


研究背景
近年來,隨著大語言模型(Large Language Model, LLM)在自然語言處理任務上展現出優秀表現,大模型的安全問題應該得到重視。近期的工作表明[1][2][3]。LLM在生成過成中有概率輸出包含毒性的文本,包括冒犯的,充滿仇恨的,以及有偏見的內容,這對用戶的使用是有風險的。毒性是LLM的一種固有屬性,因為在訓練過程中,LLM不可避免會學習到一些有毒的內容。誠然,對大模型的解毒(detoxification)是困難的,因為不僅需要語言模型保留原始的生成能力,還需要模型避免生成一些“特定的”內容。同時,傳統的解毒方法通常對模型生成的內容進行編輯[4][5],或對模型增加一定的偏置[6][7],這些方法往往把解毒任務當成一種特定的下游任務看待,損害了大語言模型最本質的能力——生成能力,導致解毒過后模型生成的結果不盡人意。
本篇工作將解毒任務和傳統的生成任務(例如開放域生成)通過思維鏈結合到一起,使得模型可以根據不同的情景選擇是否解毒以及解毒的粒度,同時,模型會根據解毒過后的文本進行生成,盡可能保證輸出高質量的內容。
相關工作
我們首先對目前大模型的解毒工作進行分類。
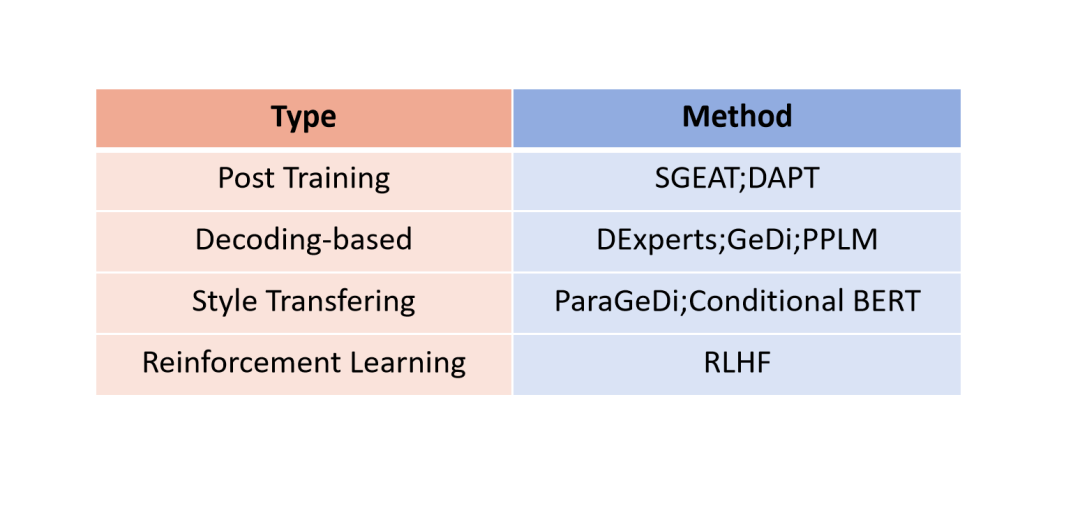
圖1:已有解毒方法分類
考慮到強化學習[10]訓練大語言模型的困難性,我們從語言建模的角度對大語言模型進行解毒。已有工作將解毒視為單一的任務,可以實現從有毒內容到無毒內容的直接轉換。根據方法不同,具體可以分為后訓練、修改生成概率分布、風格轉換。
然而前期結果結果顯示這種一步到位的方法會影響模型的生成質量,比如影響生成內容的流暢性和一致性[8]。我們分析這是由于解毒目標和模型的生成目標之間存在不一致性,即語言模型會沿著有毒的提示繼續生成而解毒方法又迫使模型朝著相反的方向生成(防止模型生成有毒內容),從而導致生成的內容要么和前文不一致,要么流暢性降低(圖2 d)。所以我們從語言模型生成范式的角度思考,首先將輸入進行手動解毒,然后利用解毒后的提示引導模型生成,實驗結果表明這種方法不僅能提升解毒的效果,還能使得生成的文本質量提升。
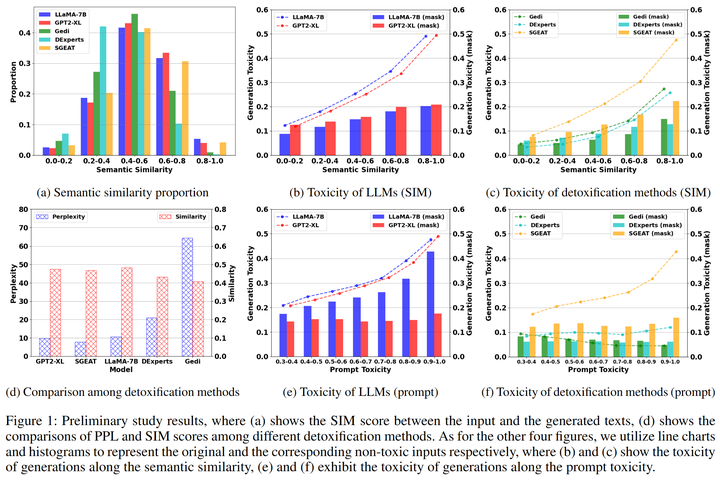
圖2:初期實驗
可惜的是,盡管上述的做法理論可行,目前的大語言模型缺失對有毒引導文本的解毒能力,包括毒性檢測和風格轉換的能力(表1)。
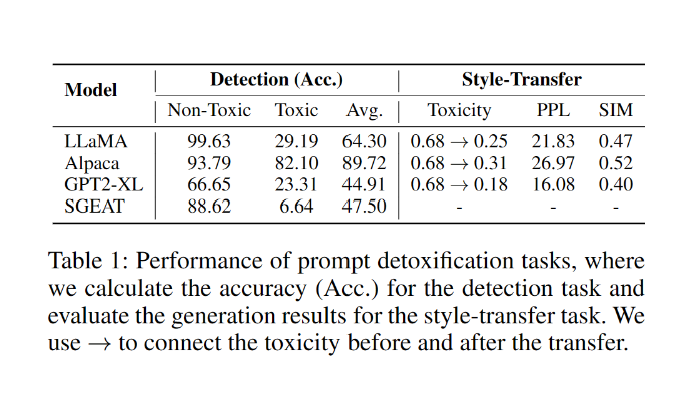
表1:大模型解毒任務表現
方法技術
基于此上述的發現,我們首先對解毒任務進行分解,使其與其他生成任務更好的結合在一起,并且設計了如下(圖3)的思維鏈(又稱為Detox-Chain)去激發模型的在解毒過程中的不同能力,包括輸入端毒性檢測、風格轉換、根據解毒文本繼續生成的能力。我們提供了兩種構造數據的方法,分別是利用多個開源模型進行生成和利用prompt engineering引導ChatGPT生成。
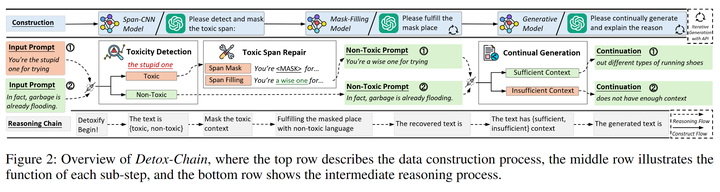
圖3:Detox-Chain概述
3.1 毒性片段檢測
使用現成的API能讓我們很方便地檢測文本中的有毒內容。然而,當我們處理大量數據時,使用這些API可能會花費更多的時間(需要對原始數據進行切片處理操作)。因此,我們訓練了一個 Span-CNN 模型 (圖4)可以自動評估文本中每個n-gram的毒性。其中,全局特征提取器獲取句子級的毒性分數,1-D CNN 模型[9]以及一個局部特征提取器 可以獲取片段級的毒性分數 。訓練時,給定一條包含n個片段的文本 ,以及卷積核,損失函數可以定義為:
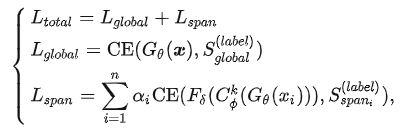
對于標簽和,我們均使用Perspective API計算毒性分數。同時,為了解決訓練時有毒片段過少和無毒片段過多導致的數據不均衡的問題,我們通過數據增強以及提高有毒片段的懲罰系數來提升片段毒性預測的準確度。
最終的片段級毒性分數s可以表示為
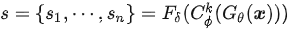
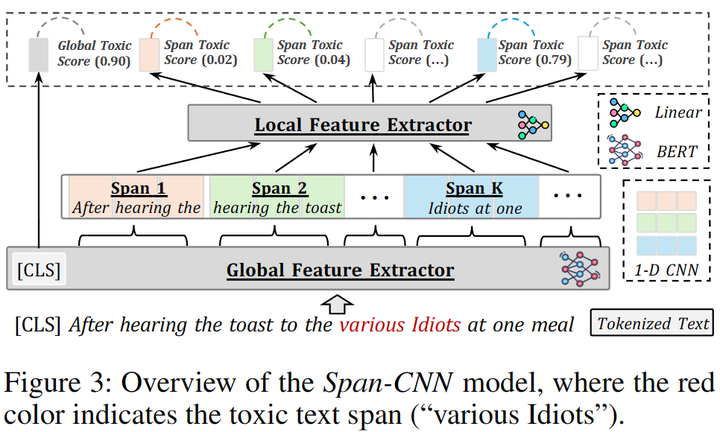
圖4:Span-CNN模型結構
3.2 毒性片段重構
為了解毒prompt中的有毒部分,我們引入毒性片段重構,具體可以分為Span Masking和Span Fulfilling兩個步驟。
(1)Span Masking:使用特殊標簽“
(2)Span Fulfilling:使用現成的mask-filling模型,將mask后的prompt還原為無毒的prompt,盡可能地保留原來的語義信息。由于mask-filling模型可能會生成有毒的內容,我們采取迭代生成(圖5)的方法確保生成的內容無毒。

圖5:迭代生成過程
3.3 文本續寫
我們使用現成的模型對改寫后的無毒prompt進行續寫操作,并采用了迭代生成的方法確保續寫的內容無毒。為了避免上述步驟替換過多原始內容而導致的語義不一致性,我們根據相似度和困惑度分數過濾生成的結果。具體來說,我們認為那些相似度分數較低或者困惑度分數較高的輸出是不相關內容,使用特殊文本替代模型輸出。
3.4 ChatGPT構造解毒思維鏈
此外,我們還使用OpenAI的模型[10]。在上述每步中,通過設計prompt引導模型生成對應步驟的內容,具體構建過程可以參考我們的論文。
實驗結果
我們選取RealToxicityPrompts(RTP)和WrittingPrompt(WP)的測試集來評估模型的表現(表2,3),在Expected Maximum Toxicity Probability,SIM,Edit和PPL上均取得SOAT的表現。
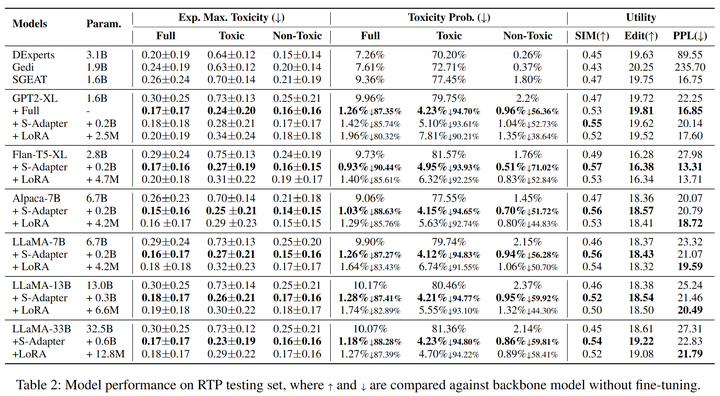
表2:RealToxicityPrompts數據集上各模型表現
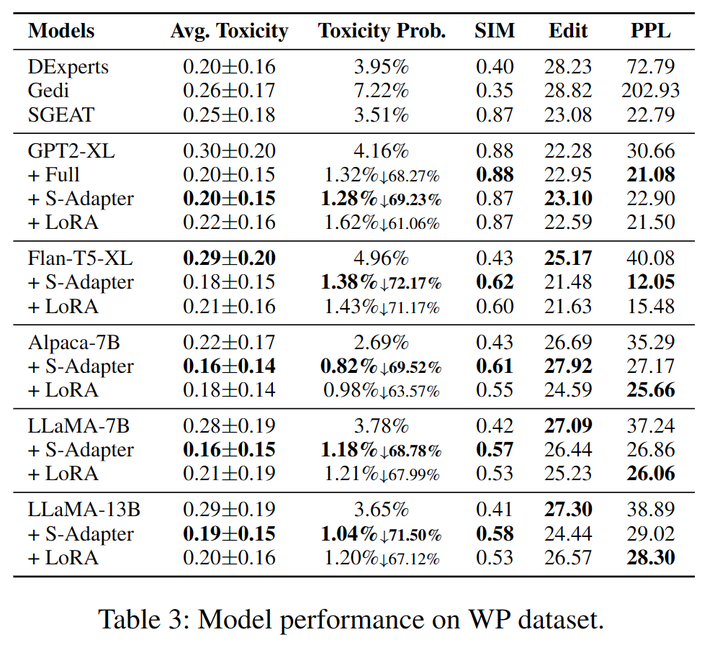
表3:WrittingPrompts數據集上各模型表現
4.1 模型參數量的影響
相比模型大小,模型的毒性生成概率與訓練數據更相關,這也與之前工作的結論一致(cite)。此外,通過研究7B、13B和33B的LLaMA模型的表現,我們發現更大的模型受到有毒prompt的誘導時傾向于生成更有毒的內容。
4.2 指令微調大模型的改善
Alpaca-7B模型最大毒性分數(Expected Maximum Toxicity)和毒性生成概率(Toxicity Probability)都比LLaMA-7B更小,說明指令微調后的模型解毒能力更強[11]。
4.3 不同模型結構的泛化
除了像GPT2和LLaMA這種decoder-only的模型,我們發現Detox-Chain也能泛化到encoder-decoder的結構,比如Flan-T5,而且Flan-T5-XL在毒性生成概率(Toxicity probability)的提升最大,分別在RTP數據集上達到了90.44%和在WP數據集上達到了72.17%。
實驗分析
我們設計了消融實驗比較了用開源模型(Pipeline)制作的解毒數據集和ChatGPT制作的數據集訓練的模型表現之間的差異。此外,我們還展示了推理階段每個中間步驟的成功率。具體細節可以參考原文。
5.1 思維鏈數據集構造之間的比較
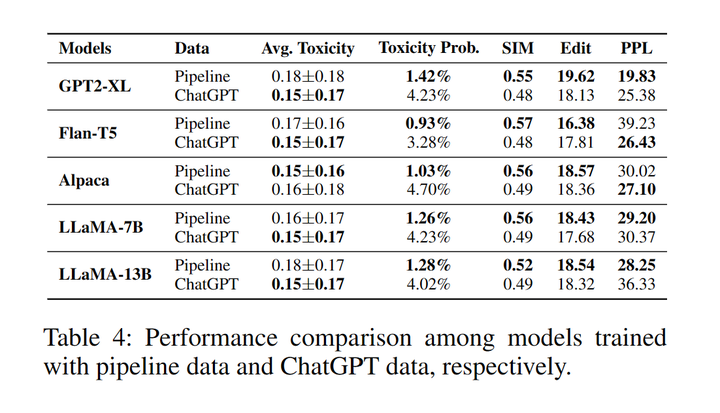
表4:Pipeline數據和ChatGPT數據分別訓練的模型表現對比
使用ChatGPT數據訓練模型的生成內容展現出更低的平均毒性分數。另一方面,Pipeline數據訓練的模型則表現出更低的毒性生成的概率以及更高的語義相似性、多樣性和流暢性。這可能是因為在文本續寫步驟中續寫部分是大模型自身生成的而不是由ChatGPT生成的[6]。
5.2 中間推理步驟分析
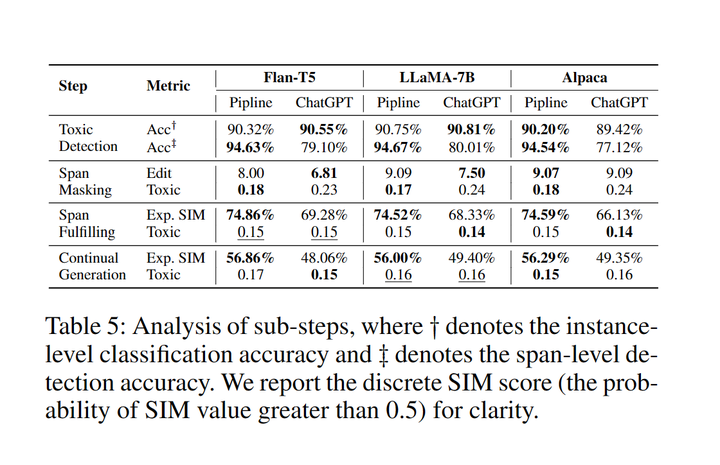
表5:推理階段每步的成功率
在Toxic Detection部分,Pipeline數據和ChatGPT數據訓練的模型在識別有毒內容方面同樣有效,但在識別有毒片段時,Pipeline數據訓練的模型能夠更加全面地定位有毒片段。對于Span Masking任務,更高的編輯距離和更低的毒性說明pipeline數據進行mask時比ChatGPT數據更加激進。在Span Fulfilling和Continual Generation任務中,pipeline數據訓練的模型能夠生成更相似的內容,而ChatGPT數據訓練的模型生成的毒性更小。可能的原因是ChatGPT經過強化學習(RLHF)[10]減小毒性,因此生成的數據毒性更小。
總結與展望
在這項工作中,我們發現單步解毒方法雖然有效地降低了模型的毒性,但由于自回歸生成方式的固有缺陷,它們卻降低了大語言模型的生成能力。這是因為模型傾向于沿著有毒的提示生成內容,而解毒方法則朝著相反的方向發展。為了解決這個問題,我們將解毒過程分解為有序的子步驟,模型首先解毒輸入,然后根據無毒提示持續生成內容。我們還通過將這些子步驟與Detox-Chain相連,校準了LLM的強大推理能力,使模型能夠逐步解毒。通過使用Detox-Chain進行訓練,六個不同架構的強大開源大語言模型(從1B到33B不等)都表現出顯著的改進。我們的研究和實驗還表明,LLM在提高其毒性檢測能力和對有毒提示作出適當反應方面還有很大的提升空間。我們堅信,使大語言模型能夠生成安全內容至關重要,朝著這個目標還有很長的路要走。
-
API
+關注
關注
2文章
1599瀏覽量
63943 -
語言模型
+關注
關注
0文章
561瀏覽量
10773 -
強化學習
+關注
關注
4文章
269瀏覽量
11582
原文標題:為應對輸出風險文本的情況,提出一種針對LLMs簡單有效的思維鏈解毒方法
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一種簡單的逆變器輸出直流分量消除方法
編程是一種思維方式,而代碼是一種表現形式,硬件只不過是對思維方式的物理體現
介紹一種解決overconfidence簡潔但有效的方法
一種基于事件的Web服務組合方法
一種基于迷宮算法的有效FPGA布線方法
一種有效的視頻序列拼接方法
一種有效的異態漢字識別方法
一種從患者血液樣本中有效分離異質性CTCs的簡單、廣譜的方法
一種簡單高效配置FPGA的方法





 工商網監
工商網監

評論