 什么是SLAM?視覺SLAM怎么實現?
什么是SLAM?視覺SLAM怎么實現?
上周的組會上,我給研一的萌新們講解什么是SLAM,為了能讓他們在沒有任何基礎的情況下大致聽懂,PPT只能多圖少字沒公式,這里我就把上周的組會匯報總結一下。
這次匯報的題目我定為“視覺SLAM:一直在入門,從未能精通”,那是因為視覺SLAM真的是博大精深,就像C++一樣,連說入門都底氣不足,只能說了解,更不敢說精通。
從五月份開始學《視覺SLAM十四講》算起,我已經正式接觸SLAM四個多月了,到現在還是很懵懂的,當然也有可能是自己的吸收能力還不夠強吧!
下面就以我這段時間的積累斗膽簡單談談對視覺SLAM的認識,如有不當,還請指教。
1 什么是SLAM?
SLAM的英文全名叫做Simultaneous Localization and Mapping,中文名是同時定位與建圖,從字面上來看就是同時解決定位和地圖構建問題。
定位主要是解決“在什么地方”的問題,比如你目前在哪國哪省哪市哪區哪路哪棟幾號幾樓哪個房間哪個角落。
建圖主要是解決“周圍環境是什么樣”的問題,你可以回憶一下百度高德地圖,甚至一些景點的手繪地圖。
下面就以掃地機器人作為例子再稍微詳細地講解一下。
對于掃地機器人來說,定位就是要知道自己在房間里的具體位置,建圖就是知道整個房間的地面結構信息,而有了這些信息才能做路徑規劃,以最短的距離到達目的地。
下面右圖就是掃地機器人在家里移動時的定位和建圖,藍點是它自己目前所在的位置,它已經把房間能抵達的地方都構建出來了。
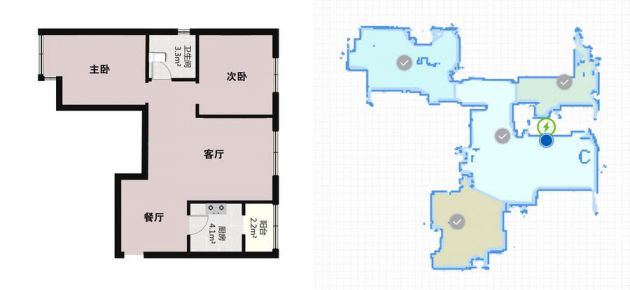
總的來說,機器人從未知環境未知地點出發,通過傳感器(這里主要說的是相機)觀測環境獲取信息,利用相機的信息估算機器人的位置、姿態和運動軌跡,并且根據位姿構建地圖,從而實現同時定位和建圖。
利用不同的傳感器實現SLAM的方法不同,目前主流的傳感器有激光雷達(LiDAR SLAM)、相機(Visual SLAM)和慣性測量單元(Visual-inertial SLAM)。
接下來我們介紹的是視覺SLAM的方法,也就是只采用相機作為傳感器的SLAM。
當然,用相機作為傳感器的話,還是有不同的方法,因為相機也有不同的種類,常見的有單目相機、雙目相機和RGB-D相機。
2 為什么用SLAM?
可能你會有疑問了,為什么不用GPS定位?為什么不用現成的地圖?下面就來一一解答。
對于定位來說,我要反問一下,沒有GPS怎么破?比如在一些建筑物內、隧道或者偏遠地方,我們是無法獲取GPS的。這種情況下機器人或者無人車是不是得自己定位了。
再者,GPS的定位精度不夠高,最多也就達到幾米的精度,要是在室內定位的話,一套房就這么巴掌大的地方,幾米的誤差也許就讓你的掃地機器人誤以為是在你鄰居家打掃了。。
對于建圖來說,我還是要反問一下,沒有現成地圖怎么破?比如你的家、公司或者工廠,我們很難直接拿到現成的地圖,家家戶戶的圖紙數據量得多大,而且每一戶裝修也不一樣,家私的擺放位置更是無從得知。
而且,不同場景需求下的地圖也是不一樣的,后面我們會提到有各式各樣的地圖,不存在解決各種問題的地圖。
所以,在沒有GPS和現成地圖的場景下,同時考慮到定位的精度和地圖的需求,SLAM對于機器人來說簡直是雪中送炭。
3 視覺SLAM怎么實現?
下面就用高博《視覺SLAM十四講》里的框圖來講解視覺SLAM大致是怎么實現的。
首先通過傳感器(這里利用的是相機)獲取環境中的數據信息,也就是一幀一幀的圖像,在前端視覺里程計中通過這些圖像信息計算出相機的位置(準確來說是位姿,后面會細說)。
同時進行閉環檢測,判斷機器人是否到達先前經過的地方。然后利用后端非線性優化,對前端得出的相機位姿進行優化,得到全局最優的狀態。
最后根據每一時刻的相機位姿和空間中目標的信息,根據需求建立相應的地圖。
接下來就來詳細說說其中每一個模塊都是怎么操作的。
4 前端視覺里程計
視覺里程計的英文名稱是Visual Odometry,簡稱VO,主要是研究怎么通過相鄰兩幀圖像計算兩幀之間相機的運動。
這里面涉及了不少知識,其中包括圖像處理中的特征提取和特征匹配、三維視覺中的剛體運動和對極幾何、數學中的李群李代數等等。。
不要慌!天空飄來五個字,那都不是事!
在視覺SLAM中,主流的方法根據前端的不同分為特征點法和直接法,下面介紹的是利用特征點法的視覺SLAM。
對于我們人眼直觀判斷來說,從前一張圖像到后一張圖像應該是往右上的方向稍微旋轉了一下。
但是,對于機器人來說它可沒那么“直觀”。
首先它要對這兩張圖像進行特征提取,也就是找到圖像中特別的地方,比如角點、邊緣點等。然后,對這些特征點在兩張圖像之間進行特征匹配。
把匹配對中誤匹配的篩選掉之后,就能得到較為準確的匹配了。
有了這些匹配點對之后,就能利用它們瘋狂計算相機的位姿了。對了,這里得講講位姿究竟是什么東西?
位姿其實就是位置和姿態的合稱,位置也就是在三維空間中的坐標(x,y,z),而姿態是在三維空間中的旋轉(r,p,y),因此位姿總共包含6個自由度。
還沒理解?來做做頭部健康運動就明白了,左右歪頭,上下點頭,左右搖頭。怎么樣,既能預防頸椎病,還能理解三維旋轉。
左右歪頭是滾轉角roll,上下點頭是俯仰角pitch,左右搖頭則是偏航角yaw。
既然要表示坐標,那我們總得知道坐標系是什么吧?在相機運動過程中,有四個常見的坐標系需要我們了解。
分別是世界坐標系、相機坐標系、歸一化坐標系還有像素坐標系。下面這張圖讓人一目了然。
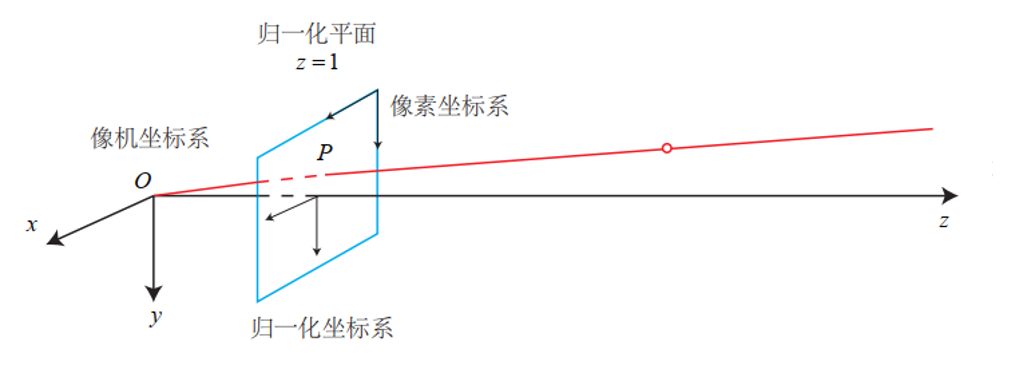
世界坐標系比較好理解,就是我們身處的整個三維空間的坐標系,坐標原點由我們自己定,可以是某一張桌子的邊角,也可以是相機第一時刻的位置。
相機坐標系是以相機光心為坐標原點,光軸為z軸的坐標系。
歸一化坐標系就是原點在相機坐標系下(0,0,1)處的二維平面坐標系。
像素坐標系是以圖像左上角的像素為原點,以一個像素為最小單元的離散坐標系。
既然有不同的坐標,當知道點在一個坐標系下的坐標時,如何求得該點在其他坐標系下的坐標呢?
舉個栗子,我們能獲取到的是圖像的像素信息,通過轉換(相機投影模型)之后能得到該像素(特征點)在相機坐標系中的坐標位置。
但是在構建地圖的時候我們得知道這個像素(特征點)在整個三維空間中的哪個位置呀,也就是相機坐標系中的坐標怎么轉化到世界坐標系下。
這就涉及到了三維空間剛體運動中坐標系的變換。直接上圖就曉得了。
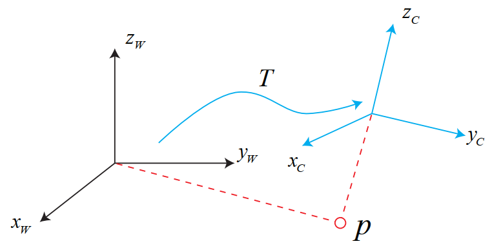
上圖展示的是世界坐標系轉化為相機坐標系的過程,當然方法都是一樣的。
這里獻上整篇文章唯一的一條數學公式:
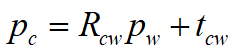
pc是點p在相機坐標系下的坐標,pw是世界坐標,Rcw是描述從世界坐標系轉化為相機坐標系旋轉的旋轉矩陣,tcw是描述從世界坐標系轉化相機坐標系平移的平移向量。
可以看出,坐標系的轉換我們可以用一個旋轉矩陣R(3*3)來表示旋轉,也就是決定姿態,還有一個平移向量t(3*1)來表示平移,也就是決定位置。
相機的位姿其實就是指相機在世界坐標系下的位置坐標和旋轉姿態,位姿估計就是根據兩幀之間匹配點的關系計算當前時刻相機的位姿。
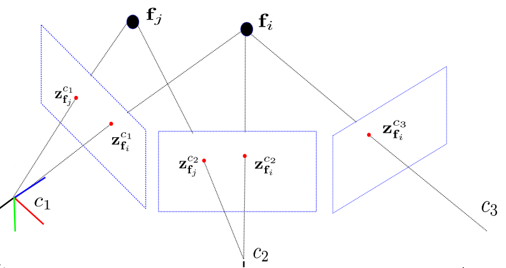
假如我們將第一幀時刻的相機作為世界坐標系原點,那么通過第1、2幀圖像的匹配點就可以計算從第2幀相機坐標系到第1幀相機坐標系(世界坐標系)的旋轉矩陣R12和平移向量t12。
然后再通過第2、3幀圖像的匹配點計算R23和t23,利用和R12相乘再加上t12就能求得第3幀時刻相機在世界坐標系下的位姿。依此類推。。。
當然,根據不同情況可以用不同的方法求R和t:
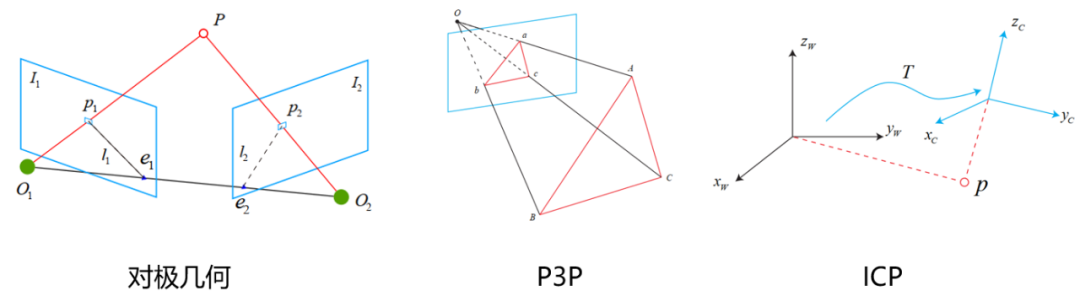
2D-2D:對極約束,在單目相機中,我們只能獲取二維圖像,利用兩幀圖像的匹配點關系通過對極幾何的關系可以求出一個叫本質矩陣E的東西,再求得R和t。
3D-3D:ICP(迭代最近法),在雙目和RGB-D相機中,我們可以直接獲取圖像的深度信息,也就是說特征點在相機坐標系下的z我們是知道的,這時候其實就相當于直接求兩個相機坐標系的轉換R和t。
3D-2D:PnP,當我們知道一組點在世界坐標系下的坐標和它們在相機中的投影位置時,可以利用這種方法直接求得當前時刻的相機位姿。
5 后端優化
視覺里程計講得很多了,但是從視覺里程計中計算得到的相機位姿會有一定的誤差,一次兩次還好,一旦多了累積誤差可是很嚴重的。
這時就需要后端對前端的結果進行優化,從而得到最優的位姿。
和前端分為兩種主流方法一樣,后端也有兩種解決方法:
濾波器方法,以擴展卡爾曼濾波(EKF)為代表,認為某一時刻的狀態只和上一時刻的狀態有關。
非線性優化方法,以高斯牛頓法和列文伯格-馬夸爾特法為代表,認為某一時刻的狀態和之前所有狀態有關。
我們主要用的是非線性優化方法,對相機位姿和路標點構建最小二乘問題,并利用圖優化的方法求解,也就是常說的Bundle Adjustment。
當然,因為BA處理的數據量很大,在整個SLAM過程中還會采取別的方法控制優化的數據,比如滑動窗口法。
簡單地說,就是在保持處理的幀數不變的情況下,將舊的數據刪除,加入新的數據。
假設每次只優化10幀,那么當接收到第11幀圖像時,移除第1幀圖像的數據,并將第11幀圖像加入優化問題中。
6回環檢測
回環檢測(Loop Closure)是一個挺特殊的模塊,主要讓機器人能識別出曾經去過的地方。
隨著時間推進,SLAM的誤差會不斷地累積,時間久了后,使得軌跡出現嚴重的漂移。
如果有了回環檢測,機器人就會檢測到自己曾經到過這個地方,利用這個信息和歷史數據比對,從而修正累積誤差,得到全局一致的狀態估計。
為什么說回環檢測挺特殊的呢?因為這個模塊乍一看還挺像機器學習甚至是目前深度神經網絡應用的領域。
判斷“兩張圖像是否為同一個地方”會出現4種結果:
事實是,機器人判斷為是;
事實是,機器人判斷為否;
事實否,機器人判斷為是;
事實否,機器人判斷為否。
最好的結果當然是第1種和第4種,因為機器人的判斷和事實符合,可現實總是不完美的。
而衡量回環檢測效果的指標也有兩種——準確率(Precision)和召回率(Recall)。
用西瓜書里的話解釋,準確率關心的是“挑出的西瓜中有多少比例是好瓜”,召回率關心的是“所有好瓜中有多少比例被挑了出來”。
西瓜書都搬出來了,這還不是機器學習問題嗎?
當然,在SLAM中還是更注重召回率的,希望更多“現實是回環”被機器人“判斷為回環”。
傳統主流的視覺SLAM中回環檢測采用的是詞袋模型,當然按照目前深度學習的勢頭來說,也不妨試試神經網絡,但是實時性就得另當別論了。
而且,回環檢測還可以用來進行重定位,解決跟蹤失敗的問題,保證在跟蹤失敗的情況下可以快速重新得到當前的精確位姿。
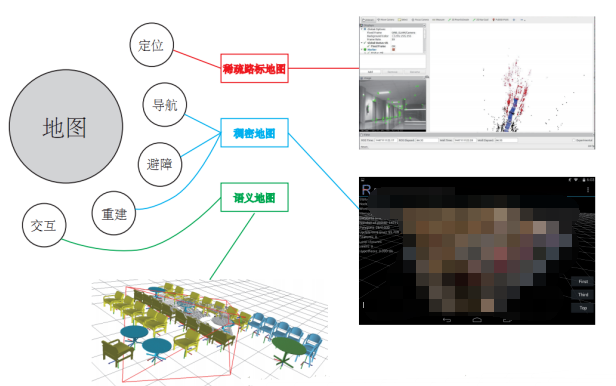
7地圖構建
最后一個模塊是地圖構建,前面也說過了,我們根據不同的傳感器類型和應用需求可以建立不同的地圖。
還是用高博《視覺SLAM十四講》中的圖,簡潔明了地說明了不同應用場景對應不同類型的地圖。
如果只是單純的定位,只需要知道機器人在什么位置即可,這時候稀疏路標地圖就足夠了。
在導航、避障的情況下,機器人必須知道什么地方可以走而什么地方不能走,這才能規劃出運動路徑。于是就需要稠密地圖,稀疏路標點的地圖壓根就不能判斷那是什么東西。
重建也很明了,既然是重建,那就得是帶有輪廓紋理等詳細信息的稠密地圖了。
如果是人機交互的話呢,機器人得知道什么是桌子、杯子在哪里等語義信息,這時候光是知道物體什么模樣可不行了,得上語義地圖才是。
我們在做導航時,有一種常用的地圖,那就是八叉樹地圖(Octomap)。
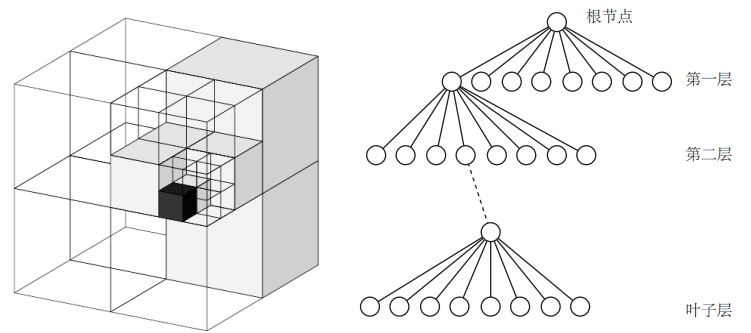
它是把三維空間分為許多方塊,方塊再分為八個同樣大小的小方塊,小方塊再繼續往下分。。整個三維空間就用八叉樹數據結構來表示。
當方塊中所有子方塊都被占據或者都沒被占據的時候,這個方塊或者說八叉樹中的這個節點就沒必要往下展開了。
相對與點云地圖來說,這樣會大大減少了地圖的存儲空間!下面就是一張八叉樹地圖。
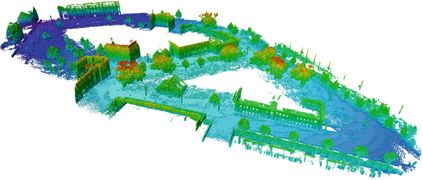
8 結語
近兩年,SLAM有要火的趨勢,但是這也不妨礙它毫不平易近人的特質。
審核編輯:彭菁
-
傳感器
+關注
關注
2552文章
51217瀏覽量
754606 -
機器人
+關注
關注
211文章
28501瀏覽量
207473 -
gps
+關注
關注
22文章
2898瀏覽量
166333 -
SLAM
+關注
關注
23文章
425瀏覽量
31861 -
激光雷達
+關注
關注
968文章
3988瀏覽量
190072
原文標題:CV領域的絕境長城,視覺SLAM:一直在入門,從未能精通
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
激光SLAM與視覺SLAM有什么區別?
基于視覺的slam自動駕駛
單目視覺SLAM仿真系統的設計與實現
視覺SLAM的技術資料總結
科普|視覺SLAM是什么——三種視覺SLAM方案
視覺SLAM與激光SLAM有什么區別?
機器人主流定位技術:激光SLAM與視覺SLAM誰更勝一籌
基于深度學習的視覺SLAM綜述
OV2SLAM(高速視覺slam)簡析
視覺SLAM開源方案匯總 視覺SLAM設備選型
視覺SLAM是什么?視覺SLAM的工作原理 視覺SLAM框架解讀





 工商網監
工商網監
評論