

Labs 導讀
數據庫設計是數據庫系統中的重要組成部分。一個良好的數據庫可以給系統帶來清晰的數據統計與數據的詳細分析,同時給后續的開發、拓展和維護帶來極大的便捷。本文通過列舉出當下互聯網領域常見的數據庫架構方案,結合數據庫架構的設計原則,對各個方案場景初步淺析,幫助大家知曉各方案優劣及適用場景;并結合實踐經驗,給出各個方案后續典型的演化方向,供大家作為今后數據庫架構選型參照。
作者:薛建正
單位:中國移動智慧家庭運營中心智慧互聯產品部
Part 01 ●數據庫架構原則●
高可用
高可用指的是數據庫應盡可能地使其服務持續可用,以消除或最小化停機時間。這可以通過減少單點故障、故障切換解決方案、數據冗余等方式實現。
高性能
這指的是數據庫在查詢和數據操作上的處理速度。高性能數據庫系統能迅速響應查詢請求,甚至在處理大量數據時也能保持高性能。這在互聯網場景下尤為重要,因為用戶通常期望快速響應。
一致性
在數據庫領域,一致性指的是在任何給定時間點,所有的復制數據都必須相同。數據庫系統采取多種策略來保證一致性,比如操作的原子性(一個操作要么全部成功,要么全部失敗,不會出現部分完成的情況)和事務的隔離性(通過鎖和其他并發控制機制來防止多個事務交叉執行產生的數據不一致問題)。
擴展性
擴展性指的是數據庫在增加硬件資源(如存儲和處理能力)時能有效提升性能的能力。水平擴展(增加更多服務器)和垂直擴展(增強單個服務器能力)是兩種常見的擴展策略。一個具有高擴展性的數據庫能夠應對數據增長和查詢量的增長,保證數據庫系統的性能和穩定性。
Part 02 ●常見的架構方案●
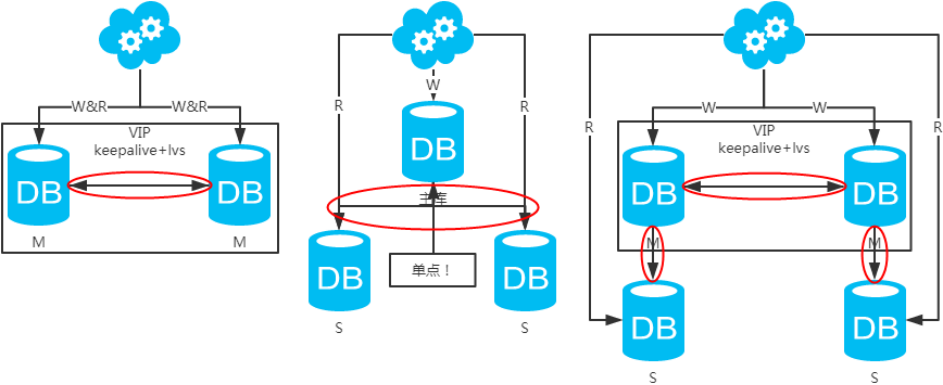
方案一:主備架構,只有主庫提供讀寫服務,備庫冗余作故障轉移用
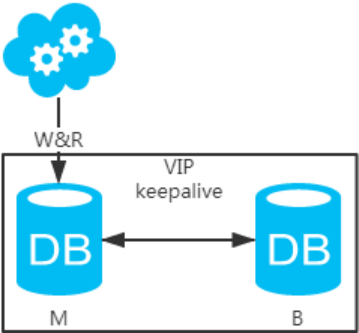
jdbc//vip:3306/xxdb
1、高可用分析:高可用,主庫掛了,keepalive(只是一種工具)會自動切換到備庫。這個過程對業務層是透明的,無需修改代碼或配置。
2、高性能分析:讀寫都操作主庫,很容易產生瓶頸。大部分互聯網應用讀多寫少,讀會先成為瓶頸,進而影響寫性能。另外,備庫只是單純的備份,資源利用率50%,這點方案二可解決。
3、一致性分析:讀寫都操作主庫,不存在數據一致性問題。
4、擴展性分析:無法通過加從庫來擴展讀性能,進而提高整體性能。
5、可落地分析:兩點影響落地使用。第一,性能一般,這點可以通過建立高效的索引和引入緩存來增加讀性能,進而提高性能。這也是通用的方案。第二,擴展性差,這點可以通過分庫分表來擴展。
方案二:雙主架構,兩個主庫同時提供服務,負載均衡
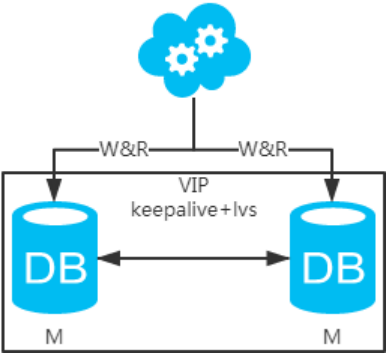
jdbc//vip:3306/xxdb
1、高可用分析:高可用,一個主庫掛了,不影響另一臺主庫提供服務。這個過程對業務層是透明的,無需修改代碼或配置。
2、高性能分析:讀寫性能相比于方案一都得到提升,提升一倍。
3、一致性分析:存在數據一致性問題。一致性解決方案。
4、擴展性分析:當然可以擴展成三主循環,但筆者不建議(會多一層數據同步,這樣同步的時間會更長)。如果非得在數據庫架構層面擴展的話,擴展為方案四。
5、可落地分析:兩點影響落地使用。第一,數據一致性問題,一致性解決方案可解決問題。第二,主鍵沖突問題,ID統一地由分布式ID生成服務來生成可解決問題。
方案三:主從架構,一主多從,讀寫分離
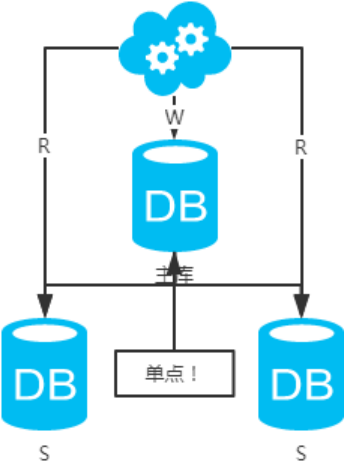
jdbc//master-ip:3306/xxdb jdbc//slave1-ip:3306/xxdb jdbc//slave2-ip:3306/xxdb
1、高可用分析:主庫單點,從庫高可用。一旦主庫掛了,寫服務也就無法提供。
2、高性能分析:大部分互聯網應用讀多寫少,讀會先成為瓶頸,進而影響整體性能。讀的性能提高了,整體性能也提高了。另外,主庫可以不用索引,線上從庫和線下從庫也可以建立不同的索引(線上從庫如果有多個還是要建立相同的索引,不然得不償失;線下從庫是平時開發人員排查線上問題時查的庫,可以建更多的索引)。
3、一致性分析:存在數據一致性問題。請看,一致性解決方案。
4、擴展性分析:可以通過加從庫來擴展讀性能,進而提高整體性能。(帶來的問題是,從庫越多需要從主庫拉取binlog日志的端就越多,進而影響主庫的性能,并且數據同步完成的時間也會更長)
5、可落地分析:兩點影響落地使用。第一,數據一致性問題,一致性解決方案可解決問題。第二,主庫單點問題,筆者暫時沒想到很好的解決方案。注:思考一個問題,一臺從庫掛了會怎樣?讀寫分離之讀的負載均衡策略怎么容錯?
方案四:雙主+主從架構,看似完美的方案
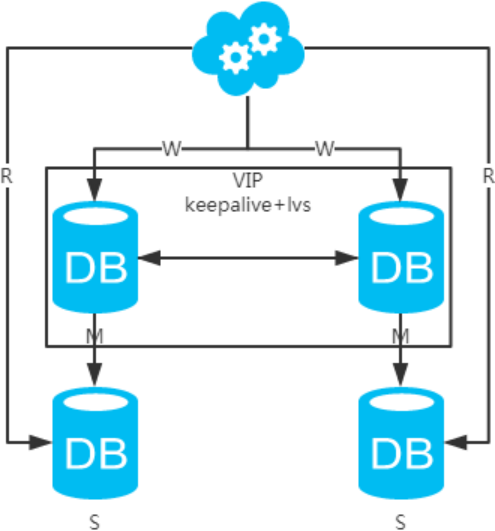
jdbc//vip:3306/xxdb jdbc//slave1-ip:3306/xxdb jdbc//slave2-ip:3306/xxdb
1、高可用分析:高可用。
2、高性能分析:高性能。
3、一致性分析:存在數據一致性問題。請看,一致性解決方案。
4、擴展性分析:可以通過加從庫來擴展讀性能,進而提高整體性能。(帶來的問題同方案二)
5、可落地分析:同方案二,但數據同步又多了一層,數據延遲更嚴重。
Part 03 ●一致性解決方案●
第一類:主庫和從庫一致性解決方案
注:圖中圈出的是數據同步的地方,數據同步(從庫從主庫拉取binlog日志,再執行一遍)是需要時間的,這個同步時間內主庫和從庫的數據會存在不一致的情況。如果同步過程中有讀請求,那么讀到的就是從庫中的老數據。如下圖:
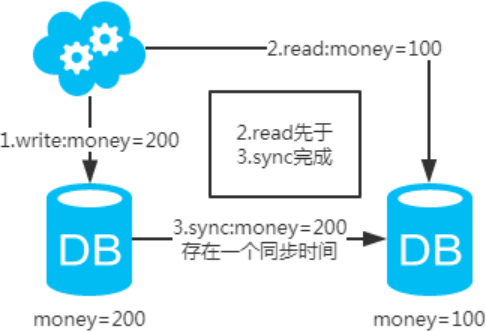
既然知道了數據不一致性產生的原因,有下面幾個解決方案供參考:
1、直接忽略,如果業務允許延時存在,那么就不去管它。
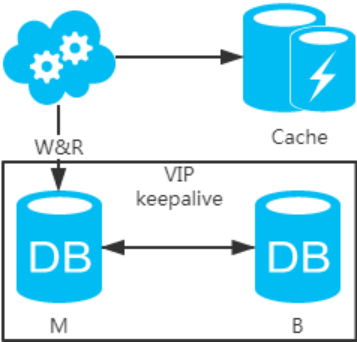
2、強制讀主,采用主備架構方案,讀寫都走主庫。用緩存來擴展數據庫讀性能 。有一點需要知道,如果緩存掛了,可能會產生雪崩現象,不過一般分布式緩存都是高可用的。
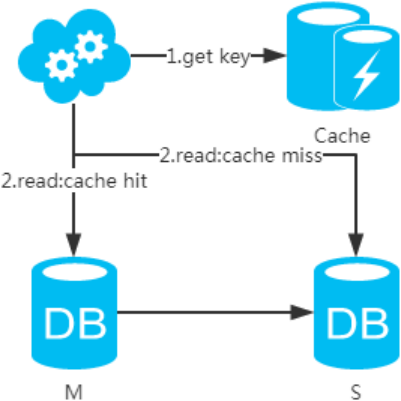
3、選擇讀主,寫操作時根據庫+表+業務特征生成一個key放到Cache里并設置超時時間(大于等于主從數據同步時間)。讀請求時,同樣的方式生成key先去查Cache,再判斷是否命中。若命中,則讀主庫,否則讀從庫。代價是多了一次緩存讀寫,基本可以忽略。
4、半同步復制,等主從同步完成,寫請求才返回。就是大家常說的“半同步復制”semi-sync。這可以利用數據庫原生功能,實現比較簡單。代價是寫請求時延增長,吞吐量降低。
5、數據庫中間件,引入開源(mycat等)或自研的數據庫中間層。個人理解,思路同選擇讀主。數據庫中間件的成本比較高,并且還多引入了一層。
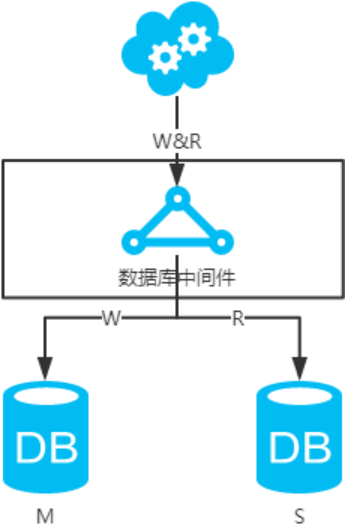
第二類:DB和緩存一致性解決方案
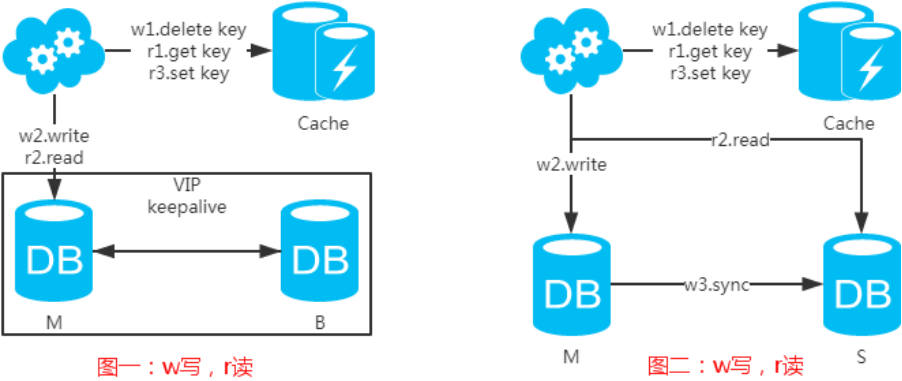
先來看一下常用的緩存使用方式:
第一步:淘汰緩存;
第二步:寫入數據庫;
第三步:讀取緩存?返回:讀取數據庫;
第四步:讀取數據庫后寫入緩存注:如果按照這種方式,圖一,不會產生DB和緩存不一致問題;圖二,會產生DB和緩存不一致問題,即4.read先于3.sync執行。如果不做處理,緩存里的數據可能一直是臟數據。解決方式如下:
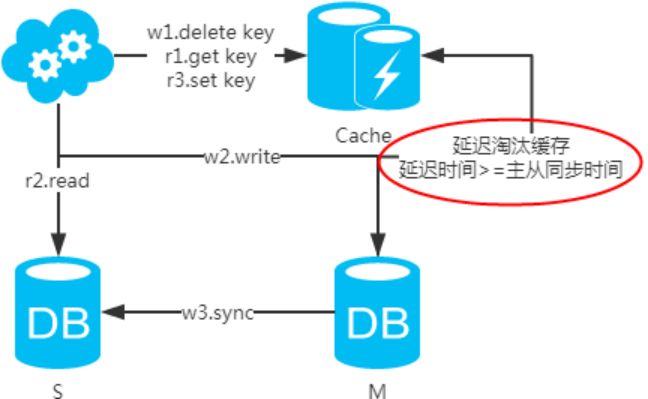
注:設置緩存時,一定要加上有效時間,以防延時淘汰緩存失敗的情況!
Part 04 ●架構演變方案●
架構演變一:方案一 -> 方案一+分庫分表 -> 方案二+分庫分表 -> 方案四+分庫分表;
架構演變二:方案一 -> 方案一+分庫分表 -> 方案三+分庫分表 -> 方案四+分庫分表;
架構演變三:方案一 -> 方案二 -> 方案四 -> 方案四+分庫分表;
架構演變四:方案一 -> 方案三 -> 方案四 -> 方案四+分庫分表;
Part 05 ●結語●
1、加緩存和索引是通用的提升數據庫性能的方式。
2、分庫分表帶來的好處是巨大的,但同樣也會帶來一些問題,詳見前日推文。
3、不管是主備+分庫分表還是主從+讀寫分離+分庫分表,都要考慮具體的業務場景。絕大部分的數據庫架構還是采用方案一和方案一+分庫分表,只有極少部分用方案三+讀寫分離+分庫分表。另外,阿里云提供的數據庫云服務也都是主備方案,要想主從+讀寫分離需要二次架構。
4、記住一句話:不考慮業務場景的架構都是耍流氓。
審核編輯:湯梓紅
-
互聯網
+關注
關注
54文章
11233瀏覽量
105623 -
數據庫
+關注
關注
7文章
3901瀏覽量
65783 -
代碼
+關注
關注
30文章
4887瀏覽量
70266
原文標題:淺析:數據庫之互聯網常用架構方案一覽及應用場景
文章出處:【微信號:5G通信,微信公眾號:5G通信】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
聯想將進軍互聯網
互聯網電視迅速崛起
工業互聯網
工業互聯網
誠征自動化(硬件、嵌入式)、互聯網、 數據庫、數據安全技術合伙人
互聯網與工業物聯網之間的區別與聯系
什么是產業互聯網?
labview軟件連接云數據庫,實現文件管理,版本更新,物聯網搭建~~~
圖模型和圖數據庫
在ARM9上用輕型WEB服務器可以不接入互聯網嗎
ARM上實現不用接入互聯網的WEB服務器可以嗎
基于互聯網的觸摸屏數據庫遠程監控系統
數據庫有哪些常見的應用結構數據庫應用結構的使用資料概述
工業互聯網時代,我們為什么需要一個時序數據庫?





 工商網監
工商網監

評論