 Alluxio是如何助力AI大模型訓練的呢?
Alluxio是如何助力AI大模型訓練的呢?
一、背景
隨著云原生技術的飛速發展,各大公有云廠商提供的云服務也變得越來越標準、可靠和易用。憑借著云原生技術,用戶不僅可以在不同的云上低成本部署自己的業務,而且還可以享受到每一個云廠商在特定技術領域上的優勢服務,因此多云架構備受青睞。
知乎目前采用了多云架構,主要是基于以下考慮:
服務多活:將同一個服務部署到不同的數據中心,防止單一數據中心因不可抗力不能正常提供服務,導致業務被 “一鍋端”;
容量擴展:一般而言,在公司的服務器規模達到萬臺時,單一數據中心就很難支撐業務后續的擴容需求了;
降本增效:對于同一服務,不同云廠商對同一服務的定價和運維的能力也不盡相同,我們期望能夠達到比較理想的狀態,在云服務滿足我們需求的前提下,盡量享受到低廉的價格。
知乎目前有多個數據中心,主要的機房有以下兩個:
在線機房:主要是部署知乎主站上直接面向用戶的服務(如評論、回答等),這部分服務對時延敏感
離線機房:主要是部署一些離線存儲,計算相關的服務,對時延不敏感,但是對吞吐要求高。
兩個數據中心之間通過專線連接,許多重要服務都依賴于專線進行跨機房調用,所以維持專線的穩定十分重要。專線流量是衡量專線是否穩定的重要指標之一,如果專線流量達到專線的額定帶寬,就會導致跨專線服務之間的調用出現大量的超時或失敗。
一般而言,服務的吞吐都不會特別高,還遠遠達不到專線帶寬的流量上限,甚至連專線帶寬的一半都達不到,但是在我們的算法場景中有一些比較特殊的情況:算法模型的訓練在離線機房,依賴 HDFS 上的海量數據集,以及 Spark 集群和機器學習平臺進行大規模分布式訓練,訓練的模型結果存儲在 HDFS 上,一個模型甚至能達到數十上百 GB;在模型上線時,算法服務會從在線機房跨專線讀取離線 HDFS 上的模型文件,而算法服務一般有數十上百個容器,這些容器在并發讀取 HDFS 上的文件時,很輕易就能將專線帶寬打滿,從而影響其他跨專線服務。

二、多 HDFS 集群
在早期,我們解決算法模型跨機房讀取的方式非常簡單粗暴,部署一套新的 HDFS 集群到在線機房供算法業務使用,業務使用模型的流程如下:
1) 產出模型:模型由 Spark 集群或機器學習平臺訓練產出,存儲到離線 HDFS 集群;
2) 拷貝模型:模型產出后,由離線調度任務定時拷貝需要上線的模型至在線 HDFS 集群;
3) 讀取模型:算法容器從在線 HDFS 集群讀取模型上線。
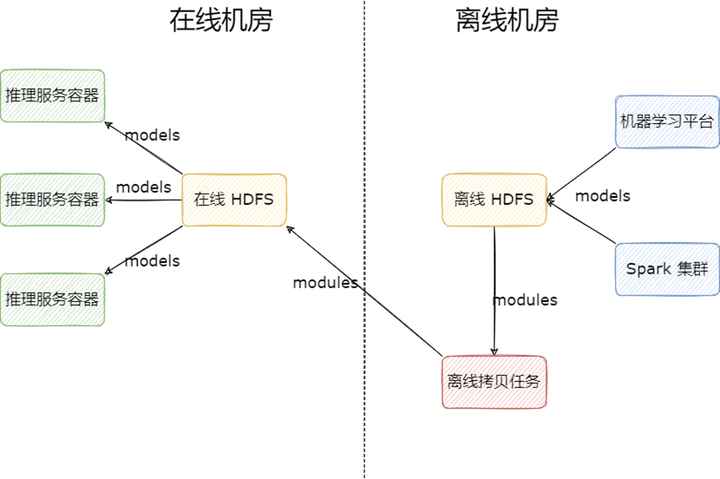
多 HDFS 集群的架構雖然解決了專線流量的問題,但是依然存在一些問題:
多個 HDFS 集群不便于維護,增加運維人員負擔;
拷貝腳本需要業務自己實現,每次新上線模型時,都要同步修改拷貝腳本,不便維護;
在線 HDFS 集群的文件需要業務定期手動刪除以降低成本,操作風險高;
在線 HDFS 與離線 HDFS 之間文件視圖不一致,用戶在使用 HDFS 時,需要明確知道自己使用的是哪個 HDFS,需要保存多個地址,心智負擔高;
在超高并發讀取時,比如算法一次性起上百個容器來讀取某個模型文件時,會導致 DataNode 負載過高,雖然可以通過增加副本解決,但是也會帶來較高的存儲成本。
基于以上痛點,我們自研了多云緩存服務 —UnionStore。
三、自研組件 UnionStore
3.1 簡介
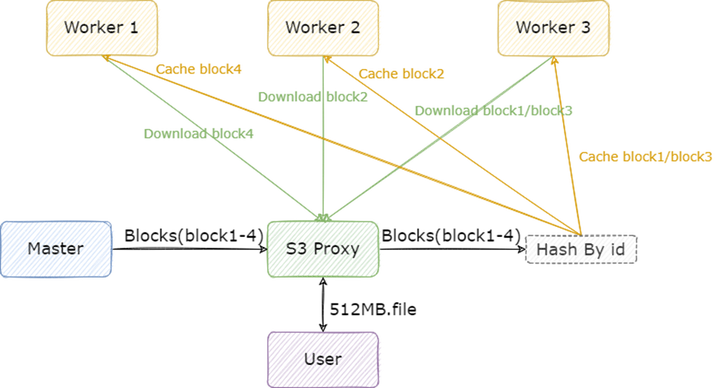
UnionStore 顧名思義,就是聯合存儲的意思,它提供了標準的 S3 協議來訪問 HDFS 上的數據,并且以對象存儲來作為跨機房緩存。UnionStore 目前在知乎有兩種使用場景:
模型上線場景:部署到在線機房,作為跨機房緩存使用:
用戶在向 UnionStore 請求讀取文件時,會先檢查文件是否已經上傳到對象存儲上:
如果對象存儲已經存在該文件,則直接從對象存儲讀取文件返回給用戶;
如果對象存儲不存在該文件,UnionStore 會先將離線 HDFS 上的文件上傳到在線機房的對象存儲上,再從對象存儲上讀取文件,返回給用戶,緩存期間用戶的請求是被 block 住的。這里相當于是利用對象存儲做了一層跨機房緩存。
模型訓練場景:部署到離線機房,作為 HDFS 代理使用,目的是為業務提供 S3 協議的 HDFS 訪問方式,通過 s3fs-fuse,業務就能掛載 HDFS 到本地目錄,讀取訓練數據進行模型的訓練。
模型訓練場景是我們 UnionStore 上線后的擴展場景,之前我們嘗試過很多 HDFS 掛載 POSIX 的方式,但是效果都不太理想,主要體現在重試方面,而 UnionStore 正好提供了 S3 協議,s3fs-fuse 重試做的不錯,所以我們最后選擇了 UnionStore + s3fs-fuse 對 HDFS 進行本地目錄的掛載。
其工作流程如下:
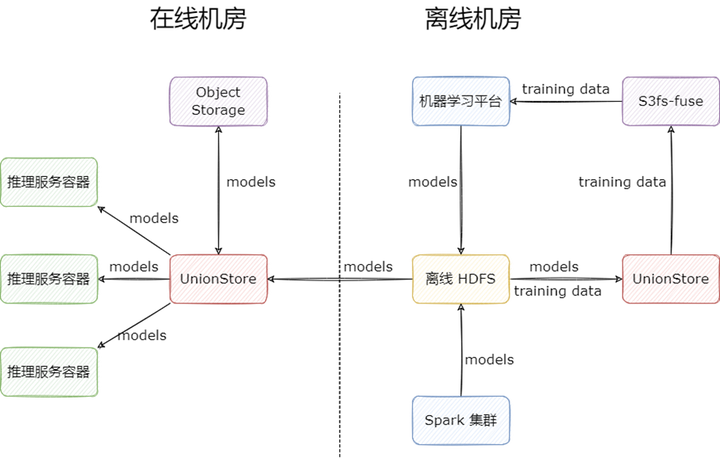
相比于之前多 HDFS 集群方案,UnionStore 的優勢如下:
1) UnionStore 提供了 S3 協議,各編程語言對 S3 協議的支持要比 HDFS 協議好,工具也相對來說也更豐富;
2) UnionStore 會自動緩存文件,無需用戶手動拷貝模型,省去了拷貝腳本的開發與維護;
3) 提供統一的文件視圖,因為元數據是實時請求 HDFS 的,所以文件視圖與 HDFS 強一致;
4) 下線了一個 HDFS 集群,文件儲存能力由對象存儲提供,節省了大量的服務器成本;
5) 文件過期可依賴對象存儲本身提供的能力,無需自己實現;
6) UnionStore 以云原生的方式提供服務,部署在 k8s 上,每一個容器都是無狀態節點,可以很輕易的擴縮容,在高并發的場景下,由于存儲能力轉移到對象存儲,在對象存儲性能足夠的情況下,不會遇到類似 DataNode 負載過高的問題。
3.2 實現細節
UnionStore 的完整架構圖如下:
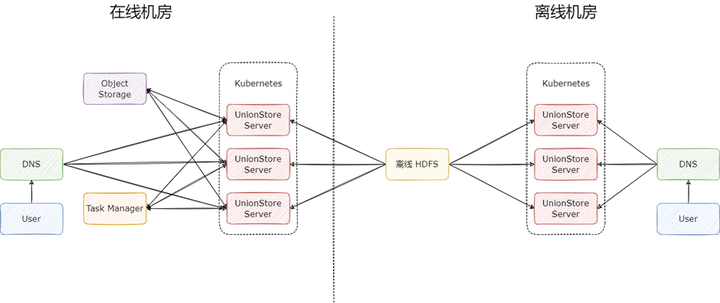
在使用對象存儲作為緩存時,UnionStore 有三個核心組件:
UnionStore Server:無狀態節點,每一個節點都能單獨提供服務,一般會部署多個,用于分攤流量
Object Storage:對象存儲,用于緩存 HDFS 上的數據,一般是在哪個云廠商就使用對應云廠商提供的對象存儲,流量費用幾乎可忽略;
Task Manager:任務管理器,用于存儲緩存任務,可用 MySQL 和 Redis 實現。
基于這三個組件我們在 UnionStore 上實現了一系列有用的功能。
文件校驗:文件被緩存至對象存儲后,如果 HDFS 上的文件做了修改,UnionStore 需要檢查到文件的變更,確保用戶不會讀取到錯誤的文件。這里我們在將 HDFS 文件上傳至對象存儲時,會將 HDFS 文件的大小,最后修改時間,checksum 等元信息存儲到對象存儲文件的 UserMetadata 上,用戶在讀取文件時,會檢查這部分的信息,只有當信息校驗通過時,才會返回對象存儲上的文件,如果校驗未通過,則會重新緩存這個文件,更新對象存儲上的緩存。
讀寫加速:對象存儲的單線程讀寫速度大約在 30-60MB/sec,遠遠小于 HDFS 的吞吐,如果不做特殊處理,是很難滿足業務的讀寫需求的。
在讀方面,我們利用對象存儲的 RangeRead 接口,多線程讀取對象存儲上的數據返回給用戶,達到了與 HDFS 相同的讀取速度。在寫方面,我們利用對象存儲的 MultiPartUpload 接口,多線程上傳 HDFS 上的文件,也能達到與 HDFS 相同的寫入速度。
文件僅緩存一次:因為 UnionStore Server 被設計成了無狀態節點,所以它們之間是無法互相感知的。如果有多個請求同時打到不同的 Server 節點上來請求未緩存的文件,這個文件可能會被不同的 Server 多次緩存,對專線造成較大的壓力。我們引入了 Task Manager 這個組件來解決這個問題:
Server 節點在接受到讀取未緩存文件的請求時,會先將用戶的請求異步卡住,生成緩存任務,提交到 Task Manager 的等待隊列中;
所有 Server 節點會不斷競爭等待隊列里的任務,只會有一個節點競爭成功,此時該節點會將緩存任務放入運行隊列,開始執行,執行期間向任務隊列匯報心跳;
每個 Server 節點會定期檢查自己卡住的用戶請求,來檢查 Task Manager 里對應的任務,如果任務執行成功,就會喚醒用戶請求,返回給用戶緩存后的文件;同時,每個 Server 都會定期檢查 Task Manager 里正在運行的任務,如果任務長時間沒有更新心跳,則會將任務從運行隊列里取出,重新放回等待隊列,再次執行。
這里所有的狀態變更操作都發生在 Server 節點,Task Manager 只負責存儲任務信息以及提供隊列的原子操作。
3.3 局限
UnionStore 項目在知乎運行了兩年,早期并沒有出現任何問題,但是隨著算法業務規模的不斷擴大,出現了以下問題:
1) 沒有元數據緩存,元數據強依賴 HDFS,在 HDFS 抖動的時候,有些需要頻繁更新的模型文件會受影響,無法更新,在線服務不應強依賴離線 HDFS;
2) 讀寫加速因為用到了多線程技術,對 CPU 的消耗比較大,在早期業務量不大的時候,UnionStore 只需要幾百 Core 就能支撐整個公司的算法團隊讀取數據,但是隨著業務量不斷上漲,需要的 CPU 數也漲到了上千;
3) 對象存儲能力有上限,單文件上千并發讀取時,也會面臨性能瓶頸;
4) UnionStore 只做到了緩存,而沒有做到高性能緩存,業務方的大模型往往需要讀取十多分鐘,極大影響模型的更新速度,制約業務的發展;
5) 無法做到邊緩存邊返回文件,導致第一次讀取文件的時間過長。
另外還有一個關鍵點,機器學習平臺為保證多活,也采用了多云架構,支持了多機房部署,在讀取訓練數據時,走的是 UnionStore 對 HDFS 的直接代理,沒走緩存流程,因為訓練數據大部分都是小文件,而且數量特別巨大,小文件都過一遍緩存會導致緩存任務在任務隊列里排隊時間過長,很難保證讀取的時效性,因此我們直接代理了 HDFS。按照這種使用方式,專線帶寬在訓練數據規模擴大時,依然會成為瓶頸。
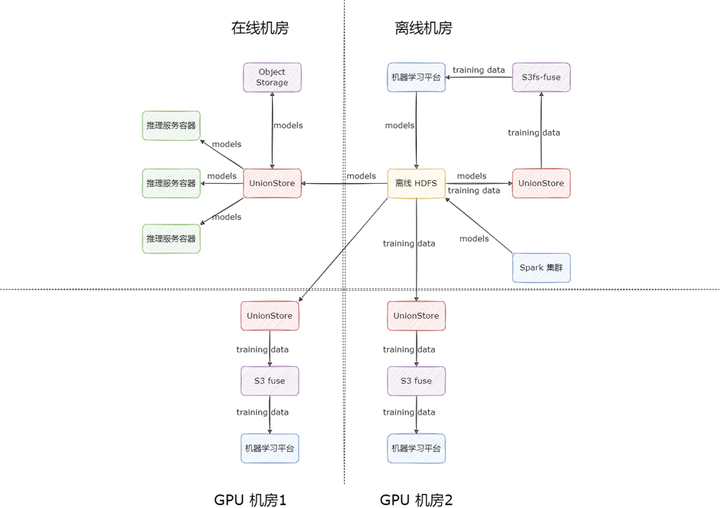
以上痛點使我們面臨兩個選擇:一是繼續迭代 UnionStore,讓 UnionStore 具備高性能緩存能力,比如支持本地 SSD 以及內存緩存;二是尋找合適的開源解決方案,完美替代 UnionStore 的使用場景。基于人力資源的寶貴,我們選擇了其二。
四、利用 Alluxio 替代 UnionStore
1. 調研
我們調研了業內主流的文件系統,發現 Alluxio 比較適合我們的場景,原因有以下幾點:
1) 透明緩存:相較于其他文件系統,Alluxio 可僅作為緩存使用,用于編排數據,業務方無需將模型文件寫入到其他的文件系統,只需要維持現狀,寫入 HDFS 即可;
2) 元數據與數據緩存:Alluxio 支持自定義緩存元數據與數據,這樣在讀取已緩存文件時,可完全不受 HDFS 影響;目前我們 UnionStore 的 QPS 大約在 20K-30K,緩存元數據可極大降低 NameNode 的壓力,反哺離線場景;
3) 豐富的 UFS 支持:支持除 HDFS 外的多種 UFS,比如對象存儲,對我們的數據湖場景也提供了強有力的支撐;
4) 即席查詢加速:知乎 Adhoc 引擎采用的是 Spark 與 Presto,Alluxio 對這兩個引擎都有較好的支持;
5) 訪問接口豐富:Alluxio 提供的 S3 Proxy 組件完全兼容 S3 協議,我們的模型上線場景從 UnionStore 遷移至 Alluxio 付出的成本幾乎可忽略不計;另外 Alluxio 提供的 Alluxio fuse 具備本地元數據緩存與數據緩存,比業務之前使用的 S3 fuse 具有更好的性能,正好能滿足我們的模型訓練場景。
6) 社區活躍:Alluxio 社區十分活躍,在我們調研期間交流群基本上都會有熱心的網友及時答復, issue 很少有超過半天不回復的情況。
對 Alluxio 的調研讓我們非常驚喜,它不僅滿足了我們的需求,還給我們 “額外贈送” 了不少附加功能。我們在內部對 Alluxio 進行了測試,以 100G 的文件做單線程讀取測試,多次測試取平均值,結果如下
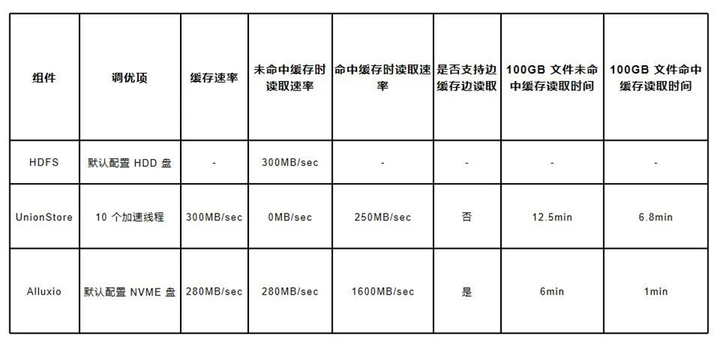
其中 HDFS 因為涉及到 OS 層面的緩存,波動是最大的,從 200MB/sec - 500MB/sec 都有,而 UnionStore 與 Alluxio 在命中緩存時表現十分穩定。
2. 集群規劃
Alluxio 在我們的規劃中是每個機房部署一套,利用高性能 NVME 磁盤對 HDFS 和對象存儲上的數據進行緩存,為業務提供海量數據的加速服務。
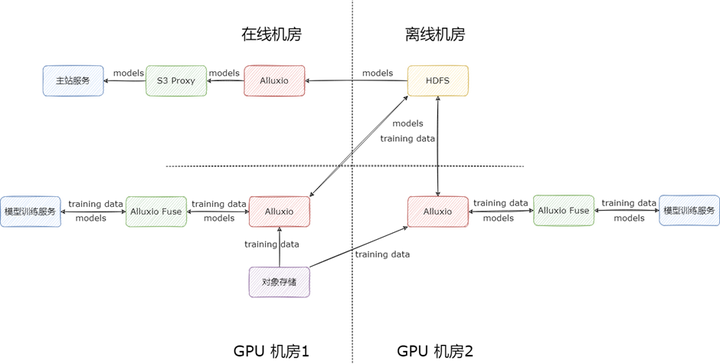
依據業務的使用場景,我們將 Alluxio 集群分為兩類。
模型上線加速集群:Alluxio 集群緩存模型本身,利用 S3 Proxy 對外提供只讀服務,加速模型的上線
模型訓練加速集群:Alluxio 集群緩存模型訓練數據,利用 Alluxio fuse 對 HDFS 上數據與元數據再做本地緩存,加速模型的訓練;產出的模型直接通過 Alluxio fuse 寫入 HDFS 進行持久化存儲。
3. 模型上線場景適配
3.1 場景特點
我們的模型上線場景有以下特點:
1) 用戶利用 S3 協議讀取模型文件;
2) 用戶將模型數據寫入到 HDFS 上后,需要立即讀取,數據產出與讀取的間隔在秒級,幾乎無法提前預熱,存在緩存穿透的問題;
3) 一份模型文件將由上百甚至上千個容器同時讀取,流量放大明顯,最大的單個模型讀取時,峰值流量甚至能達到 1Tb/sec;
4) 模型文件只會在短時間內使用,高并發讀取完畢后可視為過期;
5) 數萬容器分散在上千個 K8s 節點上,單個容器可用資源量較少。
針對模型上線場景,我們選擇了 S3 Proxy 來為業務提供緩存服務,不使用 Alluxio Client 以及 Alluxio fuse 主要是基于以下考慮:
用戶原本就是利用 S3 協議讀取文件,換成 S3 Proxy 幾乎無成本;
業務方使用的語言有 Python,Golang,Java 三種,Alluxio Client 是基于 Java 實現的,其他語言使用起來比較麻煩;
受限于單個容器的資源限制,不適合在容器內利用 CSI 等方式啟動 Alluxio fuse,因為 fuse 的性能比較依賴磁盤和內存的緩存。
3.2 集群部署
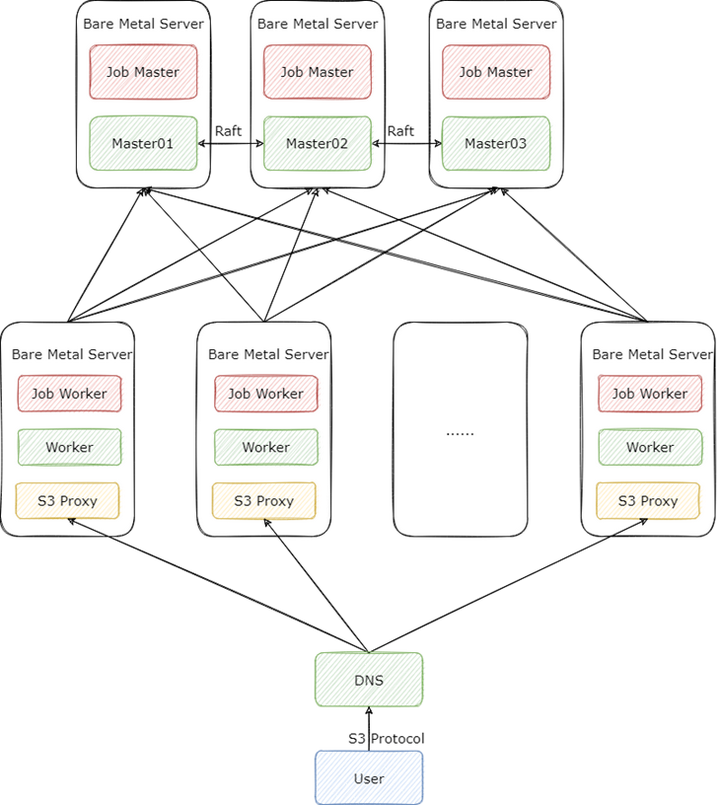
首先是集群的部署方式,在這個場景下,我們的 Alluxio 集群采取了 “大集群輕客戶端” 的方式來部署,也就是提供足夠數量的 Worker 與 S3 Proxy 來支撐業務以 S3 協議發起的高并發請求,架構圖如下
我們的集群版本是 2.9.2,在這個版本,S3 Proxy 有 v1 v2 兩種實現,可通過配置 alluxio.proxy.s3.v2.version.enabled 進行切換。v2 版本有一個很重要的功能,就是將 IO 操作與元數據操作進行了分類,分別交給不同的線程池去處理。這樣做的好處是,讓元數據操作能夠快速執行,不被 IO 線程卡住,因為一般情況下,元數據請求的 QPS 遠遠大于讀寫文件的 QPS。這個功能對我們非常有用,我們 UnionStore 的 QPS 在 25K 左右,其中 90% 的操作都是元數據訪問。
整個 Alluxio 集群我們采取了裸金屬機部署,Alluxio 也提供了 k8s 的部署方式,但是在我們的權衡之下,還是選擇了裸金屬機部署,原因如下:
1) 從我們的測試結果來看,Alluxio Worker 在” 火力全開 “的情況下是可以輕易打滿雙萬兆網卡的,這個時候網卡是瓶頸;如果選擇 k8s 部署,當有容器與 Alluxio Worker 調度到同一臺 k8s 的節點時,該容器容易受到 Alluxio Worker 的影響,無法搶占到足夠的網卡資源;
2) Alluxio Worker 依賴高性能磁盤做本地緩存,與其他服務混布容易收到其他進程的磁盤 IO 影響,無法達到最佳性能;
3) 因為 Alluxio Worker 強依賴網卡,磁盤等物理資源,這些資源不適合與其他服務共享。強行以 k8s 部署,可能就是一個 k8s 節點啟一個 Alluxio Worker 的 DaemonSet,這其實也沒必要用 k8s 部署,因為基于我們過往的經驗,容器內搞存儲,可能會遇到各類奇奇怪怪的問題,這些問題解決起來比較浪費時間,影響正常的上線進度。
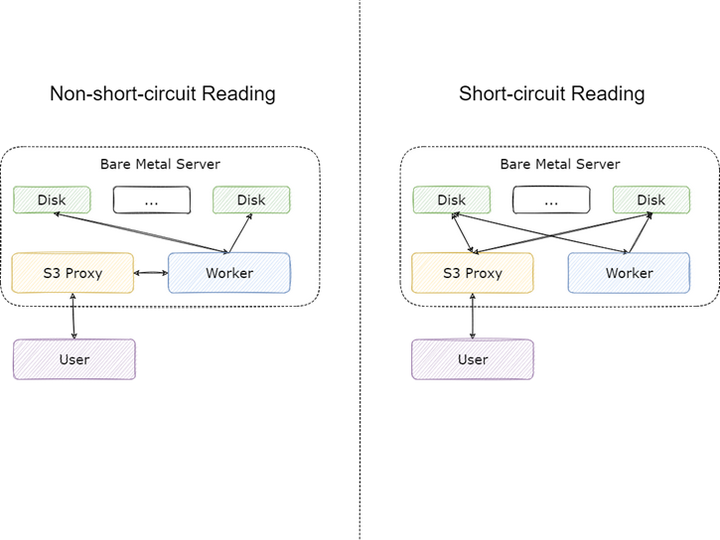
我們除了按照社區文檔的推薦將 Master 與 Job Master,Worker 與 Job Worker 部署到同一臺機器上,還另外將 S3 Proxy 與 Worker 進行了混布。S3 Proxy 在用戶看起來雖然是服務端,但是對 Alluxio 集群來說它還是客戶端,而 Alluxio 對于客戶端有一個非常重要的優化:
當 Client 與 Worker 在同一節點時,就可以使用短路讀的功能,在短路讀開啟的情況下,Client 將不再利用網絡請求調用 Worker 上的 RPC 接口讀取數據,而是直接讀本地磁盤上的數據,能夠極大節省網卡資源。通過 S3 Porxy 訪問 Alluxio 時,流量主要分為以下幾個部分:
文件未緩存至 Alluxio:Worker 從 UFS 讀取數據,任一 Worker 只要緩存了 UFS 的文件,這部分流量將不存在;
文件在遠端 Worker 緩存:本地 Worker 從其他 Worker 讀取數據緩存到本地,S3 Proxy 暫時從遠端 Worker 讀取,本地 Worker 緩存完畢后這部分流量將不存在;
文件在本地 Worker 緩存:S3 Proxy 從本地 Worker 讀取的流量,這部分流量在開啟短路讀后將不存在;
業務方從 S3 Proxy 讀取的流量,這部分流量無法避免。
其中 1,2 中的流量遠小于 3,4 中的流量,短路讀能夠將 3 的流量省下,節省約 30%-50% 的流量。
其次是集群的部署規模,在模型讀取這個場景,盡管每天的讀取總量可達數 PB,但是因為模型文件很快就會過期,所以 Worker 的容量并不需要很大,Worker 網卡的總帶寬能夠支持讀取流量即可。Worker 的數量可按照 流量峰值 /(2/3* 網卡帶寬) 來計算,這里網卡需要預留 1/3 的 buffer 來供 Worker 讀取 UFS 以及 Worker 互相同步數據使用。
最后是 Alluxio Master 的 HA 方式,我們選擇了 Raft,在我們的測試過程中,在上億的元數據以及數百 GB 堆的情況下,Master 主從切換基本上在 10 秒以內完成,效率極高,業務近乎無感。
3.3 上線與調優
我們的上線過程也是我們調優的一個過程。
在初期,我們只將一個小模型的讀取請求從 UnionStore 切換到了 Alluxio S3 Proxy,效果如下:
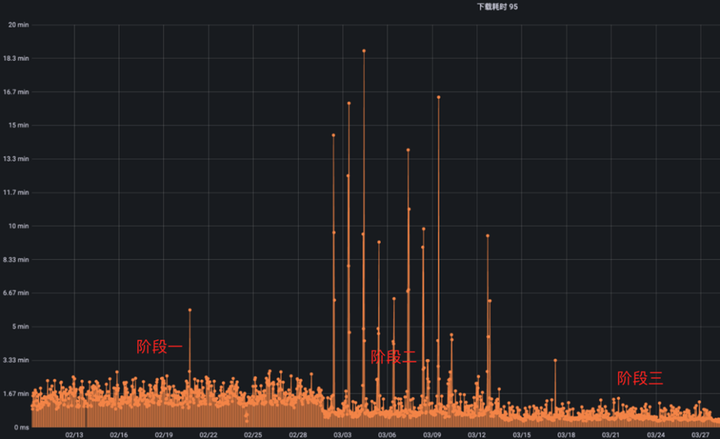
里面的每一條線段都代表著一個模型的讀取請求,線段的長短代表讀取數據的花費的時間。
其中階段一是我們內部的 UnionStore 服務,階段二是我們直接切換到 S3 Proxy 時的狀態,可以很明顯的看到換成 S3 Proxy 了以后,模型讀取的平均速度有所上升,但是出現了尖刺,也就是偶爾有請求讀取的很慢。問題出在模型讀取時,總是冷讀,也就是模型數據沒有經過預熱,在文件未預熱的情況下,從 Alluxio 讀數據最多只能達到與 HDFS 相同的速度,不能充分發揮緩存的能力。
而且通過測試,我們發現 Alluxio 在并發請求同一個沒有經過預熱的文件時,性能會下降的十分嚴重,甚至達不到直接讀 HDFS 的速度。因此我們需要想辦法預熱文件。
預熱文件的手段一般有以下兩種:
1) 用戶在寫完文件后,手動調用 Alluxio load 命令,提前將數據緩存,確保在讀取的時候,需要的文件已經被緩存了;
2) 根據 HDFS 的 audit log 或者利用 HDFS 的 inotify 來訂閱文件的變更,只要發現算法目錄下有文件變動就加載緩存進 Alluxio。
方式 1 的問題在于需要用戶深度參與,有額外的心智負擔和開發成本,其次是用戶調用 load 命令不可控,如果對一個超大目錄進行 load,將會使所有緩存失效。
方式 2 也需要用戶提供監聽的路徑,如果路徑是文件比較方便,只需要監聽 close 請求即可,但是路徑是目錄的情況下,涉及到臨時文件,rename 等,十分復雜;每次用戶新增模型時,都需要我們把路徑新加入監控,有額外的溝通成本;另外由于我們這個場景,數據產出與讀取的間隔在秒級,監控文件變更鏈路太長,可能出現一些延遲,從而導致預熱方案失效。
基于以上缺點,我們自己設計了一套緩存策略:
冷讀文件慢的本質在于通過 Alluxio 讀取未緩存文件時,讀到哪一個 block 才會去緩存這個 block,沒有做到并發緩存 block。因此我們在 S3 Proxy 上添加了一個邏輯,在讀取文件時,會將文件按 block 進行分段生成 cache block 任務,平均提交到每一個 Worker 來異步緩存。這樣的好處是,客戶端在讀取前面少量幾個未緩存的 block 后,后面的 block 都是已經緩存完畢的,讀取速度十分快。此外,由于提前緩存了 block,緩存穿透的問題也能有所緩解,HDFS 流量能夠下降 2 倍以上。
此緩存策略需要注意以下幾點:
1) 緩存 block 需要異步,并且所有的異常都要處理掉,不要影響正常的讀取請求;
2) 緩存 block 時,最好將 block id 與 Worker id 以某種方式(如 hash)進行綁定,這樣能保證在對同一個文件進行并發請求時,對某一個 block 的緩存請求都只打到同一個 Worker 上,避免不同的 Worker 從 UFS 讀取同一個 block,放大 UFS 流量;
3) S3 Proxy 需要對提交的 cache block 任務計數,避免提交過多任務影響 Worker 正常的緩存邏輯,最好不要超過配置 alluxio.worker.network.async.cache.manager.threads.max 的一半,這個配置代表 Worker 處理異步緩存請求的最大線程數,默認值是兩倍的 CPU 數;
4) S3 Proxy 需要對已經提交緩存的 block 進行去重,防止在高并發讀取同一個文件的情況下,多次提交同一個 block 的緩存請求到 Worker,占滿 Worker 的異步緩存隊列。Worker 的異步緩存隊列大小由配置 alluxio.worker.network.async.cache.manager.queue.max 控制,默認是 512。去重比較推薦使用 bitmap 按照 block id 做;
5) 在 Worker 異步緩存隊列沒滿的情況下,異步緩存的線程數將永遠保持在 4 個,需要修改代碼提高 Worker 異步緩存的最小線程數,防止效率過低,可參考 #17179。
在上線了這個緩存策略后,我們進入了階段三,可以看到,階段三的尖刺全部消失了,整體的速度略微有所提升。因為我們是對小文件(1GB 左右)進行的緩存,所以提升效果不明顯。經過我們測試,此緩存策略能夠提升讀取大文件(10GB 及以上)3-5 倍的速度,而且文件越大越明顯。
解決了緩存的問題后,我們繼續切換更多模型的讀取到 S3 Proxy,效果如下:
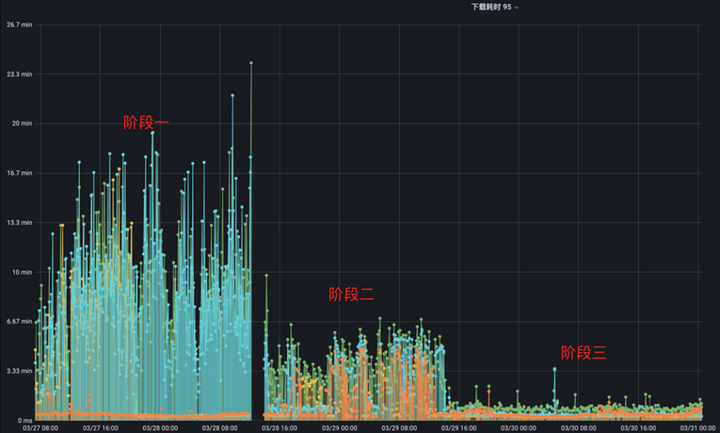
本次我們另外切換了三個模型的讀取請求到 S3 Proxy,其中橙色模型是我們之前已經切換到 S3 Proxy 的模型,本次新增的模型最大達到了 10G,讀取流量峰值為 500Gb/sec。
這次我們同樣分為三個階段,階段一是橙色模型已經切換到 S3 Proxy,其他模型都使用 UnionStore,因為橙色模型的數據量小,并且還用了 Alluxio 加速,所以它的讀取速度能夠比其他模型的讀取速度快上數十倍。
階段二是我們將其他模型也切換至 S3 Proxy 后的狀態,可以看到其他模型讀取速度明顯變快了,但是橙色模型讀取速度受到其他模型的影響反而變慢了,這是一個非常奇怪的現象。最后我們定位到是元數據緩存沒有開啟的原因,在元數據緩存沒有開啟的情況下,Alluxio 會將客戶端的每一次請求都打到 HDFS 上,加上 S3 Proxy 也會頻繁對一些系統目錄做檢查,這樣就導致 Master 同步元數據的負擔非常重,性能甚至能下降上千倍。
在這個場景,我們本來是不打算開啟元數據緩存的,主要是擔心業務對已緩存修改文件進行修改,導致讀取到錯誤的文件,從而影響模型的上線。但是從實踐的結果來看,元數據緩存必須要開啟來提升 Master 的性能。
與業務方溝通過后,我們制定了元數據一致性的規范:
1) 元數據緩存設置為 1min;
2) 新增文件盡量寫入新目錄,以版本號的方式管理,不要在舊文件上修改或覆蓋;
3) 對于歷史遺留,需要覆蓋新文件的任務,以及對元數據一致性要求比較高的任務,我們在 S3 Proxy 上提供特殊命令進行元數據的同步,數據更新后,業務方自己調用命令同步元數據。
在開啟元數據緩存過后,我們來到了圖中的階段三,可以很明顯的看到所有模型數據的讀取速度有了飛躍式提升,相比于最開始沒有使用 S3 Proxy 讀取速度提升了 10+ 倍。這里需要注意的是,10+ 倍是指在 Alluxio 機器數量足夠多,網卡足夠充足的情況下能達到的效果,我們在實際使用過程中,用了 UnionStore 一半的資源達到了與 UnionStore 同樣的效果。
3.4 S3 Proxy 限速
我們在模型讀取場景上線 Alluxio 的本意是為了提高業務方讀取模型的速度,但是因為通過 Alluxio 讀數據實在是太快了,反而需要我們給它限速,非常的具有戲劇性。不限速將會面臨一個很嚴重的問題:算法容器在讀取模型時,如果文件較大,不僅會影響 S3 Proxy 所在物理機的網卡,也會導致該容器所在的 k8s 宿主機的網卡長時間處于被占滿狀態,從而影響這一節點上的其他容器。
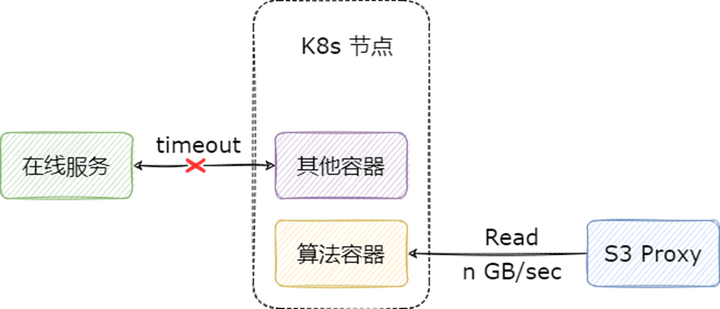
目前限速的實現主要有以下幾種方案:
Worker 端限速:優點是對所有客戶端生效,缺點是對同節點客戶端短路讀不生效,在我們的場景,S3 Proxy 會走短路讀,不能滿足我們的需求。
客戶端限速:優點是能夠同時對 Alluxio fuse 和 S3 Proxy 生效,缺點是客戶端可以自己改配置繞過限制,同時服務端版本和客戶端版本可能存在不一致的情況,導致限速失效。
S3 Proxy 限速:只能對 S3 Proxy 生效,對其他的客戶端以及 Worker 都不能生效。
因為我們當前的目標就是替代 UnionStore,業務方訪問 Alluxio 的入口只有 S3 Proxy,因此客戶端限速和 S3 Proxy 限速都能滿足我們的需求,但是從實現的難易角度上考慮,我們最后選擇了從 S3 Proxy 層面限速。
我們支持了兩種限速策略,一方面是 S3 Proxy 進程全局限速,用于保護 Worker 網卡不被打滿;另一方面是單連接限速,用于保護業務容器所在 k8s 節點。限速策略我們已經貢獻給了社區,如果感興趣可以參考:#16866。
4. 模型訓練場景適配
4.1 場景特點
我們的模型訓練場景有以下特點:
1) 因為大部分開源的模型訓練框架對本地目錄支持最好,所以我們最好是為業務提供 POSIX 訪問的方式;
2) 模型訓練時,主要瓶頸在 GPU,而內存,磁盤,網卡,CPU 等物理資源比較充足;
3) GPU 機器不會運行訓練任務以外的任務,不存在服務混布的情況;
4) 數據以快照形式管理,對元數據沒有一致性要求,但是需要有手段能夠感知 HDFS 上產生的新快照。
針對模型訓練場景,毫無疑問我們應該選擇 Alluxio fuse 來提供緩存服務:
1. Alluxio fuse 提供了 POSIX 訪問方式;
2. Alluxio fuse 能夠利用內存和磁盤做元數據緩存與數據緩存,能夠最大程度利用 GPU 機器上閑置的物理資源。
4.2 性能測試
在上線前,我們對 fuse 用 fio 進行了壓測。
Alluxio fuse 配置:

測試結果如下:
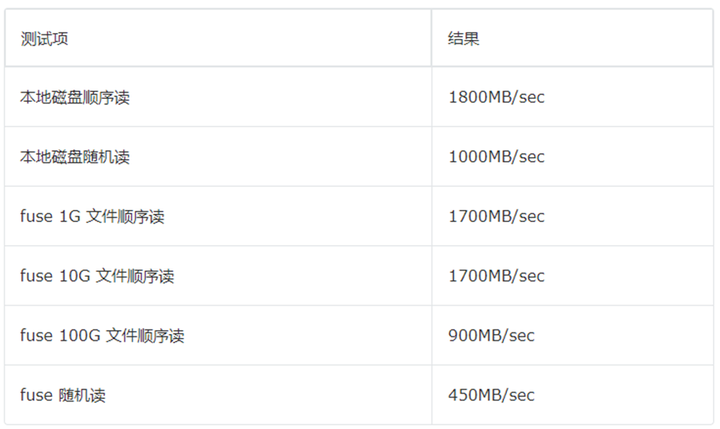
以上結果均針對數據已緩存至 fuse 本地磁盤的情況,1G 文件與 10G 文件讀取時,速度是 100G 文件的兩倍,這是因為容器的內存為 40G,有充足的 pagecache 來緩存 1G 與 10G 的文件,但是 100G 的文件沒有充足的 pagecache,所以性能會下降,但是也能達到不錯的速度,整體行為符合預期。
4.3 集群部署
Alluxio fuse 的部署方式我們選擇了以 DaemonSet 部署,通過 host path 進行映射,沒有選擇 CSI 部署,主要是基于以下考慮:
1) Alluxio fuse 高性能的核心在于數據緩存與元數據緩存,數據緩存需要消耗大量的磁盤,元數據緩存需要消耗大量的內存,如果以 CSI 的形式進行部署,每個容器只能分配到少量的磁盤與內存給 Alluxio fuse 進程;
2) 在模型進行訓練的時候,讀取的訓練數據重復程度很高,如果每個容器起一個 fuse 進程,可能會導致同一機器緩存多份相同的文件,浪費磁盤;
3) GPU 機器只跑訓練任務,所以 fuse 進程可以 long running,無需考慮資源釋放的問題;
4) host path 的部署方式可以很容易實現掛載點恢復。
這里對掛載點恢復做一個說明,一般情況下,如果 Alluxio fuse 容器因為各種異常掛了,哪怕 fuse 進程重新啟動起來,將目錄重新進行掛載,但是在業務容器里的掛載點也是壞掉的,業務也讀不了數據;但是如果做了掛載點恢復,Alluxio fuse 容器啟動起來以后,業務容器里的掛載點就會自動恢復,此時如果業務自身有重試邏輯,就能不受影響。
Alluxio fuse 進程的掛載點恢復包括兩個部分,一部分是掛載點本身的恢復,也就是 fuse 進程每次重啟后要掛到同一個掛載點;另一部分是客戶端緩存數據的恢復,也就是 fuse 進程每次重啟后緩存數據目錄要與原先保持一致,避免從 Alluxio 集群重復拉取已經緩存到本地的文件。掛載點恢復在 CSI 里需要做一些額外的開發來支持,但是如果是以 host path 的方式映射,只要在業務容器里配置了 HostToContainer 即可,不需要額外的開發。
我們 fuse 進程的部署架構圖如下:
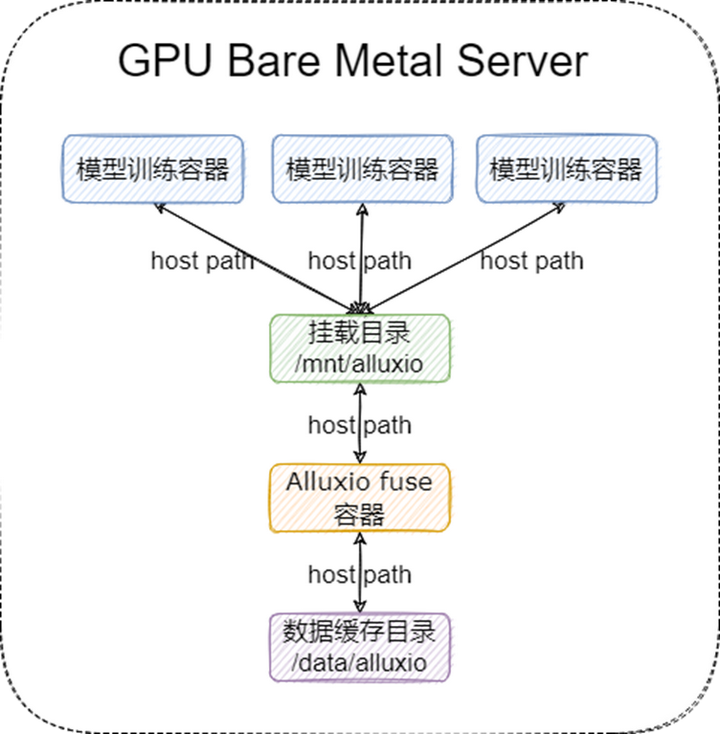
在這個場景下,我們的 Alluxio 集群采取了 “小集群重客戶端” 的方式來部署,即提供一個規模較小的 Alluxio 集群,只用來做數據的分發,性能和緩存由 Alluxio fuse 自身保證。Alluxio 集群只需要提供高配置的 Master 和少量的 Worker 即可,集群整體的部署架構如下:
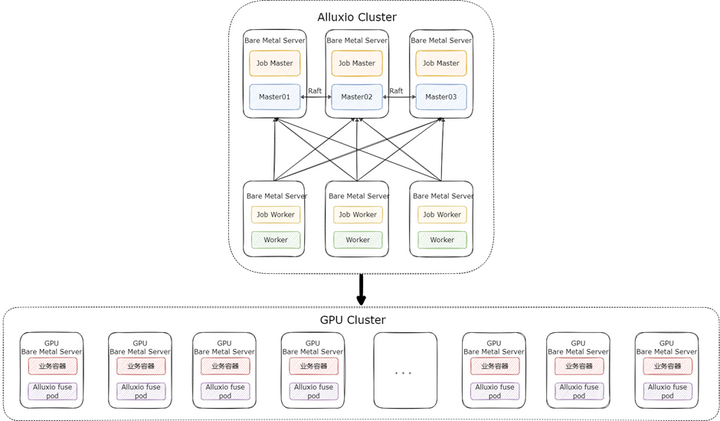
按照這種部署模式,3 臺 Raft HA 的 Master 與 少量 Worker 就可支撐起 fuse 進程大規模的部署。
4.4 Alluxio fuse 調優
首先是元數據緩存,Alluxio fuse 可開啟元數據緩存,這里容易與 Master 對 UFS 元數據的緩存弄混淆,我們簡單做個說明:
1) Alluxio Master 會緩存 UFS 的元數據,決定是否更新元數據由客戶端配置的 alluxio.user.file.metadata.sync.interval 決定。假如這個值設置為 10min,客戶端在請求 Master 時,如果 Master 在之前的 10min 內已經更新過元數據,則 Master 會直接返回緩存的元數據,而不會請求 UFS 拿最新的元數據;否則將會返回 UFS 的最新的元數據,并且更新 Master 的元數據
2) 用戶在用 Alluxio fuse 訪問 Alluxio 時,會先看內核緩存元數據是否失效(配置為 fuse 啟動參數 attr_timeout,entry_timeout),再看用戶空間元數據緩存是否失效(配置為 alluxio.user.metadata.cache.expiration.time),再看 Master 緩存是否失效(配置為 alluxio.user.file.metadata.sync.interval),只要有一層沒失效,都不能拿到 HDFS 的最新元數據。
所以建議在開啟 fuse 元數據緩存后,設置 alluxio.user.file.metadata.sync.interval=0 以便每次 fuse 在本地元數據緩存失效后,都能拿到 UFS 最新的元數據。
另外 fuse 的元數據緩存可以通過一些特殊的命令來更新(需要配置 alluxio.fuse.special.command.enabled=true):
元數據緩存可通過以下命令進行強制刷新,假設我們的 mount 目錄為 /mnt/alluxio,利用以下命令可以刷新所有元數據緩存:
ls -l /mnt/alluxio/.alluxiocli.metadatacache.dropAll
利用以下命令可以刷新指定目錄(這里以 /user/test 為例)的元數據緩存
ls -l /mnt/alluxio/user/test/.alluxiocli.metadatacache.drop
在代碼中(以 python 為例),可以這樣清理元數據:
import os print(os.path.getsize("/mnt/alluxio/user/test/.alluxiocli.metadatacache.drop"))
但是需要注意,內核元數據緩存是清理不掉的,所以這里推薦內核元數據緩存設置一個較小的值,比如一分鐘,用戶空間元數據緩存設置一個較大的值,比如一小時,在對元數據有一致性要求的時候,手動刷新用戶空間元數據緩存后,等待內核元數據緩存失效即可。
元數據緩存和數據緩存同時開啟的情況下,清理元數據緩存的命令在使用上會有一些問題,我們進行了修復,參考:#17029。
其次就是數據緩存,我們的 Alluxio fuse 因為是用 DeamonSet 的方式進行的部署,所以數據緩存我們基本上可以用滿整臺物理機的磁盤,極大降低了 Alluxio Worker 的流量。
最后就是資源配置,因為每個機器只起一個 fuse 進程,所以可以適當給 fuse 進程多分配給一些 CPU 和內存,CPU 可以適當超賣,以處理突然激增的請求。 內存方面,首先是堆內存的配置,如果開啟了用戶空間元數據緩存,按照 緩存路徑量數 * 2KB * 2 來設置 Xmx。另外 DirectoryMemory 可設置大一點,一般 8G 夠用。
如果開啟了內核數據緩存,還需要給容器留存一些空間來存放 pagecache,因為 kubernetes 計算容器內存使用量會包含 pagecache 的使用量。關于 pagecache 是否會引起容器 OOM,我們查找了很多文檔都沒有得到準確的結論,但是我們用如下配置進行了壓測,發現容器并不會 OOM,并且 fuse 的表現十分穩定:

4.5 上線結果
我們的算法模型訓練切換至 Alluxio fuse 后,模型訓練的效率達到了本地磁盤 90% 的性能,相比于原來 UnionStore 的 s3fs-fuse 的掛載,性能提升了約 250%。
五、S3 Proxy 在大數據場景的應用
回顧模型上線場景,我們不僅為算法業務提供了模型加速讀取的能力,還沉淀下來了一個與對象存儲協議兼容,但是下載速度遠超普通對象存儲的組件,那就是 Alluxio S3 Proxy,所以我們現在完全可以做一些” 拿著錘子找釘子 “的一些事情。 這里介紹一下我們大數據組件的發布與上線流程,流程圖大致如下:
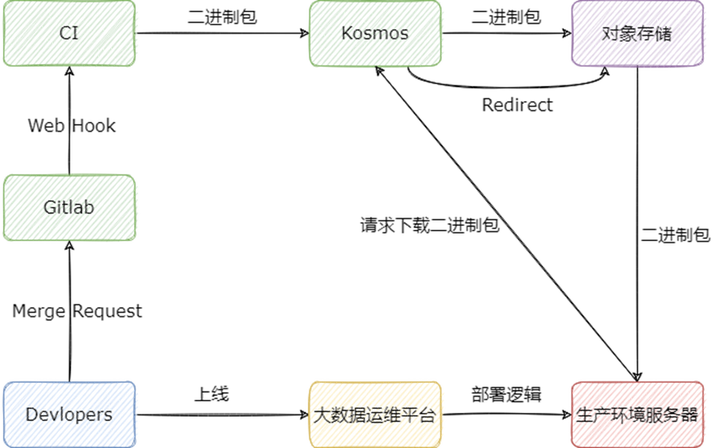
下面用文字簡單描述:
1) 開發者修改代碼以后,將代碼合入對應組件的 master 分支,此時 Gitlab 將調用 CI 的 Web Hook,CI 會運行對應組件的打包編譯邏輯;
2) 組件打包成二進制包后,CI 會向 Kosmos 注冊二進制包的元信息,以及將二進制包上傳至 Kosmos,Kosmos 在接受到二進制包后,會上傳至對象存儲;
3) 開發者在大數據運維平臺選擇要上線的組件,以及組件的版本,大數據組件會自動在生產環境的服務器上運行部署邏輯;
4) 在部署邏輯運行的過程中,會向 Kosmos 請求下載組件的二進制包,Kosmos 將會直接返回對象存儲的只讀鏈接,供生產環境服務器進行下載。
其中 Kosmos 是我們自研的包管理系統,其誕生的背景可以參考:Flink 實時計算平臺在知乎的演進;另外我們的大數據運維平臺也有相應的專欄,感興趣可以查看:Ansible 在知乎大數據的實踐。
一方面,這個流程最大的問題在于大規模上線節點時,從對象存儲下載二進制包速度過慢。比如我們要對所有的 DataNode 節點以及 NodeManager 節點做變更時,每臺機器都需要下載數百 MB 甚至上 GB 的二進制包,按照對象存儲 20-30MB/sec 的下載速度,每臺機器需要花費約 30 秒的時間來進行下載,占了整個部署邏輯約 2/3 的時間。如果按照 10000 臺 DataNode 來計算,每兩臺滾動重啟(保證三副本一個副本可用),僅僅花費在下載二進制包上的時間就達到了 40+ 小時,及其影響部署效率。
另一方面,對象存儲在不同的機房使用時,也會面臨外網流量的問題,造成比較高的費用;所以這里對 Kosmos 做了多機房改造,支持向不同的對象存儲上傳二進制包,用戶在請求 Kosmos 時,需要在請求上加上機房參數,以便從 Kosmos 獲取同機房對象存儲的下載鏈接,如果用戶選錯了機房,依然會使用外網流量。
上述問題其實可以通過改造大數據運維平臺來解決,比如將下載與部署邏輯解耦,在節點上以較高的并發下載二進制包后再進行滾動部署,但是改造起來比較費時費力,更何況我們現在有了更高效下載文件的方式 — Alluxio S3 Proxy,所以更沒有動力來做這個改造了。
我們將 Kosmos 的對象存儲掛載到 Alluxio 上,Kosmos 在被請求下載時,返回 Alluxio S3 Proxy 的只讀鏈接,讓用戶從 S3 Proxy 讀取數據,改造后的流程圖如下:

經過我們的改造,Kosmos 幾乎所有的下載請求都能在 1-2 秒內完成,相比于從對象存儲下載,快了 90% 以上,下圖是我們的生產環境中,Kosmos 分別對接對象存儲與 Alluxio 的下載速度對比,其中 Alluxio S3 Proxy 被我們限速至 600MB/sec:
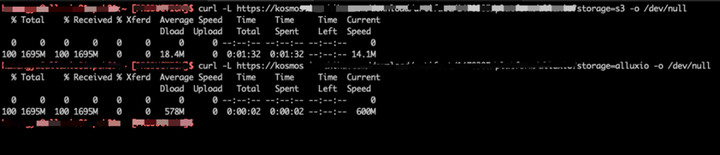
此外 Alluxio 我們也進行了多機房部署,支持了 Kosmos 的多機房方案,哪怕是用戶選錯了機房,也不會造成額外的外網流量,僅僅只是會請求其他機房的 Alluxio 集群,消耗一定的專線帶寬。
六、權限相關
Alluxio 在與 HDFS 對接時,會繼承 HDFS 的文件權限系統,而 HDFS 與 Alluxio 的用戶可能不一致,容易造成權限問題。權限問題比較重要,所以我們單獨用一個章節來做介紹。
我們通過研究代碼與測試,總結了基于 Alluxio 2.9.2 版本(HDFS 與 Alluxio 的認證方式都是 SIMPLE),用戶與權限的映射關系,總覽圖如下:
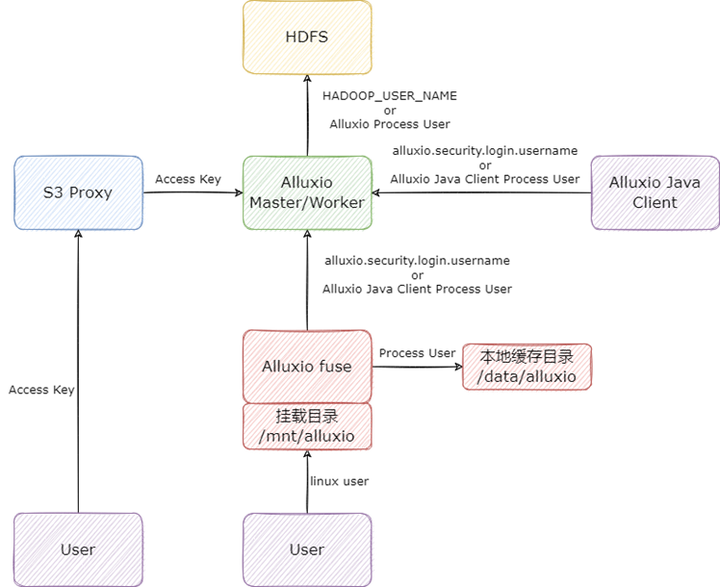
首先是 Alluxio Java Client 的用戶:Alluxio Java Client 與 Alluxio 交互時,如果配置了 alluxio.security.login.username,Alluxio 客戶端將會以配置的用戶訪問 Alluxio 集群,否則將會以 Alluxio Java Client 的啟動用戶訪問 Alluxio。
Alluxio Master/Worker 在與 HDFS 交互時,如果 Master/Worker 在啟動時配置了環境變量 HADOOP_USER_NAME(可在 alluxio-env.sh 配置),則 Master/Worker 將會以配置的用戶訪問 HDFS,否則將會以 Master/Worker 的進程啟動用戶訪問 HDFS。這里需要注意,Master 和 Worker 盡量配置一樣的 HDFS 用戶,否則一定會造成權限問題。
在向 HDFS 寫入文件時,Alluxio 會先以 Master/Worker 配置的 HDFS 用戶寫入文件,寫完以后會調用 HDFS 的 chown 命令,將文件的 owner 修改為 Alluxio Java Client 的用戶,這里我們舉例說明:假設 Alluxio 啟動用戶為 alluxio,Alluxio Java Client 用戶為 test,在向 HDFS 寫入文件時,Alluxio 會先將文件以 alluxio 賬號寫到 HDFS 上,再將文件 chown 變成 test 用戶,這時如果 alluxio 用戶不是 HDFS 超級用戶,在 chown 時會發生錯誤(比較坑的一點是這個錯誤 alluxio 不會拋出給客戶端),導致 Alluxio 上看到的文件 owner 是 test,但是 HDFS 上的文件 owner 時 alluxio,造成元數據不一致。
其次是 S3 Proxy 的用戶,S3 Proxy 它也是一個比較特殊的 Alluxio Java Client,但同時它也是一個 Server 端,這里主要是用戶請求 S3 Proxy 的 AK SK 與 HDFS 用戶的映射。S3 Proxy 默認會將用戶的 AK 映射成訪問 Alluxio 集群的用戶,這里也可以自己實現映射關系,比如將 AK 映射成特定的用戶,S3 Proxy 里有相關插件。
最后是 Alluxio fuse 的用戶,Alluxio fuse 因為涉及到 linux 文件系統,而且有多種與 linux 本地文件系統相關的實現,所以比前面的更加復雜,這里我們只討論默認情況,也就是 alluxio.fuse.auth.policy.class=alluxio.fuse.auth.LaunchUserGroupAuthPolicy 時的情況。用戶在訪問掛載目錄時,用的是當前 linux 用戶,用戶看到掛載目錄里所有文件的 owner 都是 fuse 進程啟動用戶;fuse 在寫本地緩存目錄時,用的是 fuse 進程的啟動用戶,此外 fuse 進程與 Alluxio 集群交互時又完全遵循 Alluxio Java Client 的邏輯。
綜上所述,比較推薦的用戶設置方式為:
1) Alluxio 集群使用 alluxio 賬號啟動,并且將 alluxio 賬號設置為 HDFS 超級用戶;
2) S3 Proxy 用 alluxio 賬號啟動,用戶訪問時,AK 為 HDFS 賬號;
3) Alluxio fuse 以 root 用戶啟動,防止寫本地數據沒有權限,并且加上 allow_other 參數,配置 alluxio.security.login.username 為 HDFS 用戶。
七、其他問題
在上線過程中,我們遇到了很多問題,其中大部分都跟配置項調優有關。遇到這些問題的原因主要還是因為 Alluxio 是面相通用設計的緩存系統,而用戶的場景各式各樣,很難通過默認配置完美適配,比如我們有多套 Alluxio 集群,每套集群用來解決不同的問題,所以這些集群的配置都有些許差異。多虧 Alluxio 提供了許多靈活的配置,大部分問題都能通過修改配置解決,所以這里只介紹一些讓我們印象深刻的 “代表”。
最大副本數:在模型上線場景,緩存副本數我們不設上限,因為在算法模型在讀取時,往往是一個大模型同時幾十個甚至上百個容器去讀,占用的存儲不多,但是讀取次數多,并且僅高并發讀取這一次,很少有再讀第二次的情況。所以這里對每一個緩存文件副本數不做限制,可以讓每個 Worker 都緩存一份,這樣能夠達到最大的吞吐,擁有最好的性能。在模型訓練場景,我們將緩存副本數設置為 3,一方面是因為訓練數據量很大,需要節省存儲,另一方面是 Alluxio fuse 的本地緩存會承擔大部分流量,所以對于 Worker 的吞吐要求相對較低。
S3 Proxy ListObjects 問題:我們發現 S3 Proxy 在實現 ListObjects 請求時,會忽略 maxkeys 參數,列出大量不需要的目錄。比如我們請求的 prefix 是 /tmp/b, maxkeys 是 1,S3 Proxy 會遞歸列出 /tmp 下所有文件,再從所有文件里挑選出滿足 prefix /tmp/b 的第一條數據,這樣不僅性能差,也會導致可能出現 OOM 的情況,我們采用臨時方案進行的修復,感興趣可以參考 #16926。這個問題比較復雜,需要 Master 與 S3 Proxy 聯合去解決,可以期待 #16132 的進展。
監控地址沖突:我們監控采用的是 Prometheus 方案,Alluxio 暴露了一部分指標,但是 JVM 指標需要額外在 Master 或者 Worker 的啟動參數中添加 agent 與端口暴露出來,添加 agent 以后,因為 monitor 會繼承 Master 與 Worker 的啟動參數,所以 monitor 也會嘗試使用與 Master 和 Worker 同樣的指標端口,這會出現 ”Address already in use“ 的錯誤,從而導致 monitor 啟動失敗。具體可查看 #16657。
Master 異常加載 UFS 全量元數據:如果一個路徑下有 UFS mount 路徑,在對這個路徑調用 getStatus 方法時,Alluxio master 會遞歸同步這個路徑下的所有文件的元信息。比如 /a 路徑下的 /a/b 路徑是 UFS 的 mount 路徑,在調用 getStatus ("/a") 的時候,會導致 /a 下面的元數據被全量加載。如果 /a 是一個大路徑,可能會導致 Master 因為加載了過多的元數據而頻繁 GC 甚至卡死。具體可查看 #16922。
Master 頻繁更新 access time:我們在使用過程中,發現 Master 偶爾會很卡,通過 Alluxio 社區同學的幫助,定位到問題來自 Master 頻繁更新文件的最后訪問時間,通過合入 #16981,我們解決了這個問題。
八、總結與展望
其實從 2022 年的下半年我們就開始調研 Alluxio 了,但是因為種種原因,中途擱置了一段時間,導致 Alluxio 推遲到今年才上線。在我們調研與上線的過程中,Alluxio 社區是我們最強大的外援,為我們提供了海量的幫助。
本次我們在算法場景對 Alluxio 小試牛刀,取得的結果令人十分驚喜。
從性能上講,在算法模型上線的場景,我們將 UnionStore 用 Alluxio 替換后,最高能夠獲得數十倍的性能提升;在模型訓練場景,我們配合 Alluxio fuse 的本地數據緩存,能夠達到近似本地 NVME 磁盤的速度,相比于 UnionStore + s3fs-fuse 的方案,性能提升了 2-3 倍。
從穩定性上講,在 HDFS 抖動或者升級切主的時候,因為有數據緩存和元數據緩存,Alluxio 能夠在一定時間內不受影響,正常提供服務。 從成本上講,Alluxio 相比于 UnionStore 每年為我們節省了數十萬真金白銀,而且性能上還有盈余。
從長遠的發展來看,Alluxio 具有強大的可擴展性,尤其是 Alluxio 的新一代架構 Dora ,能夠支持我們對海量小文件緩存的需求,這讓我們更有信心支撐算法團隊,面對即將到來的人工智能浪潮。 最后再次感謝 Alluxio 團隊,在我們上線的過程中為我們提供了大量的幫助與建議,也希望我們后續能夠在大數據 OLAP 查詢加速場景以及分布式數據集編排領域繼續深入合作與交流。
【案例二:螞蟻】Alluxio 在螞蟻集團大規模訓練中的應用
一、背景介紹
首先是我們為什么要引入 Alluxio,其實我們面臨的問題和業界基本上是相同的:
第一個是存儲 IO 的性能問題,目前 gpu 的模型訓練速度越來越快,勢必會對底層存儲造成一定的壓力,如果底層存儲難以支持目前 gpu 的訓練速度,就會嚴重制約模型訓練的效率。
第二個是單機存儲容量問題,目前我們的模型集合越來越大,那么勢必會造成單機無法存放的問題。那么對于這種大模型訓練,我們是如何支持的?
第三個是網絡延遲問題,目前我們有很多存儲解決方案,但都沒辦法把一個高吞吐、高并發以及低延時的性能融合到一起,而 Alluxio 為我們提供了一套解決方案,Alluxio 比較小型化,隨搭隨用,可以和計算機型部署在同一個機房,這樣可以把網絡延時、性能損耗降到最低,主要出于這個原因我們決定把 Alluxio 引入螞蟻集團。
以下是分享的核心內容:總共分為 3 個部分,也就是 Alluxio 引入螞蟻集團之后,我們主要從以下三個方面進行了性能優化:第一部分是穩定性建設、 第二部分是性能優化、第三部分是規模提升。
二、穩定性建設
首先介紹為什么要做穩定性的建設,如果我們的資源是受 k8s 調度的,然后我們頻繁的做資源重啟或者遷移,那么我們就需要面臨集群頻繁的做 FO,FO 的性能會直接反映到用戶的體驗上,如果我們的 FO 時間兩分鐘不可用,那么用戶可能就會看到有大量的報錯,如果幾個小時不可用,那用戶的模型訓練可能就會直接 kill 掉,所以穩定性建設是至關重要的,我們做的優化主要是從兩塊進行:一個是 worker register follower,另外一個是 master 遷移。
1.Worker Register Follower
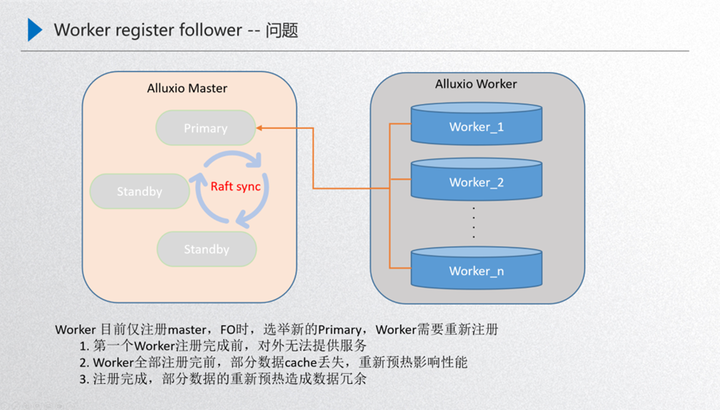
先介紹下這個問題的背景:上圖是我們 Alluxio 運行的穩定狀態,由 master 進行元數據服務,然后內部通過 raft 的進行元數據一致性的同步,通過 primary 對外提供元數據的服務,然后通過 worker 節點對外提供 data 數據的服務,這兩者之間是通過 worker 注冊 primary 進行一個發現,也就是 worker 節點的發現,這樣就可以保證在穩定狀態下運行。那如果這時候對 primary 進行了重啟,就需要做一次 FO 的遷移,也就是接下來這個過程,比如這時候對 primary 進行了重啟,那么內部的 standby 就需要通過 raft 進行重新選舉,選舉出來之前,其實 primary 的元數據和 worker 是斷聯的,斷連的狀態下就需要進行 raft 的一致性選舉,進行一次故障的轉移,接下來如果這臺機器選舉出來一個新的 primary,這個時候 work 就需要重新進行一次發現,發現之后注冊到 primary 里面,這時新的 primary 就對外提供元數據的服務,而 worker 對外提供 data 數據的服務,這樣就完成了一次故障的轉移,那么問題點就發生在故障發生在做 FO 的時候,worker 發現新的 primary 后需要重新進行一次注冊,這個部分主要面臨三個問題:
第一個就是首個 worker 注冊前集群是不可用的,因為剛開始首個 worker 恢復了新的 primary 領導能力,如果這個時候沒有 worker,其實整個 primary 是沒有 data 節點的,也就是只能訪問元數據而不能訪問 data 數據。
第二個是所有 worker 注冊過程中,冷數據對性能的影響。如果首個 worker 注冊進來了,這時就可以對外提供服務,因為有 data 節點了,而在陸續的注冊的過程當中如果首個節點注冊進來了,然后后續的節點在注冊的過程當中,用戶訪問 worker2 的緩存 block 的時候,worker2 處于一種 miss 的狀態,這時候 data 數據是丟失的,會從現存的 worker 中選舉出來到底層去讀文件,把文件讀進來后重新對外提供服務,但是讀的過程當中,比如說 worker1 去 ufs 里面讀的時候,這就牽扯了一個預熱的過程,會把性能拖慢,這就是注冊當中的問題。
第三個是 worker 注冊完成之后的數據冗余清理問題。注冊完成之后,其實還有一個問題就是在注冊的過程當中不斷有少量數據進行了重新預熱,worker 全部注冊之后,注冊過程中重新緩存的這部分數據就會造成冗余, 那就需要進行事后清理,按照這個嚴重等級其實就是第一個 worker 注冊前,這個集群不可用,如果 worker 規格比較小,可能注冊的時間 2-5 分鐘,這 2-5 分鐘這個集群可能就不可用,那用戶看到的就是大量報錯,如果 worker 規格比較大,例如一個磁盤有幾 tb 的體量,完全注冊上來需要幾個小時。那這幾個小時整個集群就不可對外提供服務,這樣在用戶看來這個集群是不穩定的,所以這個部分是必須要進行優化的。
我們目前的優化方案是:把所有的 worker 向所有的 master 進行注冊,提前進行注冊,只要 worker 起來了 那就向所有的 master 重新注冊一遍,然后中間通過這種實時的心跳保持 worker 狀態的更新。那么這個優化到底產生了怎樣效果?可以看下圖:
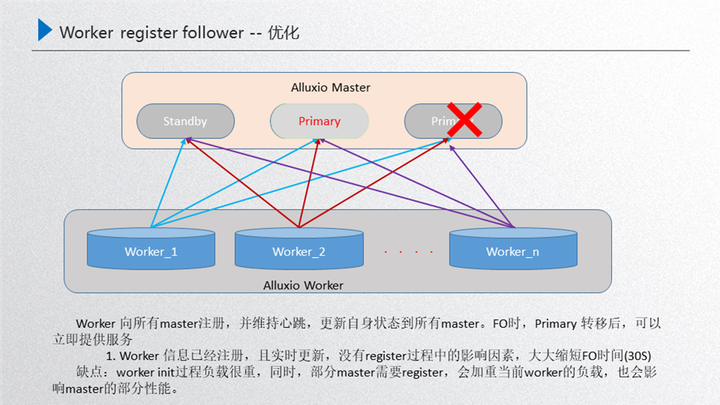
這個時候如果 primary 被重啟了,內部通過 raft 進行選舉,選舉出來的這個新的 primary 對外提供服務,primary 的選舉需要經歷幾部分:第一部分就是 primary 被重啟之后,raft 進行自發現,自發現之后兩者之間進行重新選舉,選舉出來之后這個新的 primary 經過 catch up 后就可以對外提供服務了,就不需要重新去獲取 worker 進行一個 register,所以這就可以把時間完全節省下來,只需要三步:自發現、選舉、catch up。 這個方案的效率非常高,只需要 30 秒以內就可以完成,這就大大縮短了 FO 的時間。另一個層面來說,這里也有一些負面的影響,主要是其中一個 master 如果進行了重啟,那么對外來說這個 primary 是可以提供正常服務的,然后這個 standby 重啟的話,在對外提供服務的同時,worker 又需要重新注冊這個 block 的元數據信息,這個 block 元數據信息其實流量是非常大的,這時會對當前的 worker 有一定影響,而且對部分注冊上來的 master 性能也有影響,如果這個時候集群的負載不是很重的話,是完全可以忽略的,所以做了這樣的優化。
2.Master 的遷移問題
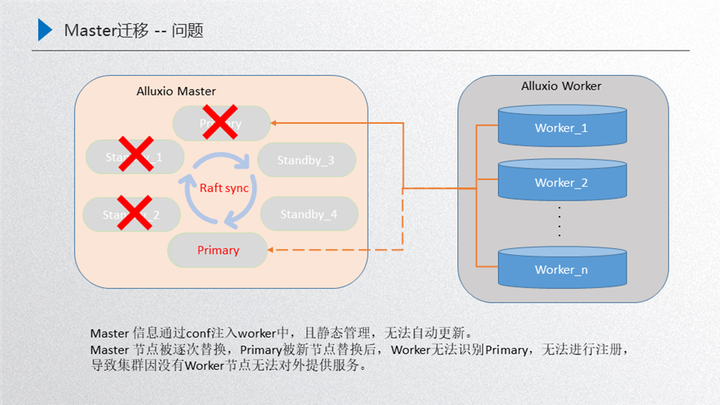
如圖所示,其實剛開始是由這三者 master 對外提供服務, 這三者達到一個穩定的狀態,然后 worker 注冊到 primary 對外提供服務,這個時候如果對機器做了一些騰挪,比如 standby3 把 standby1 替換掉,然后 standby4 把 standby2 替換掉,然后新的 primary 把老的 primary 替換掉,這個時候新的這個 master 的集群節點就是由這三者組成:standby3、standby4、新的 primary,按照正常的流程來說,這個 worker 是需要跟當前這個新的集群進行建聯的,維持一個正常的心跳,然后對外提供服務,但是這時候并沒有,主要原因就是 worker 識別的 master 信息其實是一開始由 configer 進行靜態注入的,在初始化的時候就已經寫進去了,而且后臺是靜態管理的,沒有動態的更新,所以永遠都不能識別這三個節點, 識別的永遠是三個老節點,相當于是說這種場景直接把整個集群搞掛了,對外沒有 data 節點就不可提供服務了,恢復手段主要是需要手動把這三個新節點注冊到 configer 當中,重新把這個 worker 重啟一遍,然后進行識別,如果這個時候集群規模比較大,worker 節點數量比較多,那這時的運維成本就會非常大,這是我們面臨的 master 遷移問題,接下來看一下怎么應對這種穩定性:
我們的解決方案是在 primary 和 worker 之間維持了一個主心跳,如果 master 節點變更了就會通過主心跳同步當前的 worker,實現實時更新 master 節點,比如 standby3 把 standby1 替換掉了,這個時候 primary 會把當前的這三個節點:primary、standby2、standby3 通過主心跳同步過來給當前的 worker,這個時候 worker 就是最新的,如果再把 standby4、standby2 替換,這時候又會把這三者之間的狀態同步過來,讓他保持是最新的,如果接下來把新的 primary 加進來,就把這四者之間同步過來,重啟之后進行選舉,選舉出來之后 這就是新的 primary,由于 worker 節點最后的一步是存著這四個節點,在這四個節點當中便利尋找當前的 leader,然后就可以識別新的 primary,再把這三個新的 master 同步過來 這樣就達到一個安全的迭代過程,這樣的情況下再受資源調度騰挪的時候,就可以穩定的騰挪下去。以上兩部分就是穩定性建設的內容。
三、性能優化
性能優化我們主要進行了 follower read only 的過程,首先給大家介紹一下背景,如圖所示:
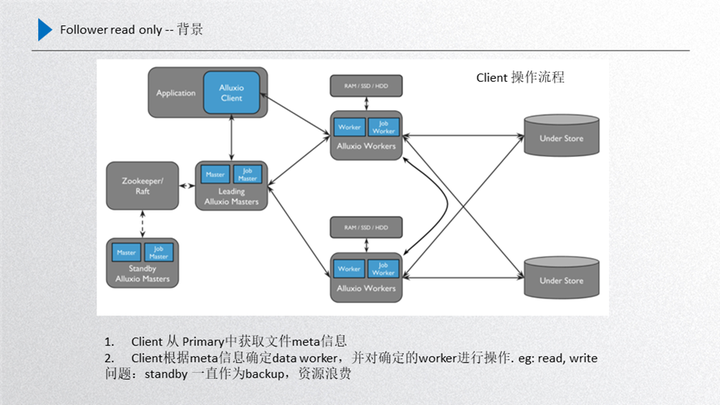
這個是當前 Alluxio 的整體框架,首先 client 端從 leader 拿取到元數據,根據元數據去訪問正常的 worker,leader 和 standby 之間通過 raft 進行與元數據一致性的同步,leader 進行元數據的同步只能通過 leader 發起然后同步到 standby,所以說他是有先后順序的。而 standby 不能通過發起新的信息同步到 leader,這是一個違背數據一致性原則的問題。
另一部分就是當前的這個 standby 經過前面的 worker register follower 的優化之后,其實 standby 和 worker 之間也是有一定聯系的,而且數據都會收集上來,這樣就是 standby 在數據的完整性上已經具備了 leader 的屬性,也就是數據基本上和 leader 是保持一致的。
而這一部分如果再把它作為 backup,即作為一種穩定性備份的話,其實就是一種資源的浪費,想利用起來但又不能打破 raft 數據一致性的規則,這種情況下我們就嘗試是不是可以提供只讀服務, 因為只讀服務不需要更新 raft 的 journal entry,對一致性沒有任何的影響,這樣 standby 的性能就可以充分利用起來,所以說這里想了一些優化的方案,而且還牽扯了一個業務場景,就是如果我們的場景適用于模型訓練或者文件的 cache 加速的,那只有第一次預熱的時候數據才會有寫入,后面是只讀的,針對大量只讀場景應用 standby 對整個集群的性能取勝是非常可觀的。
下面是詳細的優化方案,如圖所示:
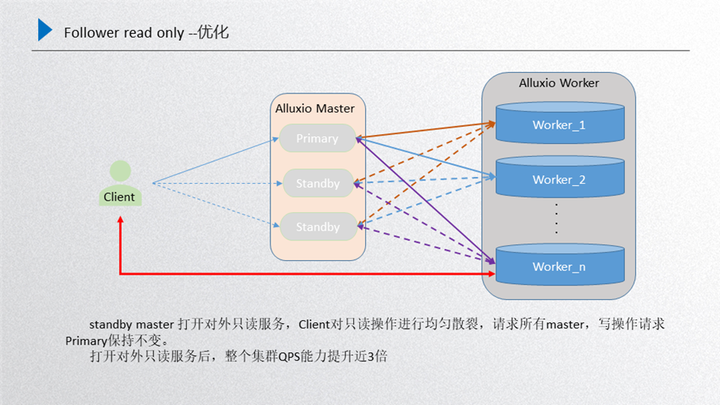
主要是針對前面進行的總結,所有的 worker 向所有的 standby 進行注冊,這時候 standby 的數據和 primary 的數據基本上是一致的,另一部分還是 primary 和 worker 之間維護的主心跳,這個時候如果 client 端再發起只讀請求的時候,就會隨機散列到當前所有的 master 上由他們進行處理,處理完成之后返回 client 端,對于寫的請求還是會發放到 primary 上去。然后在不打破 raft 一致性的前提下,又可以把只讀的性能提升,這個機器擴展出來,按照正常推理來說,只讀性能能夠達到三倍以上的擴展,通過 follower read 實際測驗下來效果也是比較明顯的。這是我們引入 Alluxio 之后對性能的優化。
四、規模提升
規模提升主要是橫向擴展,首先看一下這個問題的背景:如圖所示:
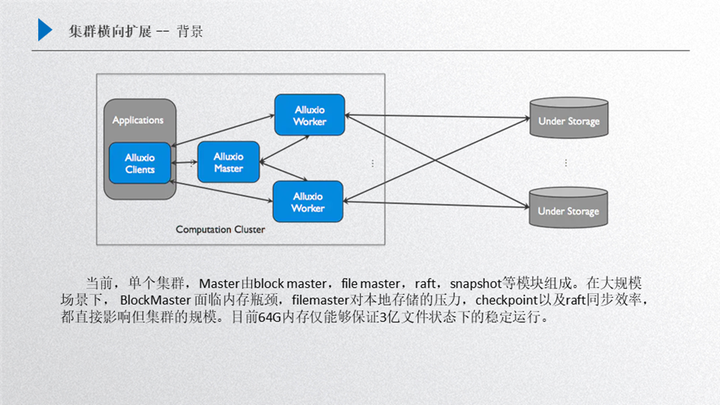
還是 Alluxio 的框架,master 里面主要包含了很多構件元素,第一個就是 block master,第二個是 file master,另外還有 raft 和 snapshot,這個部分的主要影響因素就是在這四個方面:
Bblock master,如果我們是大規模集群創建下,block master 面臨的瓶頸就是內存,它會侵占掉大量 master 的內存,主要是保存的 worker 的 block 信息;
File master,主要是保存了 inode 信息,如果是大規模場景下,對本地存儲的壓力是非常大的
Raft 面臨的同步效率問題;
snapshot 的效率,如果 snapshot 的效率跟不上,可以發現后臺會積壓非常多 journal entry,這對性能提升也有一定影響;
做了一些測試之后,在大規模場景下,其實機器規格不是很大的話,也就支持 3-6 個億這樣的規模,如果想支持 10 億甚至上百億這樣的規模,全部靠擴大存儲機器的規格是不現實的,因為模型訓練的規模可以無限增長,但是機器的規格不可以無限擴充,那么針對這個問題我們是如何優化的呢?
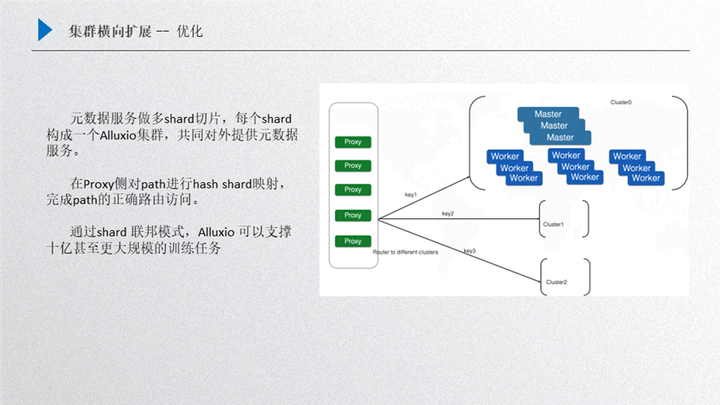
這個優化我們主要借鑒了 Redis 的實現方案,就是可以在底層對元數據進行分片,然后由多個 cluster 集群對外提供服務,這樣做的一個好處就是對外可以提供一個整體,當然也可以采取不同的優化策略,比如多個集群完全由用戶自己去掌控,把不同的數據分配到每一個集群上,但這樣對用戶的使用壓力就會比較大。先來介紹一下這個框架,首先我們把這個元數據進行一個分片,比如用戶拿到的整體數據規模集合比較大,單集群放不下了,這時候會把大規模的數據集合進行一個分片,把元數據進行一些哈希(Hash)映射,把一定 hash 的值映射到其中某一個 shard 上,這樣 cluster 這個小集群就只需要去緩存對應部分 key 對應的文件,這樣就可以在集群上面有目標性的進行選擇。
那么接下來其他的數據就會留給其他 cluster,把全量的 hash 分配到一個設定的集群規模上,這樣就可以通過幾個 shard 把整個大的模型訓練文件數量 cache 下來,對外提供大規模的模型訓練,然后我們的前端是增加了 proxy,proxy 其實內部是維護一張 hash 映射表的,用戶過來的請求其實是通過 proxy 進行 hash 的映射查找,然后分配到固定的某一個集群上進行處理,比如過來的一個文件請求通過計算它的 hash 映射可以判定 hash 映射路由到 cluster1 上面去,這樣其實就可以由 cluster1 負責,其他 key 的映射分配到其他 cluster 上,把數據打散,這樣的好處有很多方面:
第一個就是元數據承載能力變大了;
第二個就把請求的壓力分配到多個集群上去,整體的 qps 能力、集群的吞吐能力都會得到相應的提升;
第三個就是通過這種方案,理論上可以擴展出很多的 cluster 集群,如果單個集群支持的規模是 3-6 個億,那三個集群支持的規模就是 9-18 億,如果擴展的更多,對百億這種規模也可以提供一種支持的解決方案。
以上是我們對模型進行的一些優化。整個的框架包括穩定性的建設、性能的優化和規模的提升。
在穩定建設方面:我們可以把整個集群做 FO 的時間控制在 30 秒以內,如果再配合一些其他機制,比如 client 端有一些元數據緩存機制,就可以達到一種用戶無感知的條件下進行 FO,這種效果其實也是用戶最想要的,在他們無感知的情況下,底層做的任何東西都可以恢復,他們的業務訓練也不會中斷,也不會有感到任何的錯誤,所以這種方式對用戶來說是比較友好的。
在性能優化方面:單個集群的吞吐已經形成了三倍以上提升,整個性能也會提升上來,可以支持更大并發的模型訓練任務。
在模型規模提升方面:模型訓練集合越來越大,可以把這種模型訓練引入進來,對外提供支持。
在 Alluxio 引入螞蟻適配這些優化之后,目前運行下來對各個方向業務的支持效果都是比較明顯的。另外目前我們跟開源社區也有很多的合作,社區也給我們提供很多幫助,比如在一些比較著急的問題上,可以給我們提供一些解決方案和幫助,在此我們表示感謝!
【案例三:微軟】面向大規模深度學習訓練的緩存優化實踐
分享嘉賓:張虔熙 - 微軟高級研發工程師
導讀
近些年,隨著深度學習的崛起, Alluxio 分布式緩存技術逐步成為業界解決云上 IO 性能問題的主流方案。不僅如此,Alluxio 還天然具備數據湖所需的統一管理和訪問的能力。本文將分享面向大規模深度學習訓練的緩存優化,主要分析如今大規模深度學習訓練的存儲現狀與挑戰,說明緩存數據編排在深度學習訓練中的應用,并介紹大規模緩存系統的資源分配與調度。
一、項目背景和緩存策略
首先來分享一下相關背景。
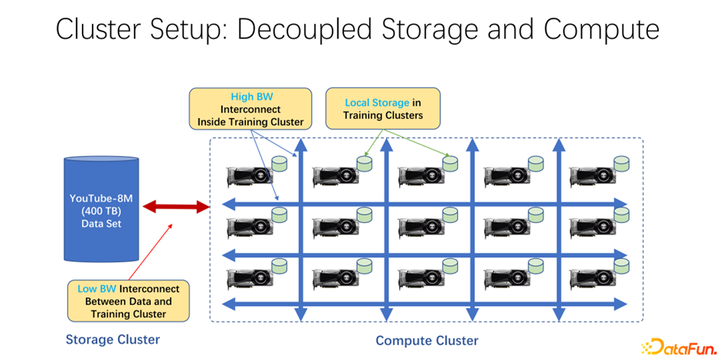
近年來,AI 訓練應用越來越廣泛。從基礎架構角度來看,無論是大數據還是 AI 訓練集群中,大多使用存儲與計算分離的架構。比如很多 GPU 的陣列放到一個很大的計算集群中,另外一個集群是存儲。也可能是使用的一些云存儲,像微軟的 Azure 或者是亞馬遜的 S3 等。這樣的基礎架構的特點是,首先,計算集群中有很多非常昂貴的 GPU,每臺 GPU 往往有一定的本地存儲,比如 SSD 這樣的幾十 TB 的存儲。這樣一個機器組成的陣列中,往往是用高速網絡去連接遠端,比如 Coco、 image net、YouTube 8M 之類的非常大規模的訓練數據是以網絡進行連接的。
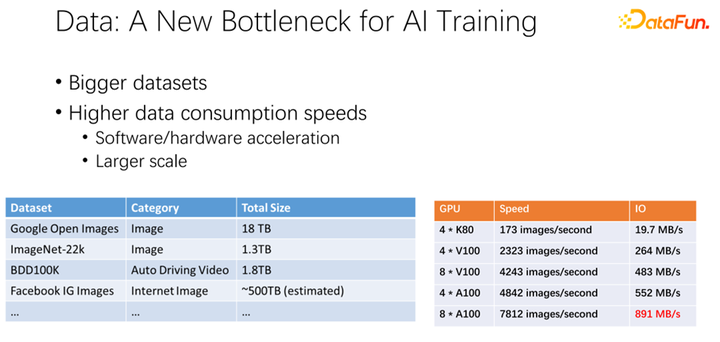
如上圖所示,數據有可能會成為下一個 AI 訓練的瓶頸。我們觀察到數據集越來越大,隨著 AI 應用更加廣泛,也在積累更多的訓練數據。同時 GPU 賽道是非常卷的。比如 AMD、TPU 等廠商,花費了大量精力去優化硬件和軟件,使得加速器,類似 GPU、TPU 這些硬件越來越快。隨著公司內加速器的應用非常廣泛之后,集群部署也越來越大。這里的兩個表呈現了關于數據集以及 GPU 速度的一些變化。之前的 K80 到 V100、 P100、 A100,速度是非常迅速的。但是,隨著速度越來越快,GPU 變得越來越昂貴。我們的數據,比如 IO 速度能否跟上 GPU 的速度,是一個很大的挑戰。
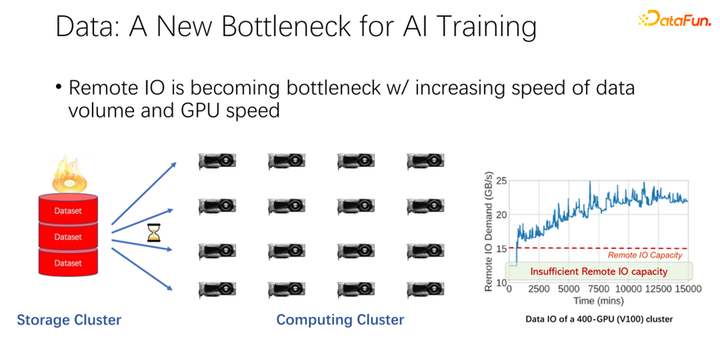
如上圖所示,在很多大公司的應用中,我們觀察到這樣一個現象:在讀取遠程數據的時候,GPU 是空閑的。因為 GPU 是在等待遠程數據讀取,這也就意味著 IO 成為了一個瓶頸,造成了昂貴的 GPU 被浪費。有很多工作在進行優化來緩解這一瓶頸,緩存就是其中很重要的一個優化方向。這里介紹兩種方式。

第一種,在很多應用場景中,尤其是以 K8s 加 Docker 這樣的基礎 AI 訓練架構中,用了很多本地磁盤。前文中提到 GPU 機器是有一定的本地存儲的,可以用本地磁盤去做一些緩存,把數據先緩存起來。啟動了一個 GPU 的 Docker 之后,不是馬上啟動 GPU 的 AI 訓練,而是先去下載數據,把數據從遠端下載到 Docker 內部,也可以是掛載等方式。下載到 Docker 內部之后再開始訓練。這樣盡可能的把后邊的訓練的數據讀取都變成本地的數據讀取。本地 IO 的性能目前來看是足夠支撐 GPU 的訓練的。VLDB 2020 上面,有一篇 paper,CoorDL,是基于 DALI 進行數據緩存。這一方式也帶來了很多問題。首先,本地的空間是有限的,意味著緩存的數據也是有限的,當數據集越來越大的時候,很難緩存到所有數據。另外,AI 場景與大數據場景有一個很大的區別是,AI 場景中的數據集是比較有限的。不像大數據場景中有很多的表,有各種各樣的業務,每個業務的數據表的內容差距是非常大的。在 AI 場景中,數據集的規模、數據集的數量遠遠小于大數據場景。所以常常會發現,公司中提交的任務很多都是讀取同一個數據。如果每個人下載數據到自己本地,其實是不能共享的,會有非常多份數據被重復存儲到本地機器上。這種方式顯然存在很多問題,也不夠高效。
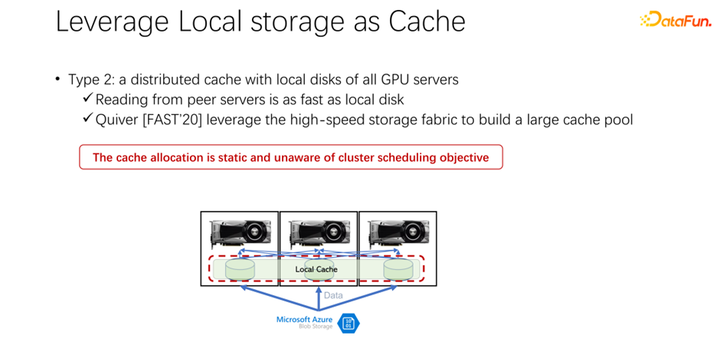
接下來介紹第二種方式。既然本地的存儲不太好,那么,是否可以使用像 Alluxio 這樣一個分布式緩存來緩解剛才的問題,分布式緩存有非常大的容量來裝載數據。另外,Alluxio 作為一個分布式緩存,很容易進行共享。數據下載到 Alluxio 中,其他的客戶端,也可以從緩存中讀取這份數據。這樣看來,使用 Alluxio 可以很容易地解決上面提到的問題,為 AI 訓練性能帶來很大的提升。微軟印度研究院在 FAST2020 發表的名為 Quiver 的一篇論文,就提到了這樣的解決思路。但是我們分析發現,這樣一個看似完美的分配方案,還是比較靜態的,并不高效。同時,采用什么樣的 cache 淘汰算法,也是一個很值得討論的問題。
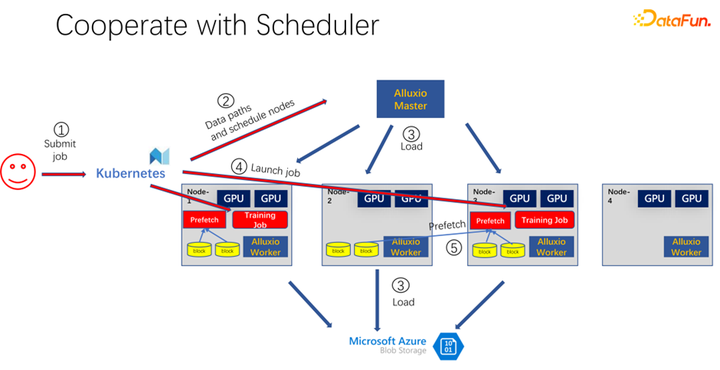
如上圖所示,是使用 Alluxio 作為 AI 訓練的緩存的一個應用。使用 K8s 做整個集群任務的調度和對 GPU、CPU、內存等資源的管理。當有用戶提交一個任務到 K8s 時,K8s 首先會做一個插件,通知 Alluxio 的 master,讓它去下載這部分數據。也就是先進行一些熱身,把作業可能需要的任務,盡量先緩存一些。當然不一定非得緩存完,因為 Alluxio 是有多少數據,就使用多少數據。剩下的,如果還沒有來得及緩存,就從遠端讀取。另外,Alluxio master 得到這樣的命令之后,就可以讓調度它的 worker 去遠端。可能是云存儲,也可能是 Hadoop 集群把數據下載下來。這個時候,K8s 也會把作業調度到 GPU 集群中。比如上圖中,在這樣一個集群中,它選擇第一個節點和第三個節點啟動訓練任務。啟動訓練任務之后,需要進行數據的讀取。在現在主流的像 PyTorch、Tensorflow 等框架中,也內置了 Prefetch,也就是會進行數據預讀取。它會讀取已經提前緩存的 Alluxio 中的緩存數據,為訓練數據 IO 提供支持。當然,如果發現有一些數據是沒有讀到的,Alluxio 也可以通過遠端進行讀取。Alluxio 作為一個統一的接口是非常好的。同時它也可以進行數據的跨作業間的共享。
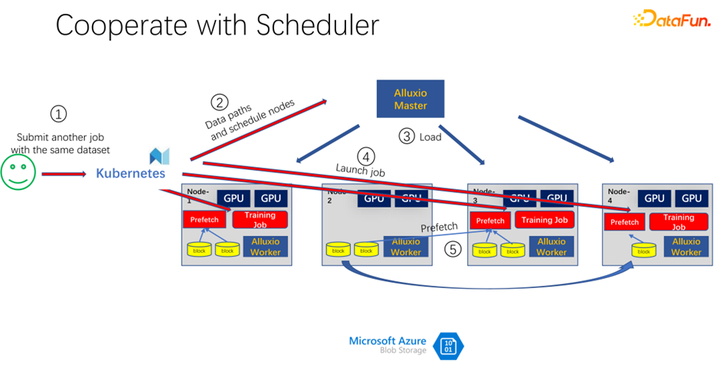
如上圖所示,比如又有一個人提交了同樣數據的另一個作業,消耗的是同一個數據集,這個時候,當提交作業到 K8s 的時候,Alluxio 就知道已經有這部分數據了。如果 Alluxio 想做的更好,甚至是可以知道,數據即將會被調度到哪臺機器上。比如這個時候調度到 node 1、node 3 和 node 4 上。node 4 的數據,甚至可以做一些副本進行拷貝。這樣所有的數據,即使是 Alluxio 內部,都不用跨機器讀,都是本地的讀取。所以看起來 Alluxio 對 AI 訓練中的 IO 問題有了很大的緩解和優化。但是如果仔細觀察,就會發現兩個問題。

第一個問題就是緩存的淘汰算法非常低效,因為在 AI 場景中,訪問數據的模式跟以往有很大區別。第二個問題是,緩存作為一種資源,與帶寬(即遠程存儲的讀取速度)是一個對立的關系。如果緩存大,那么從遠端讀取數據的機會就小。如果緩存很小,則很多數據都得從遠端讀取。如何很好地調度分配這些資源也是一個需要考慮的問題。
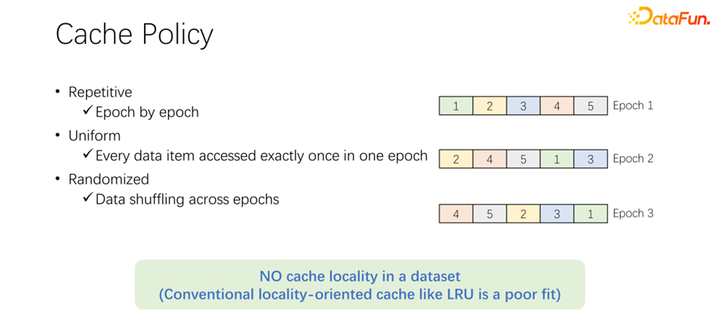
在討論緩存的淘汰算法之前,先來看一下 AI 訓練中數據訪問的過程。在 AI 訓練中,會分為很多個 epoch,不斷迭代地去訓練。每一個訓練 epoch,都會讀取每一條數據,并且僅讀一次。為了防止訓練的過擬合,在每一次 epoch 結束之后,下一個 epoch 的時候,讀取順序會變化,會進行一個 shuffle。也就是每次每個 epoch 都會把所有數據都讀取一次,但是順序卻不一樣。Alluxio 中默認的 LRU 淘汰算法,顯然不能很好地應用到 AI 訓練場景中。因為 LRU 是利用緩存的本地性。本地性分為兩方面,首先是時間本地性,也就是現在訪問的數據,馬上可能還會即將訪問。這一點,在 AI 訓練中并不存在。因為現在訪問的數據,在下一輪的時候才會訪問,而且下一輪的時候都會訪問。沒有一個特殊的概率,一定是比其他數據更容易被訪問。另一方面是數據本地性,還有空間本地性。也就是,為什么 Alluxio 用比較大的 block 緩存數據,是因為某條數據讀取了,可能周圍的數據也會被讀取。比如大數據場景中,OLAP 的應用,經常會進行表的掃描,意味著周圍的數據馬上也會被訪問。但是在 AI 訓練場景中是不能應用的。因為每次都會 shuffle,每次讀取的順序都是不一樣的。因此 LRU 這種淘汰算法并不適用于 AI 訓練場景。

不僅是 LRU,像 LFU 等主流的淘汰算法,都存在這樣一個問題。因為整個 AI 訓練對數據的訪問是非常均等的。所以,可以采用最簡單的緩存算法,只要緩存一部分數據就可以,永遠不用動。在一個作業來了以后,永遠都只緩存一部分數據。永遠都不要淘汰它。不需要任何的淘汰算法。這可能是目前最好的淘汰機制。如上圖中的例子。上面是 LRU 算法,下面是均等方法。在開始只能緩存兩條數據。我們把問題簡單一些,它的容量只有兩條,緩存 D 和 B 這兩條數據,中間就是訪問的序列。比如命中第一個訪問的是 B,如果是 LRU,B 存在的緩存中命中了。下一條訪問的是 C,C 并不在 D 和 B,LRU 的緩存中,所以基于 LRU 策略,會把 D 替換掉,C 保留下來。也就是這個時候緩存是 C 和 B。下一個訪問的是 A,A 也不在 C 和 B 中。所以會把 B 淘汰掉,換成 C 和 A。下一個就是 D,D 也不在緩存中,所以換成 D 和 A。以此類推,會發現所有后面的訪問,都不會再命中緩存。原因是在進行 LRU 緩存的時候,把它替換出來,但其實在一個 epoch 中已經被訪問一次,這個 epoch 中就永遠不會再被訪問到了。LRU 反倒把它進行緩存了,LRU 不但沒有幫助,反倒是變得更糟糕了。不如使用 uniform,比如下面這種方式。下面這種 uniform 的方式,永遠在緩存中緩存 D 和 B,永遠不做任何的替換。在這樣情況下,你會發現至少有 50% 的命中率。所以可以看到,緩存的算法不用搞得很復雜,只要使用 uniform 就可以了,不要使用 LRU、LFU 這類算法。
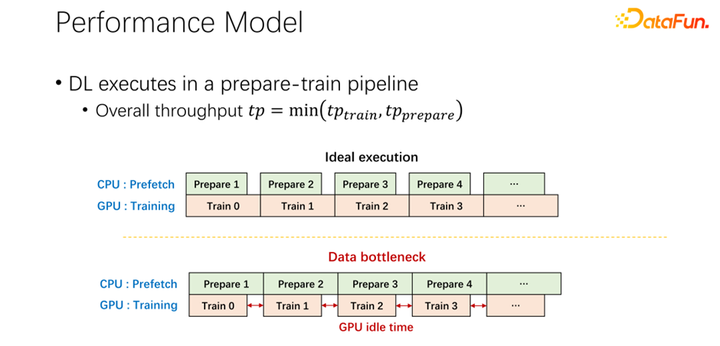
對于第二個問題,也就是關于緩存和遠程帶寬之間關系的問題。現在所有主流的 AI 框架中都內置了數據預讀,防止 GPU 等待數據。所以當 GPU 做訓練的時候,其實是觸發了 CPU 預取下一輪可能用到的數據。這樣可以充分利用 GPU 的算力。但當遠程存儲的 IO 成為瓶頸的時候,就意味著 GPU 要等待 CPU 了。所以 GPU 會有很多的空閑時間,造成了資源的浪費。希望可以有一個比較好的調度管理方式,緩解 IO 的問題。

緩存和遠程 IO 對整個作業的吞吐是有很大影響的。所以除了 GPU、CPU 和內存,緩存和網絡也是需要調度的。在以往大數據的發展過程中,像 Hadoop、yarn、my source、K8s 等,主要都是調度 CPU、內存、GPU。對于網絡,尤其對于緩存的控制都不是很好。所以,我們認為,在 AI 場景中,需要很好的調度和分配它們,來達到整個集群的最優。
二、SiloD 框架

在 EuroSys 2023 發表了這樣一篇文章,它是一個統一的框架,來調度計算資源和存儲資源。
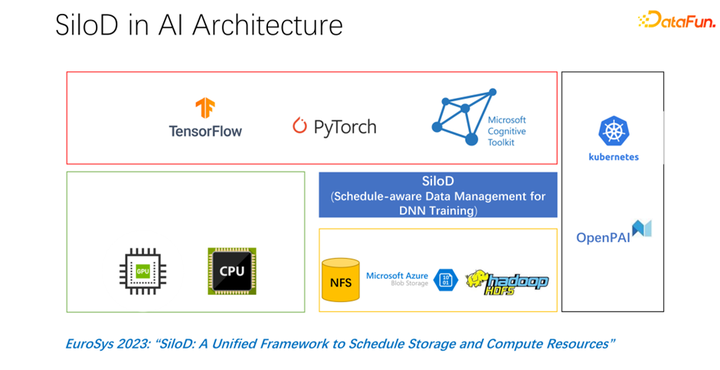
整體架構如上圖所示。左下角是集群中的 CPU 和 GPU 硬件計算資源,以及存儲資源,如 NFS、云存儲 HDFS 等。在上層有一些 AI 的訓練框架 TensorFlow、PyTorch 等。我們認為需要加入一個統一管理和分配計算和存儲資源的插件,也就是我們提出的 SiloD。
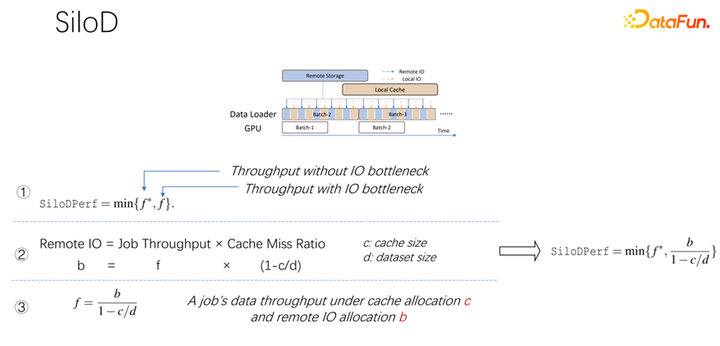
如上圖所示,一個作業可以達到什么樣的吞吐和性能,是由 GPU 和 IO 的最小值決定的。使用多少個遠程 IO,就會使用多少遠端的 networking。可以通過這樣一個公式算出訪問速度。作業速度乘以緩存未命中率,也就是(1-c/d)。其中 c 就是緩存的大小,d 就是數據集。這也就意味著數據只考慮 IO 可能成為瓶頸的時候,大概的吞吐量是等于(b/(1-c/d)),b 就是遠端的帶寬。結合以上三個公式,可以推出右邊的公式,也就是一個作業最終想達到什么樣的性能,可以這樣通過公式去計算沒有 IO 瓶頸時的性能,和有 IO 瓶頸時的性能,取二者中的最小值。
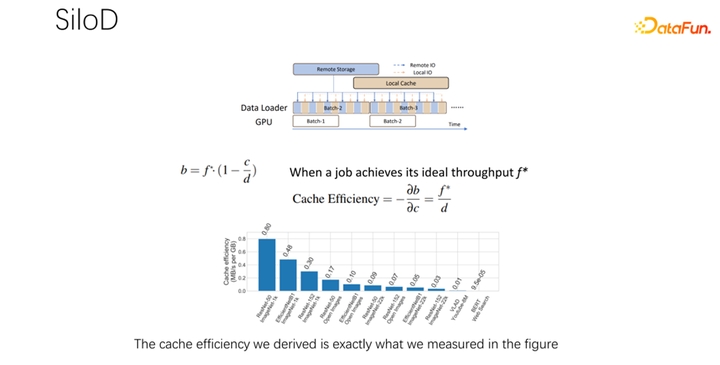
得到上面的公式之后,把它微分一下,就可以得到緩存的有效性,或者叫做緩存效率。即雖然作業很多,但在分配緩存的時候不能一視同仁。每一個作業,基于數據集的不同,速度的不同,緩存分配多少是很有講究的。這里舉一個例子,就以這個公式為例,如果發現一個作業,速度非常快,訓練起來非常快,同時數據集很小,這時候就意味著分配更大的緩存,收益會更大。
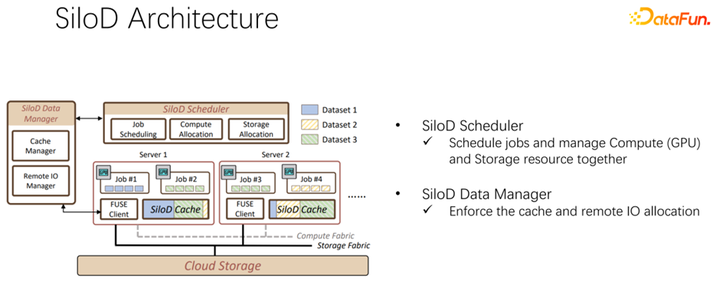
基于以上觀察,可以使用 SiloD,進行緩存和網絡的分配。而且緩存的大小,是針對每個作業的速度,以及數據集整個的大小來進行分配的。網絡也是如此。所以整個架構是這樣的:除了主流的像 K8s 等作業調度之外,還有數據管理。在圖左邊,比如緩存的管理,要統計或者監控分配整個集群中緩存的大小,每個作業緩存的大小,以及每個作業使用到的遠程 IO 的大小。底下的作業,和 Alluxio 方式很像,都可以都使用 API 進行數據的訓練。每個 worker 上使用緩存對于本地的 job 進行緩存支持。當然它也可以在一個集群中跨節點,也可以進行共享。
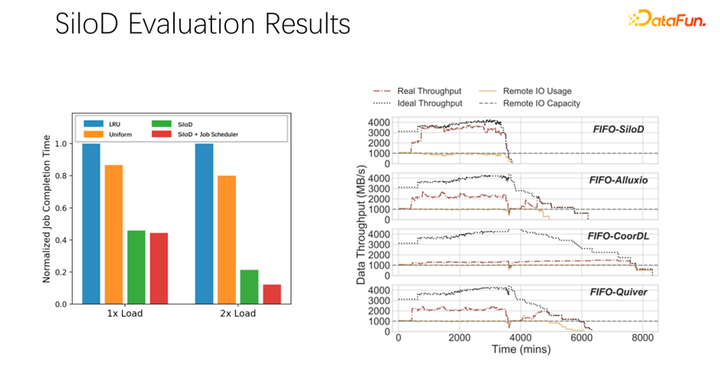
經過初步測試和實驗,發現這樣一個分配方式可以使整個集群的使用率和吞吐量都得到非常明顯的提升,最高可以達到 8 倍的性能上的提升。可以很明顯的緩解作業等待、GPU 空閑的狀態。

對上述介紹進行一下總結: 第一,在 AI 或者深度學習訓練場景中,傳統的 LRU、LFU 等緩存策略并不適合,不如直接使用 uniform。 第二,緩存和遠程帶寬,是一對伙伴,對整體性能起到了非常大的作用。 第三,像 K8s、yarn 等主流調度框架,可以很容易繼承到 SiloD。 最后,我們在 paper 中做了一些實驗,不同的調度策略,都可以帶來很明顯的吞吐量的提升。
三、分布式緩存策略以及副本管理
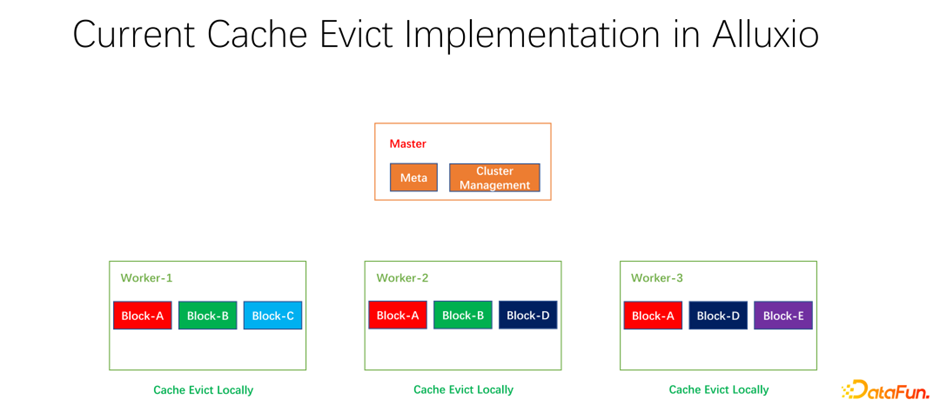
我們還做了一些開源的工作。分布式緩存策略以及副本管理這項工作,已經提交給社區,現在處于 PR 階段。Alluxio master 主要做 Meta 的管理和整個 worker 集群的管理。真正緩存數據的是 worker。上面有很多以 block 為單位的塊兒去緩存數據。存在的一個問題是,現階段的緩存策略都是單個 worker 的,worker 內部的每個數據在進行是否淘汰的計算時,只需要在一個 worker 上進行計算,是本地化的。
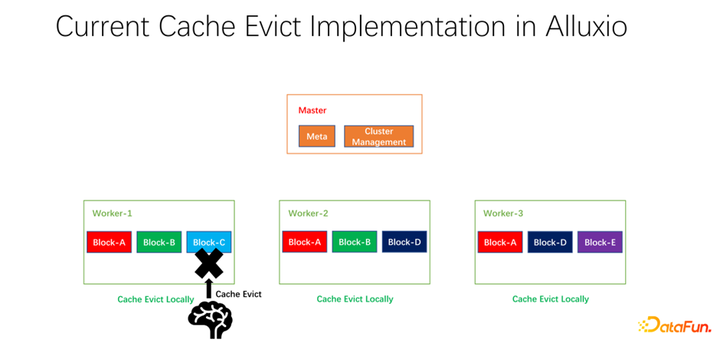
如上圖所示的例子,如果 worker 1 上有 block A, block B 和 block C,基于 LRU 算出來 block C 是最長時間沒有使用的,就會把 block C 淘汰。如果看一下全局的情況,就會發現這樣并不好。因為 block C 在整個集群中只有一個副本。把它淘汰之后,如果下面還有人要訪問 block C,只能從遠端拉取數據,就會帶來性能和成本的損失。我們提出做一個全局的淘汰策略。在這種情況下,不應該淘汰 block C,而應該淘汰副本比較多的。在這個例子中,應該淘汰 block A,因為它在其它的節點上仍然有兩個副本,無論是成本還是性能都要更好。
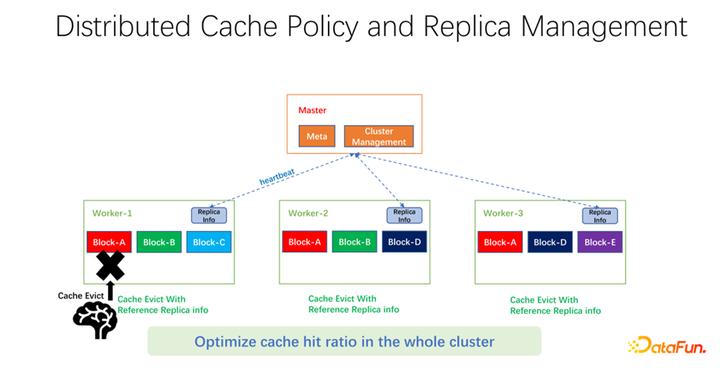
如上圖所示,我們做的工作是在每個 worker 上維護副本信息。當某一個 worker,比如加了一個副本,或者減了一個副本,首先會向 master 匯報,而 master 會把這個信息作為心跳返回值,返回給其它相關的 worker。其它 worker 就可以知道整個全局副本的實時變化。同時,更新副本信息。所以當進行 worker 內部的淘汰時,可以知道每一個 worker 在整個全局有多少個副本,就可以設計一些權重。比如仍然使用 LRU,但是會加上副本個數的權重,綜合考量淘汰和替換哪些數據。經過我們初步的測試,在很多領域,無論是 big data,AI training 中都可以帶來很大的提升。所以不僅僅是優化一臺機器上一個 worker 的緩存命中。我們的目標是使得整個集群的緩存命中率都得到提升。

最后,對全文進行一下總結。首先,在 AI 的訓練場景中,uniform 緩存淘汰算法要比傳統的 LRU、LFU 更好。第二,緩存和遠端的 networking 也是一個需要被分配和調度的資源。第三,在進行緩存優化時,不要只局限在一個作業或者一個 worker 上,應該統攬整個端到端全局的參數,才能使得整個集群的效率和性能有更好的提升。
審核編輯:劉清
-
存儲器
+關注
關注
38文章
7484瀏覽量
163764 -
緩存器
+關注
關注
0文章
63瀏覽量
11658 -
機器學習
+關注
關注
66文章
8406瀏覽量
132565 -
MYSQL數據庫
+關注
關注
0文章
96瀏覽量
9389 -
HDFS
+關注
關注
1文章
30瀏覽量
9588 -
AI大模型
+關注
關注
0文章
315瀏覽量
305
原文標題:Alluxio助力AI大模型訓練
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
GPU是如何訓練AI大模型的
訓練AI大模型需要什么樣的gpu
如何訓練自己的AI大模型
如何訓練ai大模型
ai模型訓練需要什么配置
AI訓練的基本步驟
ai大模型和ai框架的關系是什么
AI大模型訓練成本飆升,未來三年或達千億美元
【大語言模型:原理與工程實踐】大語言模型的預訓練
AI訓練,為什么需要GPU?






 工商網監
工商網監
評論