 云知聲千億參數山海大模型首次亮相
云知聲千億參數山海大模型首次亮相
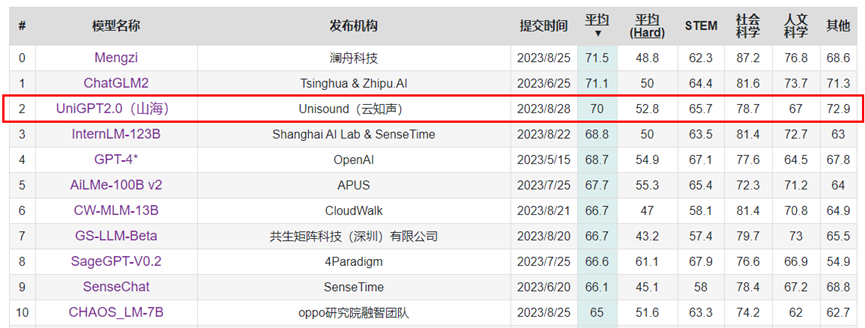
8月28日,山海大模型迎來又一次迭代升級,當前版本參數規模達到千億,實現了多學科能力、醫療能力雙提升,實測性能在C-Eval全球大模型綜合性評測中超越GPT-4,以平均分70分的成績進入前三甲。
能力突破,持續領跑行業
多學科能力增強
本次山海大模型2.0版參數規模達到千億,增加了更多的學科類的預訓練語料,訓練數據(Tokens)達到兩萬億(2.0T)。
在本次模型升級過程中,山海團隊充分利用了教材、文獻、百科類語料的價值,這些語料包含了人類對客觀世界知識的豐富理解、詳盡解釋以及在各個領域的深入研究所得到的科學結論。不同的學科領域的數據涵蓋了各自學科的專業知識,這在一定程度上彌補了第一版山海大模型在某些專業領域的知識盲區。
為了使模型能更科學合理地汲取這些不同領域和來源的數據中的知識,山海大模型團隊使用了DoReMi方法對數據進行了優化權重采樣。通過這種策略,可以在較大范圍內均勻并深入地提取各類信息。這一策略使得山海團隊在本次模型升級過程中,能更有效地吸取和運用各種知識,使模型的知識庫更加全面。
醫療能力再升級
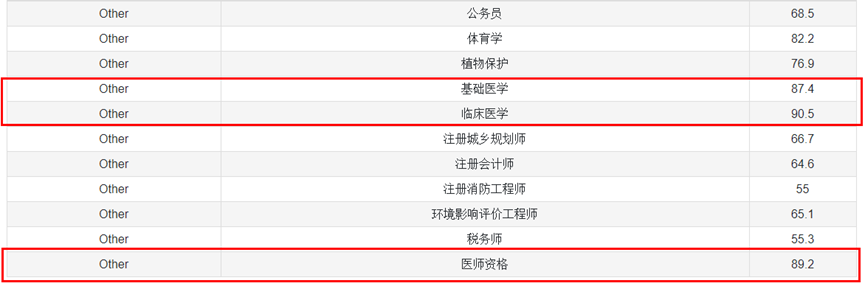
云知聲深耕醫學領域多年,山海大模型2.0在預訓練階段使用了海量的醫學病歷、醫學教材、臨床指南和醫學文獻等數據,并在對齊階段使用了人機結合方法構建的近百萬級的病歷理解、醫學考試和醫學知識問答等指令學習數據。C-Eval中醫療學科的結果表明,山海大模型2.0在基礎醫學、臨床醫學和醫師資格數據集上都能獲得接近90分的水平,為業內最高。
云知聲山海大模型團隊參加了剛剛在沈陽結束的CCKS2023-PromptCBLUE評測,該評測是當前最權威的中文醫療大模型的評測榜單,我們同樣也取得了第一名的成績,再次證明了山海大模型專業的醫學能力。
技術升級,性能加速提升
窗口長度大幅度擴展
山海團隊發現,在運用位置插值(PositionInterpolation)方法進行大幅度擴展時——比如將窗口從4k擴展到32k——其性能會顯著受到影響。這種影響主要體現在短距離情況下的使用。為了更好地解釋這一點,假設原始數據中距離為1的兩個token,當我們將數據從4k擴展到32k時,這兩個token之間的距離實際上變成了1/8。這就意味著,在進行位置插值的過程中,原本距離很近的兩個token之間的距離被大比例地拉遠了。這種場景下,衰減規律在短距離的使用會受到較大的影響,這是因為衰減規律在短距離時可能具有非常突出的變化率,意味著原本應該很近的兩個token在大規模擴展之后,它們之間的關聯性會大幅度減小。因此,直接進行位置插值的方法會使得窗口大幅度擴展后的性能較大程度地降低。發現RoPE位置編碼短距離之間的差異,主要體現在高頻分量上,長距離之間的差異,主要體現在低頻分量上。山海大模型2.0版根據神經正切核的思想,采用Neural Tangent Kernel (NTK)的非線性差值方法,實現高頻外推、低頻內插的大規模長度擴展。采用NTK擴展后模型能夠更好的支持文本窗口擴展,當前山海大模型2.0版本已經支持32K的窗口長度。
受限解碼支持業務落地
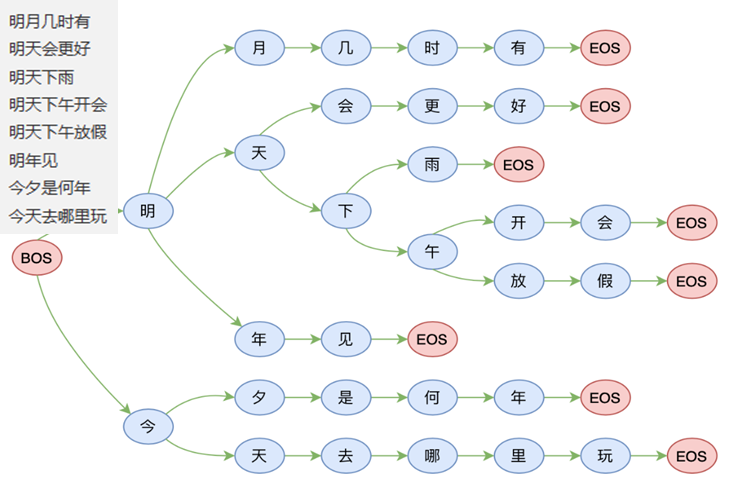
在大多數行業中,對大模型的并發使用和響應時間有很高的要求。這要求我們在保證大模型算法效果的基礎上,更需要深思其推理速度。本次山海大模型2.0基于落地場景需要,設計了受限解碼方法,在解碼過程中不需要計算整個詞表的概率,只需關注落地場景下關注的token,極大地提高了解碼效率。如圖所示,利用受限解碼方法,生成token“今”后面只需考慮token“夕”和“天”的概率,而不需要完成整個詞表概率分布的計算。
作為中國AGI技術產業化的先驅之一,云知聲于2016年開始打造Atlas人工智能基礎設施,并以此為基礎,構建云知大腦(UniBrain)技術中臺——以山海(UniGPT)通用認知大模型為核心,結合多模態感知與生成、知識圖譜、物聯平臺等智能組件,為云知聲智慧物聯、智慧醫療等業務提供高效的產品化支撐,持續推動“U(云知大腦)+X(應用場景)”戰略布局,踐行“通過通用人工智能(AGI)創建互聯直覺的世界”的公司使命。
云知聲:通過通用人工智能(AGI)創建互聯直覺的世界
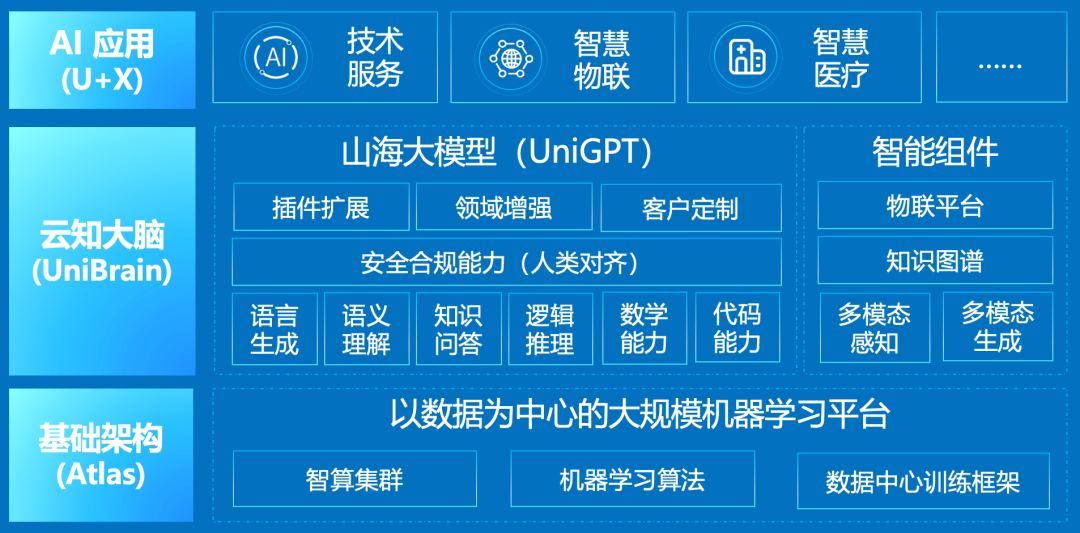
云知聲AI技術體系及U+X戰略
山海大模型作為云知大腦的核心,能力體系涵蓋語言生成、語言理解、知識問答、 邏輯推理、代碼能力、數學能力等。此外,為提高大模型在具體場景的應用落地水平,山海大模型在通用能力基礎上,增強物聯、醫療等行業能力,致力為客戶提供更智能、更靈活的解決方案,加速千行百業的智慧化升級。
自5月24日發布以來,山海大模型始終保持高速演進,不斷拓展大模型場景應用邊界——
6月25日
山海大模型通過迭代實現了在特定領域內的專業知識積累,詩詞創作能力、數學計算能力實現突破。其中,醫療能力在6月的MedQA任務上提升到了87.1%,超越Med-PaLM 2,臨床執業醫師資格考試提升至523(總分600分),超過了99%的考生水平。
6月27日
北京市首批10個人工智能行業大模型應用案例公布,由云知聲和北京友誼醫院共同開發的基于山海大模型的門診病歷生成系統示范應用成功入選。
7月2日
憑借山海大模型卓越的研發和應用成果,云知聲同時入選2023北京人工智能行業賦能典型案例、“北京市通用人工智能產業創新伙伴計劃”第二批成員名單。
7月6日-8日
云知聲攜山海大模型及最新場景應用——基于山海大模型打造的智慧車載解決方案、智慧交通解決方案亮相2023 WAIC。
7月28日
山海大模型迎來新一輪迭代升級,并在本月的C-Eval全球大模型綜合性考試評測中取得了60分以上的優異成績,成功躋身榜單前十。
8月27日
CCKS 2023現場公布系列評測任務結果,云知聲憑借基于山海大模型孵化的UNIGPT-MED 模型,在PromptCBLUE醫療大模型評測中奪得A、B榜雙榜冠軍。
云知聲希望,通過山海大模型的持續升級,不僅打造基礎能力更加強大的通用大模型,也進一步融合不同垂直領域的專業知識,讓大模型更懂行業、更具專長,實現大模型應用場景的加速拓展,讓大模型的產業價值在千行百業中綻放。
此次云知聲躋身C-Eval全球大模型綜合性考試評測前三甲,再一次印證了山海大模型的突出實力,也將持續推動云知聲AGI基礎設施能力的躍進提升,加速人工智能技術的創新與應用。未來,云知聲將以其強大的技術實力、不斷創新的科研能力以及對人工智能發展的深刻理解,不斷構建長期競爭力和創新基石,持續探索AGI的無限可能。
附:C-Eval是由清華大學、上海交通大學和愛丁堡大學合作構建的面向中文語言模型的綜合性考試評測集,包含13948道多項選擇題,涵蓋數學、物理、化學、生物、歷史、政治、計算機等52個不同學科和四個難度級別,是全球最具影響力的綜合性考試評測集之一。作為第三方發起的測試基準, C-Eval以其客觀性、公正性備受業內關注,也吸引了多家企業、機構和高校的參與。
審核編輯:湯梓紅
-
AI
+關注
關注
87文章
30728瀏覽量
268892 -
GPT
+關注
關注
0文章
352瀏覽量
15343 -
云知聲
+關注
關注
0文章
179瀏覽量
8388 -
大模型
+關注
關注
2文章
2423瀏覽量
2645
原文標題:云知聲千億參數山海大模型首次亮相,C-Eval 評測達70分,超越GPT-4
文章出處:【微信號:云知聲,微信公眾號:云知聲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
云知聲與英內物聯簽署戰略合作協議 探索基于云知聲山海大模型的多元智慧場景

云知聲榮登2024大模型企業TOP50榜單
云知聲山海大模型多項能力全球領跑

云知聲山海多模態大模型UniGPT-mMed登頂MMMU測評榜首

云知聲山海大模型醫療專業能力全球第一
云知聲山海大模型助力司法領域智慧化升級
云知聲推出山海多模態大模型
云知聲在邊緣側大模型技術探索和應用
云知聲攜手耘途教育成立云知學院福建分院
云知聲山海大模型醫療行業版登頂上海AI實驗室權威大模型評測榜






 工商網監
工商網監
評論