 語言大模型內部究竟是如何工作的?
語言大模型內部究竟是如何工作的?
OneFlow編譯
當ChatGPT在去年秋天推出時,在科技行業乃至世界范圍內引起了轟動。當時,機器學習研究人員嘗試研發了多年的語言大模型(LLM),但普通大眾并未十分關注,也沒有意識到它們變得多強大。
如今,幾乎每個人都聽說過LLM,并有數千萬人用過它們,但是,了解工作原理的人并不多。你可能聽說過,訓練LLM是用于“預測下一個詞”,而且它們需要大量的文本來實現這一點。但是,解釋通常就止步于此。它們如何預測下一個詞的細節往往被視為一個深奧的謎題。
其中一個原因是,這些系統的開發方式與眾不同。一般的軟件是由人類工程師編寫,他們為計算機提供明確的、逐步的指令。相比之下,ChatGPT是建立在一個使用數十億個語言詞匯進行訓練的神經網絡之上。
因此,地球上沒有人完全理解LLM的內部工作原理。研究人員正在努力嘗試理解這些模型,但這是一個需要數年甚至幾十年才能完成的緩慢過程。
然而,專家們確實對這些系統的工作原理已有不少了解。本文的目標是將這些知識開放給廣大受眾。我們將努力解釋關于這些模型內部工作原理的已知內容,而不涉及技術術語或高級數學。
我們將從解釋詞向量(word vector)開始,它是語言模型表示和推理語言的一種令人驚訝的方式。然后,我們將深入探討構建ChatGPT等模型的基石Transformer。最后,我們將解釋這些模型是如何訓練的,并探討為什么要使用龐大的數據量才能獲得良好的性能。
1
詞向量
要了解語言模型的工作原理,首先需要了解它們如何表示單詞。人類用字母序列來表示英文單詞,比如C-A-T表示貓。語言模型使用的是一個叫做詞向量的長串數字列表。例如,這是一種將貓表示為向量的方式:
[0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, 0.0191, 0.0038, -0.0468, -0.0212, 0.0091, 0.0030, -0.0563, -0.0396, -0.0998, -0.0796, …, 0.0002]
(注:完整的向量長度實際上有300個數字)
為什么要使用如此復雜的表示法?這里有個類比,華盛頓特區位于北緯38.9度,西經77度,我們可以用向量表示法來表示:
? 華盛頓特區的坐標是[38.9,77]
? 紐約的坐標是[40.7,74]
? 倫敦的坐標是[51.5,0.1]
? 巴黎的坐標是[48.9,-2.4]
這對于推理空間關系很有用。你可以看出,紐約離華盛頓特區很近,因為坐標中38.9接近40.7,77接近74。同樣,巴黎離倫敦也很近。但巴黎離華盛頓特區很遠。
語言模型采用類似的方法:每個詞向量代表了“詞空間(word space)”中的一個點,具有相似含義的詞的位置會更接近彼此。例如,在向量空間中與貓最接近的詞包括狗、小貓和寵物。用實數向量表示單詞(相對于“C-A-T”這樣的字母串)的一個主要優點是,數字能夠進行字母無法進行的運算。
單詞太復雜,無法僅用二維表示,因此語言模型使用具有數百甚至數千維度的向量空間。人類無法想象具有如此高維度的空間,但計算機完全可以對其進行推理并產生有用的結果。
幾十年來,研究人員一直在研究詞向量,但這個概念真正引起關注是在2013年,那時Google公布了word2vec項目。Google分析了從Google新聞中收集的數百萬篇文檔,以找出哪些單詞傾向于出現在相似的句子中。隨著時間的推移,一個經訓練過的神經網絡學會了將相似類別的單詞(如狗和貓)放置在向量空間中的相鄰位置。
Google的詞向量還具有另一個有趣的特點:你可以使用向量運算“推理”單詞。例如,Google研究人員取出最大的(biggest)向量,減去大的(big)向量,再加上小的(small)向量。與結果向量最接近的詞就是最小的(smallest)向量。
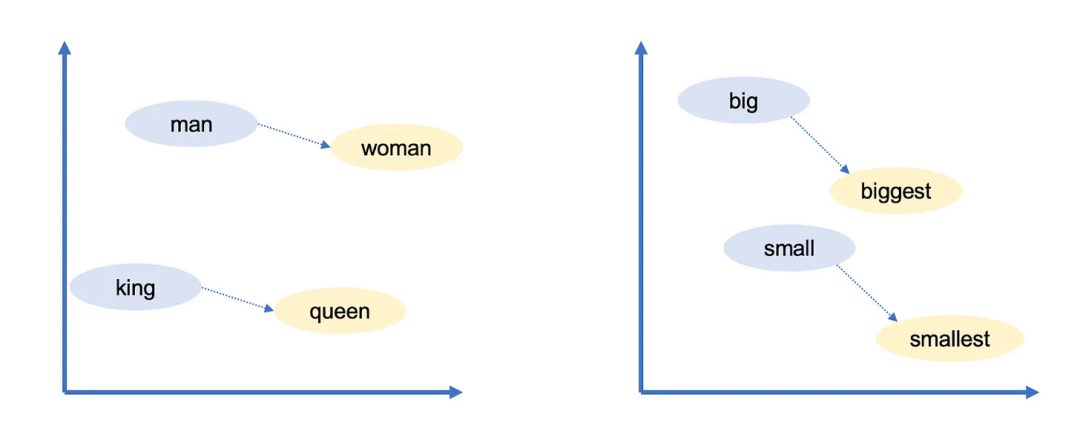
你可以使用向量運算來做類比!在這個例子中,大(big)與最大的(biggest)的關系,類似于小(small)與最小的(smallest)的關系。Google的詞向量捕捉到了許多其他的關系:
? 瑞士人與瑞士類似于柬埔寨人與柬埔寨。(國籍)
? 巴黎與法國類似于柏林與德國。(首都)
? 不道德的與道德的類似于可能的與不可能的。(反義詞)
? Mouse(老鼠)與mice(老鼠的復數)類似于dollar(美元)與dollars(美元的復數)。(復數形式)
? 男人與女人類似于國王與女王。(性別角色)
因為這些向量是從人們使用語言的方式中構建的,它們反映了許多存在于人類語言中的偏見。例如,在某些詞向量模型中,(醫生)減去(男人)再加上(女人)等于(護士)。減少這種偏見是一個很新穎的研究領域。
盡管如此,詞向量是語言模型的一個有用的基礎,它們編碼了詞之間微妙但重要的關系信息。如果一個語言模型學到了關于貓的一些知識(例如,它有時會去看獸醫),那同樣的事情很可能也適用于小貓或狗。如果模型學到了關于巴黎和法國之間的關系(例如,它們共用一種語言),那么柏林和德國以及羅馬和意大利的關系很可能是一樣的。
2
詞的意義取決于上下文
像這樣簡單的詞向量方案并沒有捕獲到自然語言的一個重要事實:詞通常有多重含義。
例如,單詞“bank”可以指金融機構或河岸。或者考慮以下句子:
?John picks up amagazine(約翰拿起一本雜志)。
?Susan works for amagazine(蘇珊為一家雜志工作)。
這些句子中,“magazine”的含義相關但又有不同。約翰拿起的是一本實體雜志,而蘇珊為一家出版實體雜志的機構工作。
當一個詞有兩個無關的含義時,語言學家稱之為同音異義詞(homonyms)。當一個詞有兩個緊密相關的意義時,如“magazine”,語言學家稱之為多義詞(polysemy)。
像ChatGPT這樣的語言模型能夠根據單詞出現的上下文以不同的向量表示同一個詞。有一個針對“bank(金融機構)”的向量,還有一個針對“bank(河岸)”的向量。有一個針對“magazine(實體出版物)”的向量,還有一個針對“magazine(出版機構)”的向量。正如你預想的那樣,對于多義詞的含義,語言模型使用的向量更相似,而對于同音異義詞的含義,使用的向量則不太相似。
到目前為止,我們還沒有解釋語言模型是如何做到這一點——很快會進入這個話題。不過,我們正在詳細說明這些向量表示,這對理解語言模型的工作原理非常重要。
傳統軟件的設計被用于處理明確的數據。如果你讓計算機計算“2+3”,關于2、+或3的含義不存在歧義問題。但自然語言中的歧義遠不止同音異義詞和多義詞:
? 在“the customer asked the mechanic to fixhiscar(顧客請修理工修理他的車)”中,“his”是指顧客還是修理工?
? 在“the professor urged the student to doherhomework(教授催促學生完成她的家庭作業)”中,“her”是指教授還是學生?
? 在“fruitflieslike a banana”中,“flies”是一個動詞(指在天空中飛的水果像一只香蕉)還是一個名詞(指喜歡香蕉的果蠅)?
人們根據上下文來解決這類歧義,但并沒有簡單或明確的規則。相反,這需要理解關于這個世界的實際情況。你需要知道修理工通常會修理顧客的汽車,學生通常完成自己的家庭作業,水果通常不會飛。
詞向量為語言模型提供了一種靈活的方式,以在特定段落的上下文中表示每個詞的準確含義。現在讓我們看看它們是如何做到這一點的。
3
將詞向量轉化為詞預測
ChatGPT原始版本背后的GPT-3模型,由數十個神經網絡層組成。每一層接受一系列向量作為輸入——輸入文本中的每個詞對應一個向量——并添加信息以幫助澄清該詞的含義,并且更好地預測接下來可能出現的詞。
讓我們從一個簡單的事例說起。
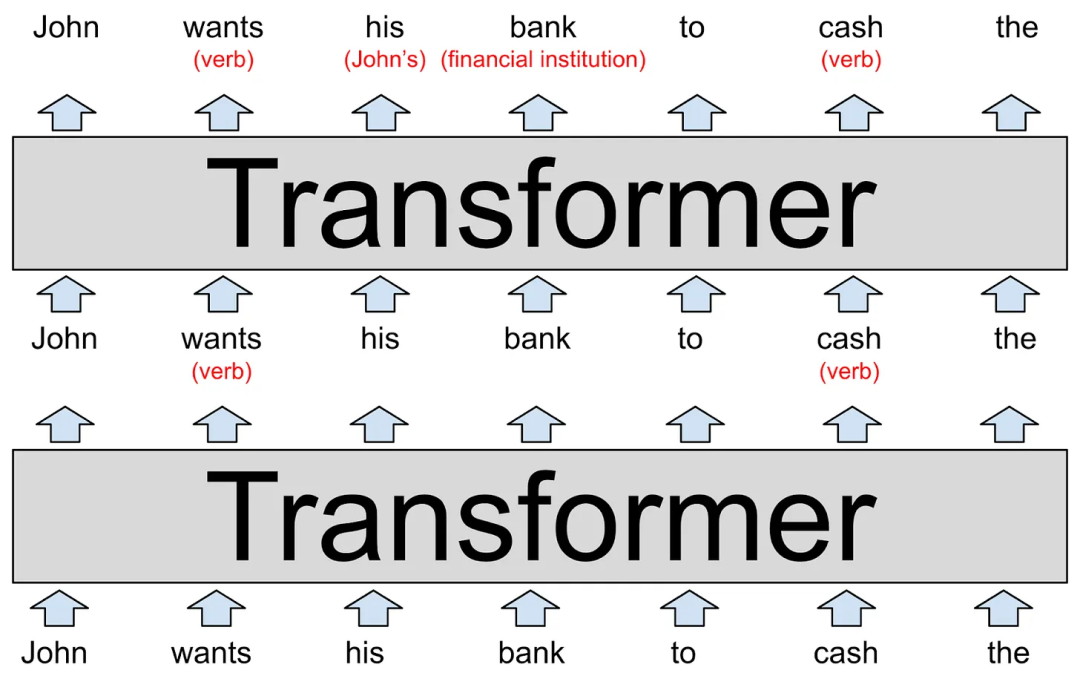
LLM的每個層都是一個Transformer,2017年,Google在一篇里程碑的論文中首次介紹了這一神經網絡結構。
在圖表底部,模型的輸入文本是“John wants his bank to cash the(約翰想讓他的銀行兌現)”, 這些單詞被表示為word2vec風格的向量,并傳送至第一個Transformer。這個Transformer確定了wants和cash都是動詞(這兩個詞也可以是名詞)。我們用小括號中的紅色文本表示這一附加的上下文,但實際上模型會通過修改詞向量的方式來存儲這一信息,這種方式對人類來說很難解釋。這些新的向量被稱為隱藏狀態(hidden state),并傳遞給下一個Transformer。
第二個Transformer添加了另外兩個上下文信息:它澄清了bank是指金融機構(financial institution)而不是河岸,并且his是指John的代詞。第二個Transformer產生了另一組隱藏狀態向量,這一向量反映的是該模型之前所學習的所有信息。
上述圖表描繪的是一個純假設的LLM,所以不要對細節過于較真。真實的LLM往往有更多層。例如,最強大的GPT-3版本有96層。
研究表明(https://arxiv.org/abs/1905.05950),前幾層專注于理解句子的語法并解決上面所示的歧義。后面的層(為保持圖表大小的可控性上述圖標沒有顯示)則致力于對整個段落的高層次理解。
例如,當LLM“閱讀”一篇短篇小說時,它似乎會記住關于故事角色的各種信息:性別和年齡、與其他角色的關系、過去和當前的位置、個性和目標等等。
研究人員并不完全了解LLM是如何跟蹤這些信息的,但從邏輯上講,模型在各層之間傳遞時信息時必須通過修改隱藏狀態向量來實現。現代LLM中的向量維度極為龐大,這有利于表達更豐富的語義信息。
例如,GPT-3最強大的版本使用有12288個維度的詞向量,也就是說,每個詞由一個包含12288個的數字列表表示。這比Google在2013年提出的word2vec方案要大20倍。你可以把所有這些額外的維度看作是GPT-3可以用來記錄每個詞的上下文的一種“暫存空間(scratch space)”。較早層所做的信息筆記可以被后來的層讀取和修改,使模型逐漸加深對整篇文章的理解。
因此,假設我們將上面的圖表改為,描述一個96層的語言模型來解讀一個1000字的故事。第60層可能包括一個用于約翰(John)的向量,帶有一個表示為“(主角,男性,嫁給謝麗爾,唐納德的表弟,來自明尼蘇達州,目前在博伊西,試圖找到他丟失的錢包)”的括號注釋。同樣,所有這些事實(可能還有更多)都會以一個包含12288個數字列表的形式編碼,這些數字對應于詞John。或者,該故事中的某些信息可能會編碼在12288維的向量中,用于謝麗爾、唐納德、博伊西、錢包或其他詞。
這樣做的目標是,讓網絡的第96層和最后一層輸出一個包含所有必要信息的隱藏狀態,以預測下一個單詞。
4
注意力機制
現在讓我們談談每個Transformer內部發生的情況。Transformer在更新輸入段落的每個單詞的隱藏狀態時有兩個處理過程:
1. 在注意力步驟中,詞匯會“觀察周圍”以查找具有相關背景并彼此共享信息的其他詞。
2. 在前饋步驟中,每個詞會“思考”之前注意力步驟中收集到的信息,并嘗試預測下一個單詞。
當然,執行這些步驟的是網絡,而不是個別的單詞。但我們用這種方式表述是為了強調Transformer是以單詞作為這一分析的基本單元,而不是整個句子或段落。這種方法使得LLM能夠充分利用現代GPU芯片的大規模并行處理能力。它還幫助LLM擴展到包含成千上萬個詞的長段落。而這兩個方面都是早期語言模型面臨的挑戰。
你可以將注意力機制看作是單詞之間的一個撮合服務。每個單詞都會制作一個檢查表(稱為查詢向量),描述它尋找的詞的特征。每個詞還會制作一個檢查表(稱為關鍵向量),描述它自己的特征。神經網絡通過將每個關鍵向量與每個查詢向量進行比較(通過計算點積)來找到最佳匹配的單詞。一旦找到匹配項,它將從產生關鍵向量的單詞傳遞相關信息到產生查詢向量的單詞。
例如,在前面的部分中,我們展示了一個假設的Transformer模型,它發現在部分句子“John wants his bank to cash the”中,“his(他的)”指的是“John(約翰)”。在系統內部,過程可能是這樣的:“his”的查詢向量可能會有效地表示為“我正在尋找:描述男性的名詞”。“John”的關鍵向量可能會有效地表示為“我是一個描述男性的名詞”。網絡會檢測到這兩個向量匹配,并將關于"John"的向量信息轉移給“his”的向量。
每個注意力層都有幾個“注意力頭”,這意味著,這個信息交換過程在每一層上會多次進行(并行)。每個注意頭都專注于不同的任務:
? 一個注意頭可能會將代詞與名詞進行匹配,就像我們之前討論的那樣。
? 另一個注意頭可能會處理解析類似"bank"這樣的一詞多義的含義。
? 第三個注意力頭可能會將“Joe Biden”這樣的兩個單詞短語鏈接在一起。
諸如此類的注意力頭經常按順序操作,一個注意力層中的注意力操作結果成為下一層中一個注意力頭的輸入。事實上,我們剛才列舉的每個任務可能都需要多個注意力頭,而不僅僅是一個。
GPT-3的最大版本有96個層,每個層有96個注意力頭,因此,每次預測一個新詞時,GPT-3將執行9216個注意力操作。
5
一個真實世界的例子
在上述兩節內容中,我們展示了注意力頭的工作方式的理想化版本。現在讓我們來看一下關于真實語言模型內部運作的研究。
去年,研究人員在Redwood Research研究了GPT-2,即ChatGPT的前身,對于段落“When Mary and John went to the store, John gave a drink to(當瑪麗和約翰去商店,約翰把一杯飲料給了)”預測下一個單詞的過程。
GPT-2預測下一個單詞是Mary(瑪麗)。研究人員發現有三種類型的注意力頭對這個預測做出了貢獻:
? 他們稱之為名稱移動頭(Name Mover Head)的三個注意力頭將信息從Mary向量復制到最后的輸入向量(to這個詞對應的向量)。GPT-2使用此最右向量中的信息來預測下一個單詞。
? 神經網絡是如何決定Mary是正確的復制詞?通過GPT-2的計算過程進行逆向推導,科學家們發現了一組他們稱之為主語抑制頭(Subject Inhibition Head)的四個注意頭,它們標記了第二個John向量,阻止名稱移動頭復制John這個名字。
? 主語抑制頭是如何知道不應該復制John?團隊進一步向后推導,發現了他們稱為重復標記頭(Duplicate Token Heads)的兩個注意力頭。他們將第二個John向量標記為第一個John向量的重復副本,這幫助主語抑制頭決定不應該復制John。
簡而言之,這九個注意力頭使得GPT-2能夠理解“John gave a drink to John(約翰給了約翰一杯飲料”沒有意義,而是選擇了“John gave a drink to Mary(約翰給了瑪麗一杯飲料)”。
這個例子側面說明了要完全理解LLM會有多么困難。由五位研究人員組成的Redwood團隊曾發表了一篇25頁的論文,解釋了他們是如何識別和驗證這些注意力頭。然而,即使他們完成了所有這些工作,我們離對于為什么GPT-2決定預測“Mary”作為下一個單詞的全面解釋還有很長的路要走。
例如,模型是如何知道下一個單詞應該是某個人的名字而不是其他類型的單詞?很容易想到,在類似的句子中,Mary不會是一個好的下一個預測詞。例如,在句子“when Mary and John went to the restaurant, John gave his keys to(當瑪麗和約翰去餐廳時,約翰把鑰匙給了)”中,邏輯上,下一個詞應該是“the valet(代客停車員)”。
假設計算機科學家們進行充足的研究,他們可以揭示和解釋GPT-2推理過程中的其他步驟。最終,他們可能能夠全面理解GPT-2是如何決定“Mary”是該句子最可能的下一個單詞。但這可能需要數月甚至數年的額外努力才能理解一個單詞的預測情況。
ChatGPT背后的語言模型——GPT-3和GPT-4——比GPT-2更龐大和復雜,相比Redwood團隊研究的簡單句子,它們能夠完成更復雜的推理任務。因此,完全解釋這些系統的工作將是一個巨大的項目,人類不太可能在短時間內完成。
6
前饋步驟
在注意力頭在詞向量之間傳輸信息后,前饋網絡會“思考”每個詞向量并嘗試預測下一個詞。在這個階段,單詞之間沒有交換信息,前饋層會獨立地分析每個單詞。然而,前饋層可以訪問之前由注意力頭復制的任何信息。以下是GPT-3最大版本的前饋層結構。
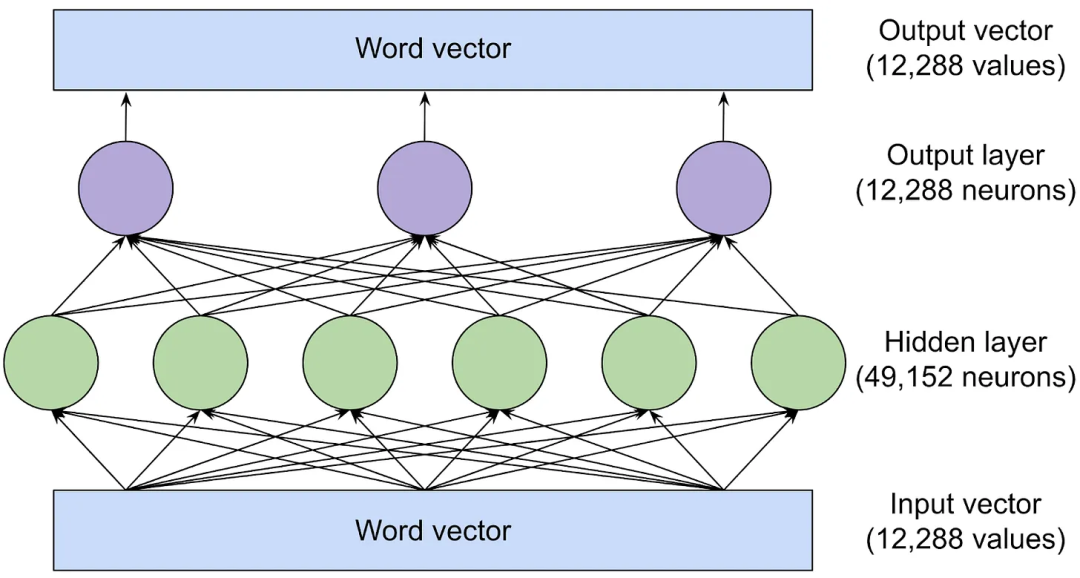
綠色和紫色的圓圈表示神經元:它們是計算其輸入加權和的數學函數。
前饋層之所以強大,是因為它有大量的連接。我們使用三個神經元作為輸出層,六個神經元作為隱藏層來繪制這個網絡,但是GPT-3的前饋層要大得多:輸出層有12288個神經元(對應模型的12288維詞向量),隱藏層有49152個神經元。
所以在最大版本的GPT-3中,隱藏層有49152個神經元,每個神經元有12288個輸入值(因此每個神經元有12288個權重參數),并且還有12288輸出神經元,每個神經元有49152個輸入值(因此每個神經元有49152個權重參數)。這意味著,每個前饋層有49152*12288+12288*49152=12億個權重參數。并且有96個前饋層,總共有12億*96=1160億個參數!這相當于具有1750億參數的GPT-3近三分之二的參數量。
來自特拉維夫大學的研究人員發現,前饋層通過模式匹配進行工作:隱藏層中的每個神經元都能匹配輸入文本中的特定模式。下面是一個16層版本的GPT-2中的一些神經元匹配的模式:
? 第1層的神經元匹配以“substitutes”結尾的詞序列。
? 第6層的神經元匹配與軍事有關并以“base”或“bases”結尾的詞序列。
? 第13層的神經元匹配以時間范圍結尾的序列,比如“在下午3點到7點之間”或者“從周五晚上7點到”。
? 第16層的神經元匹配與電視節目相關的序列,例如“原始的NBC日間版本,已存檔”或者“時間延遲使該集的觀眾增加了57%。”
正如你所看到的,在后面的層中,模式變得更抽象。早期的層傾向于匹配特定的單詞,而后期的層則匹配屬于更廣泛語義類別的短語,例如電視節目或時間間隔。
這很有趣,因為如前所述,前饋層每次只能檢查一個單詞。因此,當將序列“原始的NBC日間版本,已存檔”分類為“與電視相關”時,它只能訪問“已存檔”這個詞的向量,而不是NBC或日間等詞匯。可以推斷,前饋層之所以可以判斷“已存檔”是電視相關序列的一部分,是因為注意力頭先前將上下文信息移到了“已存檔”的向量中。
當一個神經元與其中一個模式匹配時,它會向詞向量中添加信息。雖然這些信息并不總是容易解釋,但在許多情況下,你可以將其視為對下一個詞的臨時預測。
7
使用向量運算進行前饋網絡的推理
布朗大學最近的研究展示了前饋層如何幫助預測下一個單詞的優雅例子。我們之前討論過Google的word2vec研究,顯示可以使用向量運算進行類比推理。例如,柏林-德國+法國=巴黎。
布朗大學的研究人員發現,前饋層有時使用這種準確的方法來預測下一個單詞。例如,他們研究了GPT-2對以下提示的回應:“問題:法國的首都是什么?回答:巴黎。問題:波蘭的首都是什么?回答:”
團隊研究了一個包含24個層的GPT-2版本。在每個層之后,布朗大學的科學家們探測模型,觀察它對下一個詞元(token)的最佳猜測。在前15層,最高可能性的猜測是一個看似隨機的單詞。在第16層和第19層之間,模型開始預測下一個單詞是波蘭——不正確,但越來越接近正確。然后在第20層,最高可能性的猜測變為華沙——正確的答案,并在最后四層保持不變。
布朗大學的研究人員發現,第20個前饋層通過添加一個將國家向量映射到其對應首都的向量,從而將波蘭轉換為華沙。將相同的向量添加到中國時,答案會得到北京。
同一模型中的前饋層使用向量運算將小寫單詞轉換為大寫單詞,并將現在時的單詞轉換為過去時的等效詞。
8
注意力層和前饋層有不同的功能
到目前為止,我們已經看到了GPT-2單詞預測的兩個實際示例:注意力頭幫助預測約翰給瑪麗一杯飲料;前饋層幫助預測華沙是波蘭的首都。
在第一個案例中,瑪麗來自用戶提供的提示。但在第二個案例中,華沙并沒有出現在提示中。相反,GPT-2必須“記住”華沙是波蘭的首都,這個信息是從訓練數據中學到的。
當布朗大學的研究人員禁用將波蘭轉換為華沙的前饋層時,模型不再預測下一個詞是華沙。但有趣的是,如果他們接著在提示的開頭加上句子“波蘭的首都是華沙”,那么GPT-2就能再次回答這個問題。這可能是因為GPT-2使用注意力機制從提示中提取了華沙這個名字。
這種分工更廣泛地表現為:注意力機制從提示的較早部分檢索信息,而前饋層使語言模型能夠“記住”未在提示中出現的信息。
事實上,可以將前饋層視為模型從訓練數據中學到的信息的數據庫。靠前的前饋層更可能編碼與特定單詞相關的簡單事實,例如“特朗普經常在唐納德之后出現”。靠后的層則編碼更復雜的關系,如“添加這個向量以將一個國家轉換為其首都。
9
語言模型的訓練方式
許多早期的機器學習算法需要人工標記的訓練示例。例如,訓練數據可能是帶有人工標簽(“狗”或“貓”)的狗或貓的照片。需要標記數據的需求,使得人們創建足夠大的數據集以訓練強大模型變得困難且昂貴。
LLM的一個關鍵創新之處在于,它們不需要顯式標記的數據。相反,它們通過嘗試預測文本段落中下一個單詞來學習。幾乎任何書面材料都適用于訓練這些模型——從維基百科頁面到新聞文章再到計算機代碼。
舉例來說,LLM可能會得到輸入“I like my coffee with cream and(我喜歡在咖啡里加奶油和)”,并試圖預測“sugar(糖)”作為下一個單詞。一個新的初始化語言模型在這方面表現很糟糕,因為它的每個權重參數——GPT-3最強大的版本高達1750億個參數——最初基本上都是從一個隨機數字開始。
但是隨著模型看到更多的例子——數千億個單詞——這些權重逐漸調整以做出更好的預測。
下面用一個類比來說明這個過程是如何進行的。假設你要洗澡,希望水溫剛剛好:不太熱,也不太冷。你以前從未用過這個水龍頭,所以你隨意調整水龍頭把手的方向,并觸摸水的溫度。如果太熱或太冷,你會向相反的方向轉動把手,當接近適當的水溫時,你對把手所做的調整幅度就越小。
現在,讓我們對這個類比做幾個改動。首先,想象一下有50257個水龍頭,每個水龍頭對應一個不同的單詞,比如"the"、"cat"或"bank"。你的目標是,只讓與序列中下一個單詞相對應的水龍頭里出水。
其次,水龍頭后面有一堆互聯的管道,并且這些管道上還有一堆閥門。所以如果水從錯誤的水龍頭里出來,你不能只調整水龍頭上的旋鈕。你要派遣一支聰明的松鼠部隊去追蹤每條管道,并沿途調整它們找到的每個閥門。
這變得很復雜,由于同一條管道通常供應多個水龍頭,所以需要仔細思考如何確定要擰緊和松開哪些閥門,以及程度多大。
顯然,如果字面理解這個例子,就變得很荒謬。建立一個擁有1750億個閥門的管道網絡既不現實也沒用。但是由于摩爾定律,計算機可以并且確實以這種規模運行。
截止目前,在本文中所討論的LLM的所有部分——前饋層的神經元和在單詞之間傳遞上下文信息的注意力頭——都被實現為一系列簡單的數學函數(主要是矩陣乘法),其行為由可調整的權重參數來確定。就像我故事中的松鼠松緊閥門來控制水流一樣,訓練算法通過增加或減小語言模型的權重參數來控制信息在神經網絡中的流動。
訓練過程分為兩個步驟。首先進行“前向傳播(forward pass)”,打開水源并檢查水是否從正確的水龍頭流出。然后關閉水源,進行“反向傳播(backwards pass)”,松鼠們沿著每根管道競速,擰緊或松開閥門。在數字神經網絡中,松鼠的角色由一個稱為反向傳播的算法來扮演,該算法“逆向(walks backwards)”通過網絡,使用微積分來估計需要改變每個權重參數的程度。
完成這個過程——對一個示例進行前向傳播,然后進行后向傳播來提高網絡在該示例上的性能——需要進行數百億次數學運算。而像GPT-3這種大模型的訓練需要重復這個過程數十億次——對每個訓練數據的每個詞都要進行訓練。OpenAI估計,訓練GPT-3需要超過3000億萬億次浮點計算——這需要幾十個高端計算機芯片運行數月。
10
GPT-3的驚人性能
你可能會對訓練過程能夠如此出色地工作感到驚訝。ChatGPT可以執行各種復雜的任務——撰寫文章、進行類比和甚至編寫計算機代碼。那么,這樣一個簡單的學習機制是如何產生如此強大的模型?
一個原因是規模。很難過于強調像GPT-3這樣的模型看到的示例數量之多。GPT-3是在大約5000億個單詞的語料庫上進行訓練的。相比之下,一個普通的人類孩子在10歲之前遇到的單詞數量大約是1億個。
在過去的五年中,OpenAI不斷增大其語言模型的規模。在一篇廣為傳閱的2020年論文中OpenAI報告稱,他們的語言模型的準確性與模型規模、數據集規模以及用于訓練的計算量呈冪律關系,一些趨勢甚至跨越七個數量級以上”。
模型規模越大,在涉及語言的任務上表現得越好。但前提是,他們需要以類似的倍數增加訓練數據量。而要在更多數據上訓練更大的模型,還需要更多的算力。
2018年,OpenAI發布了第一個大模型GPT-1于。它使用了768維的詞向量,共有12層,總共有1.17億個參數。幾個月后,OpenAI發布了GPT-2,其最大版本擁有1600維的詞向量,48層,總共有15億個參數。2020年,OpenAI發布了GPT-3,它具有12288維的詞向量,96層,總共有1750億個參數。
今年,OpenAI發布了GPT-4。該公司尚未公布任何架構細節,但業內普遍認為,GPT-4比GPT-3要大得多。
每個模型不僅學到了比其較小的前身模型更多的事實,而且在需要某種形式的抽象推理任務上表現出更好的性能。
例如,設想以下故事:一個裝滿爆米花的袋子。袋子里沒有巧克力。然而,袋子上的標簽寫著“巧克力”而不是“爆米花”。山姆發現了這個袋子。她以前從未見過這個袋子。她看不見袋子里面的東西。她讀了標簽。
你可能猜到,山姆相信袋子里裝著巧克力,并會驚訝地發現里面是爆米花。
心理學家將這種推理他人思維狀態的能力研究稱為“心智理論(Theory of Mind)”。大多數人從上小學開始就具備這種能力。專家們對于任何非人類動物(例如黑猩猩)是否適用心智理論存在分歧,但基本共識是,它對人類社會認知至關重要。
今年早些時候,斯坦福大學心理學家米Michal Kosinski發表了一項研究,研究了LLM的能力以解決心智理論任務。他給各種語言模型閱讀類似剛剛引述的故事,然后要求它們完成一個句子,比如“她相信袋子里裝滿了”,正確答案是“巧克力”,但一個不成熟的語言模型可能會說“爆米花”或其他東西。
GPT-1和GPT-2在這個測試中失敗了。但是在2020年發布的GPT-3的第一個版本正確率達到了近40%,Kosinski將模型性能水平與三歲兒童相比較。去年11月發布的最新版本GPT-3將上述問題的正確率提高到了約90%,與七歲兒童相當。GPT-4對心智理論問題的回答正確率約為95%。
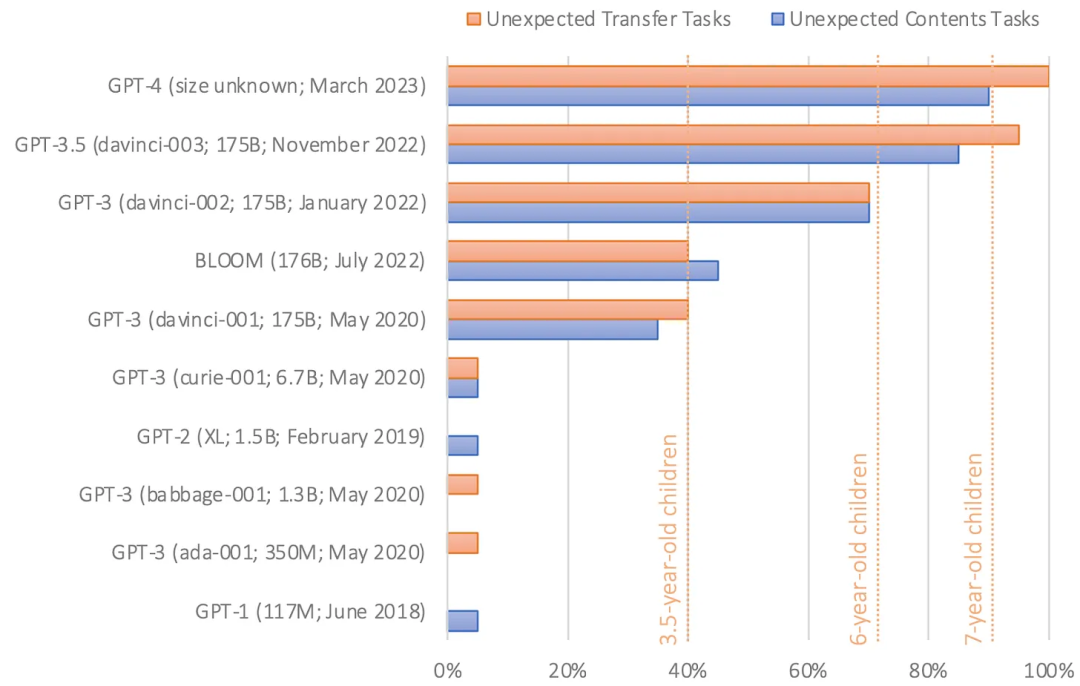
“鑒于這些模型中既沒有跡象表明ToM(心智化能力)被有意設計進去,也沒有研究證明科學家們知道如何實現它,這一能力很可能是自發且自主地出現的。這是模型的語言能力不斷增強的一個副產品。"Kosinski寫道。
值得注意的是,研究人員并不全都認可這些結果證明了心智理論:例如,對錯誤信念任務的微小更改導致GPT-3的性能大大下降;而GPT-3在測量心智理論的其他任務中的表現更為不穩定,正如其中肖恩所寫的那樣,成功的表現可能歸因于任務中的混淆因素——一種“聰明漢斯(clever Hans,指一匹名為漢斯的馬看似能完成一些簡單的智力任務,但實際上只是依賴于人們給出的無意識線索)”效應,只不過是出現在了語言模型上而不是馬身上。
盡管如此,GPT-3在幾個旨在衡量心智理論的任務上接近人類的表現,這在幾年前是無法想象的,并且這與更大的模型通常在需要高級推理的任務中表現更好的觀點相一致。
這只是語言模型表現出自發發展出高級推理能力的眾多例子之一。今年4月,微軟的研究人員發表的一篇論文表示,GPT-4展示了通用人工智能的初步、誘人的跡象——即以一種復雜、類人的方式思考的能力。
例如,一位研究人員要求GPT-4使用一種名為TiKZ的晦澀圖形編程語言畫一只獨角獸。GPT-4回應了幾行代碼,然后研究人員將這些代碼輸入TiKZ軟件。生成的圖像雖然粗糙,但清晰地顯示出GPT-4對獨角獸的外觀有一定的理解。

研究人員認為,GPT-4可能以某種方式從訓練數據中記住了繪制獨角獸的代碼,所以他們給它提出了一個后續的挑戰:他們修改了獨角獸的代碼,移除了頭角,并移動了一些其他身體部位。然后他們讓GPT-4把獨角獸的頭角放回去。GPT-4通過將頭角放在正確的位置上作出了回應:

盡管作者的測試版本的訓練數據完全基于文本,沒有包含任何圖像,但GPT-4似乎仍然能夠完成這個任務。不過,通過大量的書面文本訓練后,GPT-4顯然學會了推理關于獨角獸身體形狀的知識。
目前,我們對LLM如何完成這樣的壯舉沒有真正的了解。有些人認為,像這樣的例子表明模型開始真正理解其訓練集中詞的含義。其他人堅持認為,語言模型只是“隨機鸚鵡”,僅僅是重復越來越復雜的單詞序列,而并非真正理解它們。
這種辯論指向了一種深刻的哲學爭論,可能無法解決。盡管如此,我們認為關注GPT-3等模型的經驗表現很重要。如果一個語言模型能夠在特定類型的問題中始終得到正確答案,并且研究人員有信心排除混淆因素(例如,確保在訓練期間該語言模型沒有接觸到這些問題),那無論它對語言的理解方式是否與人類完全相同,這都是一個有趣且重要的結果。
訓練下一個詞元預測如此有效的另一個可能原因是,語言本身是可預測的。語言的規律性通常(盡管并不總是這樣)與物質世界的規律性相聯系。因此,當語言模型學習單詞之間的關系時,通常也在隱含地學習這個世界存在的關系。
此外,預測可能是生物智能以及人工智能的基礎。根據Andy Clark等哲學家的觀點 ,人腦可以被認為是一個“預測機器”,其主要任務是對我們的環境進行預測,然后利用這些預測來成功地駕馭環境。預測對于生物智能和人工智能都至關重要。直觀地說,好的預測離不開良好的表示——準確的地圖比錯誤的地圖更有可能幫助人們更好地導航。世界是廣闊而復雜的,進行預測有助于生物高效定位和適應這種復雜性。
在構建語言模型方面,傳統上一個重大的挑戰是,找出最有用的表示不同單詞的方式,特別是因為許多單詞的含義很大程度上取決于上下文。下一個詞的預測方法使研究人員能夠將其轉化為一個經驗性問題,以此避開這個棘手的理論難題。
事實證明,如果我們提供足夠的數據和計算能力,語言模型能夠通過找出最佳的下一個詞的預測來學習人類語言的運作方式。不足之處在于,最終得到的系統內部運作方式人類還并不能完全理解。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
機器學習
+關注
關注
66文章
8408瀏覽量
132568 -
GPT
+關注
關注
0文章
353瀏覽量
15344 -
ChatGPT
+關注
關注
29文章
1560瀏覽量
7597 -
LLM
+關注
關注
0文章
286瀏覽量
327
原文標題:通俗解構語言大模型的工作原理
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論