") RPP「六邊形戰(zhàn)士」處理器:融合NPU與GPU優(yōu)勢(shì),兼具高效與實(shí)時(shí)性的AI新星
RPP「六邊形戰(zhàn)士」處理器:融合NPU與GPU優(yōu)勢(shì),兼具高效與實(shí)時(shí)性的AI新星
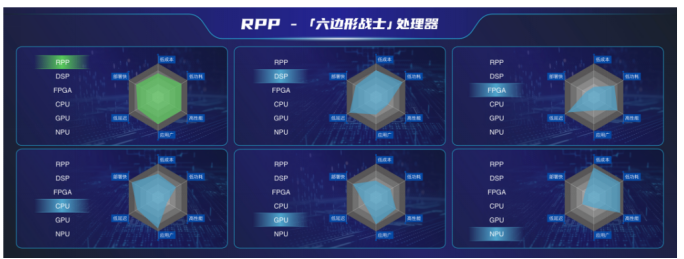
在科技江湖中,處理器家族群英薈萃,各展神通,從DSP到NPU再到GPGPU,每款處理器優(yōu)劣各異,各有所長(zhǎng)。正是這些處理器的優(yōu)點(diǎn),使它們?cè)谔囟ǖ氖袌?chǎng)領(lǐng)域中占有一席之地;也是它們的缺點(diǎn),限制了它們進(jìn)入其他市場(chǎng)領(lǐng)域發(fā)展。然而,在這個(gè)競(jìng)爭(zhēng)激烈的市場(chǎng)中,有一款處理器被譽(yù)為“六邊形戰(zhàn)士處理器”,它就是RPP,憑借其獨(dú)特的底層架構(gòu),
RPP成功實(shí)現(xiàn)了NPU的高效率和GPU的高通用性相結(jié)合,在AI市場(chǎng)中游刃有余,成為了AI領(lǐng)域的后起之秀。
這種
結(jié)合令RPP具有廣泛的應(yīng)用場(chǎng)景和高效的處理能力,使其在市場(chǎng)上具有強(qiáng)大的競(jìng)爭(zhēng)力。

(DSP & RPP 性能對(duì)比)
接下來,讓我們深入分析一下RPP是如何成為「六邊形戰(zhàn)士」處理器的。首先,我們來回顧一下DSP(數(shù)字信號(hào)處理器)的獨(dú)特優(yōu)勢(shì)——低延遲。這一特性,使得DSP在4G、5G無線通信、雷達(dá)信號(hào)處理等領(lǐng)域脫穎而出,成為不可或缺的關(guān)鍵技術(shù)。在需要即時(shí)、高效信號(hào)分析與處理的應(yīng)用場(chǎng)景中,DSP無疑是最佳的選擇。然而,正如硬幣的兩面一樣,DSP也有其局限性,尤其在高性能人工智能(AI)領(lǐng)域。
雖然DSP在特定領(lǐng)域表現(xiàn)出色,但對(duì)于涉及大規(guī)模并行計(jì)算和復(fù)雜矩陣運(yùn)算的AI任務(wù),它可能會(huì)顯露出性能瓶頸。
AI任務(wù)通常要求高度優(yōu)化的計(jì)算能力,而這恰恰是DSP的傳統(tǒng)應(yīng)用所未涉及的。
此外,DSP的匯編語言暴露性使得編程變得困難,軟件難以遷移和迭代。

(NPU& RPP 性能對(duì)比)正因如此,專門的處理器類型如NPU(神經(jīng)網(wǎng)絡(luò)處理器)和GPU(圖形處理器)應(yīng)運(yùn)而生,以滿足AI領(lǐng)域的需求。NPU專注于高效執(zhí)行神經(jīng)網(wǎng)絡(luò)計(jì)算,而GPU則以其卓越的并行處理能力,成為訓(xùn)練和推斷復(fù)雜神經(jīng)網(wǎng)絡(luò)模型的不二之選。這種針對(duì)性的架構(gòu)設(shè)計(jì)使得它們能夠在AI領(lǐng)域展現(xiàn)出更卓越的性能。任何技術(shù)都有其兩面性一樣,GPU和NPU也不例外。
它們?cè)谀承┓矫婵赡艽嬖诰窒扌裕沟盟鼈儫o法廣泛地應(yīng)用于所有領(lǐng)域。
例如,盡管NPU優(yōu)勢(shì)非常明顯,低功耗,低成本,高性能都達(dá)到極致。然而,NPU的缺點(diǎn)也是顯而易見的,首先,
部署相對(duì)較慢
,用戶需要使用NPU特有的SDK接口將其訓(xùn)練好的模型部署到芯片上,這需要用戶重新學(xué)習(xí)NPU的編程語言,大大增加了部署時(shí)間(這與GPU不同,GPU使用通用的CUDA語言進(jìn)行編程)。其次,
NPU屬于定制化的硬件,這在一定程度上限制了其適用范圍。
盡管在
AI領(lǐng)域具備廣泛的應(yīng)用前景,但在其他領(lǐng)域如圖像處理、科學(xué)計(jì)算以及信號(hào)處理等方面,其應(yīng)用可能會(huì)受到限制。此外,即便在AI領(lǐng)域,隨著新的AI算子不斷涌現(xiàn),很多神經(jīng)網(wǎng)絡(luò)模型可能難以在既有的定制化NPU上得到充分支持。這種定制化的特性使得NPU在處理特定類型的任務(wù)時(shí)能夠?qū)崿F(xiàn)卓越性能,但同時(shí)也可能在其他領(lǐng)域的應(yīng)用上顯得相對(duì)不足。由于技術(shù)的快速發(fā)展和多樣化需求,
NPU在適應(yīng)不斷變化的場(chǎng)景時(shí)可能面臨一些挑戰(zhàn)。

(GPU& RPP 性能對(duì)比)下面來說一下GPU,盡管在功耗、成本和性能方面不如NPU,但GPU依然是AI領(lǐng)域使用最多的處理器。
這歸功于GPU強(qiáng)大的CUDA生態(tài)。
CUDA是一種由NVIDIA開發(fā)的并行計(jì)算平臺(tái)和應(yīng)用程序編程接口,它讓開發(fā)者能夠使用NVIDIA的GPU進(jìn)行高性能計(jì)算。正是這種強(qiáng)大的生態(tài),使得GPU在AI領(lǐng)域占據(jù)了主導(dǎo)地位,可以廣泛應(yīng)用。然而,需要指出的是,
GPU的處理時(shí)延通常較大,這使得它不適用于實(shí)時(shí)操作系統(tǒng),
而僅限于在Linux或Windows操作系統(tǒng)上使用。正因如此,GPU在無線通信、雷達(dá)處理
等信號(hào)處理領(lǐng)域的應(yīng)用受到了一定的限制。GPU在AI領(lǐng)域的主導(dǎo)地位源于其卓越的并行計(jì)算能力和廣泛支持的軟硬件生態(tài)系統(tǒng)。這種并行計(jì)算能力使得GPU能夠在處理大規(guī)模數(shù)據(jù)和復(fù)雜神經(jīng)網(wǎng)絡(luò)模型時(shí)發(fā)揮優(yōu)勢(shì),從而在訓(xùn)練和推理中取得出色的性能。盡管在功耗和成本方面存在一些局限,但其在性能方面的優(yōu)勢(shì)往往能夠彌補(bǔ)這些不足。不過,在追求GPU強(qiáng)大性能的同時(shí),人們也不能忽視其功耗和成本帶來的挑戰(zhàn)。
特別是在移動(dòng)設(shè)備和嵌入式系統(tǒng)等資源受限的場(chǎng)景中,選擇適當(dāng)?shù)奶幚砥魇且粋€(gè)需要深思熟慮的決策。例如,大模型之所以難以商用化,很大程度上是因?yàn)槠渚薮蟮墓某杀荆?/p>
因此,在性能、功耗和成本之間尋求平衡也變得至關(guān)重要
。

(FPGA& RPP 性能對(duì)比)當(dāng)然,F(xiàn)PGA(現(xiàn)場(chǎng)可編程邏輯門陣列)確實(shí)在某些方面提供了一種獨(dú)特的解決方案,它能夠?qū)崿F(xiàn)高性能和低時(shí)延的操作。不同于一般的中央處理單元(CPU)和圖形處理單元(GPU),F(xiàn)PGA可針對(duì)特定任務(wù)進(jìn)行硬件級(jí)別的編程,從而實(shí)現(xiàn)極高的運(yùn)算速度和響應(yīng)能力。然而,這種高度專用的能力也帶來了一些挑戰(zhàn)和限制。首先,成本是一個(gè)重要的考量因素。由于其專用硬件和定制設(shè)計(jì),
FPGA往往具有相對(duì)較高的成本,這限制了其在大規(guī)模或成本敏感的應(yīng)用場(chǎng)景中的使用。其次,F(xiàn)PGA的部署和配置通常需要專業(yè)知識(shí)和時(shí)間投資。
與通用硬件相比,
FPGA需要獨(dú)特的開發(fā)環(huán)境和工具鏈,這增加了開發(fā)周期和復(fù)雜性。因此,部署速度相對(duì)較慢,這可能會(huì)影響其在快速發(fā)展和變化的市場(chǎng)環(huán)境中的適應(yīng)性。由于這些因素,F(xiàn)PGA主要用于某些特定領(lǐng)域,其中對(duì)高性能和低延遲有嚴(yán)格要求。例如,在信號(hào)處理、數(shù)據(jù)采集、實(shí)時(shí)分析和仿真等其他需要高度可定制和實(shí)時(shí)響應(yīng)的應(yīng)用場(chǎng)景中,F(xiàn)PGA有著不可替代的地位。

當(dāng)然也有一款產(chǎn)品,珠海市芯動(dòng)力科技有限公司自主研發(fā)的全球首款針對(duì)并行計(jì)算設(shè)計(jì)的芯片架構(gòu)-RPP,
則成功實(shí)現(xiàn)了低成本、低功耗、低延時(shí)、高性能、快速部署和廣泛應(yīng)用的全方位平衡。
憑借其獨(dú)特的底層架構(gòu),成功地結(jié)合了NPU的高效率與GPU的高通用性,為AI計(jì)算提供了全新的解決方案。與傳統(tǒng)的NPU和GPU相比,它成功地橋接了兩者之間的性能差距,使得應(yīng)用程序能夠在一個(gè)平臺(tái)上享受到兩者的優(yōu)點(diǎn)。同時(shí)RPP還可以支持實(shí)時(shí)操作系統(tǒng)(RTOS),它具有DSP的低延遲特性,這將大大提高系統(tǒng)的實(shí)時(shí)性和響應(yīng)速度,對(duì)于需要迅速做出決策的應(yīng)用程序來說,這一點(diǎn)至關(guān)重要。RPP的這一特性使其在許多領(lǐng)域都有廣泛的應(yīng)用前景。例如,在自動(dòng)駕駛領(lǐng)域,RPP可以實(shí)時(shí)處理大量的傳感器數(shù)據(jù),迅速做出駕駛決策,提高駕駛安全性。在醫(yī)療領(lǐng)域,RPP可以幫助醫(yī)生進(jìn)行快速的醫(yī)學(xué)圖像處理和數(shù)據(jù)分析,提高診斷的準(zhǔn)確性和效率等等。除此之外,RPP的高效率和低功耗特性還可以應(yīng)用大數(shù)據(jù)分析、工業(yè)自動(dòng)化、泛安防等領(lǐng)域。它的通用性使其能夠適應(yīng)各種不同的應(yīng)用場(chǎng)景,從而實(shí)現(xiàn)了高度的可移植性和靈活性。RPP架構(gòu)與其他產(chǎn)品相比,堪稱「六邊形戰(zhàn)士」。相較于CPU、GPU、DSP、NPU、FPGA這些產(chǎn)品,它們某些領(lǐng)域存在明顯劣勢(shì),而
RPP則成功實(shí)現(xiàn)了低成本、低功耗、低延時(shí)、高性能、快速部署和廣泛應(yīng)用的全方位平衡。
RPP架構(gòu)具備通用性和高效性,
能夠幫助人工智能用戶以最短的時(shí)間實(shí)現(xiàn)產(chǎn)品Time to Market
。它在自動(dòng)駕駛、醫(yī)療、大數(shù)據(jù)分析、工業(yè)自動(dòng)化、泛安防等領(lǐng)域具有廣泛的應(yīng)用前景,為AI計(jì)算提供了全新的解決方案。隨著科技的不斷進(jìn)步和發(fā)展,RPP將在更多領(lǐng)域展現(xiàn)出其強(qiáng)大的應(yīng)用潛力,為推動(dòng)科技發(fā)展和提升社會(huì)效益做出更大的貢獻(xiàn)。
審核編輯 黃宇
-
處理器
+關(guān)注
關(guān)注
68文章
19265瀏覽量
229673 -
FPGA
+關(guān)注
關(guān)注
1629文章
21729瀏覽量
603044 -
gpu
+關(guān)注
關(guān)注
28文章
4729瀏覽量
128901 -
AI
+關(guān)注
關(guān)注
87文章
30763瀏覽量
268907 -
NPU
+關(guān)注
關(guān)注
2文章
282瀏覽量
18585
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
四芯軸壓接PK六邊形壓接:大家覺得傳統(tǒng)六邊形壓接和四芯軸壓接方式哪個(gè)比較好呢?
請(qǐng)問PADS logic頁面連接符圖中的六邊形是什么符號(hào)?
新型有序分布正六邊形小區(qū)結(jié)構(gòu)的設(shè)計(jì)
一種改進(jìn)的六角形砍邊細(xì)分方法
一種基于正六邊形網(wǎng)格的LEACH協(xié)議改進(jìn)
基于正六邊形DGS單元的微帶低通濾波器設(shè)計(jì)方案
正六邊形元胞自動(dòng)機(jī)的行人疏散
六邊形LED燈的制作

堪稱六邊形戰(zhàn)士的aigo國(guó)民好物移動(dòng)固態(tài)硬盤S7 Pro表現(xiàn)如何?

aigo國(guó)民好物移動(dòng)固態(tài)硬盤S7 Pro評(píng)測(cè):移動(dòng)儲(chǔ)存界的六邊形戰(zhàn)士


訊飛翻譯機(jī)4.0發(fā)布,曾在消博會(huì)亮相的黑科技有多厲害?
壓線鉗四邊形與六邊形的特征、性質(zhì)以及應(yīng)用
六邊形壓接 VS B型壓接






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論