 AI計算能力限制:CoWoS和HBM供應鏈的挑戰
AI計算能力限制:CoWoS和HBM供應鏈的挑戰
Source: DYLAN PATEL,MYRON XIE, GERALD WONG, AI Capacity Constraints - CoWoS and HBM Supply Chain, July 6, 2023
生成式人工智能已經到來,它將改變世界。自從ChatGPT風靡全球,讓我們對人工智能的可能性充滿想象力以來,我們看到各種各樣的公司都在爭相訓練AI模型,并將生成式人工智能應用于內部工作流程或面向客戶的應用程序中。不僅是大型科技公司和初創公司,很多非科技行業的財富5000強公司也在努力尋找如何部署基于LLM的解決方案。
當然,這將需要大量的GPU計算資源。GPU銷售量像火箭一樣飆升,供應鏈難以滿足對GPU的需求。公司們正在爭相購買GPU或云實例。
即使是OpenAI也無法獲得足夠的GPU,這嚴重制約了其近期的路線圖。由于GPU短缺,OpenAI無法部署其多模態模型。由于GPU短缺,OpenAI無法部署更長的序列長度模型(8k vs 32k)。
與此同時,中國公司不僅在投資部署自己的LLM,還在美國出口管制進一步加強之前進行庫存儲備。例如,抖音背后的中國公司字節跳動據說正在向Nvidia訂購價值超過10億美元的A800/H800。
雖然有許多合理的用例需要數十萬個GPU用于人工智能,但也有很多情況是人們急于購買GPU,試圖構建他們不確定是否有合法市場的項目。在某些情況下,大型科技公司正在努力迎頭趕上OpenAI和Google,以免被拋在后頭。大量風投資金涌入那些沒有明確商業用例的初創公司。我們了解到有十幾個企業正在嘗試在自己的數據上訓練自己的LLM。最后,這也適用于包括沙特阿拉伯和阿聯酋在內的國家,他們今年也試圖購買價值數億美元的GPU。
即使Nvidia試圖大幅增加產量,最高端的Nvidia GPU H100也將在明年第一季度之前售罄。Nvidia將逐漸提高每季度H100 GPU的發貨量,達到40萬枚。
今天我們將詳細介紹Nvidia及其競爭對手在生產方面的瓶頸以及下游容量的擴展情況。我們還將分享我們對Nvidia、Broadcom、Google、AMD、AMD Embedded(Xilinx)、Amazon、Marvell、Microsoft、Alchip、Alibaba T-Head、ZTE Sanechips、三星、Micron和SK Hynix等公司每個季度供應增長的估計。

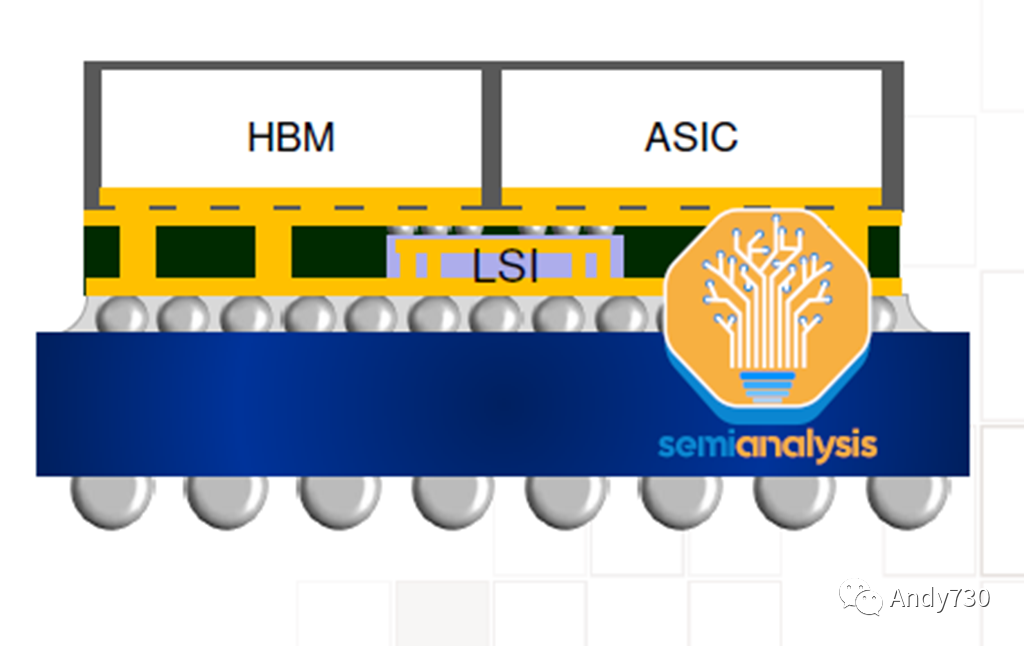
Nvidia的H100采用CoWoS-S封裝,共有7個芯片組件。中心是H100 GPU ASIC,其芯片尺寸為814平方毫米。周圍是6個HBM存儲堆疊。HBM的配置因不同的SKU而異,但H100 SXM版本使用HBM3,每個堆疊為16GB,總內存容量為80GB。H100 NVL將有兩個封裝,每個封裝上有6個活動的HBM堆疊。
在只有5個活動HBM的情況下,非HBM芯片可以是虛擬硅,用于為芯片提供結構支撐。這些芯片位于硅中間層之上,該硅中間層在圖片中不清晰可見。這個硅中間層位于ABF封裝基板上。
01.GPU芯片和TSMC制造
Nvidia GPU的主要計算組件是處理器芯片本身,采用定制的TSMC工藝節點“4N”制造。它在臺灣臺南的TSMC Fab 18工廠中制造,與TSMC N5和N4工藝節點共享設施。這不是生產的限制因素。
由于個人電腦、智能手機和非人工智能相關的數據中心芯片市場的嚴重疲軟,TSMC的N5工藝節點利用率降至70%以下。Nvidia在獲取額外晶圓供應方面沒有遇到問題。
事實上,Nvidia已經訂購了大量用于H100 GPU和NVSwitch的晶圓,并在這些芯片需要出貨之前立即開始生產。這些晶圓將在TSMC的晶圓庫中存放,直到下游供應鏈有足夠的能力將這些晶圓封裝成成品芯片。
基本上,Nvidia正在利用TSMC低利用率的情況,并在后續購買成品的路上獲得一些價格優勢。
芯片庫,也被稱為晶圓庫,是半導體行業的一種做法,即將部分加工或已完成的晶圓存放,直到客戶需要時再提供。與其它一些晶圓代工廠不同,TSMC會幫助客戶將這些晶圓保留在自己的賬面上,幾乎進行完整的加工。這種做法可以使TSMC及其客戶保持財務靈活性。由于這些晶圓只是部分加工,所以存放在晶圓庫中的晶圓并不被視為成品,而是被歸類為在制品(WIP)。只有當這些晶圓完全完成時,TSMC才能確認收入并將這些晶圓的所有權轉移給客戶。
幫助客戶調整資產負債表,使其看起來庫存水平得到了控制。對于TSMC而言,好處在于可以提高利用率,從而支持利潤率。然后,當客戶需要更多庫存時,這些晶圓可以通過幾個最后的加工步驟完全完成,然后以正常銷售價格甚至略有折扣交付給客戶。
02.數據中心中HBM的出現
AMD的創新如何幫助了Nvidia
圍繞GPU的高帶寬內存(HBM,High Bandwidth Memory)是下一個重要組件。HBM供應也有限,但正在增加。HBM是通過硅穿透孔(TSV,Through Silicon Vias)連接的垂直堆疊DRAM芯片,并使用TCB(thermocompression bonding,在未來需要更高堆疊層數時將需要使用混合鍵合技術)進行鍵合。在DRAM芯片的下方是一個作為控制器的基礎邏輯芯片。通常,現代HBM有8層存儲芯片和1個基礎邏輯芯片,但我們很快將看到具有12+1層HBM的產品,例如AMD的MI300X和Nvidia即將推出的H100升級版。
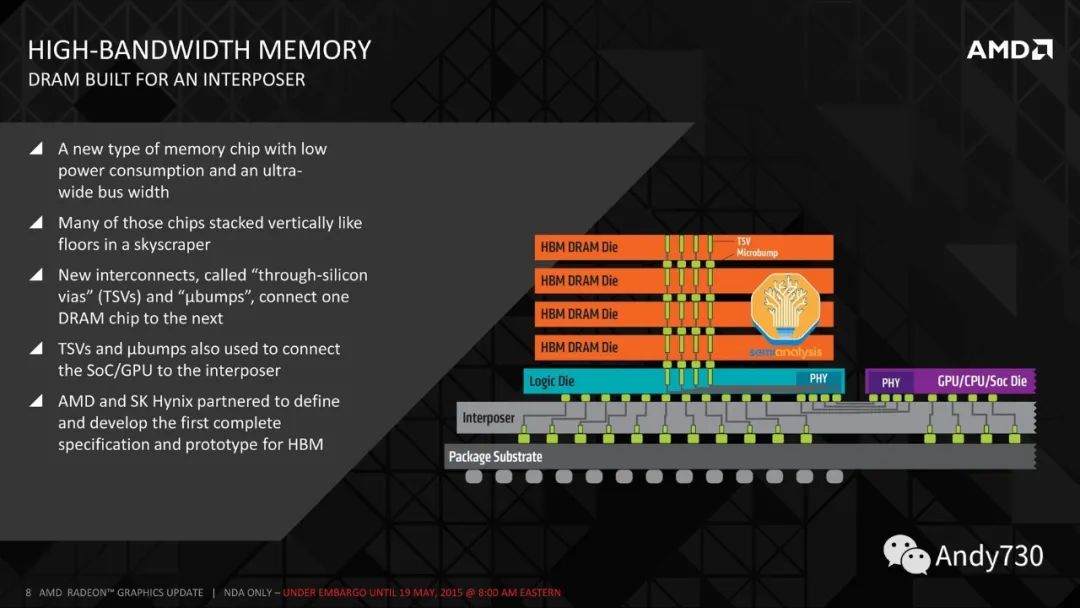
有趣的是,盡管Nvidia和Google是HBM的最大用戶,但是AMD是HBM的先驅。在2008年,AMD預測,為了匹配游戲GPU性能的持續提升,需要更多的功率,這將需要從GPU邏輯中分流,從而降低GPU性能。AMD與SK Hynix和其它供應鏈中的公司(如Amkor)合作,尋找一種能夠在更低功耗下提供高帶寬的存儲解決方案。這導致了2013年由SK Hynix開發的HBM技術的誕生。

SK Hynix于2015年首次為AMD的Fiji系列游戲GPU提供了HBM技術,這些芯片由Amkor進行了2.5D封裝。隨后,在2017年推出了Vega系列,該系列采用了HBM2技術。然而,HBM對游戲GPU性能并沒有帶來太大改變。由于性能上沒有明顯的優勢,再加上成本較高,AMD在Vega之后又轉而使用了GDDR技術來供應其游戲顯卡。如今,Nvidia和AMD的頂級游戲GPU仍在使用價格更低的GDDR6技術。
然而,AMD的初始預測在某種程度上是正確的:內存帶寬的擴展對于GPU來說確實是一個問題,尤其是對于數據中心的GPU而言。對于消費級游戲GPU,Nvidia和AMD已經轉向使用大容量緩存來存儲幀緩沖區,使它們能夠使用帶寬較低的GDDR內存。
正如我們之前詳細介紹的那樣,推理和訓練工作負載對內存的需求很高。隨著AI模型中參數數量的指數增長,僅僅是權重的模型大小就已經達到了TB級別。因此,AI加速器的性能受到存儲和檢索訓練和推理數據的能力的限制,這通常被稱為內存壁。
為了解決這個問題,領先的數據中心GPU采用了與高帶寬內存(HBM)進行共封裝的方式。Nvidia在2016年推出了他們的首款HBM GPU,即P100。HBM通過在傳統DDR內存和芯片上緩存之間找到了一個折衷方案,通過犧牲容量來提高帶寬。通過大幅增加引腳數,每個HBM堆棧可以實現1024位寬的內存總線,這是DDR5每個DIMM的64位寬度的18倍。與此同時,通過大幅縮短距離,HBM的功耗得到了控制,每位傳輸的能量消耗顯著降低(以皮焦每比特為單位)。相比于GDDR和DDR的厘米級長度,HBM的傳輸路徑只有毫米級長短。
今天,許多面向高性能計算的芯片公司正在享受AMD努力的成果。諷刺的是,AMD的競爭對手Nvidia可能是最大的受益者,成為HBM的最大用戶。
03.HBM市場:SK Hynix的主導地位
三星和美光投資迎頭趕上
作為HBM的先驅,SK Hynix是技術路線圖最為先進的領導者。SK Hynix于2022年6月開始批量生產HBM3,目前是唯一的HBM3供應商,市場份額超過95%,大多數H100 SKU產品都在使用。目前HBM的最大配置是8層16GB HBM3模塊。SK Hynix正在生產12層24GB HBM3,數據速率為5.6 GT/s,用于AMD MI300X和Nvidia H100的升級版本。

HBM的主要挑戰在于封裝和堆疊內存,而這正是SK Hynix擅長的領域,他們積累了最強的工藝流程知識。在未來的文章中,我們還將詳細介紹SK Hynix的兩項關鍵封裝創新,它們正在逐步推進,并將取代當前HBM工藝中的一個關鍵設備供應商。
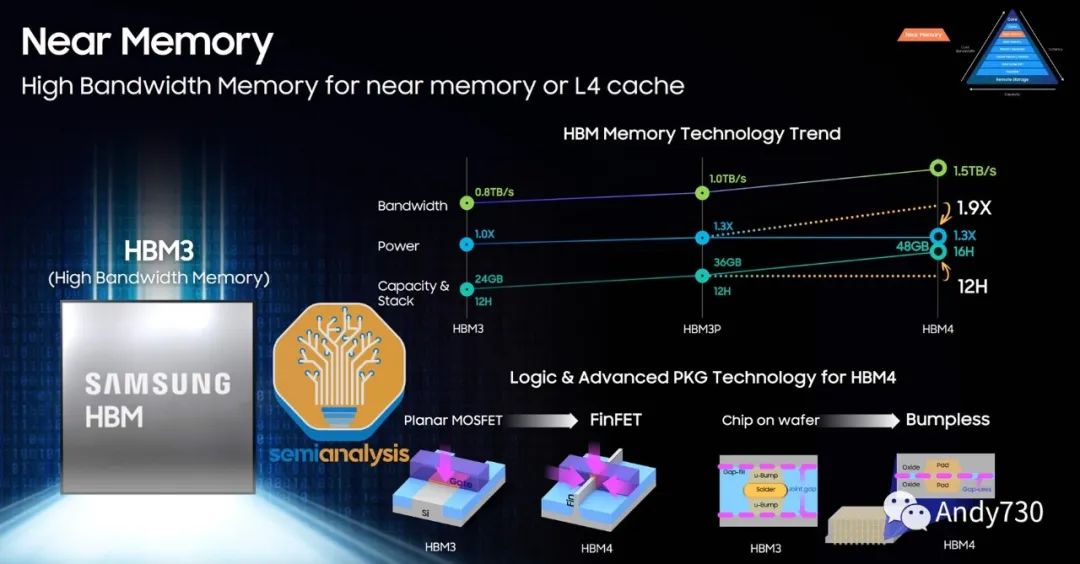
三星緊隨其后,預計將于2023年下半年開始出貨HBM3。我們相信它們設計用于Nvidia和AMD的GPU。目前,它們在產量上與SK Hynix相比存在巨大的差距,但它們正在大舉投資以追趕市場份額。三星正在努力迎頭趕上,并力爭成為HBM市場份額的第一。我們聽說他們正在與一些加速器公司達成有利的交易,試圖獲得更多份額。
他們展示了他們的12層HBM以及未來的混合鍵合HBM。三星HBM-4技術路線圖中一個有趣的方面是,他們希望將邏輯/外圍電路放在內部FinFET節點上。這顯示了他們在擁有邏輯和DRAM代工廠方面的潛在優勢。

美光公司目前進展最慢。美光公司在混合存儲立方(Hybrid Memory Cube,HMC)技術方面進行了更大的投資。HMC是與HBM競爭的一種技術,概念非常相似,并在同一時期發展起來。然而,HMC周圍的生態系統是封閉的,這使得很難在HMC周圍開發知識產權。此外,HMC存在一些技術缺陷。由于HBM的采用率更高,因此HBM成為了3D堆疊DRAM的行業標準。
直到2018年,美光才開始轉向HBM并進行投資。這就是為什么美光進展最慢的原因。他們仍然停留在HBM2E階段(而SK Hynix在2020年中期開始大規模生產HBM2E),甚至無法成功制造頂級的HBM2E芯片。
在最近的財務電話會議中,美光對他們的HBM技術路線圖發表了一些大膽的言論:他們相信他們將在2024年憑借HBM3E從落后者變為領先者。預計HBM3E將于2024年第三季度/第四季度開始供貨,用于Nvidia的下一代GPU。
我們的HBM3規模化生產實際上是下一代HBM3,具有比當前行業中HBM3產品性能、帶寬更高、功耗更低的水平。該產品將從2024年第一季度開始規模化生產,并在2024財年帶來可觀的收入,2025年將大幅增長,甚至超過2024年的水平。我們的目標是在HBM領域占據非常強勢的份額,超過當前行業DRAM的自然供應份額。
-----美光公司首席業務官Sumit Sadana
他們聲稱在HBM領域的市場份額高于他們在DRAM市場的份額,這是非常大膽的說法。考慮到他們仍然在高產量上無法成功制造頂級HBM2E芯片,我們很難相信美光聲稱他們將在2024年初發貨領先的HBM3芯片,甚至成為首個發布HBM3E芯片。在我們看來,美光似乎試圖改變關于他們在人工智能領域的失敗者形象,盡管與英特爾/AMD CPU服務器相比,Nvidia GPU服務器的內存容量大大降低。
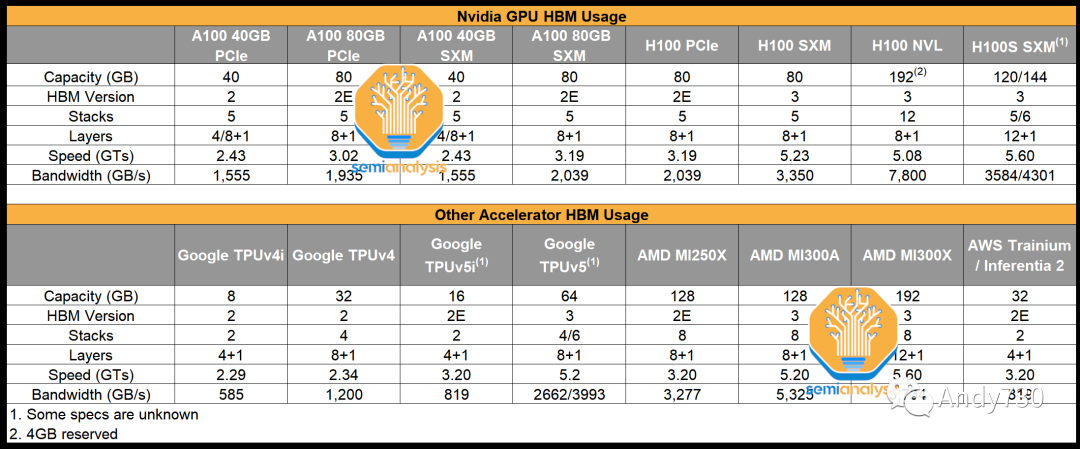
根據我們的渠道檢查,SK Hynix在新一代技術方面仍然保持領先地位,而三星則在大幅增加供應、提出大膽路線圖并達成交易方面努力迎頭趕上。
04.真正的瓶頸是CoWoS技術
CoWoS(Chip on Wafer on Substrate,芯片在晶圓上的襯底上)是TSMC的“2.5D”封裝技術,多個活性硅芯片(通常是邏輯芯片和HBM堆疊芯片)集成在一個被動硅中間層上。中間層作為頂部活性芯片的通信層。然后,中間層和活性硅芯片與包裝基板連接在一起,包裝基板上含有與系統PCB連接的I/O接口。
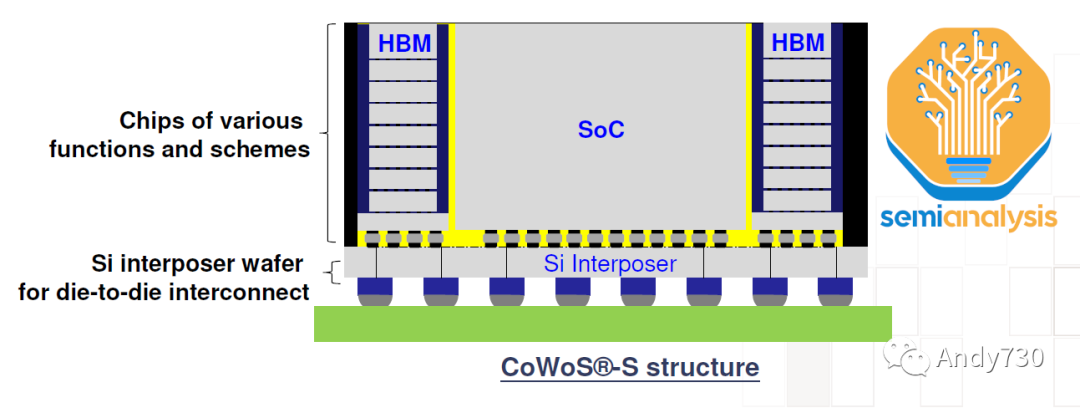
HBM和CoWoS是相輔相成的。HBM的高引腳數和短跡長要求需要2.5D先進封裝技術,如CoWoS,才能實現密集、短距離的連接,這在PCB甚至包裝基板上無法實現。CoWoS是主流封裝技術,提供最高的互連密度和最大的封裝尺寸,而成本合理。由于幾乎所有HBM系統目前都采用CoWoS封裝,所有先進的人工智能加速器都使用HBM,因此可以推斷,幾乎所有領先的數據中心GPU都由TSMC采用CoWoS封裝。百度在其產品中使用了三星的高級加速器。
盡管TSMC的SoIC等3D封裝技術可以直接將芯片堆疊在邏輯芯片上,但對于HBM來說,這種做法在熱管理和成本方面并不合理。SoIC在互連密度方面處于不同的數量級,并更適合通過芯片堆疊擴展片上緩存,正如AMD的3D V-Cache解決方案所示。AMD的Xilinx也是多年前最早使用CoWoS技術將多個FPGA芯片集成在一起的用戶。
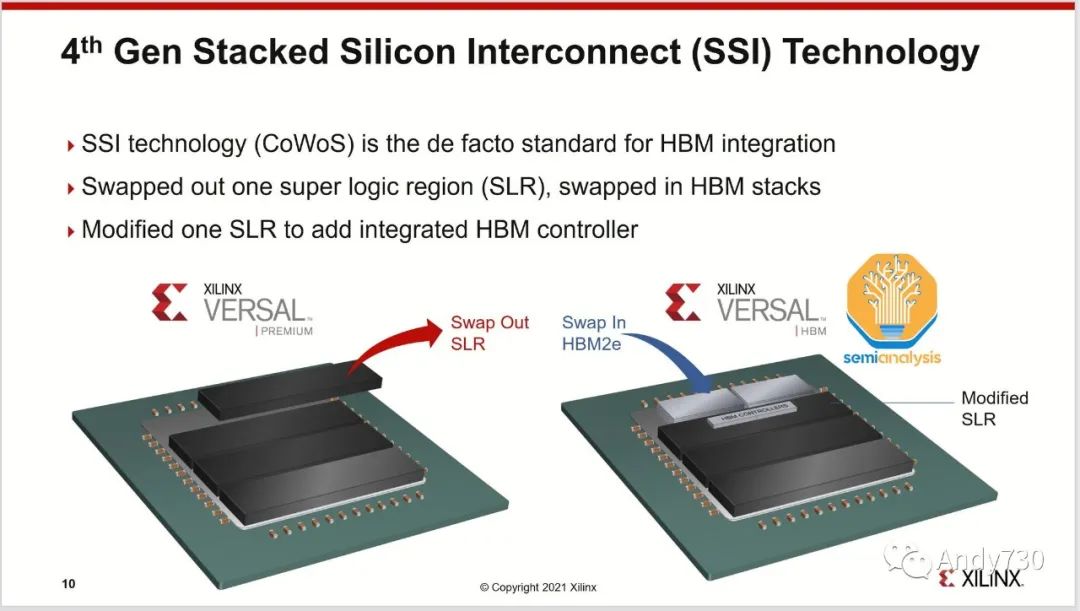
盡管還有其它一些應用程序使用了CoWoS技術,如網絡(其中一些被應用于網絡GPU集群,如博通的Jericho3-AI)、超級計算和FPGA,但絕大多數CoWoS的需求來自于人工智能領域。與半導體供應鏈的其它主要終端市場不同,這些市場的疲軟意味著有足夠的閑置產能來滿足對GPU的巨大需求,CoWoS和HBM已經是主要面向人工智能的技術,因此2022年第一季度已經消耗了所有的閑置產能。隨著GPU需求的激增,這些供應鏈的部分已經無法跟上,成為了GPU供應的瓶頸。
就在最近的兩天,我接到了一個客戶的電話,要求大幅增加后端產能,特別是CoWoS方面的產能。我們正在評估這個需求。
-----TSMC首席執行官魏哲家
TSMC一直在為更多的封裝需求做準備,但可能沒有預料到這股生成式人工智能需求會來得如此迅速。今年6月,TSMC宣布他們在竹南開設了先進封測 6工廠。這個工廠占地面積達14.3公頃,足夠容納每年高達100萬片的3D封測產能。這不僅包括CoWoS,還包括SoIC和InFO技術。有趣的是,這個工廠的面積比TSMC其它封裝工廠的總和還要大。盡管這只是凈化室的面積,并遠未完全配備充分的設備來提供如此多的產能,但很明顯TSMC正在做好準備,預期會有更多對其先進封裝解決方案的需求。
微觀封裝(Wafer Level Fan-Out)的產能有些閑置,這在主要用于智能手機SoC的領域比較常見,其中的一些部分可以重新用于CoWoS的某些工藝步驟。特別是在沉積、電鍍、背面研磨、成型、放置和RDL(重密度線路)形成等方面存在一些重疊的工藝。我們將在后續文章中詳細介紹CoWoS的工藝流程以及所有由此帶來積極需求的公司。在設備供應鏈中會有一些有意義的變化。
英特爾、三星和外包測試組織(如ASE的FOEB)還有其它的2.5D封裝技術,但CoWoS是唯一一種被大量采用的,因為TSMC是最為主導的人工智能加速器代工廠。甚至英特爾的Habana加速器也是由TSMC制造和封裝。然而,一些客戶正在尋求與TSMC的替代方案,下面我們將討論這方面的內容。更多信息請參閱我們的先進封裝系列。
05.CoWoS的變種
CoWoS有幾個變種,但原始的CoWoS-S仍然是高產量生產的唯一配置。這是上面描述的經典配置:邏輯芯片和HBM芯片通過基于硅的中間層和TSV進行連接。中間層然后放置在有機封裝基板上。

硅中間層的一項關鍵技術是“版圖拼接”(reticle stitching)。由于光刻工具的缺陷掃描限制,芯片通常具有最大尺寸為26mm x 33mm。隨著GPU芯片尺寸接近這一限制并需要適應周圍的HBM芯片,中間層需要更大的尺寸,將超過這個版圖限制。TSMC利用版圖拼接技術來解決這個問題,允許他們對中間層進行多次版圖拼接(目前最多可以達到3.5倍,與AMD的MI300相適應)。
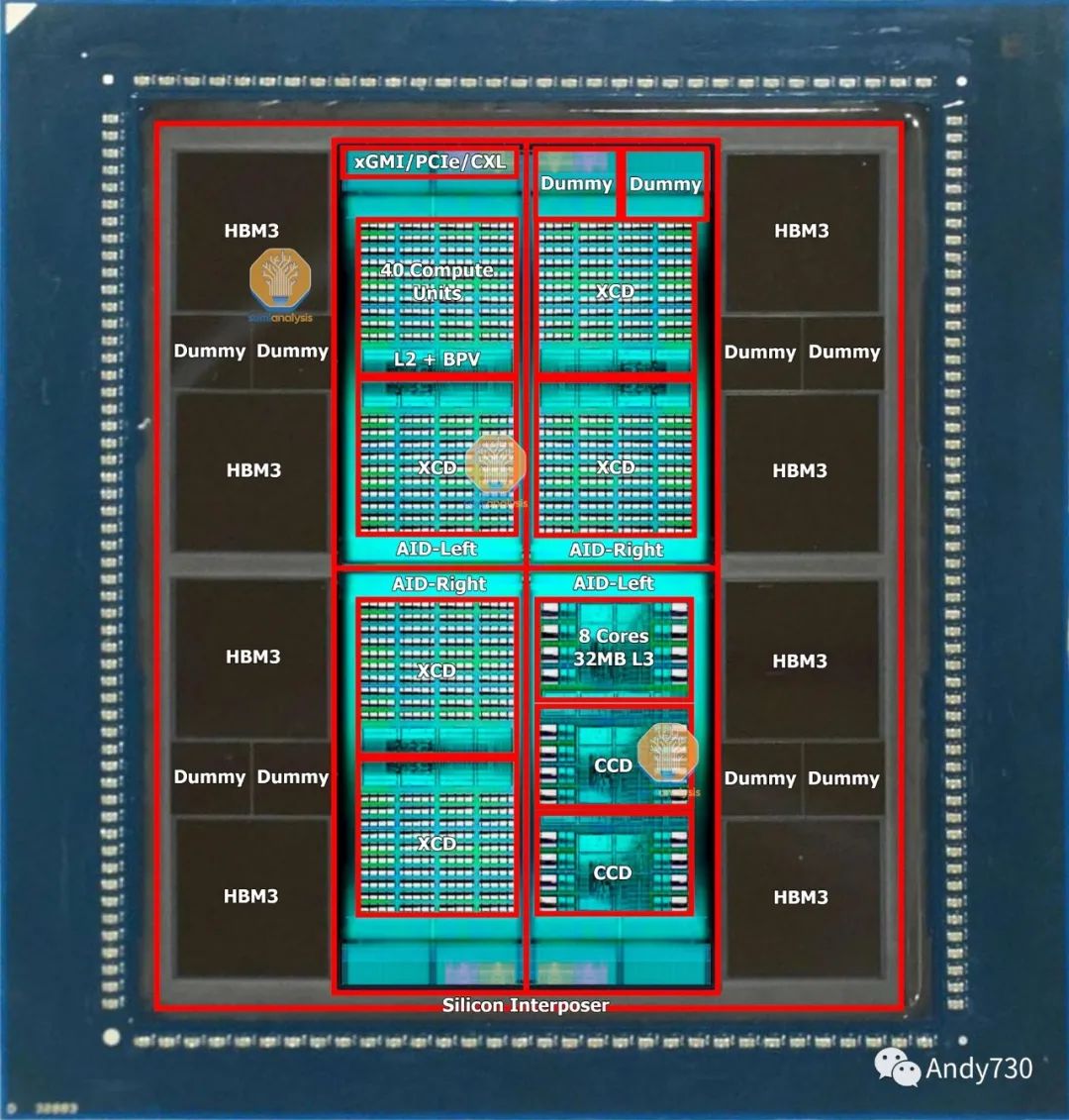
CoWoS-R采用有機基板和重新分布層(RDL),而不是硅中間層。這是一種成本較低的變種,由于使用有機RDL而不是基于硅的中間層,犧牲了I/O密度。正如我們所詳細介紹的那樣,AMD的MI300最初是設計在CoWoS-R上的,但我們認為由于翹曲和熱穩定性的問題,AMD不得不改用CoWoS-S。
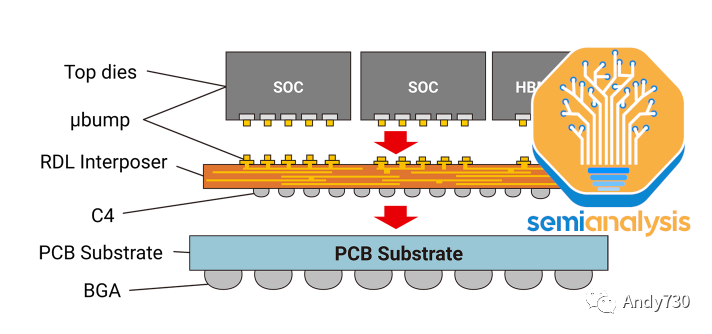
CoWoS-L預計將于今年晚些時候推出,并使用RDL中間層,但包含用于芯片間互連的主動和/或被動硅橋,嵌入在中間層內部。這是TSMC的等效產品,類似于英特爾的EMIB封裝技術。這將允許更大的封裝尺寸,因為硅中間層的規模越來越難以擴展。MI300 CoWoS-S可能已接近單個硅中間層的限制。
對于更大的設計來說,采用CoWoS-L將更具經濟性。TSMC正在研發一個6倍版圖尺寸的CoWoS-L超級載體中間層。對于CoWoS-S,他們并未提及超過4倍版圖的內容。這是因為硅中間層的脆弱性。這種硅中間層只有100微米厚,當中間層在工藝流程中擴展到更大尺寸時,有可能出現剝離或開裂的風險。
-
gpu
+關注
關注
28文章
4729瀏覽量
128903 -
CoWoS
+關注
關注
0文章
138瀏覽量
10485 -
OpenAI
+關注
關注
9文章
1082瀏覽量
6485
原文標題:AI計算能力限制:CoWoS和HBM供應鏈的挑戰
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英偉達AI服務器供應鏈遇挑戰:GB300/B300 DrMOS過熱問題
智能制造裝備行業的供應鏈特點分析

數字孿生在供應鏈優化中的作用
英偉達Blackwell AI服務器遭遇供應鏈挑戰
深入了解半導體供應鏈:特點、風險與未來趨勢

供應鏈大屏設計實踐
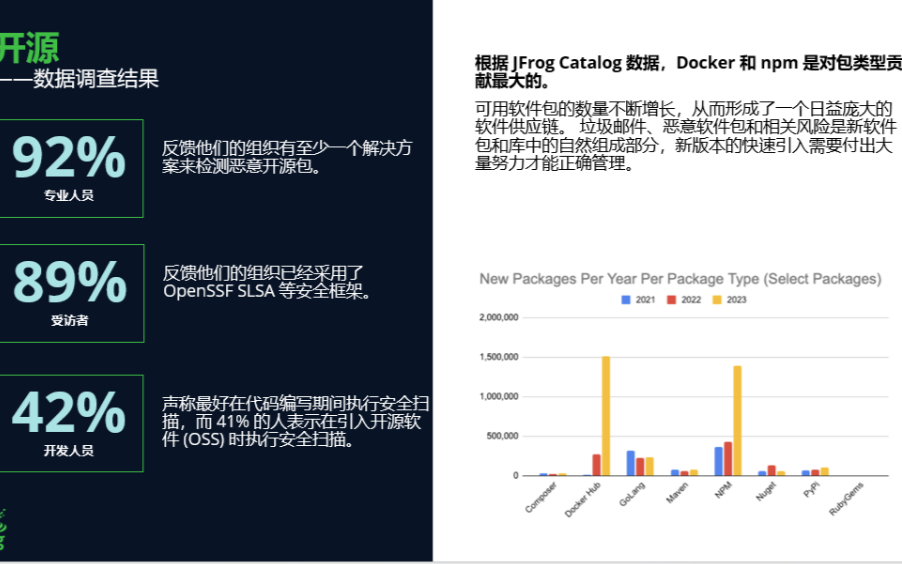
生成式AI之下,軟件供應鏈安全的升級更迫切

戴爾榮獲Gartner供應鏈的最高榮譽“年度供應鏈突破獎”






 工商網監
工商網監
評論