 不只是GPU,內存廠商們的AI野望
不只是GPU,內存廠商們的AI野望
電子發燒友網報道(文/周凱揚)在諸多云服務廠商或互聯網廠商一頭扎進GPU的瘋搶潮后,不少公司也發現了限制AI大模型性能或是成本消耗的除了GPU以外,還有內存。內存墻作為橫亙在AI計算和HPC更進一步的阻礙之一,在計算量井噴的今天,已經變得愈發難以忽視。所以,在今年的HotChips大會上,內存廠商們也競相展示自己的內存技術在AI計算上的優勢。
三星
三星作為最早一批開始跟進存內計算的公司,早在兩年前的HotChips33上,就展示了HBM2-PIM的技術Aquabolt-XL。三星在去年底展示了用PIM內存和96個AMD Instinct MI100 GPU組建的大規模計算系統,并宣稱這一配置將AI訓練的速度提高了近2.5倍。
而今年的HotChips上,三星也著重點明了PIM和PNM技術在生成式AI這類熱門應用上的優勢。三星認為在ChatGPT、GPT-3之類的應用中,主要瓶頸出現在生成階段的線性層上,這是因為GPU受到了內存限制且整個過程是線性順序進行的。
在三星對GPT的分析中,其主要由概括和生成兩大負載組成,其中概括考驗的是計算單元的性能,而生成則考驗的是內存的性能。而生成占據了絕大多數的運算次數和耗時,其中占據了60%到80%延遲的GEMV(矩陣向量操作)也就成了三星試圖用PIM和PNM攻克的目標。
根據三星的說法,像GPT這類Transformer架構的模型,都可以將多頭注意力(MHA)和前饋神經網絡(FFN)完全交給PIM或PNM,完全利用他們的所有帶寬,從而減少在推理上所花費的時間和能耗。三星也在單個AMD MI100-PIM的GPU上進行了試驗,得出運行GPT模型時,在HBM-PIM的輔助下,能效是GPU搭配傳統HBM的兩倍,性能同樣提升至兩倍以上。
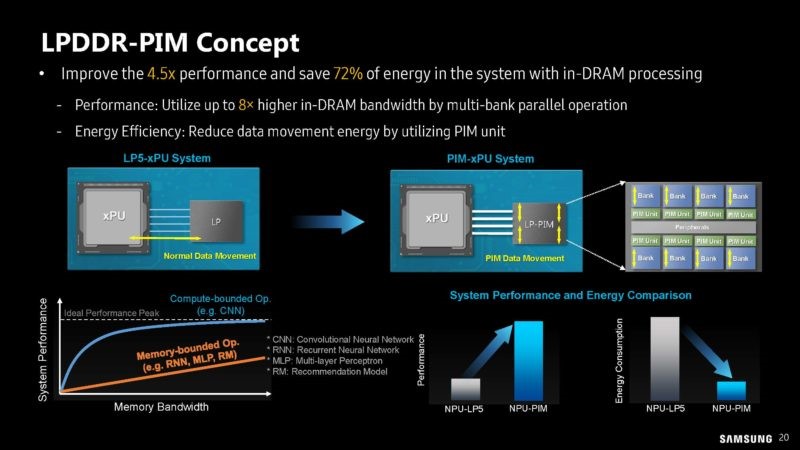
LPDDR-PIM概念 / 三星
除了HBM-PIM外,這次三星還展示了最新的LPPDR-PIM概念。除了云端生成式AI需要存內計算的輔助外,諸如智能手機這樣的端側生成式AI概念也被炒起來,所以LPPDR-PIM這樣的存內計算技術,可以進一步保證續航的同時,也不會出現為了帶寬內存使用超量的情況。
SK海力士
另一大韓國內存巨頭SK海力士也沒有閑著,在本次HotChips大會上,他們展示了自己的AiM存內加速器方案。相較三星而言,他們為生成式AI的推理負載準備的是基于GDDR6的存內計算方案。
GDDR6-AiM采用了1y的制造工藝,具備512GB/s內部帶寬的同時,也具備32GB/s的外部帶寬。且GDDR6-AiM具備頻率高達1GHz的處理單元,算力可達512GFLOPS。GDDR6-AiM的出現,為存內進行GEMV計算提供了端到端的加速方案,比如乘法累加和激活函數等操作都可以在內存bank內同時進行,單條指令實現全bank操作提供更高的計算效率。
同時,SK海力士也已經考慮到了AiM的擴展性問題,比如單個AiM卡中集成了8個AiM封裝,也就是8GB的容量和256個處理單元。但這類擴展方案最大的問題還是在軟件映射、硬件架構和接口上,這也是絕大多數集成存內計算的新式內存面臨的問題。
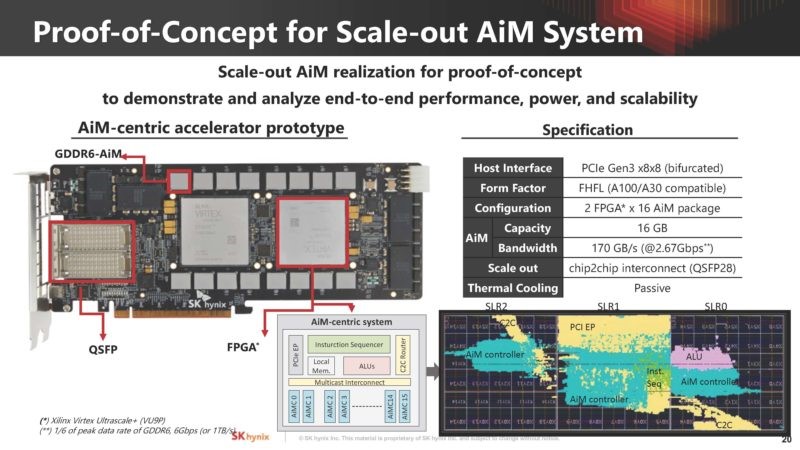
AiM系統擴展性驗證Demo / SK海力士
而SK海力士已經給出了這方面的解決方案,比如專門針對AiM的Tiling、基于AiM架構的控制器、路由和ALU等等。他們還展示了在兩個FPGA上結合GDDR6-AiM的Demo,以及用于LLM推理的軟件棧。與此同時,他們也還在探索AiM的下一代設計,比如如何實現更高的內存容量,用于應對更加龐大的模型。
寫在最后
無論是三星還是SK海力士都已經在存內計算領域耕耘多年,此次AI熱來勢洶洶,也令他們研發速度進一步提快。畢竟如今能夠解決大模型訓練與推理的耗時與TCO的硬件持續大賣,如果存內計算產品商業化量產落地進展順利,且確實能為AI計算帶來助力的話,很可能會小幅提振如今略微萎縮的內存市場。
-
gpu
+關注
關注
28文章
4752瀏覽量
129057
發布評論請先 登錄
相關推薦
GPU是如何訓練AI大模型的
PON不只是破網那么簡單
《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
不只是前端,后端、產品和測試也需要了解的瀏覽器知識(二)
為什么跑AI往往用GPU而不是CPU?

AI訓練,為什么需要GPU?

新型的FPGA器件將支持多樣化AI/ML創新進程
國產GPU在AI大模型領域的應用案例一覽

Achronix新推出一款用于AI/ML計算或者大模型的B200芯片

FPGA在深度學習應用中或將取代GPU
GPU交期緩解,AI服務器廠商營收暴漲





 工商網監
工商網監
評論