 LibTorch-based推理引擎優化內存使用和線程池
LibTorch-based推理引擎優化內存使用和線程池
由喜馬拉伊·莫漢拉爾·喬里瓦爾、皮埃爾-伊夫·阿基蘭蒂、維韋克·戈溫丹、哈米德·舒賈納澤里、安基思·古納帕勒、特里斯坦·賴斯撰寫
大綱大綱
在博客文章中,我們展示了如何優化基于 LibTorrch 的推論引擎,通過減少記憶用量和優化線狀組合戰略來最大限度地增加吞吐量。 我們將這些優化應用到音頻數據模式識別引擎,例如音樂和語音識別或聲波指紋。 本博客文章中討論的優化使得內存使用率減少了50%,推論端到端的延遲度減少了37.5%。 這些優化適用于計算機視覺和自然語言處理。
音頻識別推斷
音頻識別(AR)引擎可用于識別和識別聲音模式。 例如,識別鳥類與錄音的種類和種類,區分音樂與歌手的聲音,或檢測顯示建筑物有異常故障的聲音。 為了識別有興趣的聲音,AR引擎將音頻處理到4個階段:
文件校驗:AR 引擎驗證輸入音頻文件。
采掘:從音頻文件中的每個部分提取特征。
推斷: LibTorrch 使用 CPU 或加速器進行推論。就我們的情況而言,在 Elastic Cloud 計算( EC2) 實例中,使用 Intel 處理器進行推論。
后處理:后處理模式解碼結果并計算用來將推斷輸出轉換成標記或記錄謄本的分數。
在這4個步驟中,推論是計算最密集的,根據模型的復雜性,推論可以占管道處理時間的50%,這意味著現階段的任何優化都會對整個管道產生重大影響。
最優化音頻識別引擎, 使用 conconconconconcondal 貨幣... 并不簡單
輸入數據是一個音頻文件,由幾個短聲段組成(圖1中的S1至S6),輸出數據與按時間戳訂購的標記或記錄謄本相對應。
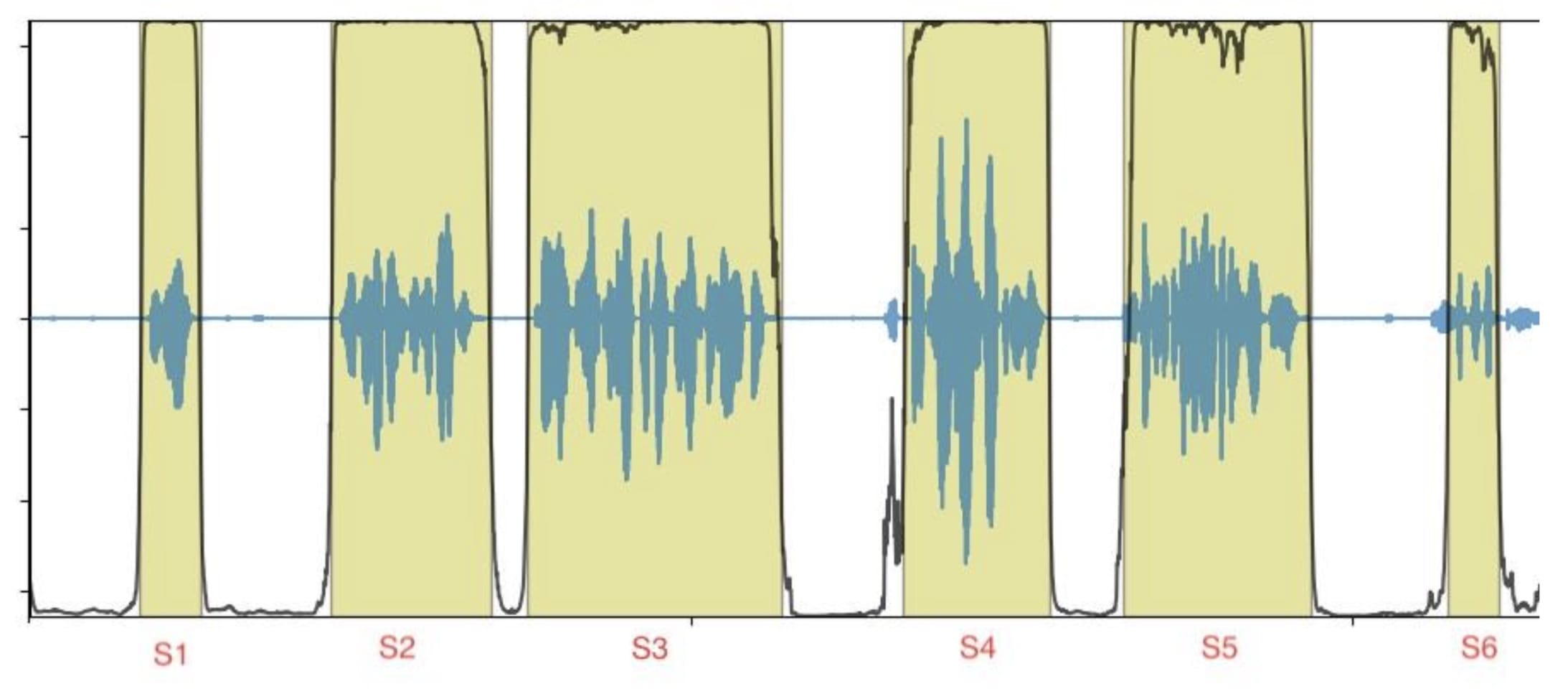
圖1 圖1:有段邊框的音頻文件示例
每一部分可以獨立和不按部就班的方式處理,這樣就有機會同時處理各部分,同時處理各部分,優化總體推論量,最大限度地利用資源。
實例的平行化可以通過多行( phread: std:: threads, OpenMP) 或多處理來實現。 多處理的多行的好處是能夠使用共享的內存。 它使開發者能夠通過共享線條的數據來盡量減少線條上的數據重復; 我們的 AR 模型( 以我們為例) ( AR 模型) 。圖2 圖2此外,記憶力的減少使我們能夠通過增加引擎線的數量,同時運行更多的管道,以便利用我們亞馬遜EC2實例中的所有小CPU(VCPU)。c5.4 寬度我們的情況是,它提供了16 VCPUs。 理論上,我們期望看到我們的AR引擎的硬件利用率更高,輸送量更高。
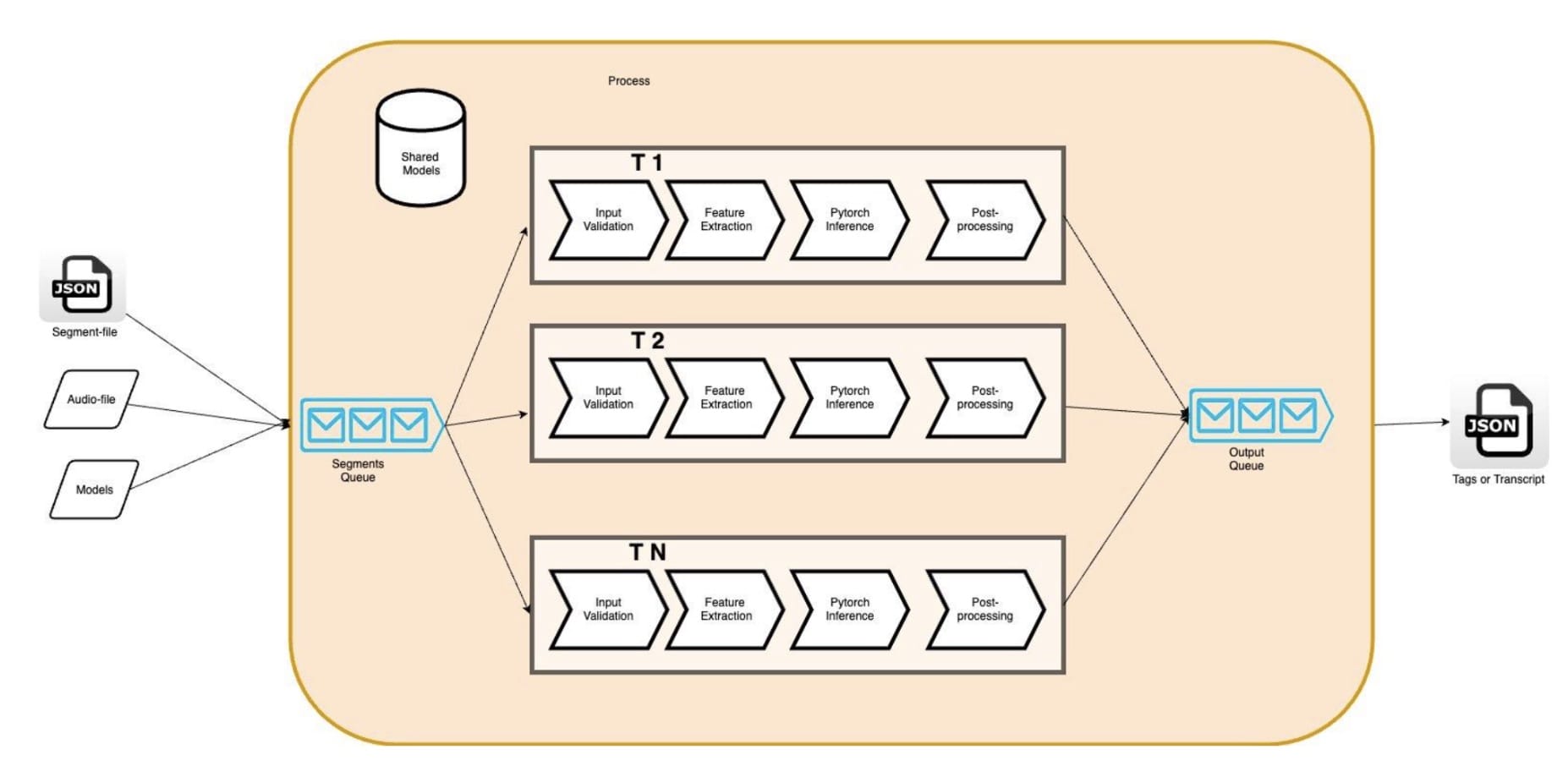
圖2 圖2:多讀 AR 引擎
但是,我們發現這些假設是錯誤的。 事實上,我們發現應用程序的線條數量增加導致每個音頻段端到端的延遲度增加,引擎輸送量減少。 比如,將同值貨幣從1個線條增加到5個線條導致延緩度增加4x,這對減少吞吐量產生了相應的影響。 事實上,衡量標準顯示,在管道內,單是推斷階段的延遲度就比單一線線條基線高出3x。
使用一個剖面文件 我們發現CPU旋轉時間由于CPU 過度訂閱會影響系統和應用性能,我們可能因此增加。 鑒于我們對應用程序多軌執行的控制,我們選擇更深入地潛入堆棧,并找出與 LibTorrch 默認設置的潛在沖突。
深入了解LibTorch的多行及其對同貨幣的影響
LibTorch 平行執行CPU的推斷依據是:全環線串聯集合執行實例是跨業務和內部平行,可視模型的特性選擇。在這兩種情況下,都有可能設定線索數在每個線性孔中 優化潛伏和吞吐量
為了測試LibTorrch的平行默認執行設置是否對我們的推論延緩期產生了反作用,我們用一個35分鐘的音頻文件對一臺16 vCPus機器進行了實驗,將LibTorrch的連接線條常數保持在1(因為我們的模型沒有使用操作間線條庫 ) 。 我們收集了以下數據,如圖3和圖4所示。
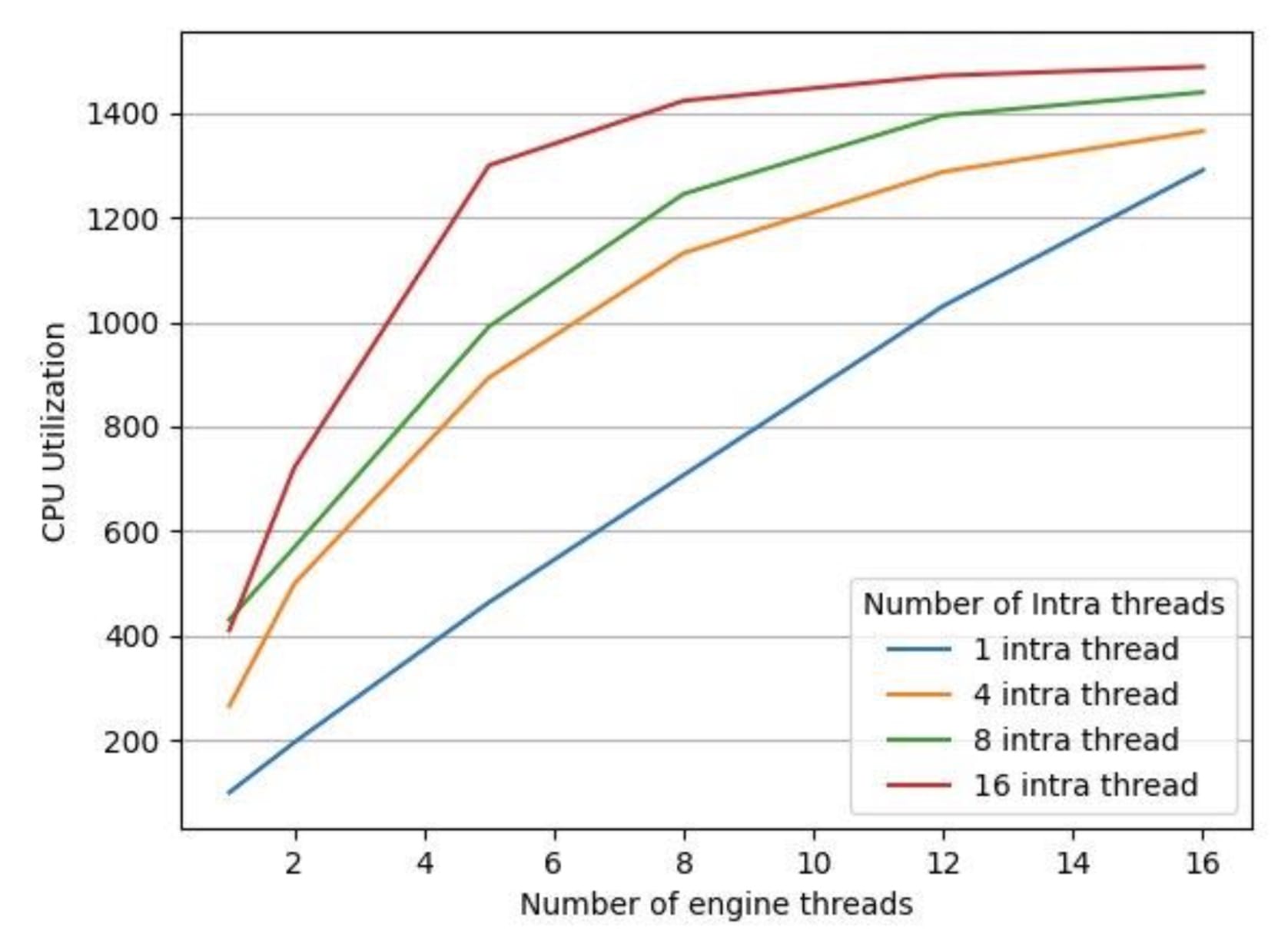
圖3 圖3:不同數量引擎線索的 CPU 利用率
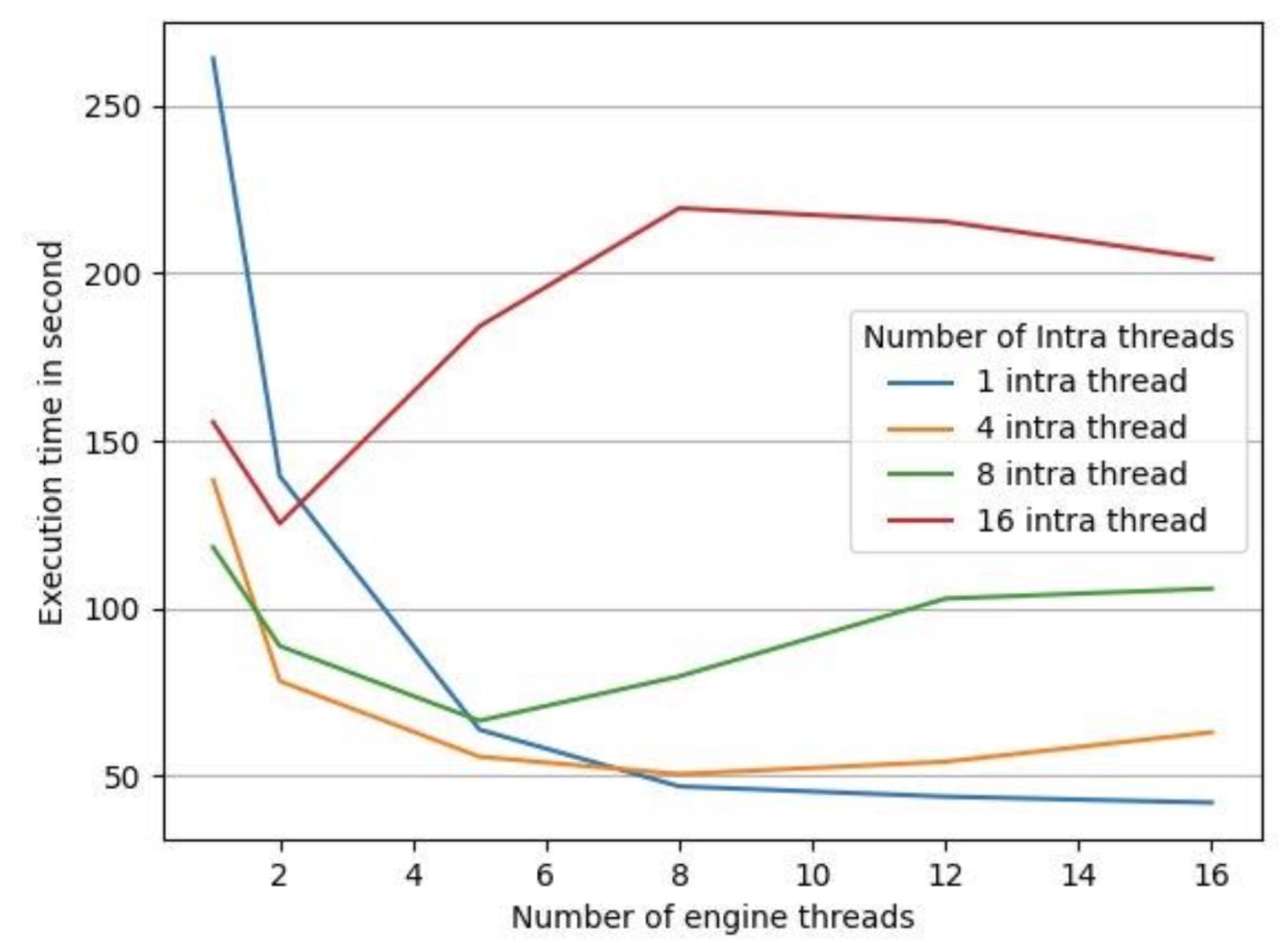
圖4 圖4: 不同數量引擎線索的處理時間
圖4中的執行時間是處理給定音頻文件所有部分的端到端處理時間。 我們有4個不同配置的 LibTorrch 內部線條內部配置為 1 、 4 、 8 、 16, 并且我們將每條線內配置的引擎線數從1 改為 16。 如圖3所示, CPU的利用率隨著所有 LibTorrch 內部配置的引擎線數的增加而增加。 但是, 如圖4所示, CPU 利用率的增加并沒有轉化為較低的執行時間。 我們發現, 在除1個案例之外的所有案例中, 發動機線條數量增加, 執行時間也隨之增加。 例外的是, 整個線條內庫規模增加1 的情況是一個例外。
解決全球線索池問題
與全球線索庫使用過多的線索導致性能退化,并造成訂閱過多問題。全球連托全球聯線人才庫,很難與多過程發動機的性能相匹配。
將LibTorrch全球線條庫拆解, 簡單到將操作內部/操作間平行線線設置為 1, 如下表所示:
:set_num_threads(1) // 禁用內部線條庫 :set_ num_interop_threads(1) 。 / 禁用內部線條庫 。
如圖4所示,當LibTorch全球線條池被禁用時,最低處理時間是測量的。
這一解決方案在若干情況下改善了AR發動機的吞吐量。 然而,在評價長數據集(在負荷測試中超過2小時的Audio文件)時,我們發現發動機的記憶足跡開始逐漸增加。
優化內存使用
我們用兩個小時長的音頻文件對系統進行了負荷測試,發現觀察到的內存增加是多軌LibTorch推論中內存破碎的結果。我們用這個方法解決了這個問題。杰梅洛c,這是一個通用的商場(3)執行,強調避免分散和可縮放的貨幣支持。使用 Jemalloc我們的峰值內存使用率平均下降了34%,平均內存使用率下降了53%。
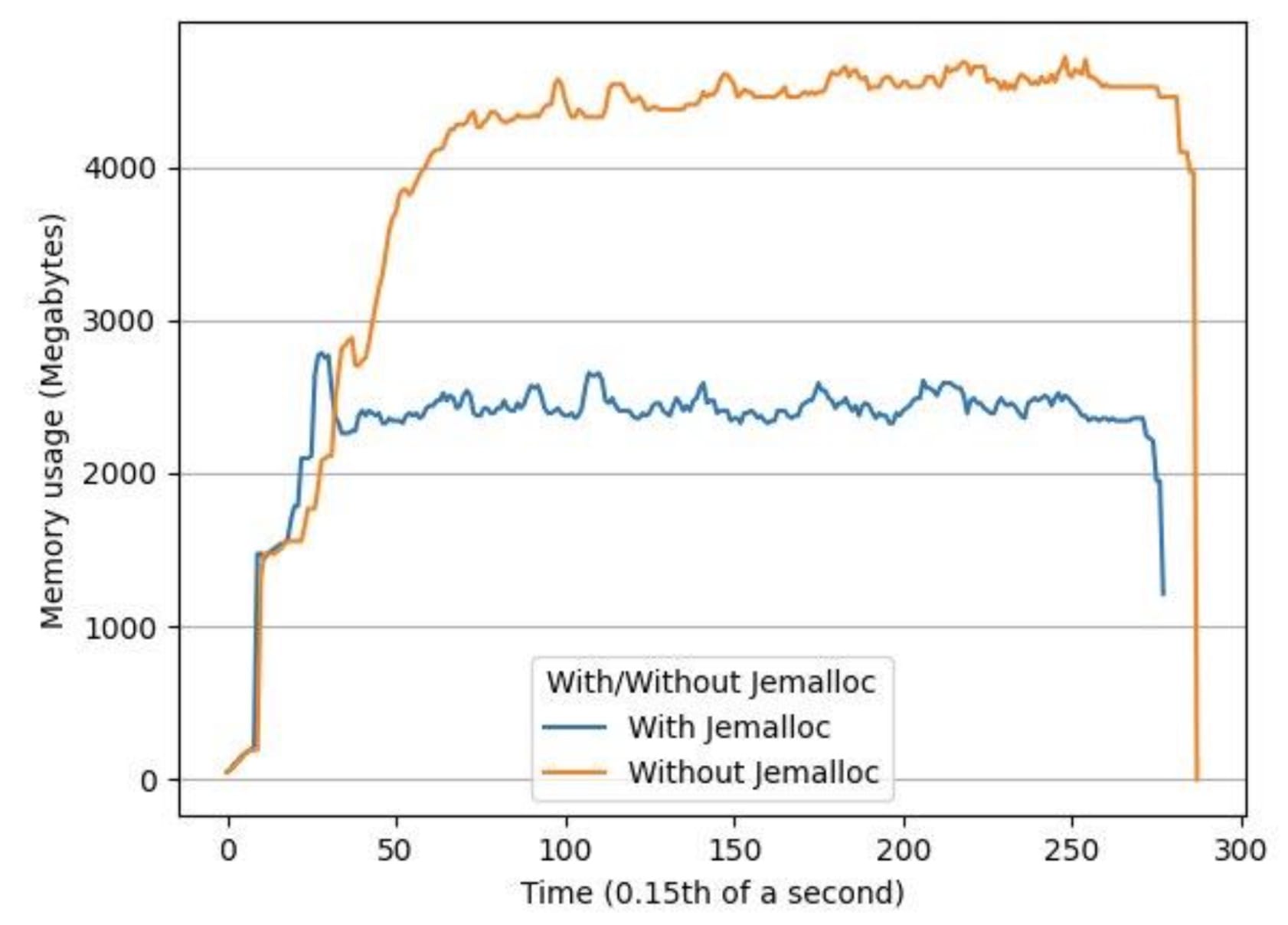
圖5 圖5:使用有 Jemalloc 和沒有 Jemalloc 的同一輸入文件,隨著時間的推移內存使用量
摘要摘要
為了優化基于 libTorrch 的多軌 LibTorrch 推斷引擎的性能,我們建議核實LibTorrch 中不存在過量訂閱問題。 就我們而言,多軌引擎中的所有線條都是共享 LibTorrch 全球線條庫,這造成了一個過量訂閱問題。 這一點通過讓全球線條庫失效而得到糾正: 我們通過將線條設為 1 來禁用內部和內部全球線條庫。 為了優化多軌引擎的內存, 我們建議使用 Jemalloc 來作為記憶分配工具, 而不是默認的時鐘功能 。
審核編輯:湯梓紅
-
cpu
+關注
關注
68文章
10854瀏覽量
211583 -
內存
+關注
關注
8文章
3019瀏覽量
74003 -
線程池
+關注
關注
0文章
57瀏覽量
6844 -
pytorch
+關注
關注
2文章
807瀏覽量
13200
發布評論請先 登錄
相關推薦
多線程之線程池

線程池的線程怎么釋放
Spring 的線程池應用

高并發內存池項目實現





 工商網監
工商網監
評論