 基于時空圖概率模型的不確定性衡量介紹
基于時空圖概率模型的不確定性衡量介紹
引言
時空數據是復雜而又多樣化的數據,分析時空數據能為人類天氣預測(如華為盤古大模型)、地質起伏預測、太陽黑子預測、紅綠燈優化調度、共享單車投放規劃等方面帶來重大影響。然而時空數據又是復雜的,體現在其數據的時空變換和空間異質,而其數據分布也極其極端 -- 存在大量的零值,以及數據體現長尾分布。
今天要介紹的便是通過引入Tweedie分布和Zero-inflated負二項分布去捕捉零膨脹效應和長尾效應的復雜時空數據,結合時空圖神經網絡,來衡量預測的不確定性。
01
介紹
1.1
不確定性衡量
想象一下,當我們踏入人工智能這片廣袤領域,仿佛邁入一片神秘森林,其中充滿了機器智能和前沿科技的奧秘。在這充滿活力的領域中,存在一個至關重要的概念,需要我們一同深入探索,那便是不確定性衡量。或許你正在引導一臺智能計算機學會識別各種動物,像是讓它分辨狗、貓、大象等。但是,當它面對一張全新的動物圖片時,需要做的不僅是做出判斷,還有告訴我們它對自己的判斷有多有信心,這個信心便是——不確定性。
這個過程引發了一個有趣的問題:在計算機模型做出預測時,如何讓我們知道它有多確信這個預測是準確的呢?這涉及到一個核心概念,即模型的不確定性。模型的不確定性涉及它在進行預測時可能出現錯誤或產生不確定結果的程度。這種不確定性可能來源于兩個方面,一個是模型接觸到的數據有限,另一個是模型自身的復雜性導致它無法始終做出準確預測。
首先,我們來考慮模型所面臨的數據不確定性。就如同當你只看過幾張貓和狗的照片后,被要求辨認一種你從未見過的奇特動物一樣,模型也可能在面對全新、未曾接觸過的數據時感到困惑。畢竟,模型所了解的知識來自于它在訓練時接觸到的數據,它難以直接將這些知識應用于陌生情境。這就好比你只見過黑色和白色的狗,突然間面對一只藍色的狗,你也會感到困惑吧?
其次,還有模型本身的不確定性,也就是模型的局限性。假設你要教計算機區分貓和狗,你指示它關注尾巴的長度、耳朵的形狀等特征。但是,如果你給它一張模糊的圖片,它可能無法精確判斷。因為模型并不能像人類一樣從模糊的線索中推斷出合理結論,它可能因為信息不足而做出錯誤預測。
為了克服這些不確定性,研究者們提出了一些方法,使我們能更好地理解模型的預測。例如,模型可以輸出一個預測的置信度,就好像是它告訴你“我對這個預測很有信心”或者“我對這個預測不太確定”。另一種方法是,模型可以輸出一個預測的分布,顯示每個可能結果的概率。這種方法類似于擲骰子,你了解每個面的概率,從而更好地預測結果。
通過這些方法,我們可以更清晰地理解模型預測時的不確定性,就像是在未知的森林中多了一張地圖,幫助我們更自信地踏出每一步。這一概念在醫學、交通、金融等領域都有廣泛應用,讓我們能更明智地利用模型的預測,做出更可靠的決策。
1.2
時空圖神經網絡
Spatial-Temporal Graph Neural Network
時空圖神經網絡是近年來在深度學習領域異軍突起的一項強大工具,為我們理解和處理涉及時空關系的數據開辟了嶄新視角。比方說,我們想分析城市中的交通流量變化,或者預測未來氣象的演變,這些任務涉及到時間和空間的錯綜復雜聯系。時空圖神經網絡就如同一把鑰匙,為我們敞開了探索時空數據的大門。
首先,我們來解釋一下時空數據是什么。時空數據包括了時間和空間信息,比如在不同時間和地點的溫度、交通流量、人口分布等。而時空圖則是一種用來展示時空數據中關系和相互作用的圖結構。在這個圖中,節點代表不同的地點或物體,邊代表它們之間的關聯。
時空圖神經網絡是專為處理時空圖數據而設計的深度學習模型。它結合了圖神經網絡和時間序列預測的思想,能夠幫助我們從復雜的時空數據中提取有價值的信息。這些網絡可以捕捉地點之間的關系,同時也能追蹤隨時間變化的模式,這樣我們就能更準確地預測未來、分析趨勢,甚至優化決策。
舉個例子來說,想象一個城市的交通系統。每個路口可以被視為一個節點,而車輛在不同時刻穿越這些路口則形成了邊。時空圖神經網絡可以學習交通流量在不同路口、不同時間之間的變化規律,這有助于城市規劃者更好地優化交通流動,減少擁堵。
這種網絡結構在很多領域都有廣泛應用。在氣象學中,時空圖神經網絡可以分析全球各地的氣象數據,幫助氣象學家更精準地預測氣候變化。在醫療領域,它可以處理醫療設備產生的時空數據,用于疾病預測和診斷。在金融領域,它可以分析不同市場之間的關系,幫助投資者做出更明智的決策。
1.3
概率模型
在數據分析的舞臺上,我們時常會面對一些特殊情況,這些情況使得傳統統計方法不再足夠。其中兩種常見情形分別是長尾數據和零膨脹數據。這些數據背后隱藏著復雜的分布特征,傳統統計模型可能難以妥善應對。而此時,概率模型如 Zero-inflated負二項分布 和 Tweedie分布 就發揮了關鍵作用。
長尾數據意味著數據分布中存在著許多數值較小但數量龐大的極端值,這些值往往對模型產生重大影響。比如,分析社交媒體上的點贊數或銷售數據中的銷售量時,傳統的均值和方差等統計量可能無法完全揭示分布的特性。
零膨脹數據則是數據中零值的數量遠超預期的情況。舉例而言,當我們分析醫療保險索賠數據時,大部分人可能沒有提出索賠,導致數據中有大量的零值。然而,傳統模型可能因為其假設與實際情況不符而表現不佳。
長尾和零膨脹效應在時空數據上體現極為明顯,以 O-D flows數據(任意兩地在任意事件的車流量值)為例:

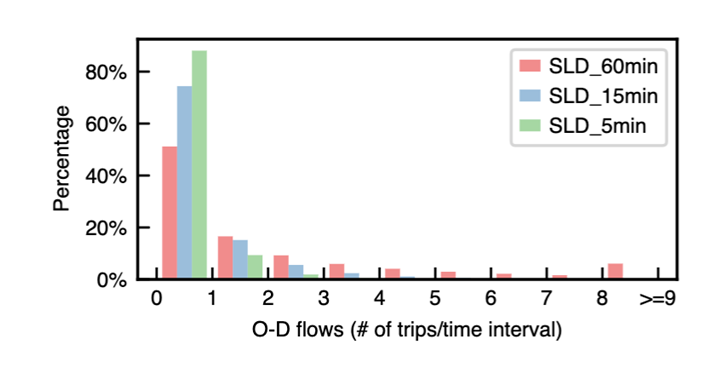
可以看到在SLD_60min, SLD_15min, SLD_5min這三個數據集上,零值幾乎占據了大多數,而大于2的情況所占比例非常少,又明顯體現了“長尾”的特點。
為了更好地解決這些問題,Zero-inflated負二項分布 和 Tweedie分布應運而生。
Zero-inflated 負二項分布可以看作是兩種分布的結合體:負二項分布(用于計數數據的離散分布)和零膨脹分布(用于描述數據中零值較多的情況)。這種分布適用于數據中不僅存在大量零值,還可能出現較大值的情形。利用這個模型,我們能夠更精確地捕捉數據分布的特點,從而更好地進行預測和分析。
Tweedie 分布則屬于廣義線性模型中的概率分布,適用于處理長尾數據和零膨脹數據。其特點之一是廣泛適用范圍,能夠應對連續數據、離散數據、混合數據等多種情況。通過調整Tweedie分布的參數,我們可以更好地擬合實際數據的分布。
這些概率模型在解決長尾數據和零膨脹數據問題上發揮了重要作用。它們不僅有助于更精確地描述和理解特殊類型數據,還為數據分析和預測提供了更強大的工具。醫療、金融、社會科學等領域都廣泛應用這些模型,為數據分析帶來了更多可能性。
02
算法介紹
2.1
分布介紹
負二項分布(Negative Binomial Distribution)
負二項分布是統計學上一種離散概率分布,用于描述在重復試驗中獲得固定數量的成功所需的獨立失敗次數的分布。這個分布經常用來描述不定次數的成功事件,例如在多次投擲硬幣直到獲得一定數量的正面朝上為止。
與二項分布不同,二項分布描述的是進行固定次數試驗中成功次數的分布,而負二項分布則關注在獲得固定數量成功之前所需的試驗次數。負二項分布在許多實際場景中都有應用,比如在金融中用于分析投資成功前的失敗次數,或者在生物學中用于研究實驗成功前需要多少次不成功的嘗試。這個分布提供了一種數學工具,幫助我們理解和解釋各種隨機事件中的概率分布。
滿足以下條件的稱為負二項分布:實驗包含一系列獨立的實驗,每個實驗都有成功、失敗兩種結果,成功的概率是恒定的,實驗持續到n次不成功,n為正整數。切換到我們的時空數據中,成功即數據非0,失敗即數據為0。
其概率分布如下:
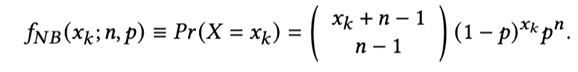
這里的 n 和 p 是模型參數,分別表示成功的次數和單次失敗的概率。
零膨脹負二項分布(Zero-InflatedNegative
Binomial Distribution)
然而,現實世界中的數據通常會出現許多零觀測值。零值的激增加劇了負二項分布參數的學習。因此,引入了一個新的參數來學習零值膨脹率,從而得到了零膨脹負二項分布。
零膨脹負二項分布(Zero-Inflated Negative Binomial Distribution,簡稱ZINB 分布)是一種概率統計學中的概率分布,用于處理數據中存在大量零值的情況,同時考慮了負二項分布的特性。
在現實世界的數據中,往往會有很多零值的存在,這可能是因為某些特定原因導致的。例如,在社交媒體上的點贊數量中,很多帖子可能沒有被點贊,導致數據中存在許多零值。然而,傳統的負二項分布在處理這種情況時可能表現不佳,因為它無法很好地捕捉到數據中的零值特征。
ZINB 分布的引入就是為了更好地處理這種零值問題。它結合了兩個部分:一個用于描述零值的部分,另一個用于描述非零值的部分。具體而言,ZINB分布中引入了一個額外的參數,用于表示數據中零值的膨脹程度。在生成數據時,有的概率產生零值,而有的概率遵循負二項分布生成非零值。這樣,ZINB分布能夠更準確地刻畫存在零值的數據特征,并在建模和分析過程中更加適用。
其概率分布如下:
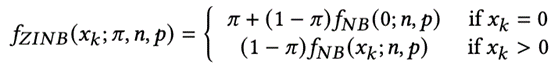
在負二項分布的基礎上,考慮了零值的加權。這里的pi即為零膨脹系數。
ZINB 分布在許多領域的數據分析中都有應用,特別是在處理存在大量零值的數據集時,如社交媒體數據、醫療數據等。通過引入零膨脹參數,ZINB 分布幫助我們更好地理解和解釋這些特殊類型的數據,并提供了更準確的分析工具。
Tweedie 分布
負二項分布是對零值做了一定的處理,但不能適用于極度零值的情況;因此通過引入新參數來對零值做加權,加強了模型魯棒性。然而,有過多零值的出現,就一定會有長尾效應的產生,因此如何建模長尾效應也是一個值的考慮的問題 —— Tweedie 分布。
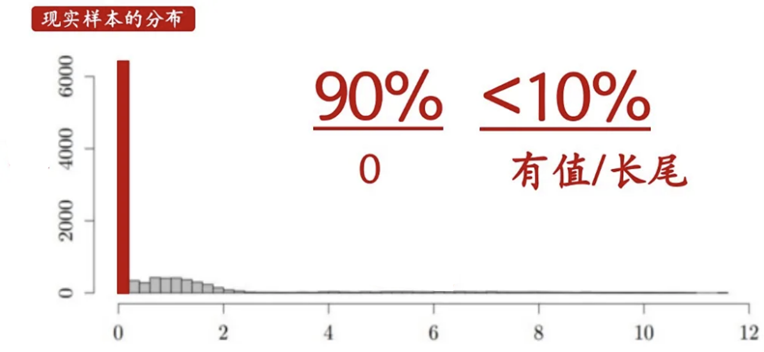
圖源知乎用戶:一直學習一直爽
Tweedie分布是一種概率統計學中的廣義線性模型,用于建模和分析具有復雜分布特征的正數數據。這種分布在描述連續、離散和混合數據等多種數據類型時都具有應用價值。Tweedie分布由一系列的特殊情況組成,包括正態分布、伽馬分布、泊松分布等。它的靈活性使得它能夠適應各種數據分布的特點,而不需要對每種特定情況進行單獨的建模。Tweedie分布的參數化形式取決于兩個主要參數:指數參數和離散參數。指數參數決定了數據的分布形狀,離散參數則控制了數據的離散程度。通過適當地選擇這些參數,可以使Tweedie分布擬合多種數據類型,包括長尾數據和零膨脹數據。
Tweedie分布的概率密度函數如下:
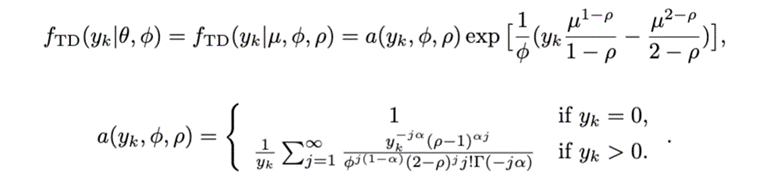
這里一共有三個參數:離散系數, 指數系數和模型均值。
在實際應用中,Tweedie分布廣泛用于處理存在多樣性和復雜性的數據集,如保險索賠數據、金融時間序列數據、生態學數據等。通過使用Tweedie分布,我們能夠更好地捕捉和解釋數據的分布特征,從而進行更精確的分析、建模和預測。
綜上所述,為了更好地建模時空圖的某一個時間點的某一個地理點的數據以及其不確定性,我們采用二參數模型(NB),三參數模型(ZINB和Tweedie)來計算模型的不確定性。
2.2
時空圖神經網絡介紹
如何建模每個分布的參數成為了一個棘手的問題,但在時空數據上,我們可以采用時空圖神經網絡來建模。
而為了學習這些參數,我們使用了時空圖神經網絡(STGNN)——這個神經網絡的設計有點像是在解謎,它通過一個時間編碼器和一個空間編碼器來學習參數的值。
具體而言:時間編碼器使用了一種叫做門控循環單元(GRU)的技術,類似于人類大腦中的一些運作方式,來處理數據中的時間信息。
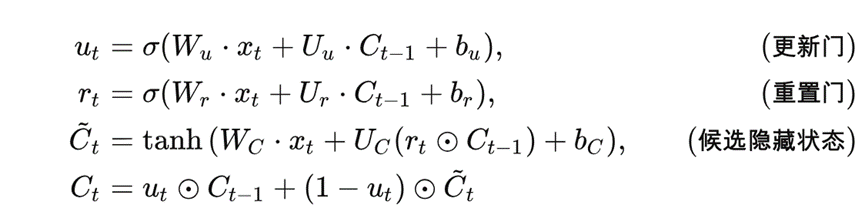
GRU 計算公式
而空間編碼器則使用了圖注意力網絡(GAT),就好像在數據之間建立了一種連接關系,幫助我們更好地理解數據之間的關聯性。
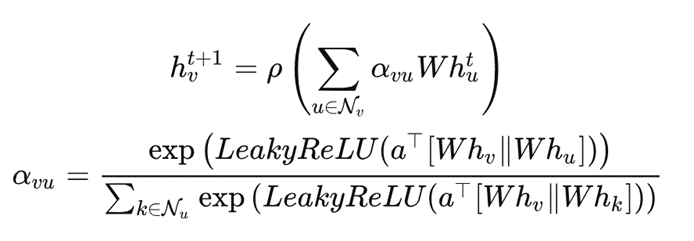
GAT 計算公式
其STGNN網絡框架如下:
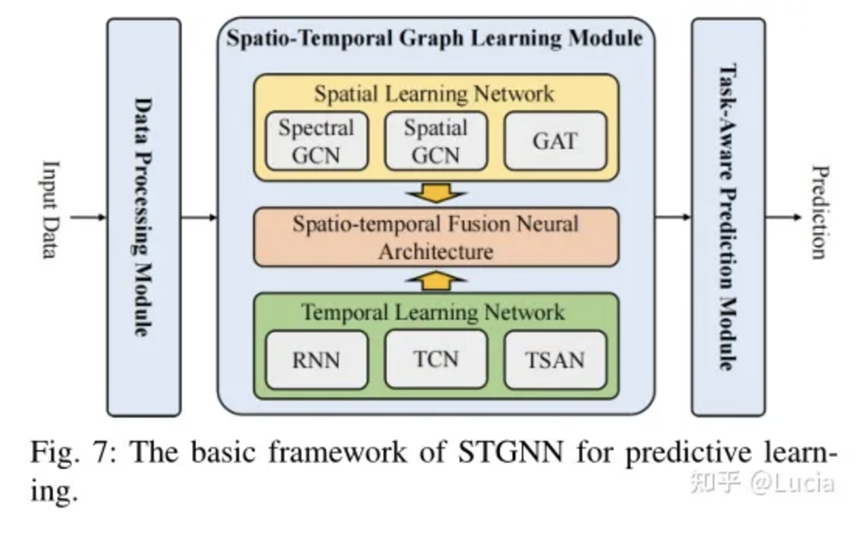
圖來自知乎用戶:Lucia
通過這個特殊的時空圖神經網絡,我們能夠更準確地學習數據模型中的參數(二參數、三參數等),基于該參數構建結果分布,從而更好地分析數據,做出更可靠的預測。這就像是在解謎一樣,不斷優化網絡,讓我們的數據分析變得更加精準和有用。
2.3
模型訓練指導函數
作者采用最大似然函數方法來指導模型訓練。
最大化似然函數是一種在統計學和概率論中常用的方法,用于找到最適合數據的參數值,以便使得數據出現的概率最大化。
讓我們用一個簡單的例子來解釋這個概念。假設你有一堆骰子擲出的數據,你想要找出這個骰子是均勻的還是有偏的。你知道這個骰子有6個面,但你不知道每個面出現的概率。你可以用一個參數來表示每個面出現的概率,然后構建一個概率模型。
現在,你有了一些實際擲骰子得到的數據,比如說你投了100次骰子,記錄下每次的結果。你的目標是找到一個參數,使得在這個參數下,投出這100次骰子的概率最大化。
這就是最大化似然函數的思想。似然函數表示的是,在給定參數的情況下,觀察到實際數據的概率。你要做的就是調整參數,使得這個概率最大化,也就是讓觀察到的數據在模型下出現的概率最大化。
最大化似然函數是一種尋找最優參數的方法,它在許多領域都有應用,從機器學習到統計分析。通過找到最適合數據的參數,我們能夠更好地理解數據的規律,從而做出更準確的預測和決策。這個方法就像是在拼圖,我們不斷嘗試不同的拼法,以找到最符合實際情況的模型。
ZINB 最大似然函數
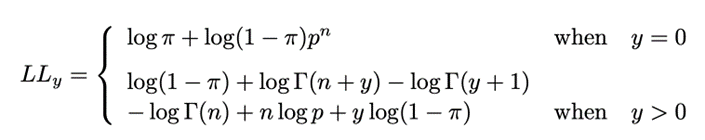
其中, , 均為通過STGNN學習所得,不斷得優化該函數,能達到模型的訓練目的。
Tweedie 最大似然函數
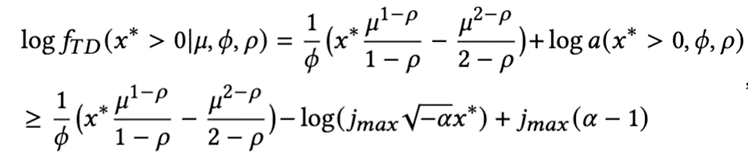
其中, , 均為通過STGNN學習所得,不斷得優化該函數,能達到模型的訓練目的。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19259瀏覽量
229653 -
編碼器
+關注
關注
45文章
3638瀏覽量
134427 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238264 -
Gru
+關注
關注
0文章
12瀏覽量
7477
原文標題:基于時空圖概率模型的不確定性衡量
文章出處:【微信號:bdtdsj,微信公眾號:中科院半導體所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何創造可信任的機器學習模型?先要理解不確定性






 工商網監
工商網監
評論