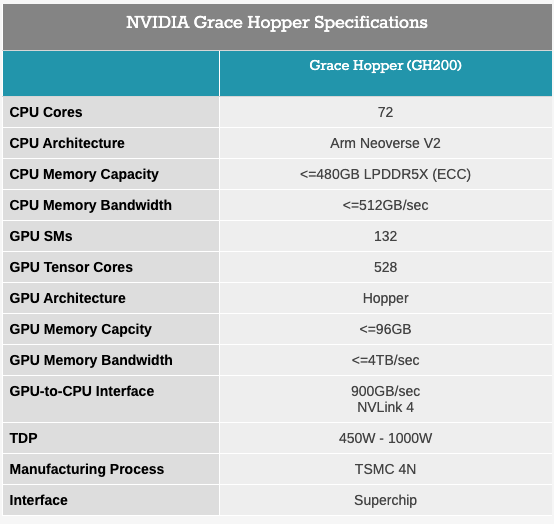
GH200的規格
而在時隔沒多久,英偉達帶來了全新的升級版本芯片。
據介紹,全新 GH200 Grace Hopper Superchip 同樣是基于 72 核 Grace CPU,配備 480 GB ECC LPDDR5X 內存以及 GH100 計算 GPU,搭配 141 GB HBM3E 內存,采用 6 個 24 GB 堆棧,使用 6,144位存儲器接口。雖然 Nvidia 物理安裝了 144 GB 內存,但只有 141 GB 可用才能獲得更高的良率。
作為世界上第一款配備HBM3e 內存的芯片,英偉達新版本的 GH200能夠將其本地 GPU 內存增加 50%,這對于人工智能市場來說尤其受歡迎,因為頂級模型尺寸巨大且通常內存容量有限。而在雙配置設置中,它將配備高達 282 GB 的 HBM3e 內存,NVIDIA 表示,與當前一代產品相比,內存容量高出 3.5 倍,帶寬高出 3 倍。Nvidia還聲稱,HBM3e內存將使下一代GH200運行AI模型的速度比當前模型快3.5倍。
“我們對這款新的 GH200 感到非常興奮。它將配備 141 GB 的 HBM3e 內存,”Nvidia 超大規模和 HPC 副總裁兼總經理 Ian Buck 在與媒體和分析師的會議上表示。“HBM3e 不僅增加了 GPU 的容量和內存量,而且速度也更快。”
在 SIGGRAPH 2023 的主題演講中,NVIDIA 總裁兼首席執行官黃仁勛 (Jensen Huang) 表示:“為了滿足生成式 AI 不斷增長的需求,數據中心需要具有特殊需求的加速計算平臺。”Jensen 還接著說道:“全新 GH200 Grace Hopper Superchip 平臺通過卓越的內存技術和帶寬來實現這一點,以提高吞吐量、連接 GPU 以不妥協地聚合性能的能力,以及可以在整個數據中心輕松部署的服務器設計。“
從昨晚英偉達的介紹中我們可以看到,他們不僅制造更快的芯片,還在新的服務器設計中對其進行擴展。
如Ian Buck就表示,Nvidia正在開發一種新的基于雙GH200的Nvidia MGX服務器系統,該系統將集成兩個下一代Grace Hopper Superchip。他解釋說,新的GH200將與Nvidia的互連技術NVLink連接。借助新型雙 GH200 服務器中的 NVLink,系統中的 CPU 和 GPU 將通過完全一致的內存互連進行連接。
“CPU 可以看到其他 CPU 的內存,GPU 可以看到其他 GPU 內存,當然 GPU 也可以看到 CPU 內存,”Buck說。“因此,合并后的超大超級 GPU 可以作為一個整體運行,提供 144 個 Grace CPU 核心,超過 8 petaflops 的計算性能以及 282 GB 的 HBM3e 內存。”他強調。
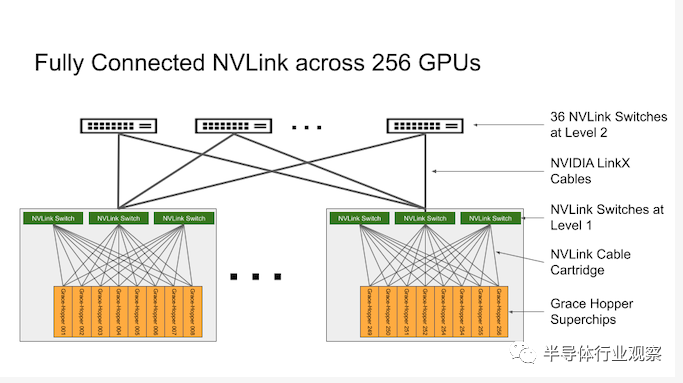
值得一提的是,在此前,我們已經介紹了圍繞 NVIDIA Grace Hopper 平臺構建的已發布的 DGX GH200 AI 超級計算機。DGX GH200 是完全基于 NVIDIA 架構構建的 24 機架集群,每個 DGX GH200 都結合了 256 個芯片,并提供 120 TB 的 CPU 連接內存。它們使用 NVIDIA 的 NVLink 進行連接,該 NVLink 具有多達 96 個本地 L1 交換機,可在 GH200 刀片之間提供即時通信。NVIDIA 的 NVLink 允許部署與高速一致的互連一起工作,使 GH200 能夠完全訪問 CPU 內存,并在雙配置時允許訪問高達 1.2 TB 的內存。
英特爾 Falcon Shores 2,卷土重來
為了應對來自英偉達和AMD的競爭,英特爾最初計劃為其稱為 Falcon Shores 的 芯片配備 GPU 和 CPU 內核,打造該公司首款用于高性能計算的“XPU”。但是在幾個月前,他們意外宣布,Falcon Shores將轉向純 GPU 設計并將芯片推遲到 2025 年,這讓行業觀察家感到震驚——因為這使得英特爾無法與AMD 的 Instinct MI300和Nvidia 的 Grace Hopper處理器競爭,后兩者均采用 CPU+GPU的混合處理器設計。
然而在近日的財報說明會上,英特爾首席執行官 Pat Gelsinger 透露,公司計劃于 2026 年推出新版本的 Falcon Shores 芯片,代號為 Falcon Shores 2。Falcon Shores 2 芯片將于 2025年接替首款 Falcon Shores 芯片,后者是一款用于人工智能和超級計算的高性能 GPU。?
“當我們將 GPU 和加速器整合到一個產品中時,我們有一個簡化的路線圖,”
雖然英特爾并未過多談論這款將于2026 年推出的產品,但英特爾方面曾表示,因為Falcon Shores 芯片將使用Chiplet設計,因此英特爾將能夠混合搭配 GPU、AI 加速器和第三方 CPU。
英特爾公司副總裁兼超級計算事業部總經理 Jeff McVeigh 在 5 月份的電話會議上更是表示:“這為跨供應商提供了將 Falcon Shores GPU 與其他 CPU 以及 CPU 與 GPU 比例結合起來的靈活性。”
McVeigh 表示,獨立GPU Falcon Shores 產品模型使用基于 GPU 的通用編程接口,CPU 和 GPU 的 CXL 接口將提高代碼的生產力和性能。?
此外,2026 年的發布Falcon Shores 2,這也許意味著該芯片采用 Angstrom 時代的工藝制作。該芯片制造商將重點放在 2025 年之前的產品發布上,屆時將實現四年內啟動五個節點的目標。又因為Falcon Shores 2 的發布日期為 2026 年,這似乎代表著原始版本的 Falcon Shores GPU 的生命周期很短,是一個過渡產品。
如之前很多報道中所說,Falcon Shores 芯片是專為 HPC 和 AI 計算而設計,英特爾已經討論過將 GPU 與 Gaudi 芯片系列合并。Gelsinger在財報電話會議上表示,Falcon Shores 的執行情況“良好”。他同時還表示Falcon Shores 將擁有最好的 GPU 和最好的矩陣加速。
對于其GPU和Gaudi等面向AI的芯片,英特爾的目標是確保人工智能軟件堆棧通過其 OneAPI 軟件堆棧在 Gaudi 和 Falcon Shores 芯片上向前兼容。
“我們將擴大該軟件堆棧的靈活性。我們正在添加 FP8。我們剛剛添加了 PyTorch 2 支持。一路走來的每一步,它都會變得更好、更廣泛的用例。正在支持更多語言模型。軟件堆棧支持更多的可編程性,”Gelsinger強調。
此外,英特爾還在通過 OneAPI 采用部分開放的軟件方法,該方法以名為 SYCLomatic 的工具為中心,可以轉換專有的 CUDA 代碼以在包括 Ponte Vecchio 在內的各種 GPU 上運行。
AMD也不甘人后
在英特爾和英偉達在為未來傾囊而出的同時,AMD也不甘人后。幾個月前,公司就帶來了全新的MI 300系列芯片,這也是公司面向AI市場祭出的一個殺手锏。具體信息參考半導體行業觀察之前的報道《1530億晶體管芯片發布,AMD正式叫板英偉達》。而在AMD最近的財報發布會上,該公司CEO Lisa Su也披露,AMD的AI芯片參與度在本季度增加了七倍多。
Lisa同時還表示,公司在遵守美國的出口管制之余。正在尋找機會為中國客戶提供定制的人工智能解決方案。
眾所周知,隨著生成式人工智能的出現,市場對 GPU 的需求猛增。特斯拉的Elon Musk在該公司最近的財報電話會議上談到了 Nvidia GPU 的短缺問題,微軟也在其年報中談到了GPU短缺可能帶來的風險,為此這些公司正在尋找人工智能芯片替代品的機會。
其中,AMD無疑是最值得關注的一家。
審核編輯:劉清
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238258 -
存儲器接口
+關注
關注
0文章
16瀏覽量
7951 -
英偉達
+關注
關注
22文章
3770瀏覽量
90989 -
GPU芯片
+關注
關注
1文章
303瀏覽量
5804 -
DDR5
+關注
關注
1文章
422瀏覽量
24142
原文標題:全球首用HBM3e,英偉達最強芯片升級
文章出處:【微信號:Rocker-IC,微信公眾號:路科驗證】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論