 SpringBoot 2種方式快速實現分庫分表,輕松拿捏!
SpringBoot 2種方式快速實現分庫分表,輕松拿捏!
本文將為您介紹 ShardingSphere 的一些基礎特性和架構組成,以及在 Springboot 環境下通過 JAVA編碼 和 Yml配置 兩種方式快速實現分庫分表。
一、什么是 ShardingSphere?
shardingsphere 是一款開源的分布式關系型數據庫中間件,為 Apache 的頂級項目。其前身是 sharding-jdbc 和 sharding-proxy 的兩個獨立項目,后來在 2018 年合并成了一個項目,并正式更名為 ShardingSphere。
其中 sharding-jdbc 為整個生態中最為經典和成熟的框架,最早接觸分庫分表的人應該都知道它,是學習分庫分表的最佳入門工具。
如今的 ShardingSphere 已經不再是單純代指某個框架,而是一個完整的技術生態圈,由三款開源的分布式數據庫中間件 sharding-jdbc、sharding-proxy 和 sharding-sidecar 所構成。前兩者問世較早,功能較為成熟,是目前廣泛應用的兩個分布式數據庫中間件,因此在后續的文章中,我們將重點介紹它們的特點和使用方法。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
二、為什么選 ShardingSphere?
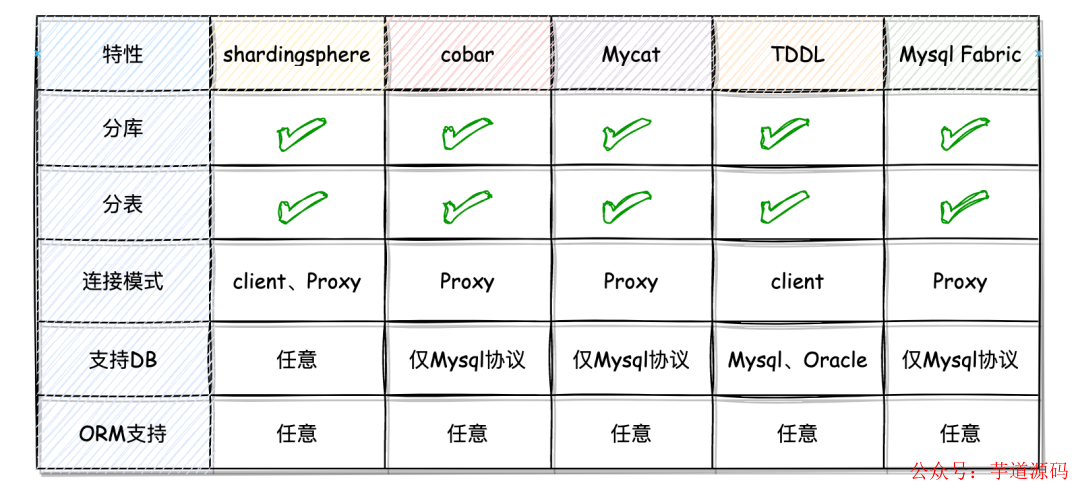
為了回答這個問題,我整理了市面上常見的分庫分表工具,包括 ShardingSphere、Cobar、Mycat、TDDL、MySQL Fabric 等,并從多個角度對它們進行了簡單的比較。
Cobar
Cobar 是阿里巴巴開源的一款基于MySQL的分布式數據庫中間件,提供了分庫分表、讀寫分離和事務管理等功能。它采用輪詢算法和哈希算法來進行數據分片,支持分布式分表,但是不支持單庫分多表。
它以 Proxy 方式提供服務,在阿里內部被廣泛使用已開源,配置比較容易,無需依賴其他東西,只需要有Java環境即可。兼容市面上幾乎所有的 ORM 框架,僅支持 MySQL 數據庫,且事務支持方面比較麻煩。
MyCAT
Mycat 是社區愛好者在阿里 Cobar 基礎上進行二次開發的,也是一款比較經典的分庫分表工具。它以 Proxy 方式提供服務,支持分庫分表、讀寫分離、SQL路由、數據分片等功能。
兼容市面上幾乎所有的 ORM 框架,包括 Hibernate、MyBatis和 JPA等都兼容,不過,美中不足的是它僅支持 MySQL數據庫,目前社區的活躍度相對較低。
TDDL
TDDL 是阿里巴巴集團開源的一款分庫分表解決方案,可以自動將SQL路由到相應的庫表上。它采用了垂直切分和水平切分兩種方式來進行分表分庫,并且支持多數據源和讀寫分離功能。
TDDL 是基于 Java 開發的,支持 MySQL、Oracle 和 SQL Server 數據庫,并且可以與市面上 Hibernate、MyBatis等 ORM 框架集成。
不過,TDDL僅支持一些阿里巴巴內部的工具和框架的集成,對于外部公司來說可能相對有些局限性。同時,其文檔和社區活躍度相比 ShardingSphere 來說稍顯不足。
Mysql Fabric
MySQL Fabric是 MySQL 官方提供的一款分庫分表解決方案,同時也支持 MySQL其他功能,如高可用、負載均衡等。它采用了管理節點和代理節點的架構,其中管理節點負責實時管理分片信息,代理節點則負責接收并處理客戶端的讀寫請求。
它僅支持 MySQL 數據庫,并且可以與市面上 Hibernate、MyBatis 等 ORM 框架集成。MySQL Fabric 的文檔相對來說比較簡略,而且由于是官方提供的解決方案,其社區活躍度也相對較低。
ShardingSphere
ShardingSphere 成員中的 sharding-jdbc 以 JAR 包的形式下提供分庫分表、讀寫分離、分布式事務等功能,但僅支持 Java 應用,在應用擴展上存在局限性。
因此,ShardingSphere 推出了獨立的中間件 sharding-proxy,它基于 MySQL協議實現了透明的分片和多數據源功能,支持各種語言和框架的應用程序使用,對接的應用程序幾乎無需更改代碼,分庫分表配置可在代理服務中進行管理。
除了支持 MySQL,ShardingSphere還可以支持 PostgreSQL、SQLServer、Oracle等多種主流數據庫,并且可以很好地與 Hibernate、MyBatis、JPA等 ORM 框架集成。重要的是,ShardingSphere的開源社區非常活躍。
如果在使用中出現問題,用戶可以在 GitHub 上提交PR并得到快速響應和解決,這為用戶提供了足夠的安全感。
產品比較
通過對上述的 5 個分庫分表工具進行比較,我們不難發現,就整體性能、功能豐富度以及社區支持等方面來看,ShardingSphere 在眾多產品中優勢還是比較突出的。下邊用各個產品的主要指標整理了一個表格,看著更加直觀一點。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
三、ShardingSphere 成員
ShardingSphere 的主要組成成員為sharding-jdbc、sharding-proxy,它們是實現分庫分表的兩種不同模式:
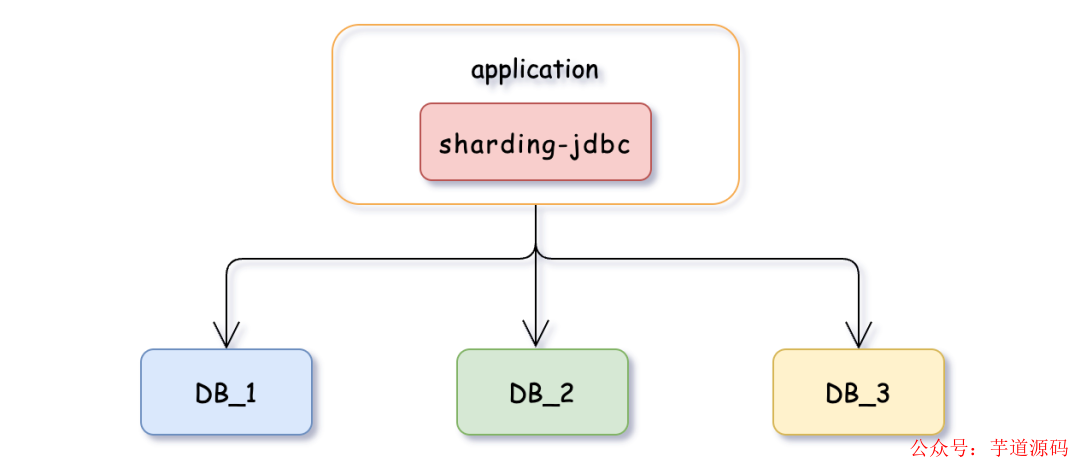
sharding-jdbc
它是一款輕量級Java框架,提供了基于 JDBC 的分庫分表功能,為客戶端直連模式。使用sharding-jdbc,開發者可以通過簡單的配置實現數據的分片,同時無需修改原有的SQL語句。支持多種分片策略和算法,并且可以與各種主流的ORM框架無縫集成。
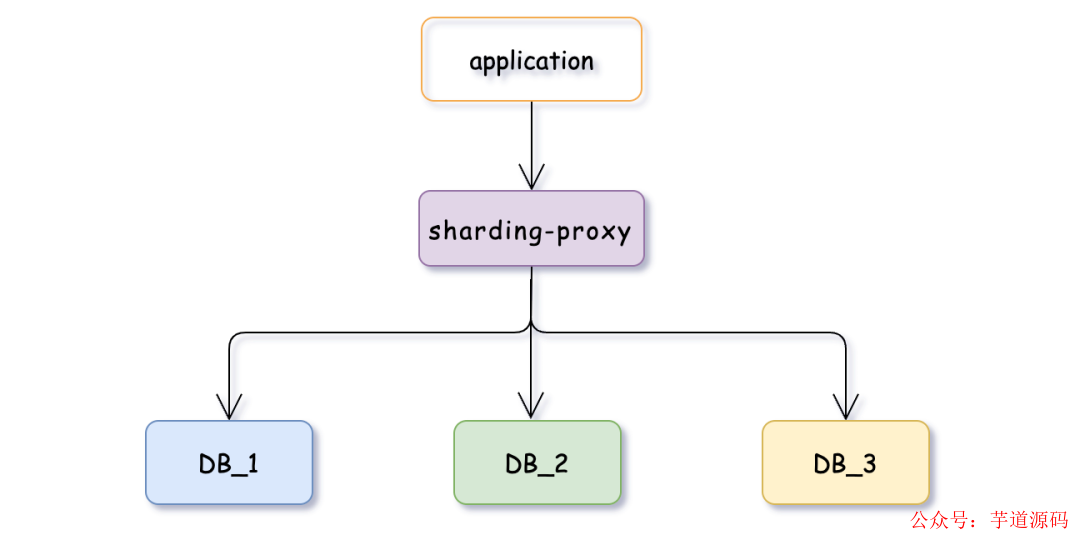
sharding-proxy
它是基于 MySQL 協議的代理服務,提供了透明的分庫分表功能。使用 sharding-proxy 開發者可以將分片邏輯從應用程序中解耦出來,無需修改應用代碼就能實現分片功能,還支持多數據源和讀寫分離等高級特性,并且可以作為獨立的服務運行。
四、快速實現
我們先使用sharding-jdbc來快速實現分庫分表。相比于 sharding-proxy,sharding-jdbc 適用于簡單的應用場景,不需要額外的環境搭建等。下邊主要基于 SpringBoot 的兩種方式來實現分庫分表,一種是通過YML配置方式,另一種則是通過純Java編碼方式(不可并存 )。在后續章節中,我們會單獨詳細介紹如何使用sharding-proxy以及其它高級特性。
ShardingSphere 官網地址:https://shardingsphere.apache.org/
準備工作
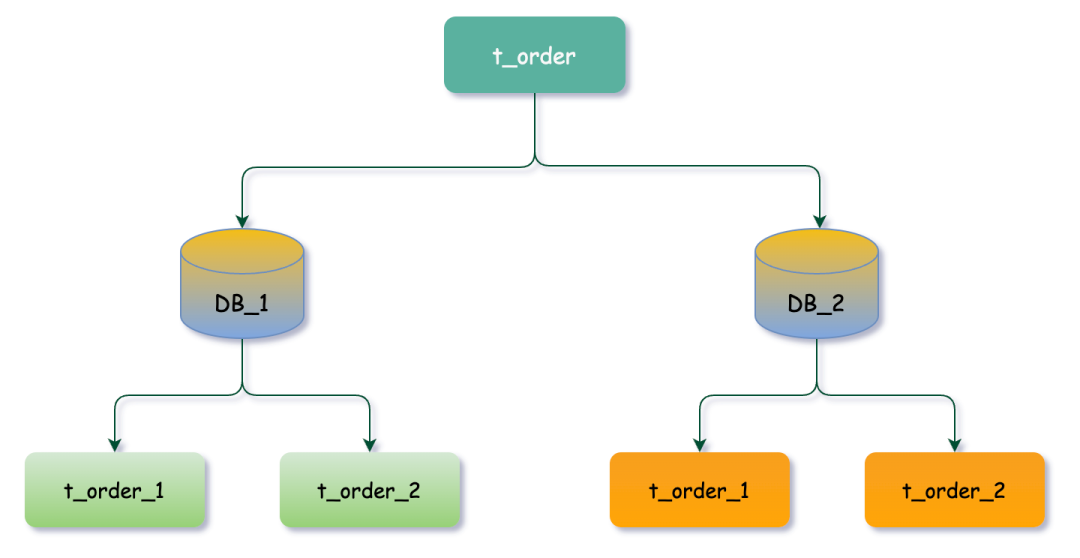
在開始實現之前,需要對數據庫和表的拆分規則進行明確。以對t_order表進行分庫分表拆分為例,具體地,我們將 t_order 表拆分到兩個數據庫中,分別為db1和db2,每個數據庫又將該表拆分為三張表,分別為t_order_1、t_order_2和t_order_3。
db0
├──t_order_0
├──t_order_1
└──t_order_2
db1
├──t_order_0
├──t_order_1
└──t_order_2
JAR包引入
引入必要的 JAR 包,其中最重要的是shardingsphere-jdbc-core-spring-boot-starter和mysql-connector-java這兩個。為了保證功能的全面性和兼容性,以及避免因低版本包導致的不必要錯誤和調試工作,我選擇的包版本都較高。

shardingsphere-jdbc-core-spring-boot-starter 是 ShardingSphere 框架的核心組件,提供了對 JDBC 的分庫分表支持;而 mysql-connector-java 則是 MySQL JDBC 驅動程序的實現,用于連接MySQL數據庫。除此之外,我使用了JPA作為持久化工具還引入了相應的依賴包。
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
<version>2.7.6version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.31version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starterartifactId>
<version>5.2.0version>
dependency>
YML配置
我個人是比較推薦使用YML配置方式來實現 sharding-jdbc 分庫分表的,使用YML配置方式不僅可以讓分庫分表的實現更加簡單、高效、可維護,也更符合 SpringBoot的開發規范。
在 src/main/resources/application.yml 路徑文件下添加以下完整的配置,即可實現對t_order表的分庫分表,接下來拆解看看每個配置模塊都做了些什么。
spring:
shardingsphere:
#數據源配置
datasource:
#數據源名稱,多數據源以逗號分隔
names:db0,db1
db0:
type:com.zaxxer.hikari.HikariDataSource
driver-class-name:com.mysql.cj.jdbc.Driver
jdbc-url:jdbc//127.0.0.1:3306/shardingsphere-db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username:root
password:123456
db1:
type:com.zaxxer.hikari.HikariDataSource
driver-class-name:com.mysql.cj.jdbc.Driver
jdbc-url:jdbc//127.0.0.1:3306/shardingsphere-db0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username:root
password:123456
#分片規則配置
rules:
sharding:
#分片算法配置
sharding-algorithms:
database-inline:
#分片算法類型
type:INLINE
props:
#分片算法的行表達式(算法自行定義,此處為方便演示效果)
algorithm-expression:db$->{order_id>4?1:0}
table-inline:
#分片算法類型
type:INLINE
props:
#分片算法的行表達式
algorithm-expression:t_order_$->{order_id%4}
tables:
#邏輯表名稱
t_order:
#行表達式標識符可以使用${...}或$->{...},但前者與Spring本身的屬性文件占位符沖突,因此在Spring環境中使用行表達式標識符建議使用$->{...}
actual-data-nodes:db${0..1}.t_order_${0..3}
#分庫策略
database-strategy:
standard:
#分片列名稱
sharding-column:order_id
#分片算法名稱
sharding-algorithm-name:database-inline
#分表策略
table-strategy:
standard:
#分片列名稱
sharding-column:order_id
#分片算法名稱
sharding-algorithm-name:table-inline
#屬性配置
props:
#展示修改以后的sql語句
sql-show:true
以下是 shardingsphere 多數據源信息的配置,其中的 names 表示需要連接的數據庫別名列表,每添加一個數據庫名就需要新增一份對應的數據庫連接配置。
spring:
shardingsphere:
#數據源配置
datasource:
#數據源名稱,多數據源以逗號分隔
names:db0,db1
db0:
type:com.zaxxer.hikari.HikariDataSource
driver-class-name:com.mysql.cj.jdbc.Driver
jdbc-url:jdbc//127.0.0.1:3306/shardingsphere-db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username:root
password:123456
db1:
type:com.zaxxer.hikari.HikariDataSource
driver-class-name:com.mysql.cj.jdbc.Driver
jdbc-url:jdbc//127.0.0.1:3306/shardingsphere-db0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username:root
password:123456
rules節點下為分片規則的配置,sharding-algorithms 節點為自定義的分片算法模塊,分片算法可以在后邊配置表的分片規則時被引用,其中:
-
database-inline:自定義的分片算法名稱; -
type:該分片算法的類型,這里先以 inline 為例,后續會有詳細章節介紹; -
props:指定該分片算法的具體內容,其中algorithm-expression是該分片算法的表達式,即根據分片鍵值計算出要訪問的真實數據庫名或表名,。
db$->{order_id % 2}這種為 Groovy 語言表達式,表示對分片鍵order_id進行取模,根據取模結果計算出db0、db1,分表的表達式同理。
spring:
shardingsphere:
#規則配置
rules:
sharding:
#分片算法配置
sharding-algorithms:
database-inline:
#分片算法類型
type:INLINE
props:
#分片算法的行表達式(算法自行定義,此處為方便演示效果)
algorithm-expression:db$->{order_id%2}
table-inline:
#分片算法類型
type:INLINE
props:
#分片算法的行表達式
algorithm-expression:t_order_$->{order_id%3}
tables節點定義了邏輯表名t_order的分庫分表規則。actual-data-nodes 用于設置物理數據節點的數量。
db${0..1}.t_order_${0..3} 表達式意思此邏輯表在不同數據庫實例中的分布情況,如果只想單純的分庫或者分表,可以調整表達式,分庫db${0..1}、分表t_order_${0..3}。
db0
├──t_order_0
├──t_order_1
└──t_order_2
db1
├──t_order_0
├──t_order_1
└──t_order_2
spring:
shardingsphere:
#規則配置
rules:
sharding:
tables:
#邏輯表名稱
t_order:
#行表達式標識符可以使用${...}或$->{...},但前者與Spring本身的屬性文件占位符沖突,因此在Spring環境中使用行表達式標識符建議使用$->{...}
actual-data-nodes:db${0..1}.t_order_${0..3}
#分庫策略
database-strategy:
standard:
#分片列名稱
sharding-column:order_id
#分片算法名稱
sharding-algorithm-name:database-inline
#分表策略
table-strategy:
standard:
#分片列名稱
sharding-column:order_id
#分片算法名稱
sharding-algorithm-name:table-inline
database-strategy 和 table-strategy分別設置了分庫和分表策略;
sharding-column表示根據表的哪個列(分片鍵)進行計算分片路由到哪個庫、表中;
sharding-algorithm-name 表示使用哪種分片算法對分片鍵進行運算處理,這里可以引用剛才自定義的分片算法名稱使用。
props節點用于設置其他的屬性配置,比如:sql-show表示是否在控制臺輸出解析改造后真實執行的 SQL語句以便進行調試。
spring:
shardingsphere:
#屬性配置
props:
#展示修改以后的sql語句
sql-show:true
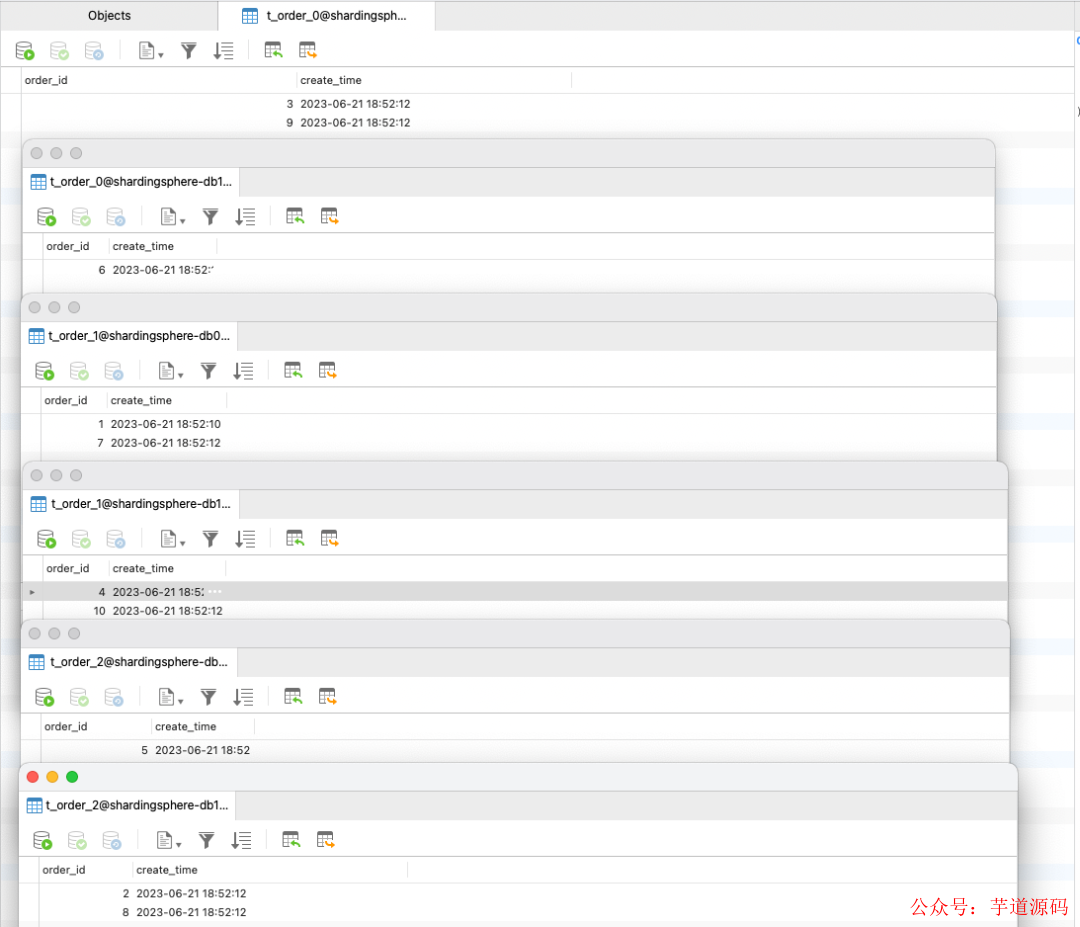
跑個單測在向數據庫中插入 10 條數據時,發現數據已經相對均勻地插入到了各個分片中。
JAVA 編碼
如果您不想通過 yml 配置文件實現自動裝配,也可以使用 ShardingSphere 的 API 實現相同的功能。使用 API 完成分片規則和數據源的配置,優勢在于更加靈活、可定制性強的特點,方便進行二次開發和擴展。
下邊是純JAVA編碼方式實現分庫分表的完整代碼。
@Configuration
publicclassShardingConfiguration{
/**
*配置分片數據源
*/
@Bean
publicDataSourcegetShardingDataSource()throwsSQLException{
MapdataSourceMap=newHashMap<>();
dataSourceMap.put("db0",dataSource1());
dataSourceMap.put("db1",dataSource2());
//分片rules規則配置
ShardingRuleConfigurationshardingRuleConfig=newShardingRuleConfiguration();
shardingRuleConfig.setShardingAlgorithms(getShardingAlgorithms());
//配置t_order表分片規則
ShardingTableRuleConfigurationorderTableRuleConfig=newShardingTableRuleConfiguration("t_order","db${0..1}.t_order_${0..2}");
orderTableRuleConfig.setTableShardingStrategy(newStandardShardingStrategyConfiguration("order_id","table-inline"));
orderTableRuleConfig.setDatabaseShardingStrategy(newStandardShardingStrategyConfiguration("order_id","database-inline"));
shardingRuleConfig.getTables().add(orderTableRuleConfig);
//是否在控制臺輸出解析改造后真實執行的SQL
Propertiesproperties=newProperties();
properties.setProperty("sql-show","true");
//創建ShardingSphere數據源
returnShardingSphereDataSourceFactory.createDataSource(dataSourceMap,Collections.singleton(shardingRuleConfig),properties);
}
/**
*配置數據源1
*/
publicDataSourcedataSource1(){
HikariDataSourcedataSource=newHikariDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setJdbcUrl("jdbc//127.0.0.1:3306/shardingsphere-db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true");
dataSource.setUsername("root");
dataSource.setPassword("123456");
returndataSource;
}
/**
*配置數據源2
*/
publicDataSourcedataSource2(){
HikariDataSourcedataSource=newHikariDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setJdbcUrl("jdbc//127.0.0.1:3306/shardingsphere-db0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true");
dataSource.setUsername("root");
dataSource.setPassword("123456");
returndataSource;
}
/**
*配置分片算法
*/
privateMapgetShardingAlgorithms() {
MapshardingAlgorithms=newLinkedHashMap<>();
//自定義分庫算法
PropertiesdatabaseAlgorithms=newProperties();
databaseAlgorithms.setProperty("algorithm-expression","db$->{order_id%2}");
shardingAlgorithms.put("database-inline",newAlgorithmConfiguration("INLINE",databaseAlgorithms));
//自定義分表算法
PropertiestableAlgorithms=newProperties();
tableAlgorithms.setProperty("algorithm-expression","t_order_$->{order_id%3}");
shardingAlgorithms.put("table-inline",newAlgorithmConfiguration("INLINE",tableAlgorithms));
returnshardingAlgorithms;
}
}
ShardingSphere 的分片核心配置類 ShardingRuleConfiguration,它主要用來加載分片規則、分片算法、主鍵生成規則、綁定表、廣播表等核心配置。我們將相關的配置信息 set到配置類,并通過createDataSource創建并覆蓋 DataSource,最后注入Bean。
使用Java編碼方式只是將 ShardingSphere 預知的加載配置邏輯自己手動實現了一遍,兩種實現方式比較下來,還是推薦使用YML配置方式來實現 ShardingSphere的分庫分表功能,相比于Java編碼,YML配置更加直觀和易于理解,開發者可以更加專注于業務邏輯的實現,而不需要過多關注底層技術細節。
@Getter
@Setter
publicfinalclassShardingRuleConfigurationimplementsDatabaseRuleConfiguration,DistributedRuleConfiguration{
//分表配置配置
privateCollectiontables=newLinkedList<>();
//自動分片規則配置
privateCollectionautoTables=newLinkedList<>();
//綁定表配置
privateCollectionbindingTableGroups=newLinkedList<>();
//廣播表配置
privateCollectionbroadcastTables=newLinkedList<>();
//默認的分庫策略配置
privateShardingStrategyConfigurationdefaultDatabaseShardingStrategy;
//默認的分表策略配置
privateShardingStrategyConfigurationdefaultTableShardingStrategy;
//主鍵生成策略配置
privateKeyGenerateStrategyConfigurationdefaultKeyGenerateStrategy;
privateShardingAuditStrategyConfigurationdefaultAuditStrategy;
//默認的分片鍵
privateStringdefaultShardingColumn;
//自定義的分片算法
privateMapshardingAlgorithms=newLinkedHashMap<>();
//主鍵生成算法
privateMapkeyGenerators=newLinkedHashMap<>();
privateMapauditors=newLinkedHashMap<>();
}
經過查看控制臺打印的真實 SQL日志,發現在使用 ShardingSphere 進行數據插入時,其內部實現會先根據分片鍵 order_id 查詢記錄是否存在。如果記錄不存在,則執行插入操作;如果記錄已存在,則進行更新操作。看似只會執行10條插入SQL,但實際上需要執行20條SQL語句,多少會對數據庫的性能產生一定的影響。
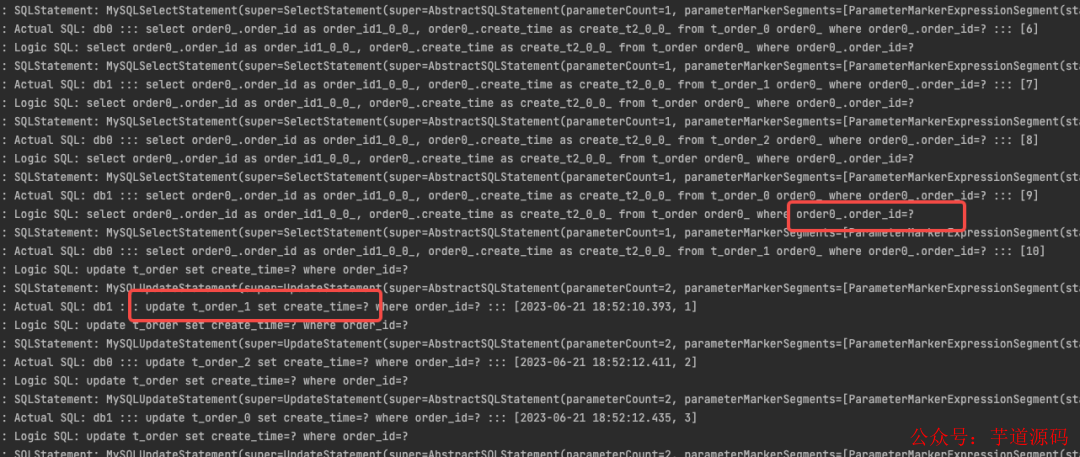
功能挺簡單的,但由于不同版本的 ShardingSphere 的 API 變化較大 ,網上類似的資料太不靠譜,本來想著借助 GPT 快點實現這段代碼,結果差點和它干起來,最后還是扒了扒看了源碼完成的。
默認數據源
可能有些小伙伴會有疑問,對于已經設置了分片規則的t_order表可以正常操作數據,如果我們的t_user表沒有配置分庫分表規則,那么在執行插入操作時會發生什么呢?
仔細看了下官方的技術文檔,其實已經回答了小伙伴這個問題,如果只有部分數據庫分庫分表,是否需要將不分庫分表的表也配置在分片規則中?官方回答:不需要 。

我們創建一張t_user表,并且不對其進行任何分片規則的配置。在我的印象中沒有通過設置 default-data-source-name 默認的數據源,操作未分片的表應該會報錯的!
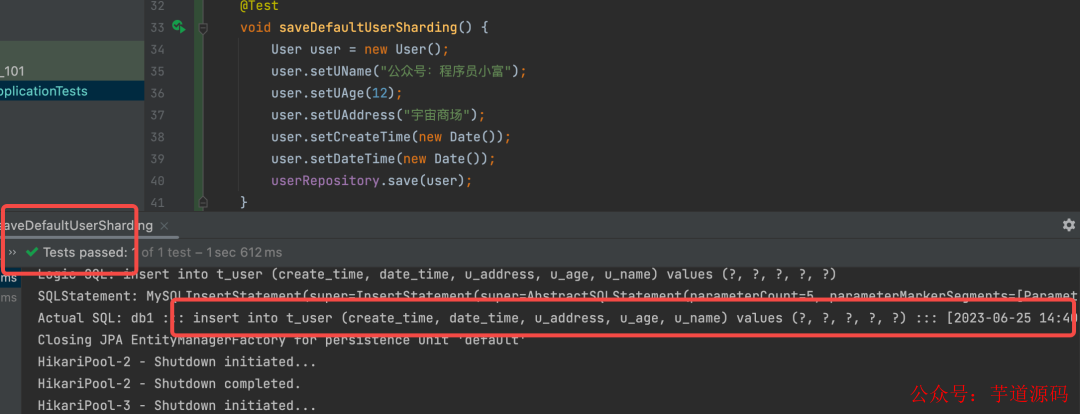
我們向t_user嘗試插入一條數據,結果居然成功了?翻了翻庫表發現數據只被插在了 db1 庫里,說明沒有走廣播路由。
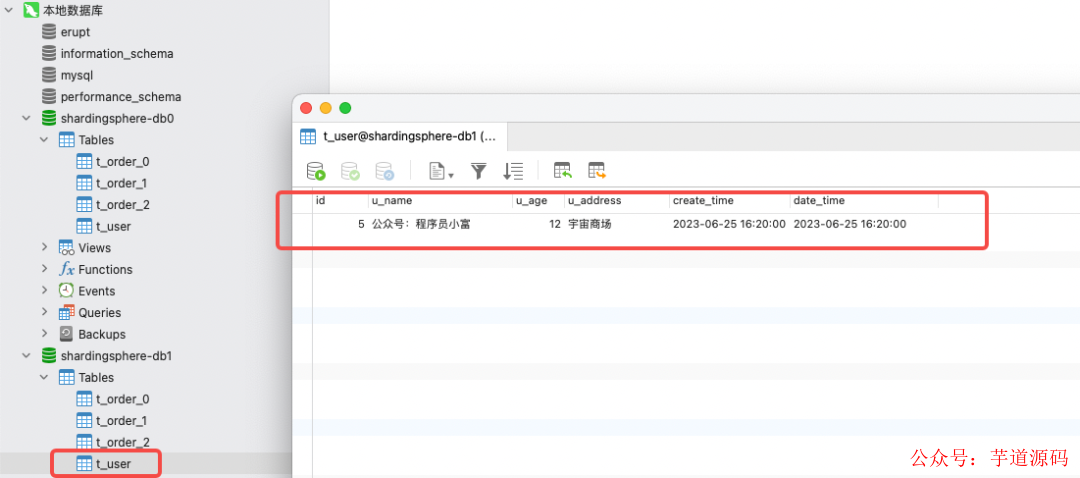
shardingsphere-jdbc 5.x版本移除了原本的默認數據源配置,自動使用了默認數據源的規則,為驗證我多增加了數據源,嘗試性的調整了db2、db0、db1的順序,再次插入數據,這回記錄被插在了 db2 庫,反復試驗初步得出結論。
未分片的表默認會使用第一個數據源作為默認數據源,也就是 datasource.names 第一個。
spring:
shardingsphere:
#數據源配置
datasource:
#數據源名稱,多數據源以逗號分隔
names:db2,db1,db0
總結
本期我們對 shardingsphere 做了簡單的介紹,并使用 yml 和 Java編碼的方式快速實現了分庫分表功能。
-
數據庫
+關注
關注
7文章
3816瀏覽量
64472 -
架構
+關注
關注
1文章
515瀏覽量
25492 -
MySQL
+關注
關注
1文章
816瀏覽量
26613 -
SpringBoot
+關注
關注
0文章
173瀏覽量
183
原文標題:SpringBoot 2 種方式快速實現分庫分表,輕松拿捏!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
談分布式數據庫中間件之分庫分表
你們知道為什么要分庫分表嗎
優化MySQL數據庫中樸實無華的分表和花里胡哨的分庫
分庫分表的21條法則速來碼住(上)
分庫分表的21條法則速來碼住(下)
SpringBoot 連接ElasticSearch的使用方式
分庫分表后復雜查詢的應對之道:基于DTS實時性ES寬表構建技術實踐





 工商網監
工商網監
評論