 GPU Microarch學習筆記
GPU Microarch學習筆記
Warp
GPU的線程從thread grid 到threadblock,一個thread block在CUDA Core上執行時,會分成warp執行,warp的顆粒度是32個線程。比如一個thread block可能有1024個線程,那么就會分成32個warp執行。
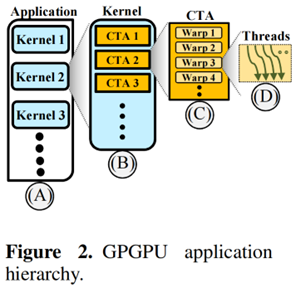
上圖的CTA(cooperative thread arrays)即為thread block。
Warp內的32個線程是以lock-step的方式鎖步執行,也就是在沒有遇到分支指令的情況下,如果執行,那么執行的都是相同的指令。通過這種方式32個線程可以共享pc,源寄存器ID和目標寄存器ID。
雖然warp是以32的顆粒度,但是具體在GPU內部執行時,也可能是以16的顆粒度,分兩次執行,比如早期的fermi架構。
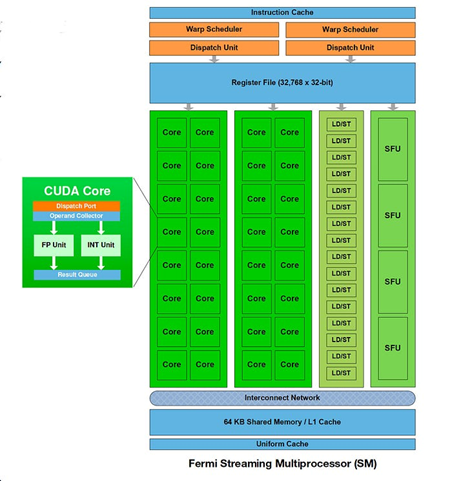
如上圖所示,兩個warp scheduler,每個warp每次只能在16個CUDA core上執行。
后續的Pascal GPU架構 CUDA core增加到了32個,每個周期都能執行一個warp。
寄存器
GPU的寄存器數量是影響劃分CUDA thread block的數量的原因之一,如下圖所示[1]。

雖然內部執行是按照warp執行的,按照調度順序和ready進行調度。但是寄存器的分配是靜態的按照thread number分配的,而不是warp。在warp執行時,32個線程,每個線程讀取源寄存器,寫入目標寄存器。假設每個寄存器4B,那么每次32個線程讀取128B。
因而128B也就是GPU L1 Cache Cacheline的大小。不同于CPU,每一級的cache都要維護MOSEI的一致性,對于GPU的thread來說,私有memory不需要共享,因此對于local memory可以write back。而全局共享memory則可以write evict。
CPU的寄存器,在編譯器編譯時,會根據寄存器的live time進行優化,而且在CPU內部執行時,進行重命名,在有限的寄存器數量上盡量地解決依賴問題。
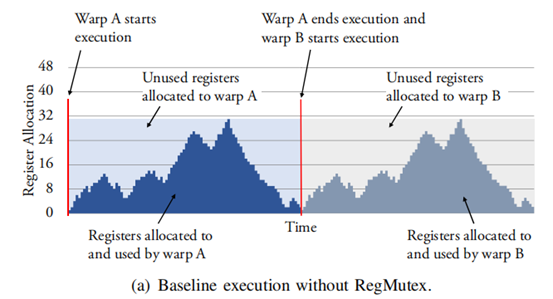
GPU只在編譯時優化,盡量減少對memory的使用,在內部執行時,如果針對每個warp都增加一個寄存器重命名單元,設計復雜。因此GPU每個線程需要的寄存器就是它編譯時需要的寄存器上限(寄存器上限也可以通過編譯器控制)。這就導致了實際GPU內部執行時對寄存器使用數量的波動。如下圖[2]所示,因此也有很多文章研究如何優化寄存器的使用。
在編譯時,nvcc可以通過指定--maxrregcount指定寄存器的數量,但是過多的寄存器會因為固定的寄存器資源而導致thread數量變少,過少的寄存器也會導致需要頻繁的訪問memory,因此也需要折衷。

WARP Divergence
之前討論warp時說如果32個線程,沒有遇到分支,那么每個線程都執行同一條指令,但是如果存在分支呢?
GPU沒有CPU的分支預測,使用active mask和predicate register來構建token stack來處理遇到分支時的問題。
GPGPU-sim按照下圖[3]模擬的token stack,其中的
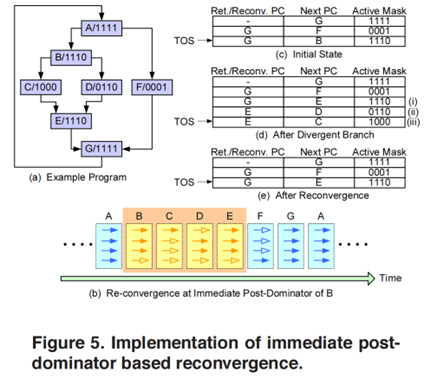
另一種可能的token stack則是按照如下的方式構建,結合了指令,predicateregister和token stack。
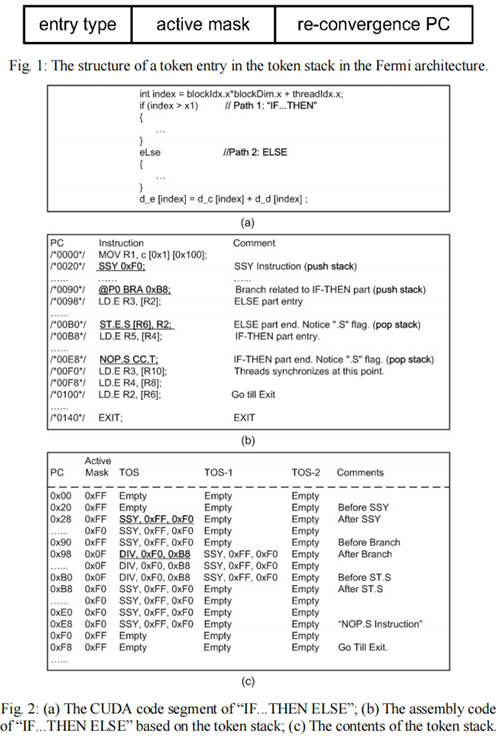
上圖[4]中的(b)即為編譯出的匯編指令,SSY 0xF0即為push stack,if else分支指令結束重聚的指令地址為0xF0。每個warp會有當前的active pc寄存器和active mask寄存器。我們假設一個warp內有8個thread,在SSY0xF0指令執行時,會將active mask 壓棧,壓棧的內容包括Fig1中的entry type SSY,active mask和re-convergence pc,也就是0xF0(從SSY 0xF0指令可以獲得).
在分支指令@PO BRA 0xB8執行時,會將DIV(divergence),activemask(0xF0,這個并非pc,而是active mask,當前warp的每個thread的predicateregister拼接而成,8bit 每個bit表示一個thread是否滿足if條件)和 0xB8(if語句塊內的第一條指令的地址)壓棧。
然后gpu會默認執行else分支(因為if需要跳轉,else直接順序執行),執行else分支時,需要對active mask取反,只執行不滿足if條件的那些thread。
Else分支的最后一條匯編指令末尾會增加.S flag用于標志popstack,此時pop指令會將active mask出棧,更新到active mask寄存器和active pc中,然后執行if 分支,直到執行完畢if內的最后一條指令,對應地址0xE8,此時再次出棧。
將當前active pc更新為0xF0,activemask更新為0xFF,此時if else分支執行完畢,回到重聚點,所有線程繼續lock-step鎖步執行。
這里只假設一個if else,但是實際上可能存在if else的嵌套,因此第一步SSY 0xF0,可以理解成上下文切換時的先保存當前的activemask 0xFF和重聚點的指令地址0xF0。
上述的方案與GPGPU-sim中的架構類似,除了在指令中顯式的增加了壓棧出棧,GPGPU-sim處理每一個分支都需要壓棧if else兩條分支,占用兩項,而方案2)中每次除了保存當前active mask外,只需壓棧一項。
審核編輯:劉清
-
寄存器
+關注
關注
31文章
5342瀏覽量
120274 -
編譯器
+關注
關注
1文章
1629瀏覽量
49115 -
CUDA
+關注
關注
0文章
121瀏覽量
13620 -
cache技術
+關注
關注
0文章
41瀏覽量
1062 -
GPU芯片
+關注
關注
1文章
303瀏覽量
5806
原文標題:GPU Microarch 學習筆記【1】
文章出處:【微信號:處理器與AI芯片,微信公眾號:處理器與AI芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA在深度學習應用中或將取代GPU

Altera FPGA CPLD學習筆記

使用外部GPU在Linux筆記本上加速機器學習
GPU在深度學習中的應用與優勢






 工商網監
工商網監
評論