 LoRA繼任者ReLoRA登場,通過疊加多個低秩更新矩陣實現更高效大模型訓練效果
LoRA繼任者ReLoRA登場,通過疊加多個低秩更新矩陣實現更高效大模型訓練效果
本文是一篇專注于減輕大型Transformer語言模型訓練代價的工作。作者提出了一種基于低秩更新的ReLoRA方法。過去十年中深度學習發展階段中的一個核心原則就是不斷的“堆疊更多層(stack more layers),因此作者希望探索能否同樣以堆疊的方式來提升低秩適應的訓練效率,實驗結果表明,ReLoRA在改進大型網絡的訓練方面更加有效。

論文鏈接: https://arxiv.org/abs/2307.05695 代碼倉庫: https://github.com/guitaricet/peft_pretraining
一段時間以來,大模型(LLMs)社區的研究人員開始關注于如何降低訓練、微調和推理LLMs所需要的龐大算力,這對于繼續推動LLMs在更多的垂直領域中發展和落地具有非常重要的意義。目前這一方向也有很多先驅工作,例如從模型結構上創新的RWKV,直接替換計算量較大的Transformer架構,改用基于RNN范式的新架構。還有一些方法從模型微調階段入手,例如在原有LLMs中加入參數量較小的Adapter模塊來進行微調。還有微軟提出的低秩自適應(Low-Rank Adaptation,LoRA)方法,LoRA假設模型在任務適配過程中對模型權重的更新量可以使用低秩矩陣進行估計,因而可以用來間接優化新加入的輕量級適應模塊,同時保持原有的預訓練權重不變。目前LoRA已經成為大模型工程師必備的一項微調技能,但本文作者仍然不滿足于目前LoRA所能達到的微調效果,并進一步提出了一種可疊加的低秩微調方法,稱為ReLoRA。
本文來自馬薩諸塞大學洛厄爾分校的研究團隊,作者團隊將ReLoRA應用在具有高達350M參數的Transformer上時,展現出了與常規神經網絡訓練相當的性能。此外,本文作者還觀察到ReLoRA的微調效率會隨著模型參數規模的增加而不斷提高,這使得其未來有可能成為訓練超大規模(通常超過1B參數)LLMs的新型手段。
一、引言雖然目前學術界和工業界都在不斷推出自家的各種基座模型,但不可否認的是,完全預訓練一個具有初等推理能力的LLMs仍然需要非常龐大的算力,例如大家熟知的LLaMA-6B模型[1]就需要數百個GPU才能完成訓練,這種規模的算力已經讓絕大多數學術研究小組望而卻步了。在這種背景下,參數高效微調(PEFT)已經成為了一個非常具有前景的LLMs研究方向。具體來說,PEFT方法可以在消費級GPU(例如RTX 3090或4090)上對十億級語言或擴散模型進行微調。因此本文重點關注PEFT中的低秩訓練技術,尤其是LoRA方法。作者思考到,過去十年中深度學習發展階段中的一個核心原則就是不斷的“堆疊更多層(stack more layers)”,例如ResNet的提出可以使我們將卷積神經網絡的深度提升到100層以上,并且也獲得了非常好的效果。因此本文探索能否同樣以堆疊的方式來提升低秩適應的訓練效率呢?
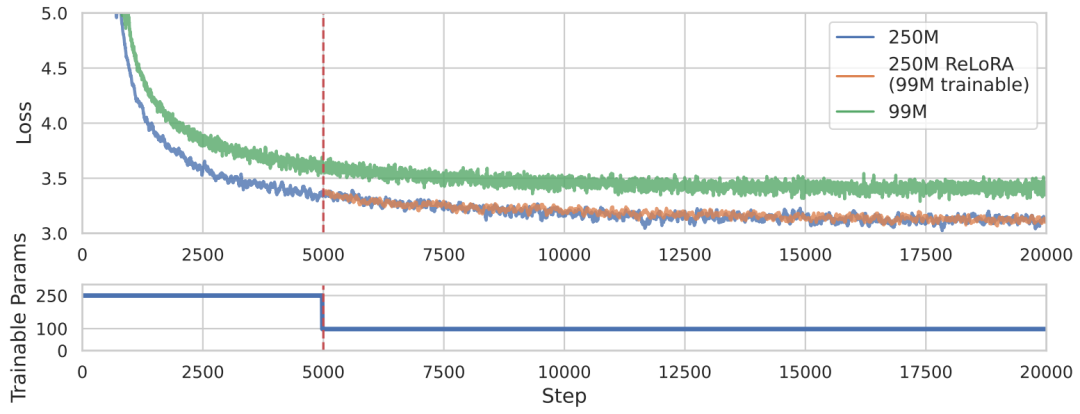
本文提出了一種基于低秩更新的ReLoRA方法,來訓練和微調高秩網絡,其性能優于具有相同可訓練參數數量的網絡,甚至能夠達到與訓練100M+規模的完整網絡類似的性能,對比效果如上圖所示。具體來說,ReLoRA方法包含(1)初始化全秩訓練、(2)LoRA 訓練、(3)參數重新啟動、(4)鋸齒狀學習率調度(jagged learning rate schedule)和(5)優化器參數部分重置。作者選擇目前非常火熱的自回歸語言模型進行實驗,并且保證每個實驗所使用的GPU計算時間不超過8天。二、本文方法作者首先從兩個矩陣之和的秩入手,通常來說,矩陣相加的后秩的上界會比較緊湊,對于矩陣,,然后存在矩陣,,使得矩陣之和的秩高于或。作者希望利用這一特性來制定靈活的參數高效訓練方法,然后從LoRA算法開始入手,LoRA可以將模型權重的更新量 分解為一組低秩矩陣乘積 ,如下式所示,其中 是固定縮放因子。
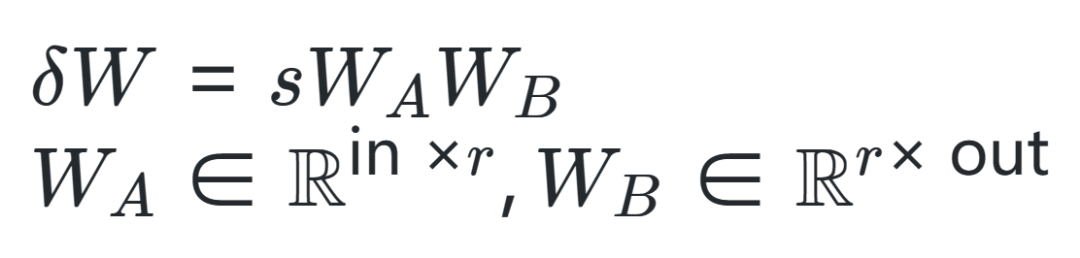
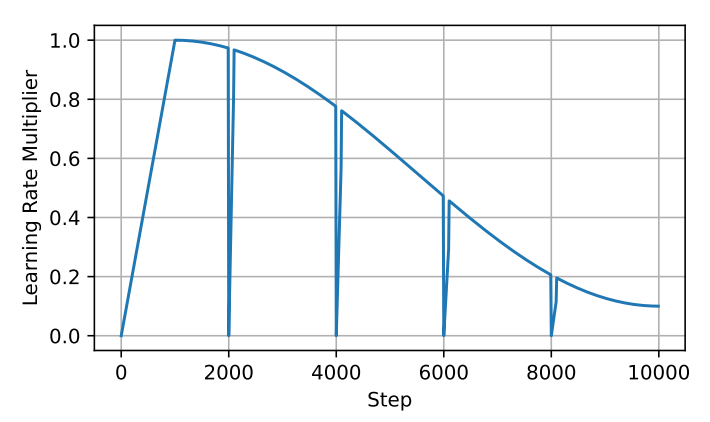
在具體操作時,LoRA通常是加入新的可學習參數 和 來實現,這些參數可以在訓練后合并回原始參數中。因此,盡管上述方程允許我們在訓練階段中實現總參數更新量高于任意單個矩陣的秩,但其仍然受到的限制。因此作者想到通過不斷疊加這一過程來突破限制達到更好的訓練效果。這首先需要對LoRA過程進行重新啟動,就可以在訓練階段不斷合并每次得到的 和 來得到累加的權重更新量,計算公式如下:但是,想要對已經完成的LoRA過程重新啟動并不容易,這需要對優化器進行精細的調整,如果調整不到位,會導致模型在重啟后立即與之前的優化方向出現分歧。例如Adam優化器在更新時主要由先前步驟中所累積梯度的一階矩和二階矩引導。實際上,梯度矩平滑參數 和 通常非常高,因而在重新啟動時的秩上界為 ,相應的梯度矩 和 都是滿秩的,在合并參數后就會使用先前的舊梯度來優化 朝向與 相同的子空間方向。 為了解決這個問題,作者提出了ReLoRA方法,ReLoRA在合并和重新啟動期間可以對優化器進行部分重置,并在隨后的預熱中過程中將學習率設置為0。具體來說,作者提出了一種鋸齒狀學習率調度算法,如下圖所示,在每次對ReLoRA參數進行重置時,都會將學習率設置為零,并執行快速(50-100 步)學習率預熱使其回到與重置前相同的水平范圍內。
ReLoRA通過序列疊加的方式僅訓練一小組參數就可以實現與全秩訓練相當的性能,并且遵循LoRA方法的基礎原則,即保持原始網絡的凍結權重并添加新的可訓練參數。乍一看,這種方式可能顯得計算效率低下,但我們需要清楚的是,這種方法可以通過減小梯度和優化器狀態的大小,來顯著提高顯存效率。例如Adam優化器狀態消耗的顯存通常是模型權重占用的兩倍。通過大幅減少可訓練參數的數量,ReLoRA可以在相同的顯存條件下使用更大的batchsize大小,從而最大限度地提高硬件效率,ReLoRA的整體操作細節如下圖所示。

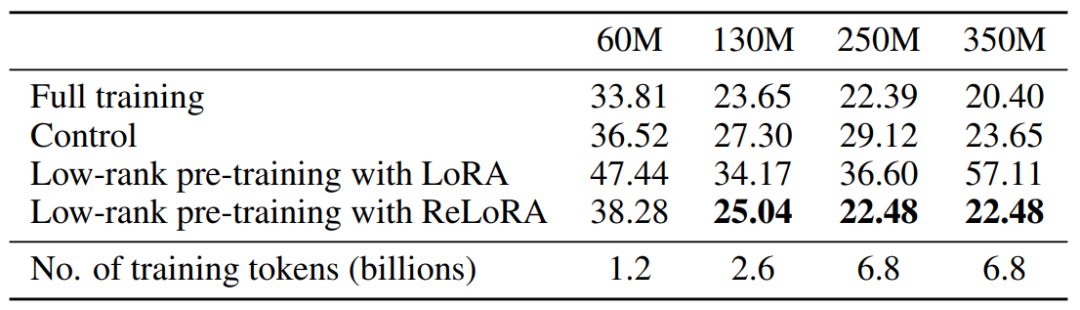
三、實驗效果為了清晰的評估ReLoRA方法的性能,作者將其應用在各種規模大小(60M、130M、250M 和 350M)的Transformer模型上,并且都在C4數據集上進行訓練和測試。為了展現ReLoRA方法的普適性,作者重點考察NLP領域的基礎語言建模任務。模型架構和訓練超參數設置基本與LLaMA模型保持一致。與LLaMA不同的是,作者在實驗中將原始的注意力機制(使用float32進行 softmax計算)替換為了Flash注意力[2],并且使用bfloat16精度進行計算,這樣操作可以將訓練吞吐量提高50-100%,且沒有任何訓練穩定性問題。此外,使用ReLoRA方法訓練的模型參數規模相比LLaMA要小得多,最大的模型參數才僅有350M,使用8個RTX4090上訓練了一天時間就可以完成。 下圖展示了本文方法與其他方法的性能對比效果,可以看到ReLoRA顯著優于低秩LoRA方法,證明了我們提出的修改的有效性。此外,ReLoRA還實現了與滿秩訓練(Full training)相當的性能,并且我們可以觀察到,隨著網絡規模的增加,性能差距逐漸縮小。有趣的是,ReLoRA 唯一無法超過的基線模型是僅具有60M參數的最小模型。這一觀察結果表明,ReLoRA在改進大型網絡的訓練方面更加有效,這與作者最開始研究探索一種改進大型網絡訓練方法的目標是一致的。
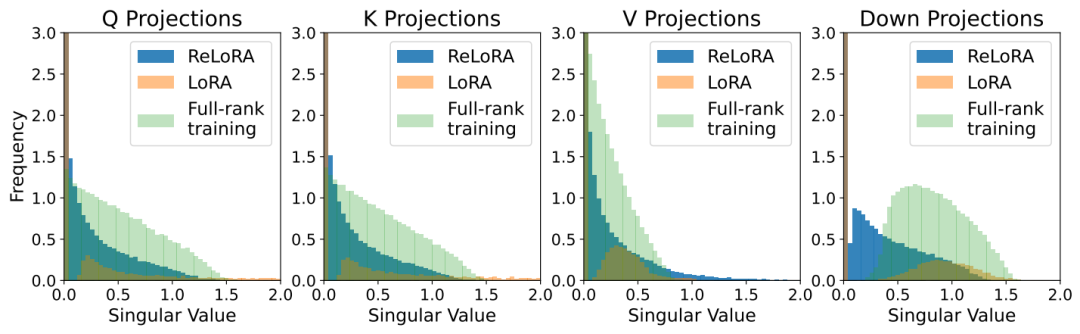
此外,為了進一步判斷ReLoRA是否能夠通過迭代低秩更新來實現相比LoRA更高的秩更新訓練,作者繪制了ReLoRA、LoRA和全秩訓練的熱啟動權重與最終權重之間差異的奇異值譜。如下圖所示,下圖說明了LoRA和ReLoRA之間對于 、、 和 奇異值的顯著差異,可以看到ReLoRA在所有四個矩陣參數上均得到了最小的奇異值。
四、總結本文是一篇專注于減輕大型Transformer語言模型訓練代價的工作,作者選取了一條非常具有前景的方向,即低秩訓練技術,并且從最樸素的低秩矩陣分解 (LoRA) 方法出發,利用多個疊加的低秩更新矩陣來訓練高秩網絡,為了實現這一點,作者精心設計了包含參數重新啟動、鋸齒狀學習率調度算法和優化器參數重置等一系列操作,這些操作共同提高了ReLoRA算法的訓練效率,在某些情況下甚至能夠達到與全秩訓練相當的性能,尤其實在超大規模的Transformer網絡中。作者通過大量的實驗證明了ReLoRA的算法可行性和操作有效性,不知ReLoRA是否也會成為大模型工程師一項必備的算法技能呢?
-
神經網絡
+關注
關注
42文章
4773瀏覽量
100877 -
深度學習
+關注
關注
73文章
5506瀏覽量
121259 -
LoRa
+關注
關注
349文章
1694瀏覽量
232044 -
大模型
+關注
關注
2文章
2477瀏覽量
2837
原文標題:LoRA繼任者ReLoRA登場,通過疊加多個低秩更新矩陣實現更高效大模型訓練效果
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「大模型啟示錄」閱讀體驗】營銷領域大模型的應用
GPU是如何訓練AI大模型的
PyTorch GPU 加速訓練模型方法
如何訓練自己的AI大模型
2024 VDC人工智能會場:全新藍心大模型矩陣,助力開發者高效創新

如何通過增強抗干擾能力提高LoRa通信效果

使用TensorFlow進行神經網絡模型更新
人臉識別模型訓練失敗原因有哪些
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
基于雙級優化(BLO)的消除過擬合的微調方法






 工商網監
工商網監
評論