") 基于Mediatek AIoT Genio1200 的即時影像物件識別方案
基于Mediatek AIoT Genio1200 的即時影像物件識別方案
在MediaTek AIoT Genio1200平臺上,MediaTek 提供許多不同的軟件解決方案,伙伴們可通過CPU、GPU和APU來提供 AI 計算能力。在開發(fā)和部署廣泛的機(jī)器學(xué)習(xí)時,決大部分會為了推演自行開發(fā)出的模型,來提供硬件加速功能,伙伴們也可通過圖形處理器來啟用 TensorFlot Lite模型的硬件加速。
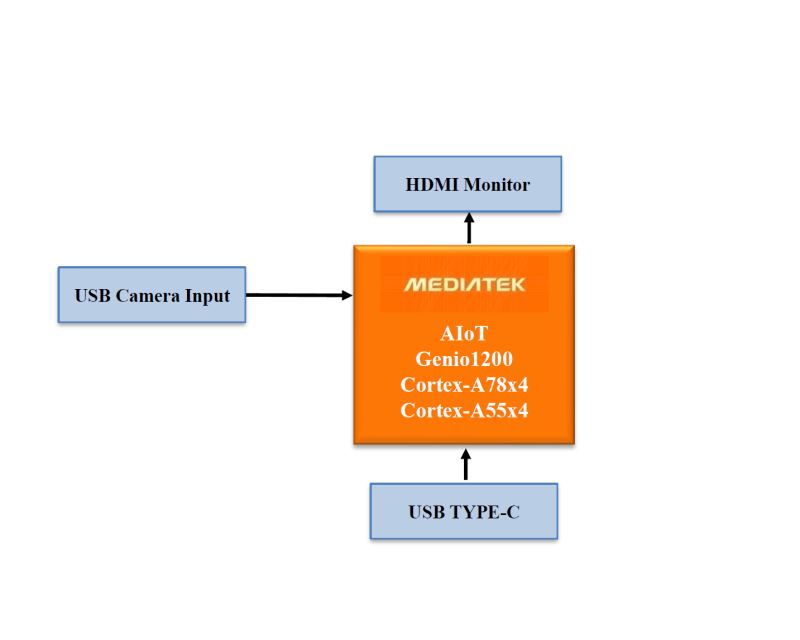
MediaTek AIoT Genio1200 board:

以MTK AIoT Yocto而言,目前已知下列三種方式(CPU、GPU和APU)
第一種是 ARM NN,是一組開源軟件,可在 ARM 的硬件設(shè)備上實現(xiàn)機(jī)器學(xué)習(xí)工作,它在目前常見的神經(jīng)網(wǎng)路框架 Cortex-A CPU、ARM Mali GPU 之間橋接,透過 CPU 來運算和推演模型。
第二種是GPU Neural Network Acceleration,它使用的是設(shè)備上的 OpenGL ES(OpenGL for Embedded Systems)計算著色器來推演模型。
第三種是 APU Neural Network Acceleration(MediaTek Deep Learning Accelerator and Vision Processing Unit)。
讓小弟來為各位伙伴們介紹 MediaTek 專有的深度學(xué)習(xí)加速器,它是一款功能強(qiáng)大且高效的卷積神經(jīng)網(wǎng)路(Convolutional Neural Network)加速器,MDLA能夠以高乘法累加(Multiply-Accumulate utilization, MAC)利用率實現(xiàn)高 AI 基準(zhǔn)測試結(jié)果,此設(shè)計將 MAC單元與存用功能模塊集成在一起。
在開始演練之前,各位伙伴們是否還記得什么是 MediaTek NeuroPilot 呢?忘記的伙伴們,可以回過頭去了解 淺談MediaTek NeuroPilot
NeuroPilot是聯(lián)發(fā)科AI 生態(tài)系統(tǒng)的核心。伙伴們可介由NeuroPilot在邊緣設(shè)備上,以極高的效率開發(fā)和部署 AI 應(yīng)用程序。這使得各種各樣的人工智能應(yīng)用程序運行得更快。伙伴們?nèi)蘸罂梢栽?NeuroPilot SDK內(nèi),使用 Neuron編譯器( ncc-tflite),用于將 TFLite 模型轉(zhuǎn)換為MediaTek 專有的二進(jìn)制文件 (DLA, 深度學(xué)習(xí)存檔),以便在 Genio1200 平臺上部署。生成的模型非常高效,延遲減少,內(nèi)存占用更少。 Neuron SDK 還提供了 Neuron Run-time API,它提供了一組 API,可以讓伙伴們從 C/C++ 程序中調(diào)用這些 API,以創(chuàng)建運行時的環(huán)境,解析編譯的模型文件,并執(zhí)行設(shè)備上的神經(jīng)網(wǎng)路推理。

由圖示可以知道,DLA檔是 MediaTek專有模型,它是 MDLA(MediaTek Deep Learning Accelerator) 和 VPU(Vision processing unit )計算設(shè)備的 low-level binary 檔案。使用 ncc-tflite 將 TensorFlow lite 模型轉(zhuǎn)換成可在 APU 上推演的 DLA文件,再供給圖像/物件識別的應(yīng)用程序使用。
使用預(yù)先寫好的腳本來將 TensorFlow Lite模型轉(zhuǎn)換成 DLA 文檔,信息如下:
root@i1200-demo:~# lsconvert_tensorflowLite_to_DLA.sh demos test.tfliteroot@i1200-demo:~# ./convert_tensorflowLite_to_DLA.sh[apusys][info]apusysSession: Seesion(0xaaaae26f9910): thd(ncc-tflite) version(2) log(0)root@i1200-demo:~# lsconvert_tensorflowLite_to_DLA.sh demos test.dla test.tfliteroot@i1200-demo:~#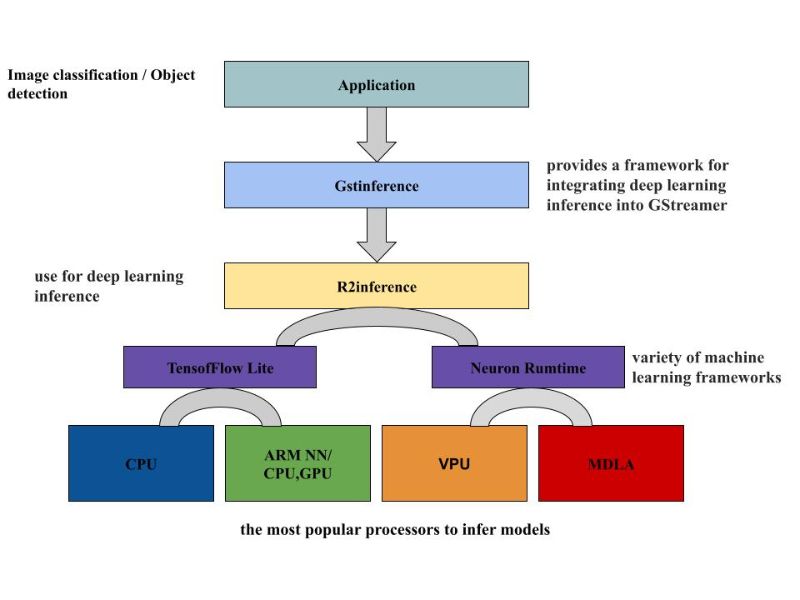
如圖所示,GstInference 是個開源項目,它提供了一個將深度學(xué)習(xí)推理整合到 GStreamer 中的框架。可用于眾多的深度學(xué)習(xí)架構(gòu)進(jìn)行推理,也可搭配實用的程序來支持自定義的架構(gòu)。此框架使用 R2Inference,這是 C/C++ 中的一個抽象層,用于各種機(jī)器學(xué)習(xí)框架。單一個 C/C++ 應(yīng)用程序就可以借助 R2Inference來使用不同框架上的模型。這對于利用不同的硬件執(zhí)行推理時非常有用 (CPU、GPU、APU的加速器)。本次的演練是基于圖中的框架來實現(xiàn)即時影像識別的應(yīng)用,將剛才轉(zhuǎn)換好的 DLA文檔來執(zhí)行于圖像識別的推演。
接下來執(zhí)行預(yù)先配置好的腳位來實現(xiàn)圖像和物件識別的演練。
root@i1200-demo:~# lsconvert_tensorflowLite_to_DLA.sh labels_objectD.txt test2.dlademos objectD.dla test2.tfliteimage_classification.sh object_detection.shlabels.txt test.tfliteroot@i1200-demo:~# ./image_classification.sh
執(zhí)行結(jié)果將會顯示于 HDMI 屏上,可以看到所推演出的物件為 ballpoint pen

繼續(xù)執(zhí)行物件識別的演示。
root@i1200-demo:~# lsconvert_tensorflowLite_to_DLA.sh labels_objectD.txt test2.dlademos objectD.dla test2.tfliteimage_classification.sh object_detection.shlabels.txt test.tfliteroot@i1200-demo:~# ./object_detection.sh
推演的結(jié)果,可以看到識別為 bottle

推演的結(jié)果可以看到識別為 monitor

推演的結(jié)果可以,可以看到識別為 chair

本次的演示就到此,有興趣的伙伴們可以一起來討論和研究,謝謝大家!
?場景應(yīng)用圖
?展示板照片

?方案方塊圖
?核心技術(shù)優(yōu)勢
雙核AI處理器單元(APU) 可處理基于 AI 的任務(wù),支持深度學(xué)習(xí)(Deep Learning)、神經(jīng)網(wǎng)絡(luò)(Neural Network)加速和計算機(jī)視覺(computer vision)應(yīng)用。
?方案規(guī)格
CPU: Arm Cortex-A78 x4 Arm Cortex-A55 x4
GPU: Arm Mali-G57 MP5
APU: MediaTek AI Processor (dual core)
Video processing: Video encoding 4K60fps HEVC/H.264 Video decoding 4K90fps AV1/VP9/HEVC/H.264
Software: Android/Yocto Linux/Ubuntu/NeuroPilot SDK
Interface: HDMI 2.0 receiver (HDMI RX) PCIE3.0 USB3.1 GbE MAC ISP, 48MP@30fps/16MP+16MP@30fps
-
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268886 -
AIoT
+關(guān)注
關(guān)注
8文章
1406瀏覽量
30650
發(fā)布評論請先 登錄
相關(guān)推薦
鴻蒙案例技術(shù)分享 | 基于AIoT-3568X的鴻蒙通行一體機(jī)方案項目
大聯(lián)大推出基于MediaTek Genio 130與ChatGPT的AI語音助理方案
即時通話軟件音頻傳輸質(zhì)量測試方案
東軟發(fā)布新一代醫(yī)學(xué)影像解決方案
杭州國芯微AIoT產(chǎn)品系列及方案列表
MediaTek天璣旗艦芯賦能下的影像魅力
AIOT是什么意思?AIOT的應(yīng)用場景和作用


MediaTek NeuroPilot SDK整合NVIDIATAO
MediaTek與美團(tuán)攜手合作打造新一代餐飲系統(tǒng)硬件S4 Pro系列收銀機(jī)
瑞莎科技發(fā)布NIO 12L開發(fā)板,搭載聯(lián)發(fā)科Genio 1200處理器
MediaTek天璣9300旗艦芯亮相UDE 2024
MediaTek商用顯示解決方案亮相UDE 2024
提速互聯(lián) 智向未來 | 廣和通AIoT模組及解決方案驚艷MWC 2024

研華科技與瞰瞰智能達(dá)成戰(zhàn)略合作,共同深化“AIoT+影像”應(yīng)用助力產(chǎn)業(yè)升級






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論