") JVM內(nèi)存大對象監(jiān)控和優(yōu)化問題描述及解決辦法
JVM內(nèi)存大對象監(jiān)控和優(yōu)化問題描述及解決辦法
服務(wù)器內(nèi)存問題是影響應用程序性能和穩(wěn)定性的重要因素之一,需要及時排查和優(yōu)化。本文介紹了某核心服務(wù)內(nèi)存問題排查與解決過程。首先在JVM與大對象優(yōu)化上進行了有效的實踐,其次在故障轉(zhuǎn)移與大對象監(jiān)控上提出了可靠的落地方案。最后,總結(jié)了內(nèi)存優(yōu)化需要考慮的其他問題。
一、問題描述
音樂業(yè)務(wù)中,core服務(wù)主要提供歌曲、歌手等元數(shù)據(jù)與用戶資產(chǎn)查詢。隨著元數(shù)據(jù)與用戶資產(chǎn)查詢量的增長,一些JVM內(nèi)存問題也逐漸顯露,例如GC頻繁、耗時長,在高峰期RPC調(diào)用超時等問題,導致業(yè)務(wù)核心功能受損。
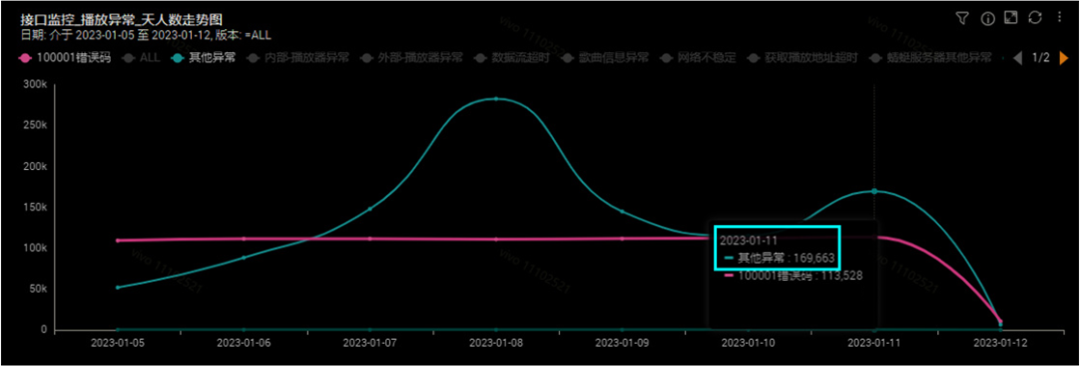
圖1 業(yè)務(wù)異常數(shù)量變化
二、分析與解決
通過對日志,機器CPU、內(nèi)存等監(jiān)控數(shù)據(jù)分析發(fā)現(xiàn):
YGC平均每分鐘次數(shù)12次,峰值為24次,平均每次的耗時在327毫秒。FGC平均每10分鐘0.08次,峰值1次,平均耗時30秒。可以看到GC問題較為突出。
在問題期間,機器的CPU并沒有明顯的變化,但是堆內(nèi)存出現(xiàn)較大異常。圖2,黃色圓圈處,內(nèi)存使用急速上升,F(xiàn)GC變的頻繁,釋放的內(nèi)存越來越少。
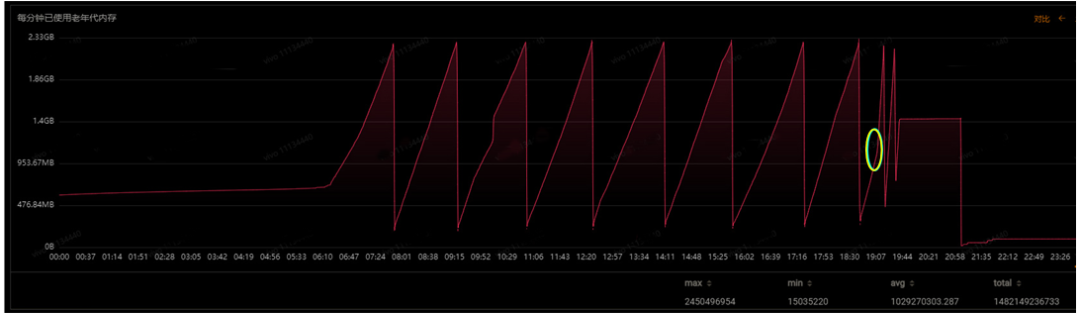
圖2 老年代內(nèi)存使用異常
因此,我們認為業(yè)務(wù)功能異常是機器的內(nèi)存問題導致的,需要對服務(wù)的內(nèi)存做一次專項優(yōu)化。
步驟1 JVM優(yōu)化
以下是默認的JVM參數(shù):
-Xms4096M-Xmx4096M-Xmn1024M-XX:MetaspaceSize=256M-Djava.security.egd=file:/dev/./urandom-XX:+HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=/data/{runuser}/logs/other
如果不指定垃圾收集器,那么JDK 8默認采用的是Parallel Scavenge(新生代) +Parallel Old(老年代),這種組合在多核CPU上充分利用多線程并行的優(yōu)勢,提高垃圾回收的效率和吞吐量。但是,由于采用多線程并行方式,會造成一定的停頓時間,不適合對響應時間要求較高的應用程序。然而,core這類的服務(wù)特點是對象數(shù)量多,生命周期短。在系統(tǒng)特點上,吞吐量較低,要求時延低。因此,默認的JVM參數(shù)并不適合core服務(wù)。
根據(jù)業(yè)務(wù)的特點和多次對照實驗,選擇了如下參數(shù)進行JVM優(yōu)化(4核8G的機器)。該參數(shù)將young區(qū)設(shè)為原來的1.5倍,減少了進入老年代的對象數(shù)量。將垃圾回收器換成ParNew+CMS,可以減少YGC的次數(shù),降低停頓時間。此外還開啟了CMSScavengeBeforeRemark,在CMS的重新標記階段進行一次YGC,以減少重新標記的時間。
-Xms4096M-Xmx4096M-Xmn1536M-XX:MetaspaceSize=256M-XX:+UseConcMarkSweepGC-XX:+CMSScavengeBeforeRemark-Djava.security.egd=file:/dev/./urandom-XX:+HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=/data/{runuser}/logs/other
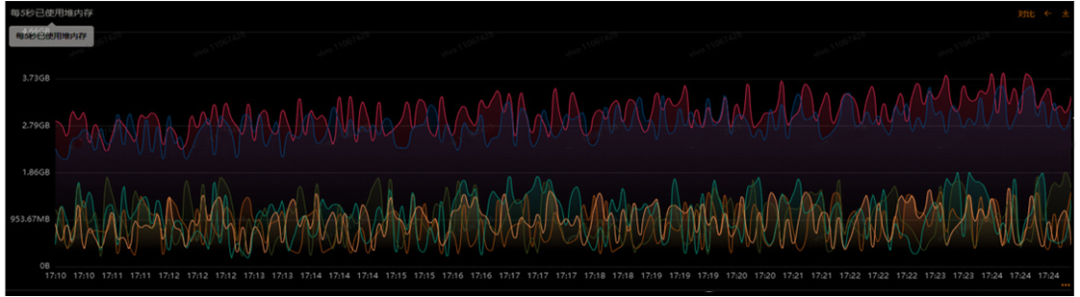
圖3 JVM優(yōu)化前后的堆內(nèi)存對比
優(yōu)化后效果如圖3,堆內(nèi)存的使用明顯降低,但是Dubbo超時仍然存在。
我們推斷,在業(yè)務(wù)高峰期,該節(jié)點出現(xiàn)了大對象晉升到了老年代,導致內(nèi)存使用迅速上升,并且大對象沒有被及時回收。那如何找到這個大對象及其產(chǎn)生的原因呢?為了降低問題排查期間業(yè)務(wù)的損失,提出了臨時的故障轉(zhuǎn)移策略,盡量降低異常數(shù)量。
步驟2 故障轉(zhuǎn)移策略
在api服務(wù)調(diào)用core服務(wù)出現(xiàn)異常時,將出現(xiàn)異常的機器ip上報給監(jiān)控平臺。然后利用監(jiān)控平臺的統(tǒng)計與告警能力,配置相應的告警規(guī)則與回調(diào)函數(shù)。當異常觸發(fā)告警,通過配置的回調(diào)函數(shù)將告警ip傳遞給api服務(wù),此時api服務(wù)可以將core服務(wù)下的該ip對應的機器視為“故障”,進而通過自定義的故障轉(zhuǎn)移策略(實現(xiàn)Dubbo的AbstractLoadBalance抽象類,并且配置在項目),自動將該ip從提供者集群中剔除,從而達到不去調(diào)用問題機器。圖 4 是整個措施的流程。在該措施上線前,每當有機器內(nèi)存告警時,將會人工重啟該機器。
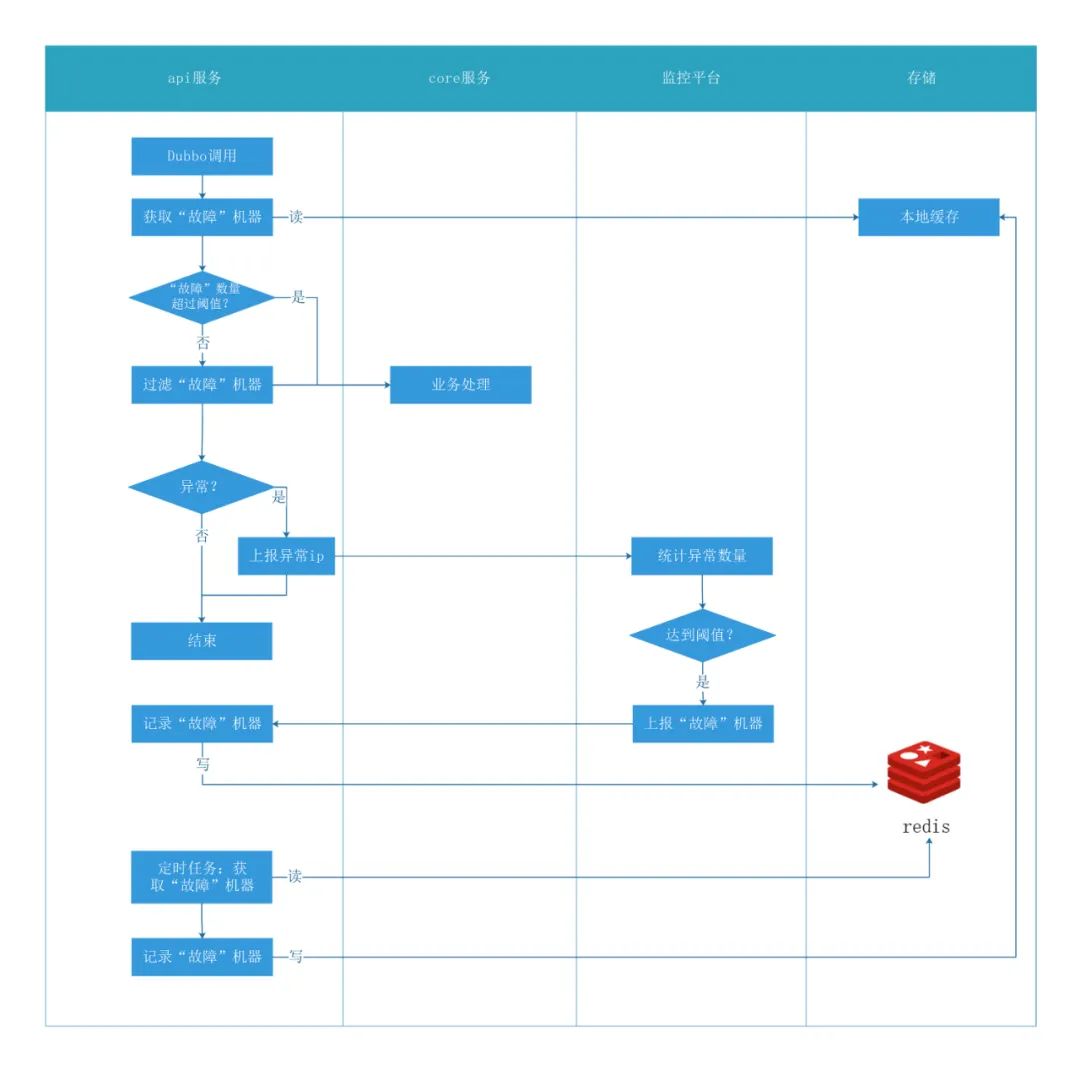
圖4 故障轉(zhuǎn)移策略
步驟3 大對象優(yōu)化
大對象占用了較多的內(nèi)存,導致內(nèi)存空間無法被有效利用,甚至造成OOM(Out Of Memory)異常。在優(yōu)化過程中,先是查看了異常期間的線程信息,然后對堆內(nèi)存進行了分析,最終確定了大對象身份以及產(chǎn)生的接口。
(1) Dump Stack 查看線程
從監(jiān)控平臺上Dump Stack文件,發(fā)現(xiàn)一定數(shù)量的如下線程調(diào)用。
Thread 5612: (state = IN_JAVA) - org.apache.dubbo.remoting.exchange.codec.ExchangeCodec.encodeResponse(org.apache.dubbo.remoting.Channel, org.apache.dubbo.remoting.buffer.ChannelBuffer, org.apache.dubbo.remoting.exchange.Response) @bci=11, line=282 (Compiled frame; information may be imprecise) - org.apache.dubbo.remoting.exchange.codec.ExchangeCodec.encode(org.apache.dubbo.remoting.Channel, org.apache.dubbo.remoting.buffer.ChannelBuffer, java.lang.Object) @bci=34, line=73 (Compiled frame) - org.apache.dubbo.rpc.protocol.dubbo.DubboCountCodec.encode(org.apache.dubbo.remoting.Channel, org.apache.dubbo.remoting.buffer.ChannelBuffer, java.lang.Object) @bci=7, line=40 (Compiled frame) - org.apache.dubbo.remoting.transport.netty4.NettyCodecAdapter$InternalEncoder.encode(io.netty.channel.ChannelHandlerContext, java.lang.Object, io.netty.buffer.ByteBuf) @bci=51, line=69 (Compiled frame) - io.netty.handler.codec.MessageToByteEncoder.write(io.netty.channel.ChannelHandlerContext, java.lang.Object, io.netty.channel.ChannelPromise) @bci=33, line=107 (Compiled frame) - io.netty.channel.AbstractChannelHandlerContext.invokeWrite0(java.lang.Object, io.netty.channel.ChannelPromise) @bci=10, line=717 (Compiled frame) - io.netty.channel.AbstractChannelHandlerContext.invokeWrite(java.lang.Object, io.netty.channel.ChannelPromise) @bci=10, line=709 (Compiled frame) ...
state = IN_JAVA 表示Java虛擬機正在執(zhí)行Java程序。從線程調(diào)用信息可以看到,Dubbo正在調(diào)用Netty,將輸出寫入到緩沖區(qū)。此時的響應可能是一個大對象,因而在對響應進行編碼、寫緩沖區(qū)時,需要耗費較長的時間,導致抓取到的此類線程較多。另外耗時長,也即是大對象存活時間長,導致full gc 釋放的內(nèi)存越來越小,空閑的堆內(nèi)存變小,這又會加劇full gc 次數(shù)。
這一系列的連鎖反應與圖2相吻合,那么接下來的任務(wù)就是找到這個大對象。
(2)Dump Heap 查看內(nèi)存
對core服務(wù)的堆內(nèi)存進行了多次查看,其中比較有代表性的一次快照的大對象列表如下,
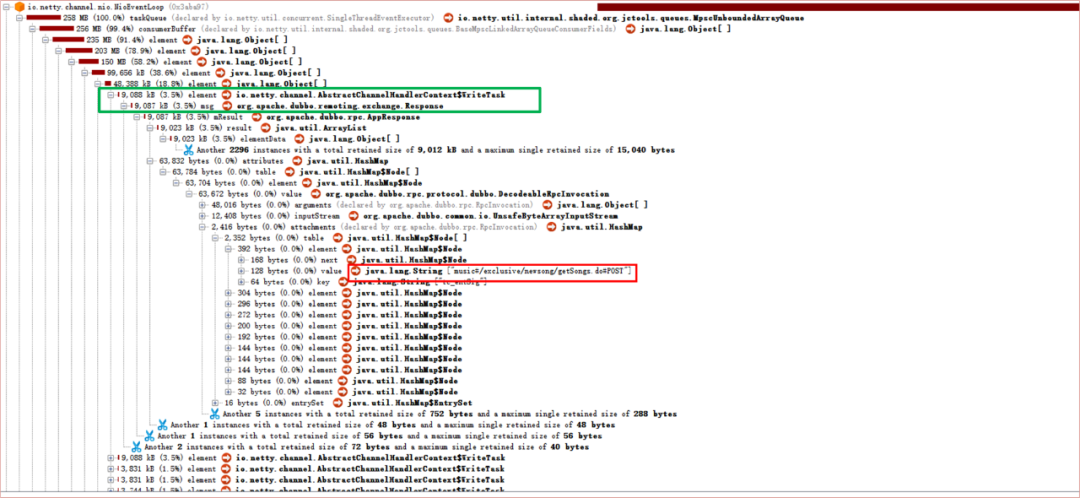
圖5 core服務(wù)的堆內(nèi)存快照
整個Netty的taskQueue有258MB。并且從圖中綠色方框處可以發(fā)現(xiàn),單個的Response竟達到了9M,紅色方框處,顯示了調(diào)用方的服務(wù)名以及URI。
進一步排查,發(fā)現(xiàn)該接口會通過core服務(wù)查詢大量信息,至此基本排查清楚了大對象的身份以及產(chǎn)生原因。
(3)優(yōu)化結(jié)果
在對接口進行優(yōu)化后,整個core服務(wù)也出現(xiàn)了非常明顯的改進。YGC全天總次數(shù)降低了76.5%,高峰期累計耗時降低了75.5%。FGC三天才會發(fā)生一次,并且高峰期累計耗時降低了90.1%。
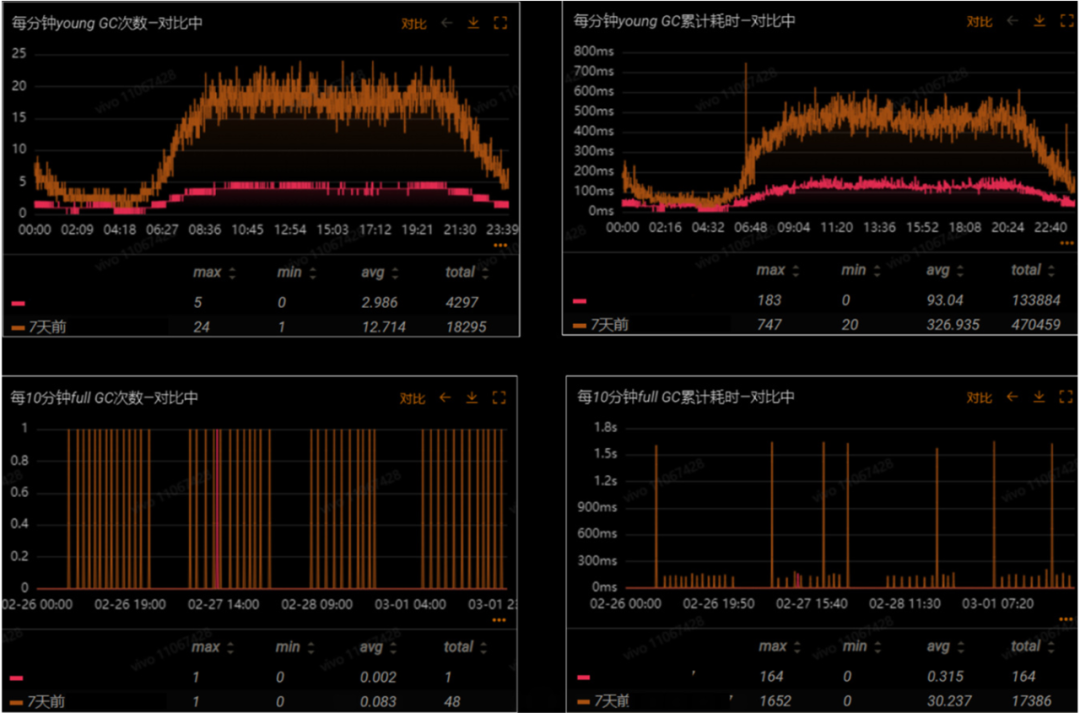
圖6大對象優(yōu)化后的core服務(wù)GC情況
盡管優(yōu)化后,因內(nèi)部異常導致獲取核心業(yè)務(wù)失敗的異常請求數(shù)顯著減少,但是依然存在。為了找到最后這一點異常產(chǎn)生的原因,我們打算對core服務(wù)內(nèi)存中的對象大小進行監(jiān)控。
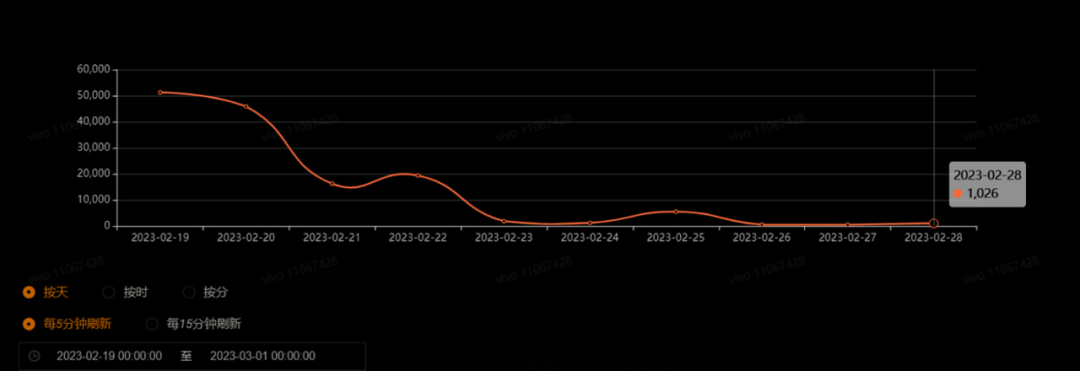
圖7系統(tǒng)內(nèi)部異常導致核心業(yè)務(wù)失敗的異常請求數(shù)
步驟4 無侵入式內(nèi)存對象監(jiān)控
Debug Dubbo 源碼的過程中,發(fā)現(xiàn)在網(wǎng)絡(luò)層,Dubbo通過encodeResponse方法對響應進行編碼并寫入緩沖區(qū),通過checkPayload方法去檢查響應的大小,當超過payload時,會拋出ExceedPayloadLimitException異常。在外層對異常進行了捕獲,重置buffer位置,而且如果是ExceedPayloadLimitException異常,重新發(fā)送一個空響應,這里需要注意,空響應沒有原始的響應結(jié)果信息,源碼如下。
//org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encodeResponse protected void encodeResponse(Channel channel, ChannelBuffer buffer, Response res) throws IOException { //...省略部分代碼 try { //1、檢查響應大小是否超過 payload,如果超過,則拋出ExceedPayloadLimitException異常 checkPayload(channel, len); } catch (Throwable t) { //2、重置buffer buffer.writerIndex(savedWriteIndex); //3、捕獲異常后,生成一個新的空響應 Response r = new Response(res.getId(), res.getVersion()); r.setStatus(Response.BAD_RESPONSE); //4、ExceedPayloadLimitException異常,將生成的空響應重新發(fā)送一遍 if (t instanceof ExceedPayloadLimitException) { r.setErrorMessage(t.getMessage()); channel.send(r); return; } } } //org.apache.dubbo.remoting.transport.AbstractCodec#checkPayload protected static void checkPayload(Channel channel, long size) throws IOException { int payload = getPayload(channel); boolean overPayload = isOverPayload(payload, size); if (overPayload) { ExceedPayloadLimitException e = new ExceedPayloadLimitException("Data length too large: " + size + ", max payload: " + payload + ", channel: " + channel); logger.error(e); throw e; } }
受此啟發(fā),自定義了編解碼類(實現(xiàn)org.apache.dubbo.remoting.Codec2接口,并且配置在項目),去監(jiān)控超出閾值的對象,并打印請求的詳細信息,方便排查問題。在具體實現(xiàn)中,如果特意去計算每個對象的大小,那么勢必是對服務(wù)性能造成影響。經(jīng)過分析,采取了和checkPayload一樣的方式,根據(jù)編碼前后buffer的writerIndex位置去判斷有沒有超過設(shè)定的閾值。代碼如下。
/**
* 自定義dubbo編碼類
**/
public class MusicDubboCountCodec implements Codec2 {
/**
* 異常響應池:緩存超過payload大小的responseId
*/
private static Cache EXCEED_PAYLOAD_LIMIT_CACHE = Caffeine.newBuilder()
// 緩存總條數(shù)
.maximumSize(100)
// 過期時間
.expireAfterWrite(300, TimeUnit.SECONDS)
// 將value設(shè)置為軟引用,在OOM前直接淘汰
.softValues()
.build();
@Override
public void encode(Channel channel, ChannelBuffer buffer, Object message) throws IOException {
//1、記錄數(shù)據(jù)編碼前的buffer位置
int writeBefore = null == buffer ? 0 : buffer.writerIndex();
//2、調(diào)用原始的編碼方法
dubboCountCodec.encode(channel, buffer, message);
//3、檢查&記錄超過payload的信息
checkOverPayload(message);
//4、計算對象長度
int writeAfter = null == buffer ? 0 : buffer.writerIndex();
int length = writeAfter - writeBefore;
//5、超過告警閾值,進行日志打印處理
warningLengthTooLong(length, message);
}
//校驗response是否超過payload,超過了,緩存id
private void checkOverPayload(Object message){
if(!(message instanceof Response)){
return;
}
Response response = (Response) message;
//3.1、新的發(fā)送過程:通過狀態(tài)碼BAD_RESPONSE與錯誤信息識別出空響應,并記錄響應id
if(Response.BAD_RESPONSE == response.getStatus() && StrUtil.contains(response.getErrorMessage(), OVER_PAYLOAD_ERROR_MESSAGE)){
EXCEED_PAYLOAD_LIMIT_CACHE.put(response.getId(), response.getErrorMessage());
return;
}
//3.2、原先的發(fā)送過程:通過異常池識別出超過payload的響應,打印有用的信息
if(Response.OK == response.getStatus() && EXCEED_PAYLOAD_LIMIT_CACHE.getIfPresent(response.getId()) != null){
String responseMessage = getResponseMessage(response);
log.warn("dubbo序列化對象大小超過payload,errorMsg is {},response is {}", EXCEED_PAYLOAD_LIMIT_CACHE.getIfPresent(response.getId()),responseMessage);
}
}
}
在上文中提到,當捕獲到超過payload的異常時,會重新生成空響應,導致失去了原始的響應結(jié)果,此時再去打印日志,是無法獲取到調(diào)用方法和入?yún)⒌模莈ncodeResponse方法步驟4中,重新發(fā)送這個Response,給了我們機會去獲取到想要的信息,因為重新發(fā)送意味著會再去走一遍自定義的編碼類。
假設(shè)有一個超出payload的請求,執(zhí)行到自定編碼類encode方法的步驟2(Dubbo源碼中的編碼方法),在這里會調(diào)用encodeResponse方法重置buffer,發(fā)送新的空響應。
(1)當這個新的空響應再次進入自定義encode方法,執(zhí)行 checkOverPayload方法的步驟3.1時,就會記錄異常響應的id到本地緩存。由于在encodeResponse中buffer被重置,無法計算對象的大小,所以步驟4、5不會起到實際作用,就此結(jié)束新的發(fā)送過程。
(2)原先的發(fā)送過程回到步驟2 繼續(xù)執(zhí)行,到了步驟3.2 時,發(fā)現(xiàn)本地緩存的異常池中有當前的響應id,這時就可以打印調(diào)用信息了。
綜上,對于大小在告警閾值和payload之間的對象,由于響應信息成功寫入了buffer,可以直接進行大小判斷,并且打印響應中的關(guān)鍵信息;對于超過payload的對象,在重新發(fā)送中記錄異常響應id到本地,在原始發(fā)送過程中訪問異常id池識別是否是異常響應,進行關(guān)鍵信息打印。
在監(jiān)控措施上線后,通過日志很快速的發(fā)現(xiàn)了一部分產(chǎn)生大對象的接口,當前也正在根據(jù)接口特點做針對性優(yōu)化。
三、總結(jié)
在對服務(wù)JVM內(nèi)存進行調(diào)優(yōu)時,要充分利用日志、監(jiān)控工具、堆棧信息等,分析與定位問題。盡量降低問題排查期間的業(yè)務(wù)損失,引入對象監(jiān)控手段也不能影響現(xiàn)有業(yè)務(wù)。除此之外,還可以在定時任務(wù)、代碼重構(gòu)、緩存等方面進行優(yōu)化。優(yōu)化服務(wù)內(nèi)存不僅僅是JVM調(diào)參,而是一個全方面的持續(xù)過程。
審核編輯:劉清
-
編碼器
+關(guān)注
關(guān)注
45文章
3645瀏覽量
134569 -
RPC
+關(guān)注
關(guān)注
0文章
111瀏覽量
11540 -
cms
+關(guān)注
關(guān)注
0文章
60瀏覽量
10981 -
JVM
+關(guān)注
關(guān)注
0文章
158瀏覽量
12235 -
回調(diào)函數(shù)
+關(guān)注
關(guān)注
0文章
87瀏覽量
11566
原文標題:JVM 內(nèi)存大對象監(jiān)控和優(yōu)化實踐
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
常見墊圈故障及解決辦法 防漏墊圈的設(shè)計與應用
雷達探測器常見故障及解決辦法
PCBA板常見故障及解決辦法
谷景科普電感磁芯發(fā)熱的解決辦法
常見RAM內(nèi)存故障及解決辦法
溫控器常見故障及解決辦法
常見MCU故障及解決辦法
常見元器件故障及解決辦法
談JVM xmx, xms等內(nèi)存相關(guān)參數(shù)合理性設(shè)置
海外大帶寬服務(wù)器連接失敗解決辦法
從原理聊JVM(一):染色標記和垃圾回收算法
聊聊JVM如何優(yōu)化
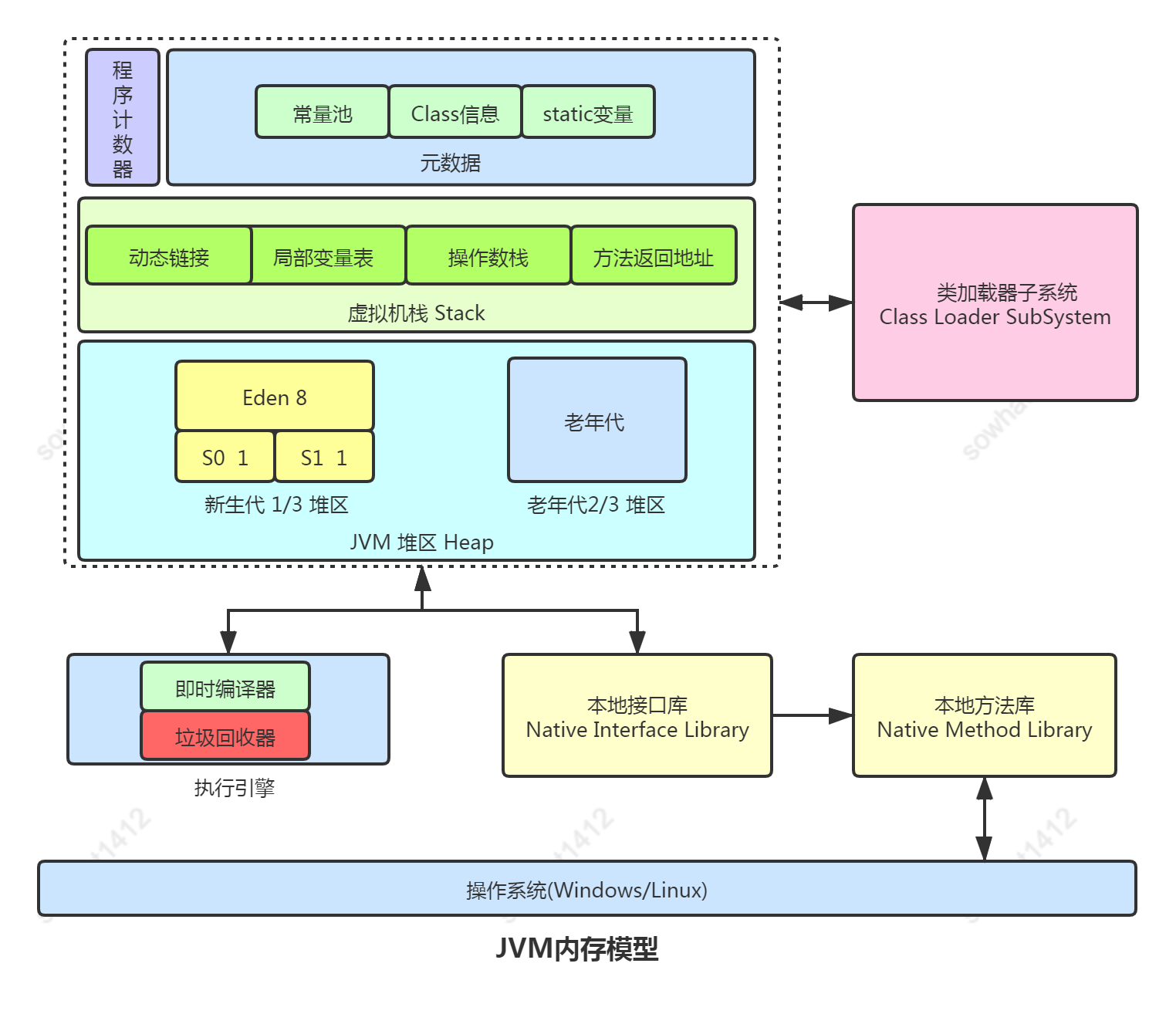
深入理解Java 8內(nèi)存管理機制及故障排查實戰(zhàn)指南
大模型訓練loss突刺原因和解決辦法





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論