 SHERF:可泛化可驅動人體神經輻射場的新方法
SHERF:可泛化可驅動人體神經輻射場的新方法
人體神經輻射場的目標是從 2D 人體圖片中恢復高質量的 3D 數字人并加以驅動,從而避免耗費大量人力物力去直接獲取 3D 人體幾何信息。這個方向的探索對于一系列應用場景,比如虛擬現實和輔助現實場景,有著非常大潛在性的影響。
現有人體神經輻射場生成和驅動技術主要可以分為兩類。
第一類技術利用單目或者多目人體視頻去重建和驅動 3D 數字人。這類技術主要是針對特定數字人的建模和驅動,優化耗時大,缺乏泛化到大規模數字人重建上的能力。
第二類技術為了提升 3D 數字人重建的效率。提出利用多視角人體圖片作為輸入去重建人體神經輻射場。
盡管這第二類方法在 3D 人體重建上取得了一定的效果,這類方法往往需要特定相機角度下的多目人體圖片作為輸入。在現實生活中,我們往往只能獲取到任意相機角度下人體的一張圖片,給這類技術的應用提出了挑戰。
在 ICCV2023 上,南洋理工大學 - 商湯科技聯合研究中心 S-Lab 團隊提出了基于單張圖片的可泛化可驅動人體神經輻射場方法 SHERF。
SHERF 可以基于用戶輸入的一張任意相機角度 3D 人體圖片,該角度下相機和人體動作體型(SMPL)參數,以及給定目標輸出空間下任意相機參數和人體動作體型(SMPL)參數,重建并驅動該 3D 數字人。本方法旨在利用任意相機角度下人體的一張圖片去重建和驅動 3D 人體神經輻射場。
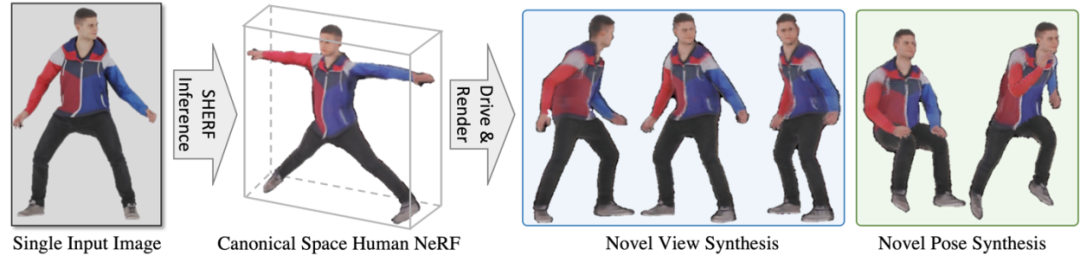
圖 1
基本原理
人體神經輻射場重建和驅動主要分為五個步驟(如圖 2 所示)。
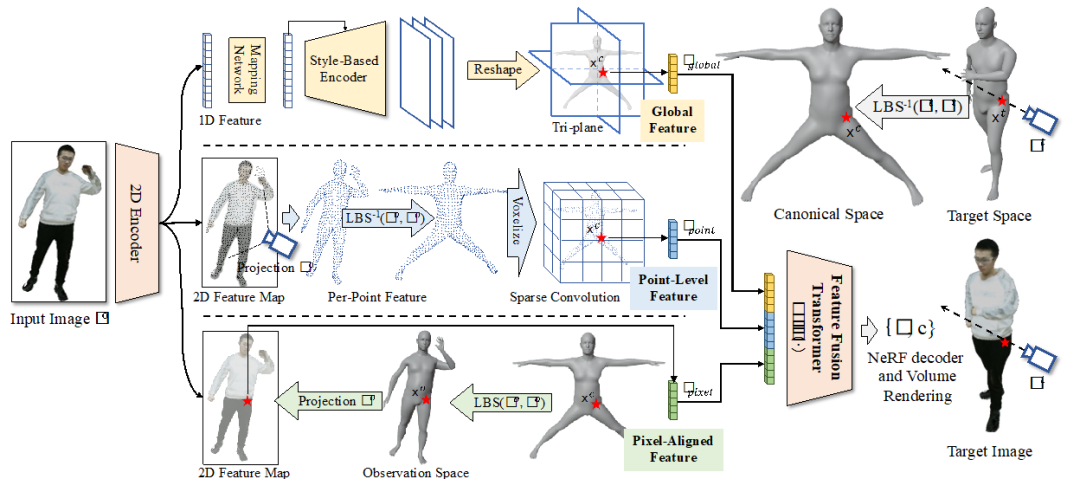
圖 2
第一步為目標空間(target space)到標準空間(canonical space)的坐標轉換,基于用戶輸入目標輸出空間下任意人體動作體型參數和相機外參參數,在目標空間內射出光線,并在光線上采樣一系列空間點,利用 SMPL 算法的逆線性蒙皮轉換(Inverse Linear Blend Skinning)將目標空間里的空間點轉換到標準空間中。
第二步為提取標準空間中 3D 點對應的層級特征(hierarchical feature)。
全局特征(global feature)提取:利用二維編碼網絡(2D Encoder)從輸入圖片提取一維特征,并利用映射網絡(Mapping Network)和風格編碼網絡(Style-Based Encoder)進一步將 1D 特征轉換為標準空間下的三平面特征(Tri-plane),接下來將標準空間中 3D 點投影到三平面提取相應的全局特征;
點級別特征(Point-Level Feature)提取:首先利用二維編碼網絡(2D Encoder)從輸入圖片提取二維特征,并將觀測空間(observation space)下 SMPL 的頂點投影到輸入圖片成像平面上去提取相應特征,緊接著利用 SMPL 算法的逆線性蒙皮轉換(Inverse Linear Blend Skinning)將觀測空間下 SMPL 的頂點轉到標準空間下構建稀疏三維張量,然后利用稀疏卷積得到標準空間中 3D 點的點級別特征;
像素級別特征(Pixel-Aligned Feature)提取:首先利用二維編碼網絡(2D Encoder)從輸入圖片提取二維特征,并利用 SMPL 算法的線性蒙皮轉換(Linear Blend Skinning)將標準空間中 3D 點轉到觀測空間下,再投影到輸入圖片成像平面上去提取相應像素級別特征。
第三步為特征融合(Feature Fusion Transformer),利用 Transformer 模型將三種不同級別的特征進行融合。第四步為人體神經輻射場解碼生成相應圖片信息,將標準空間中 3D 點坐標,光線方向向量和對應特征輸入到人體神經輻射場解碼網絡中得到 3D 點的體密度和顏色信息,并進一步基于體渲染(Volume Rendering)在目標空間下生成相應像素的顏色值,并得到最終用戶輸入目標輸出空間下任意人體動作體型參數和相機外參參數下的圖片。
基于以上步驟,給定目標輸出空間下任意人體動作序列(SMPL)參數可以從 2D 圖片恢復 3D 數字人并加以驅動。
結果比較
本文在四個人體數據集上人體數據集上進行了實驗,分別是 THuman,RenderPeople,ZJU_MoCap,HuMMan。
該研究對比了對比了最先進的可泛化多視角人體圖片的人體神經輻射場方法,NHP 和 MPS-NeRF。本文在 peak signal-to-noise ratio (PSNR),structural similarity index (SSIM),以及 Learned Perceptual Image Patch Similarity (LPIPS)進行了比較。如下圖所示,本文在所有數據集,所有指標上均大幅超越之前的方案。
SHERF 動態驅動 3D 人體結果如下圖所示:

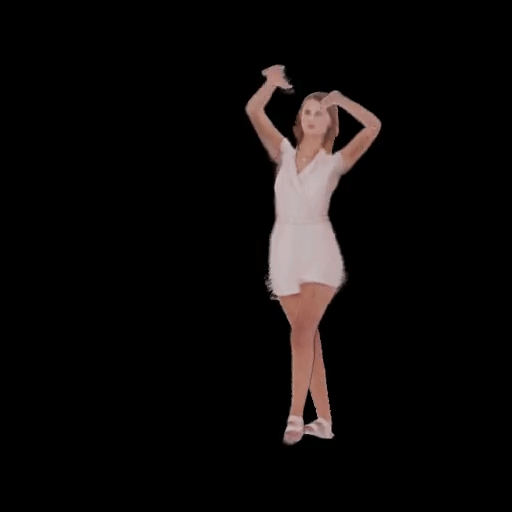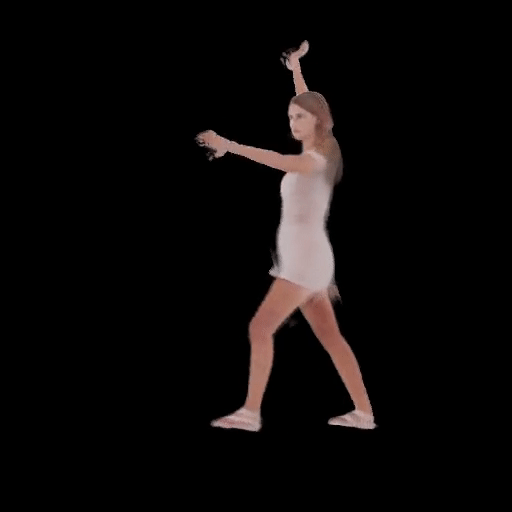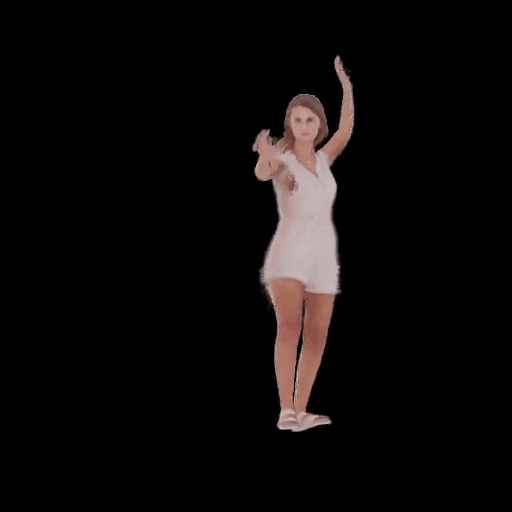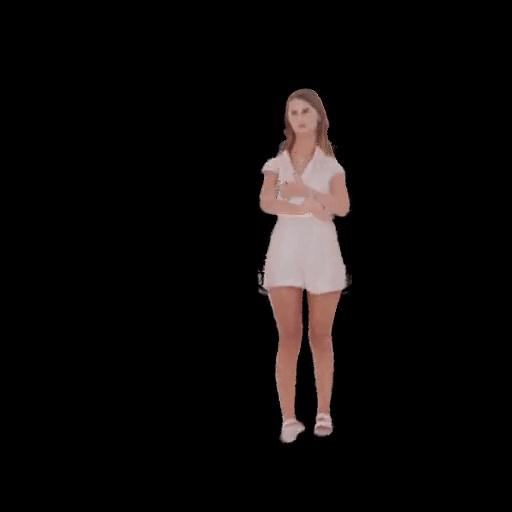
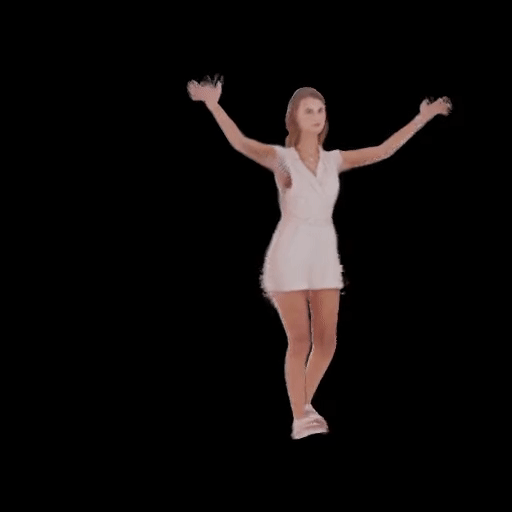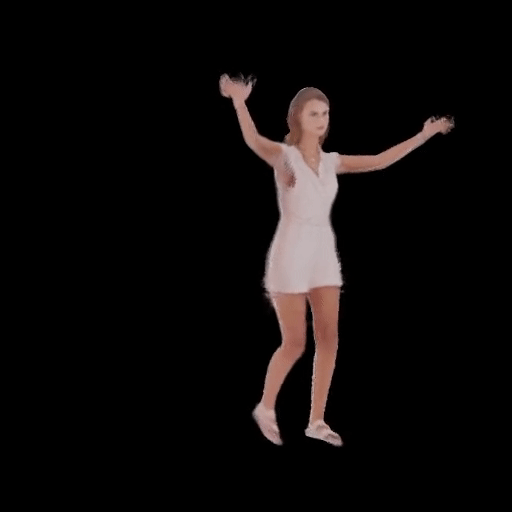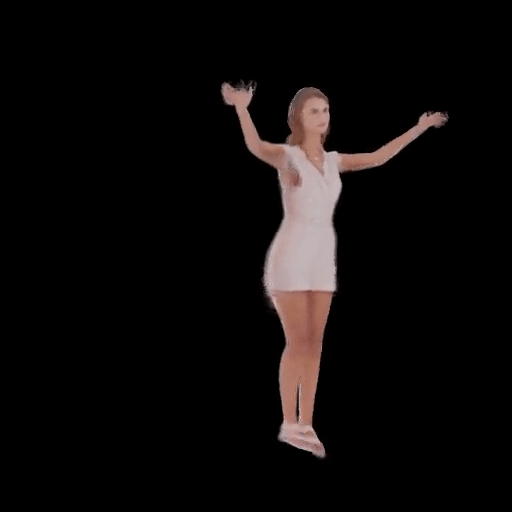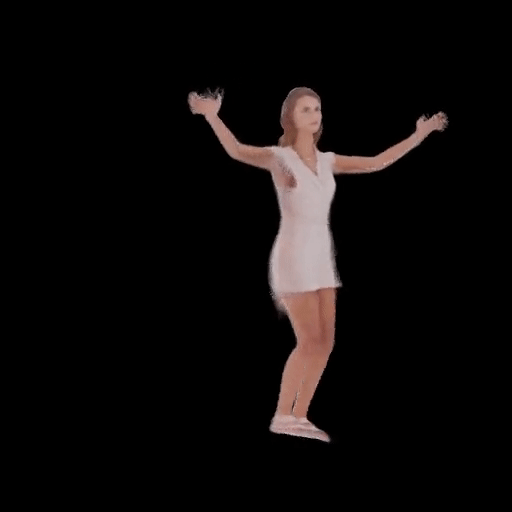

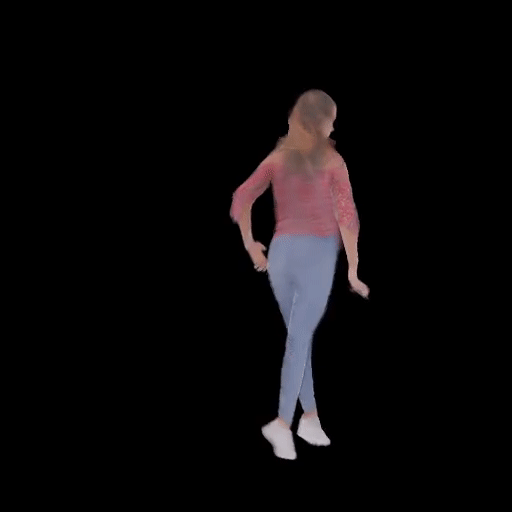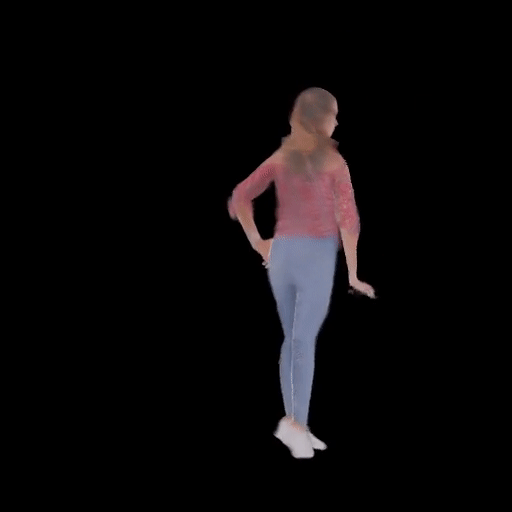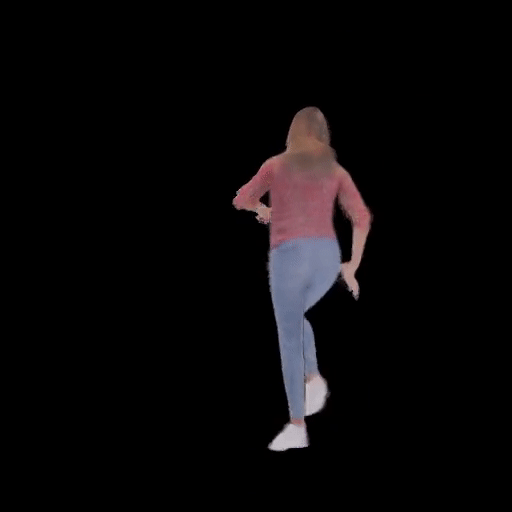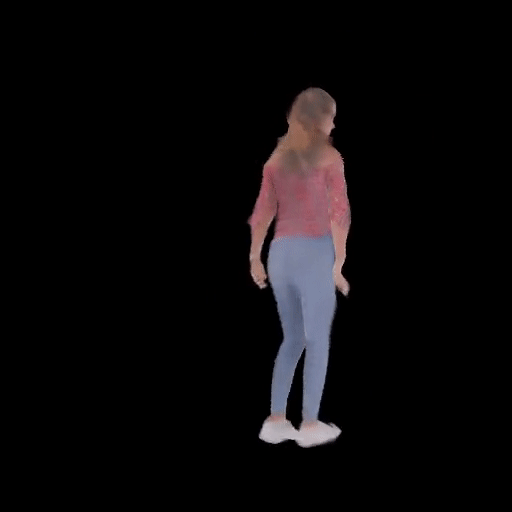



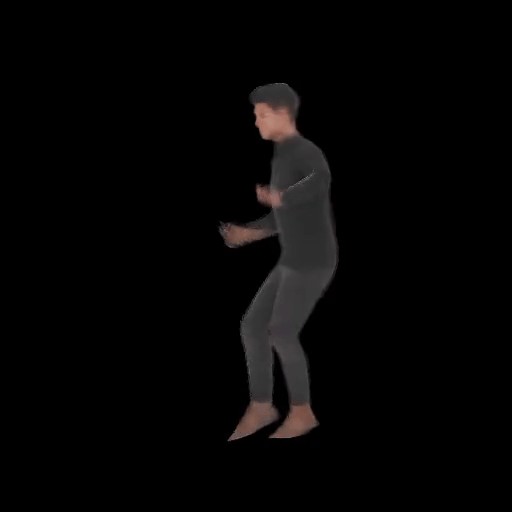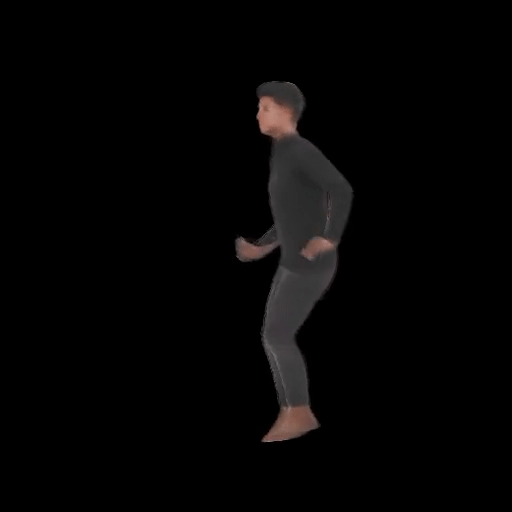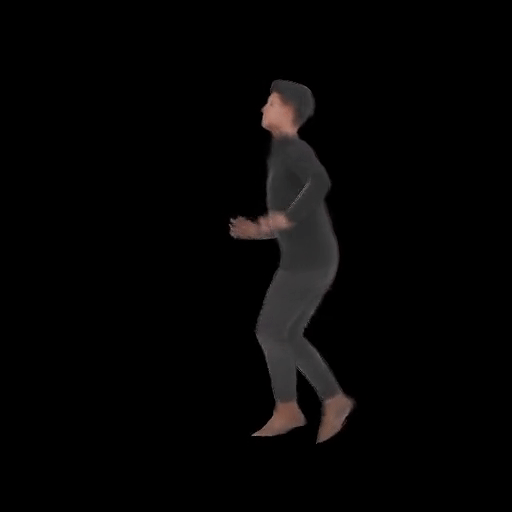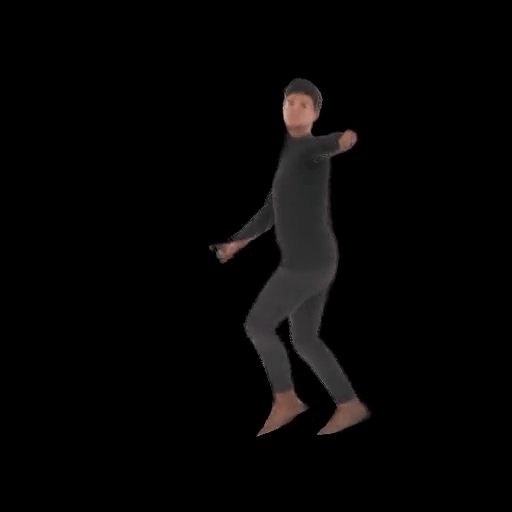
從左到右分別為input Image、motion seq 1、motion seq 2
本文同樣驗證了在 in-the-wild DeepFashion 數據上的泛化和驅動效果,如下圖 3 所示,給定任意一張輸入圖片,本文利用單視角估 SMPL 的先進算法估出 SMPL 和相應相機角度,后利用本文提出的算法對 3D 人體進行驅動。實驗結果顯示 SHERF 具有較強的泛化性。



從左到右分別為input Image、motion seq 1、motion seq 2
應用前景
在游戲電影制作,虛擬現實增強現實或者其他需要數字人建模的場景,用戶可以無需專業技能,專業軟件,即可通過輸入的一張任意相機角度 3D 人體圖片,該角度下相機的參數和相應的人體動作體形參數(SMPL),就可以達到重建并驅動該 3D 數字人的目的。
結語
本文提出一種基于單張輸入圖片可泛化可驅動的人體神經輻射場方法 SHERF。可以承認的是,本文依然存在一定的缺陷。
首先,對于輸入圖片觀測不到一部分人體表面, 渲染出來的結果可以觀察到一定的瑕疵,一個解決的辦法是建立一種遮擋可知(occlusion-aware)的人體表征。
其次,關于如何補齊輸入圖片觀測不到人體部分依舊是一個很難得問題。本文從重建角度提出 SHERF,只能對觀測不到的人體部分給出一個確定性的補齊,對觀測不到部分的重建缺乏多樣性。一個可行的方案是利用生成模型在觀測不到的人體部分生成多樣性高質量的 3D 人體效果。
審核編輯:劉清
-
驅動器
+關注
關注
53文章
8271瀏覽量
146857 -
編碼器
+關注
關注
45文章
3664瀏覽量
135075
原文標題:ICCV 2023 | SHERF:可泛化可驅動人體神經輻射場的新方法
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
判斷可膨脹石墨好壞的方法
大華股份榮獲中國創新方法大賽一等獎
基于遺傳算法的QD-SOA設計新方法

一種降低VIO/VSLAM系統漂移的新方法
大華股份榮獲2024年中國創新方法大賽一等獎
利用全息技術在硅晶圓內部制造納米結構的新方法

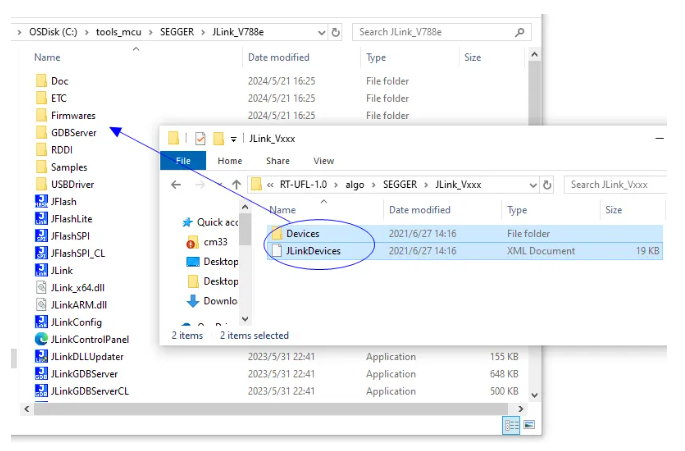
實踐JLink 7.62手動增加新MCU型號支持新方法
一種無透鏡成像的新方法

使隱形可見:新方法可在室溫下探測中紅外光
可攝入電子設備可用于追蹤和治療人體胃腸道中的不同疾病






 工商網監
工商網監
評論