") 訓練大語言模型帶來的硬件挑戰(zhàn)
訓練大語言模型帶來的硬件挑戰(zhàn)
01
介紹
生成式AI和大語言模型(LLM)正在以難以置信的方式吸引全世界的目光,本文簡要介紹了大語言模型,訓練這些模型帶來的硬件挑戰(zhàn),以及GPU和網(wǎng)絡行業(yè)如何針對訓練的工作負載不斷優(yōu)化硬件。
02
生成式AI/大語言模型-Generative AI/Large Language Models
生成式AI是人工智能的一個分支,主要聚焦在基于既有的內(nèi)容、創(chuàng)造和生成諸如圖片、文字和音樂等新的內(nèi)容,而不僅僅簡單的復制和衍生。它包括訓練深度學習模型,通過學習大型數(shù)據(jù)集的基本模式和特征,然后利用這些知識來生成新的輸出結(jié)果。大語言模型是生成式人工智能的一種,利用先進的深度學習算法在大量的自然語言數(shù)據(jù)上進行訓練。這些模型可以學習到人類語言的模式和結(jié)構(gòu),并可以針對各類書面輸入(譯者注:可以理解為提出的各行各業(yè),各種方面的提問)或者提示做成類似人類的反饋(回答)。
大語言模型已經(jīng)“悄然工作”了十多年,直到openAI發(fā)布了ChatGPT,才吸引了廣泛關注。ChatGPT可以讓任何一個可以上網(wǎng)的人,都能和“強悍”的大語言模型-GPT3.5進行交互。隨著更多的個人和組織開始和chatGPT“戲耍”起來,我們意識到很多應用會因此發(fā)生變化,而這種改變,在一年前無法想象。
ChatGPT以及其他最新的大語言模型產(chǎn)品帶來近乎完美的“人類”表現(xiàn),得益于架構(gòu)模型的進步,這些模型就是高效的深度神經(jīng)網(wǎng)絡(DDN)和數(shù)十億訓練參數(shù)的大型數(shù)據(jù)集。大多數(shù)參數(shù)是用于訓練和推理的權(quán)重矩陣。而訓練這些模型的浮點計算次數(shù)(FLOP)與參數(shù)數(shù)量和訓練集的大小幾乎呈現(xiàn)線性增長。這些運算是專為矩陣云端設計的處理器上進行的,如圖形處理器(GPU)、張量處理單元(TPU)和其他專用人工智能芯片。GPU/TPU 和人工智能加速硬件以及它們之間用于通信的互聯(lián)技術(shù)的進步,使這些巨型模型的訓練成為可能。
03
大語言模型應用(LLM)
大語言模型有很多使用案例(譯者注:后LLM即為大語言模型,后續(xù)兩者都可能出現(xiàn)),幾乎每個行業(yè)都可以從中獲益。任何組織都可以基于自己領域和特定需求進行微調(diào)。微調(diào)在特定的數(shù)據(jù)集上訓練已有的語言模型,使得更具備專業(yè)性,來滿足特定任務的要求(譯者注:英文原文為fine-tune,個人覺得是不是叫調(diào)優(yōu)更好一些,不過后面還是寫成微調(diào))。微調(diào)可以使企業(yè)能夠利用訓練模型的已知能力,同時適應企業(yè)的獨特需求。它使得模型可以獲取特定領域的知識,從而提高為組織本身的應用場景創(chuàng)造輸出。有了經(jīng)過微調(diào)的模型,企業(yè)可以將大語言模型應用在諸多場景中。
例如,根據(jù)公司文檔進行微調(diào)的LLM可以用于客戶支持的服務。LLM可以幫助軟件工程師創(chuàng)建代碼,或者幫助他們創(chuàng)建部分代碼,當根據(jù)企業(yè)的專用代碼庫進行微調(diào)之后,LLM還可能生成與現(xiàn)有代碼庫一樣的軟件。(譯者注:在juniper的mist無線管理平臺下,客戶就可以通過AI對話助手,利用chatGPT對juniper的文檔進行查詢,提問一些像“交換機的VLAN該如何配置”這樣的問題)。
利用情感分析來了解客戶的反饋,將技術(shù)文檔翻譯成其他語言,總結(jié)會議和客戶的電話,以及生成工程或營銷內(nèi)容,這些都是LLM的諸多案例的“灑灑碎”(一點點)。
而隨著LLM的規(guī)模不斷呈指數(shù)級增長,對計算和互聯(lián)的需求也大幅增加。只有當模型的訓練和微調(diào),以及推理更具成本優(yōu)勢時,LLM才會得到廣泛應用。
04
LLM訓練
使用自然語言文本訓練,通常需要通過網(wǎng)絡抓取,維基百科、GitHub、Stack Exchange(問答網(wǎng)站)、arXiv(一個免費的科學預印論文庫)等網(wǎng)站收集大量數(shù)據(jù)。大多數(shù)模型堅持使用開放數(shù)據(jù)集進行訓練。首先要對數(shù)據(jù)集中的大量文本進行標記化,通常是使用字節(jié)對編碼等方法。
標記化是將互聯(lián)網(wǎng)上的原始文本轉(zhuǎn)換成一串整數(shù)(標記)。一個標記(唯一整數(shù))可以代表一個字符,也可以代表一個詞。標記也可以是單詞的一部分。例如,單詞 "unhappy "可能被分成兩個標記--一個代表子單詞 "un",另一個代表子單詞 "happy"。

圖 1 — 段落的標記化
根據(jù)數(shù)據(jù)集的不同,可能會有數(shù)以萬計的獨特標記,而數(shù)據(jù)集本身也可能映射出數(shù)千億個標記。序列或上下文長度是模型在訓練過程中預測下一個標記時,將查看的連續(xù)標記的數(shù)量。在 GPT-3 和 LLaMA(Meta 的 LLM)中,序列長度約為 2K。有些模型使用的序列長度為 100,000 左右。表 1 比較了 GPT-3 和 LLaMA 模型的訓練參數(shù)。
為了訓練模型,標記會被分成大小為 batch_size (B) x 序列長度的數(shù)組,這些會批量送入大型神經(jīng)網(wǎng)絡模型。在這篇文章中,我不會深入探討模型架構(gòu),因為這需要對深度學習和轉(zhuǎn)換器(transformers)有更深入的了解(我不具備這方面的知識)。訓練通常需要數(shù)周甚至數(shù)月的時間,并且需要大型 GPU 集群。
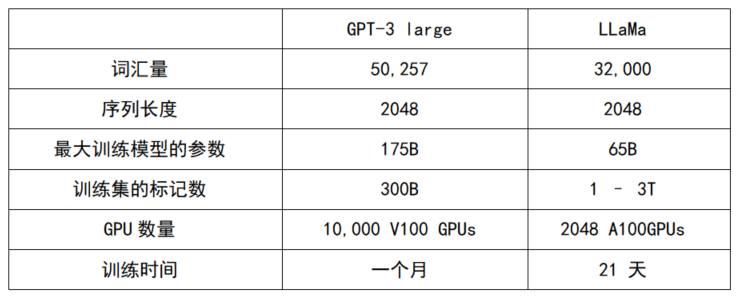
|表 1 — 比較GPT-3 和 LLaMA 模型
當基礎模型訓練完成后,通常會進行監(jiān)督微調(diào)- Supervised Fine-Tuning (SFT)。這是可以讓LLM化身助手,根據(jù)人類提示回答問的重要步驟。在監(jiān)督微調(diào)的過程中,承包商(供應商)會人工創(chuàng)建一個精致的數(shù)據(jù)集(數(shù)量少,但是質(zhì)量超高),并利用這個數(shù)據(jù)集對基礎模型進行重新訓練。對,就是這樣,訓練有素的SFT模型就可以變成助手,能夠?qū)τ脩舻奶崾咀龀鲱愃迫祟惖幕貞@是對LLM的一個簡化解釋,目前是為后面的章節(jié)提供一些背景信息。
05
數(shù)學模型
一個擁有 175B 參數(shù)的模型通常需要大于 1TB 的內(nèi)存來存儲參數(shù)和計算過程中的中間狀態(tài)。它還需要存儲空間來檢查訓練狀態(tài)(在訓練迭代過程中遇到硬件錯誤時回退)。一萬億個標記通常需要 4TB 的存儲空間。像 Nvidia H100 這樣的高端 GPU 集成了 80GB 的 HBM 內(nèi)存。一個 GPU 的內(nèi)存無法滿足模型參數(shù)和訓練集的需求。
根據(jù)維基百科,一個 LLM 的每個參數(shù)和標記通常需要 6 個FLOP。這意味著訓練 GPT-3 模型需要 6 x 175B x 300B 或 3.15 x 10^23 FLOP。GPT-3 模型的訓練耗時三周。因此,在這三周的時間里,它需要 5.8 x 10^16 FLOPS(每秒浮點運算)的計算能力。
性能最高的 Nvidia H100 GPU 大約可以實現(xiàn) 60 TeraFLOPS(每秒萬億浮點數(shù))。如果這些 GPU 的利用率達到 100%,那么我們需要約 1000 個 GPU 才能獲得 5.8 x 10^16 FLOPS。但是,在許多訓練工作負載中,由于內(nèi)存和網(wǎng)絡瓶頸,GPU 的利用率徘徊在 50% 左右或更低。因此,訓練所需的 GPU 數(shù)量是原來的兩倍,即大約需要 2000 個 H100 GPU。最初的 LLM 模型(表 1)是使用舊版本的 GPU 進行訓練的,因此需要 10,000 個 GPU。
在使用數(shù)千個 GPU 的情況下,模型和訓練數(shù)據(jù)集需要在 GPU 之間進行分布,以便并行運行。并行可以從多個維度進行。
06
Data parallelism-數(shù)據(jù)并行
數(shù)據(jù)并行是在多個 GPU 上分割訓練數(shù)據(jù),并在每個 GPU 上訓練模型的副本。
# 典型的流程如下
數(shù)據(jù)分發(fā):訓練數(shù)據(jù)被分成多個迷你批次,并分配給多個 GPU。每個 GPU 獲得一個獨特的迷你批次訓練集。
模型拷貝:在每個 GPU(worker)上放置一份模型副本。
梯度計算:每個 GPU 使用其迷你批次對模型進行一次迭代訓練,運行一次前向傳遞來進行預測,一次后向傳遞來計算梯度(表明在下一次迭代之前應如何調(diào)整模型參數(shù))。
梯度聚合:然后將所有 GPU 的梯度匯總在一起。通常的做法是取梯度的平均值。
模型更新:聚合梯度被廣播到所有 GPU。GPU 更新其本地模型參數(shù)并同步。
重復:這一過程會重復多次迭代,直到模型完全訓練完成。
在使用大型數(shù)據(jù)集時,數(shù)據(jù)并行化可以大大加快訓練速度。但是,由于每個 GPU 必須將其結(jié)果與參與訓練的其他 GPU 進行通信,因此可能會產(chǎn)生相當大的 GPU 間通信量。在每次訓練迭代中,這種所有GPU全部相互交互的通信會在網(wǎng)絡中產(chǎn)生大量流量。
有幾種方法可以減少這種情況。對于小規(guī)模模型,可由專門的服務器(參數(shù)服務器)匯總梯度。這可能會造成從眾多 GPU 到參數(shù)服務器之間的通信瓶頸。Ring All-Reduce等方案可以用于將梯度以環(huán)形模式從一個 GPU 發(fā)送到另一個 GPU,其中每個 GPU 將從上一個 GPU 接收到的梯度與本地計算的梯度聚合在一起,然后再發(fā)送給下一個 GPU。因為梯度聚合分布在各個 GPU 上,最終結(jié)果需要傳回環(huán)形拓撲結(jié)構(gòu)中的所有 GPU,因此這個過程非常緩慢。如果網(wǎng)絡出現(xiàn)擁塞,GPU 流量在等待梯度聚合時就會停滯。
此外,單個 GPU 無法處理數(shù)十億參數(shù)的 LLM。因此,僅靠數(shù)據(jù)并行性并不適用于 LLM 模型。
(譯者注:數(shù)據(jù)并行的概念描述,參考baidu大腦的一篇文章:https://baijiahao.baidu.com/s?id=1721295143486708825&wfr=spider&for=pc)
07
Model parallelism--模型并行
模型并行旨在通過在多個 GPU 上分割模型參數(shù)(和計算)來解決模型無法在單個 GPU 上運行的問題。
# 典型的流程如下
模型分區(qū): 模型被分為幾個分區(qū)。每個分區(qū)分配給不同的 GPU。由于深度神經(jīng)網(wǎng)絡通常包含一堆垂直層,因此將大型模型按層分割是合乎邏輯的,其中一個或一組層可能被分配給不同的 GPU。
前向傳遞:在前向傳遞過程中,每個 GPU 都會使用 "整個 "訓練集計算其模型部分的輸出。一個 GPU 的輸出將作為輸入傳遞給序列中的下一個 GPU。序列中的下一個 GPU 在收到前一個 GPU 的更新之前無法開始處理。
后向傳遞:在后向傳遞過程中,一個 GPU 的梯度被傳遞給序列中的前一個 GPU。收到輸入后,每個 GPU 都會計算模型中自己那部分的梯度。與前向傳遞類似,GPU 之間會建立順序依賴關系。
參數(shù)更新:每個 GPU 都會在后向傳遞結(jié)束時更新其模型部分的參數(shù)。請注意,這些參數(shù)無需廣播給其他 GPU。
重復:重復這一過程,直到模型在所有數(shù)據(jù)上都訓練完成。
模型并行化允許對單個 GPU 難以支撐的大型模型進行訓練。但這也會在前向和后向傳遞過程中引入 GPU 之間的通信。此外,由于數(shù)據(jù)集規(guī)模巨大,上述通過一大批 GPU 運行整個訓練數(shù)據(jù)集的天真實現(xiàn)方式,對于 LLM 可能并不實用,也會在 GPU 之間產(chǎn)生順序依賴關系,導致大量等待時間和計算資源利用率嚴重不足。這也就產(chǎn)生了下面的流水線并的方式。
08
Pipeline parallelism-流水線并行
流水線并行結(jié)合了數(shù)據(jù)并行和模型并行,其中訓練數(shù)據(jù)集的每個迷你批次被進一步拆分為多個微型批次。在上面的模型并行例子中,當一個 GPU 使用第一個微批次計算輸出并將數(shù)據(jù)傳遞給序列中的下一個 GPU 后,它不會閑置,而是開始處理訓練數(shù)據(jù)集的第二個微批次,以此類推。這就增加了 GPU 之間的通信,因為每個微批次都需要在序列中相鄰的 GPU 之間進行前向傳遞和后向傳遞通信。
09
Tensor parallelism-張量并行
模型和流水線并行技術(shù)都會在層邊界垂直分割模型。對于大型 LLM,即使在 GPU 中安裝單層也是一項挑戰(zhàn)!在這種情況下,張量并行技術(shù)就派上了用場。它是模型并行的一種形式,但不是在層級上劃分模型,而是在單個操作或 "張量 "級別上劃分模型。這樣可以實現(xiàn)更細粒度的并行,對某些模型來說效率更高。
還有許多其他技術(shù)可以在 GPU 上分割數(shù)據(jù)集和模型參數(shù)。這一領域的研究重點是盡量減少 GPU 間的通信,并在訓練大型模型時減少 GPU 的閑置時間(FLOP 利用率)。大多數(shù)深度學習框架都內(nèi)置了對模型和數(shù)據(jù)集分區(qū)的支持(如果用戶不想手動設置的話)。
無論使用哪種并行方式,LLM 都會因為參數(shù)和數(shù)據(jù)集的龐大規(guī)模,通過連接這些 GPU 的矩陣產(chǎn)生大量 GPU 間通信。結(jié)構(gòu)中的任何擁塞都可能導致訓練時間過長,使得GPU 利用率極低。
因此,用于 GPU/TPU 集群的互連架構(gòu)技術(shù)和拓撲結(jié)構(gòu)對 LLM 的總成本和性能起著至關重要的作用。讓我們探討一下流行的 GPU/TPU 集群設計,以了解互連技術(shù)及其在 LLM 訓練中的應用。
10
GPU/TPU全貌
TPU 是谷歌開發(fā)的人工智能加速器,用于加速矩陣乘法、矢量處理以及訓練大規(guī)模神經(jīng)網(wǎng)絡所需的其他計算。谷歌不向其他云提供商或個人出售 TPU。這些 TPU 集群僅由谷歌用于在谷歌云中提供 ML/AI 服務和其他內(nèi)部應用。
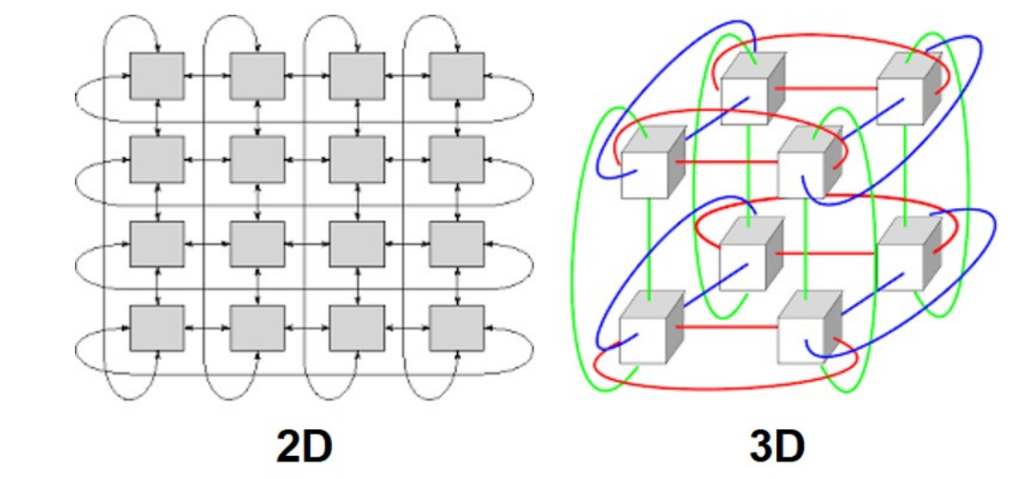
|圖二2 — 2D/3D
谷歌使用二維-2D或三維-3D環(huán)形網(wǎng)狀網(wǎng)絡構(gòu)建 TPU 集群。在二維環(huán)形網(wǎng)格中,每個 TPU 與南/北/東/西的四個方向的 TPU 相連。環(huán)形網(wǎng)格的特點是網(wǎng)格邊緣環(huán)繞(像甜甜圈或環(huán)形),因此網(wǎng)格邊緣的 TPU 仍與其他四個 TPU 相連。同樣的概念也可以擴展到三維拓撲結(jié)構(gòu)。這種拓撲結(jié)構(gòu)使相鄰的 GPU 在交換結(jié)果時能夠快速通信(張量/管道并行)。
TPU v4 集群在三維環(huán)形網(wǎng)絡中擁有超過 4,096 個 TPU。它們使用光交換機(OCS)來轉(zhuǎn)發(fā)TPU 之間的流量。因為消除了轉(zhuǎn)發(fā)過程中光電轉(zhuǎn)換操作,因此可以節(jié)省 OCS 上光模塊的功耗。谷歌在 TPU v4 集群中對其所有 LLM 模型(LaMDA、MUM 和 PaLM)進行了訓練,并聲稱訓練中 TPU 的利用率非常高(超過 55%)。
談到 GPU,Nvidia 是 GPU 供應商的“大佬”,所有大型數(shù)據(jù)中心和高性能計算(HPC)都使用 Nvidia 系統(tǒng)來訓練大型 DNN。大多數(shù) LLM(谷歌創(chuàng)建的模型除外)都是使用 Nvidia 的 GPU 進行訓練。
Nvidia GPU 配備高速 NVLinks,用于 GPU 與 GPU 之間的通信。與傳統(tǒng)的 PCIe 接口相比,NVLink 提供了更高的帶寬,可加快 GPU 之間的數(shù)據(jù)傳輸,從而縮短機器學習的訓練時間。第四代 NVlink 可提供每個方向200Gbps 的帶寬。Nvidia 最新的 H100 GPU 有 18 個這樣的鏈路,可提供 900GBps 的總帶寬。此外,NVLink 支持 GPU 內(nèi)存池,即多個 GPU 可以連接在一起,形成更大的內(nèi)存資源。這有利于運行需要比本地 GPU 內(nèi)存大的應用程序,并允許在 GPU 之間靈活劃分模型參數(shù)。
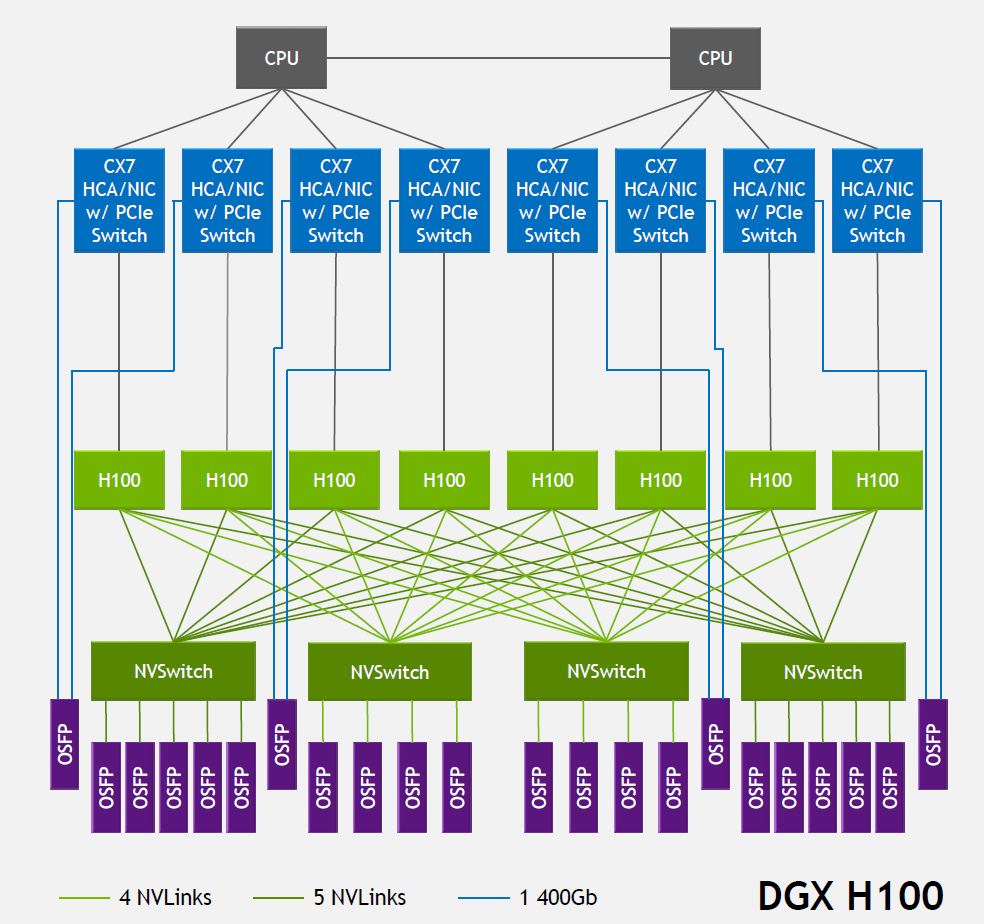
| Figure 3 — GPU 服務器(節(jié)點) 共計 8個GPUs. 每個網(wǎng)卡會通過每個方向的OSFP承載 400Gbps的數(shù)據(jù). The OSFP cage 把GPU的CX7 NIC 上和外部的以太/IB交換機互聯(lián),節(jié)點中的 GPU 可以通過 NVLink 交換機系統(tǒng)的層級結(jié)構(gòu),利用四個 NV 交換機的 OSFP 端口連接到其他 GPU 來源: Nvidia’s Hot Chips 2022 presentation.
GPU 服務器,又稱系統(tǒng)或節(jié)點,是一個 8 個 GPU 的集群,集群內(nèi)的 GPU 通過四個定制的 NVLink 交換機(NVswitches)通過 NVLinks 相互通信。多個 GPU 服務器可通過 GPU 架構(gòu)連接在一起,形成大型系統(tǒng)。
GPU 矩陣是以葉脊結(jié)構(gòu)(Leaf/Spine)或三級 CLOS 拓撲排列的交換機陣列。為所有連接于此的GPU 服務器之間提供任意對任意的連接。矩陣的葉/脊(Leaf-Spine)交換機通常采用胖樹(fat-tree)拓撲結(jié)構(gòu)。在胖樹拓撲結(jié)構(gòu)中,隨著拓撲結(jié)構(gòu)從節(jié)點向上移動到葉子和骨干,鏈路的帶寬也會增加。這是因為每個上行鏈路需要處理來自多個下行鏈路的帶寬。
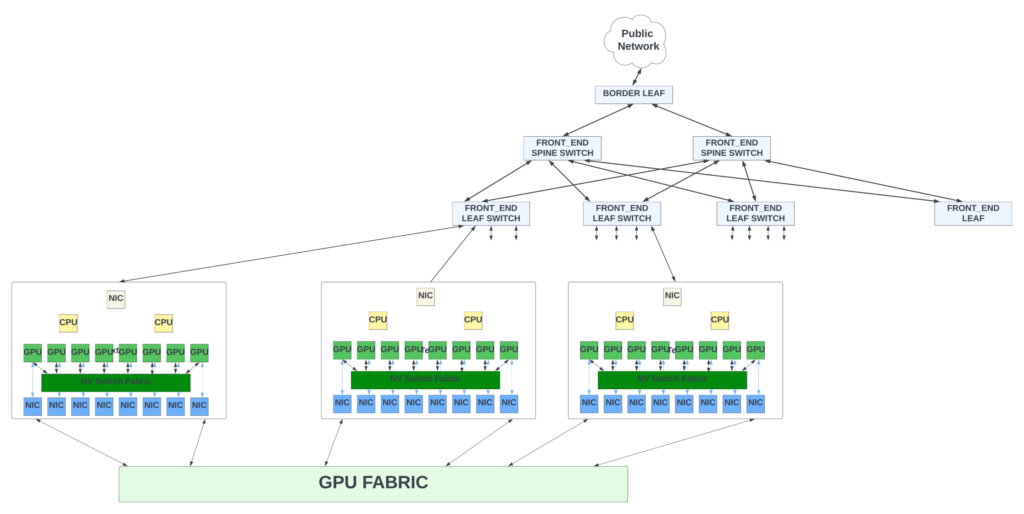
| 圖 4 — 數(shù)據(jù)中心網(wǎng)絡中 GPU 服務器和 GPU 網(wǎng)絡矩陣的概念圖
# GPU網(wǎng)絡矩陣的交換機數(shù)量取決于
· 系統(tǒng)規(guī)模 (或者說GPU節(jié)點的數(shù)量)。
· 內(nèi)部交換機的吞吐量,單個交換機提供的吞吐量越高,構(gòu)建矩陣所需的交換機數(shù)量就越少。
· 矩陣中的額外帶寬(超額配置),以緩解擁塞情況。
# 想要實現(xiàn)最佳訓練性能,就需要
· GPU 結(jié)構(gòu)應具有較低的端到端延遲。由于存在大量 GPU 間通信,降低節(jié)點間數(shù)據(jù)傳輸?shù)恼w延遲有助于縮短整體訓練時間。
· 矩陣可以保證節(jié)點間無損傳輸數(shù)據(jù)。無損傳輸是人工智能訓練的一個重要標準,因為梯度或中間結(jié)果的任何損失,都會導致整個訓練回到存儲在內(nèi)存中的上一個檢查點,然后重新開始。這會對訓練性能產(chǎn)生不利影響。
· 系統(tǒng)應具備良好的端到端擁塞控制機制。在任何樹狀拓撲結(jié)構(gòu)中,當多個節(jié)點向一個節(jié)點傳輸數(shù)據(jù)時,瞬時擁塞是不可避免的。持續(xù)擁塞會增加系統(tǒng)的尾部延遲。由于 GPU 之間的順序依賴關系,即使單個 GPU 的梯度更新在網(wǎng)絡中出現(xiàn)延遲,許多 GPU 也會停滯。一個緩慢的鏈路(譯者注:這里我個人理解為擁塞的交換機物理鏈路)就會導致訓練性能下降!
此外,還應考慮到構(gòu)建系統(tǒng)的總成本、功耗、冷卻成本等。有鑒于此,讓我們來看看 GPU 架構(gòu)設計的選擇以及每種方法的優(yōu)缺點。
11
定制化 NVLink 交換機系統(tǒng)-- Custom NVLink switch system
NVLink交換機既可以用于連接GPU服務器內(nèi)部的8個GPU,也可以用于構(gòu)建GPU服務器之間的交換結(jié)構(gòu),Nvidia 在 Hot Chips 2022 會議上展示了使用 NV switch 矩陣的 32 節(jié)點(或 256 個 GPU)拓撲結(jié)構(gòu)。由于 NVLink 被專門設計為連接 GPU 的高速點對點鏈路,因此它比傳統(tǒng)網(wǎng)絡具有更高的性能和更低的開銷。
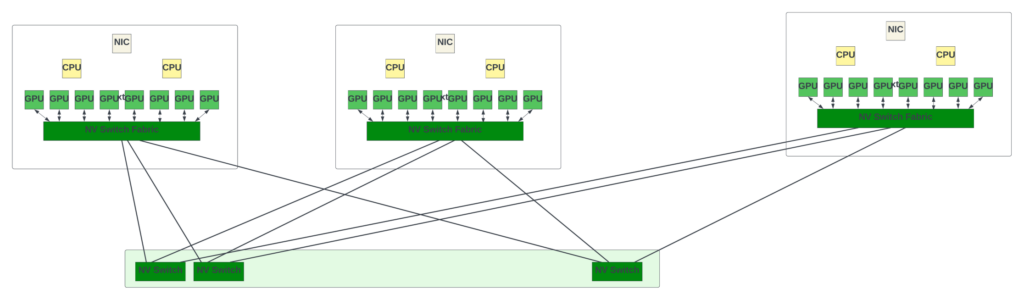
| 圖5 — 使用NV Switch的GPU矩陣
第三代 NV switch 支持 64 個 NVLink 端口,交換容量為 12.8Tbps。它還支持組播和網(wǎng)內(nèi)聚合。通過網(wǎng)內(nèi)聚合,來自所有工作 GPU 的梯度數(shù)據(jù)會在 NV 交換內(nèi)部聚合,更新后的梯度會發(fā)送回 GPU 以開始下一次迭代。這有可能減少訓練迭代之間的 GPU 間通信量。
Nvidia 聲稱,使用 NV switch矩陣訓練 GPT-3 模型的速度比使用 InfiniBand 交換矩陣快 2 倍。這一性能令人印象深刻,但交換機的帶寬比高端交換機供應商提供的 51.2Tbps 交換機少 4 倍!使用 NV switch構(gòu)建具有 >1K GPU 的大型系統(tǒng)在經(jīng)濟上并不可行,而且協(xié)議本身在支持更大規(guī)模方面可能存在局限性。
此外,Nvidia 并不單獨銷售這些 NV switch。如果數(shù)據(jù)中心希望通過混合和匹配不同供應商的 GPU 來擴展現(xiàn)有的 GPU 集群,就不能使用 NV switch,因為其他供應商的 GPU 不支持這些接口。
(譯者注:并沒有把NV switch翻譯成NV交換機,是為了保證這個名詞的獨立性)
12
InfiniBand (IB) 矩陣
InfiniBand 于 1999 年推出,被視為 PCI 和 PCI-X 總線技術(shù)的高速替代品,用于連接服務器、存儲和網(wǎng)絡。盡管由于其經(jīng)濟性的因素,InfiniBand 最初的雄心壯志有所收斂,但由于其卓越的速度、低延遲、無損傳輸和遠程直接內(nèi)存訪問(RDMA)功能,InfiniBand 在高性能計算、人工智能/ML 集群和數(shù)據(jù)中心中找到了自己的位置。
InfiniBand (IB) 協(xié)議設計高效、輕便,避免了與以太網(wǎng)協(xié)議相關的典型開銷。它既支持基于通道的通信,也支持基于內(nèi)存的通信,因此可以高效地處理各種數(shù)據(jù)傳輸方案。
IB 通過發(fā)送和接收設備之間基于信用的流量控制(在每個隊列或虛擬線路層次上)實現(xiàn)無損傳輸。這種逐跳流量控制可確保數(shù)據(jù)不會因緩沖區(qū)溢出而丟失。此外,它還支持端點之間的擁塞通知(類似于 TCP/IP 協(xié)議棧中的 ECN)。它提供卓越的服務質(zhì)量,允許優(yōu)先處理某些類型的流量,以降低延遲并防止數(shù)據(jù)包丟失。
此外,所有 IB 交換機都支持 RDMA 協(xié)議,該協(xié)議允許數(shù)據(jù)從一個 GPU 的內(nèi)存直接傳輸?shù)搅硪粋€ GPU 的內(nèi)存,而不牽扯CPU的操作系統(tǒng)。這種直接傳輸方式大大提高了吞吐量,減少了端到端延遲。
盡管具備這些優(yōu)勢,但因為它們更難配置、維護和擴展,InfiniBand 交換機系統(tǒng)卻不如以太網(wǎng)交換機系統(tǒng)受歡迎。InfiniBand 的控制平面通常通過單個子網(wǎng)管理器集中管理。它可以與小型集群配合使用,但對于擁有 32K 或更多 GPU 的 矩陣 而言,擴展難度很大。IB 矩陣還需要主機通道適配器和 InfiniBand 線纜等專用硬件,擴展成本比以太網(wǎng)矩陣高。
目前,Nvidia 是唯一一家為 HPC 和 AI GPU 集群提供高端 IB 交換機的廠商。OpenAI 在微軟的 Azure 云中使用 10,000 個 Nvidia A100 GPU 和 IB 交換機矩陣訓練了他們的 GPT-3 模型。Meta 公司最近利用 Nvidia A100 GPU 服務器和 Quantum-2 IB 交換機 (25.6Tbps 交換容量,400Gbps 端口)構(gòu)建了一個 16000的 GPU 集群。該集群用于訓練生成式人工智能模型,包括 LLaMA。
請注意,在超過10,000 GPU連接時,每個服務器內(nèi)部 GPU 之間的切換是通過服務器中的 NV switch進行的。IB/以太網(wǎng)矩陣只是將服務器連接在一起。
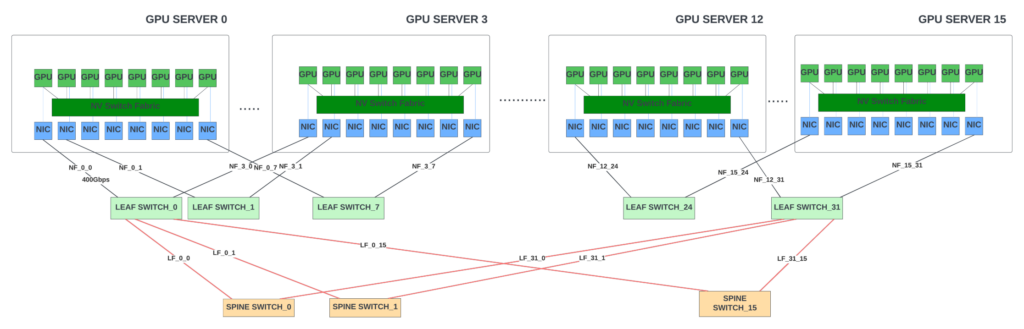
| 圖6 — 連接 128 個 GPU 的 GPU 結(jié)構(gòu)概念圖(未顯示所有節(jié)點)。GPU-Leaf鏈路: 400Gbps; Leaf-Spine鏈路:800Gbps.
由于對 LLM 訓練工作負載和更大 LLM 模型的需求不斷增加,超大規(guī)模廠商正在尋求建立擁有 32K 甚至 64K GPU 的 GPU 集群。在這種規(guī)模下,使用以太網(wǎng) Fabric 在經(jīng)濟上更有意義,因為以太網(wǎng)已經(jīng)擁有一個強大的生態(tài)系統(tǒng),包括許多芯片/系統(tǒng)和光學器件供應商,并且正在推動開放標準,以實現(xiàn)供應商之間的互操作性。
13
以太網(wǎng)矩陣--Ethernet fabric
從數(shù)據(jù)中心到骨干網(wǎng)絡,處處都可以看到以太網(wǎng)的部署,從 1G的低速端口到800G,再到即將到來的 1.6T,應用部署各不相同。Infiniband 在端口帶寬和總交換容量方面都落后于以太網(wǎng)。以太網(wǎng)交換機每G帶寬的成本低于 InfiniBand 交換機,這得益于高端網(wǎng)絡芯片供應商之間的良性競爭,導致供應商在每個 ASIC芯片增加更多帶寬(譯者注:互相PK追逐性能),從而使得不論固定端口交換機和模塊化交換機,每G成本都更優(yōu)異。
行業(yè)領先企業(yè)的高端以太網(wǎng)交換機 ASIC芯片,已經(jīng)可以提供 51.2Tbps 的交換容量和 800G 端口,是 Quantum-2 性能的兩倍。如果每個交換機的吞吐量增加一倍,在相同數(shù)量GPU的情況下,構(gòu)建GPU矩陣所需所需的交換機數(shù)量將會減半!
無損傳輸:以太網(wǎng)可以通過優(yōu)先流量控制(PFC)提供無損傳輸。PFC 允許八類服務,每一類都支持流量控制。其中一些類別可指定為啟用 PFC 的無損傳輸。與有損流量相比,無損流量以更高的優(yōu)先級通過交換機進行處理和交換。在擁塞期間,交換機/網(wǎng)卡可以對其上游設備進行流量控制,而不是丟棄數(shù)據(jù)包。
RDMA支持:以太網(wǎng)還可通過 RoCEv2(RDMA over Converged Ethernet,聚合以太網(wǎng)上的 RDMA)支持 RDMA,RDMA 幀封裝在 IP/UDP 內(nèi)。當 GPU 服務器中的網(wǎng)絡適配器(NIC)接收到發(fā)送給 GPU 的 RoCEv2 數(shù)據(jù)包時,NIC 會繞過 CPU 將 RDMA 數(shù)據(jù)直接發(fā)送到 GPU 的內(nèi)存中。此外,還可以部署強大的端到端擁塞控制方案(如 DCQCN),以減少 RDMA 的端到端擁塞和數(shù)據(jù)包丟失。
負載均衡增強:BGP 等路由協(xié)議使用等價多路徑路由(ECMP),在源和目的地之間有多條 "成本 "相等的路徑時,將數(shù)據(jù)包分配到多條路徑上。鏈路成本(cost)就可以簡單理解為設備跳數(shù)。ECMP 的目標是分配網(wǎng)絡流量,提高鏈路利用率,防止擁塞。
當數(shù)據(jù)包到達交換機時,可以多條等價路徑到達目的地,交換機會使用哈希函數(shù)來決定發(fā)送數(shù)據(jù)包的路徑(實現(xiàn)負載均衡)。這種哈希可以使用源和目的IP 地址、源和目的端口號以及協(xié)議字段,將數(shù)據(jù)包映射到不同鏈路的流量上。然而,哈希并不總是完美的,可能會導致某些鏈路流量過載。例如,在圖 7 中,假設單播流量模式為 G0 -> G19、G9 -> G2 ,以及G18 -> G11。理想情況下,網(wǎng)絡應該不會擁塞,因為葉/脊交換機有足夠的帶寬支持這種流量模式。然而,由于哈希的離散不夠,導致所有流量都可能選擇 Spine_switch_0。當出現(xiàn)這種情況時,該交換機的輸出端口就會出現(xiàn)流量超載,1200Gbps 的流量試圖從 800Gbps 的端口流出。(譯者注:此處有一句due to a lack of entropy,我理解為就是hash并沒有把流量分布出去,而是落在一個交換機上)。
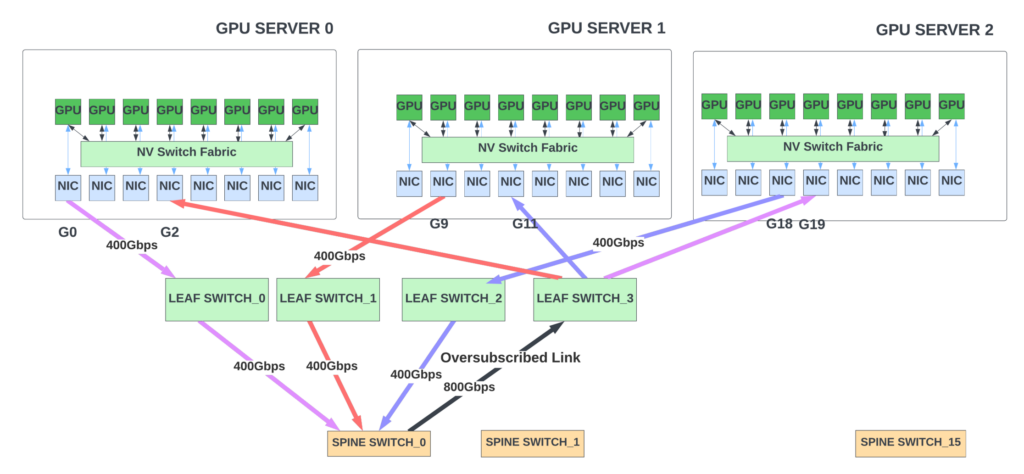
| 圖 7 — 不完善的哈希計算可能會導致某些鏈路被過度占用(譯者注:在Spine_ switch_0上看,左側(cè)三個400G端口進入的流量湊要從右側(cè)黑色的800G端口發(fā)出)
在這種情況下,端到端擁塞方案(例如ECN/DCQCN 等)可以有效地根據(jù)交換機結(jié)構(gòu)內(nèi)部的擁塞情況對發(fā)送方流量進行節(jié)流,不過在發(fā)送方節(jié)流之前仍可能會出現(xiàn)短暫的擁塞情況。
# 還有其他方法可以進一步減少擁塞
1.在脊/葉交換機之間的線路略微超配帶寬。
自適應負載平衡:當有多條路徑到達目的地時,如果一條路徑出現(xiàn)擁塞,交換機可以通過其他端口來路由后續(xù)的流量數(shù)據(jù),直到擁塞得到解決。為實現(xiàn)這一功能,交換機硬件會監(jiān)控出口隊列深度和耗盡率,并定期將信息反饋給上游交換機的負載平衡器。許多交換機已經(jīng)支持這一功能。
RoCEv2 的數(shù)據(jù)包負載均衡可將這些數(shù)據(jù)包均勻地分布在所有可用鏈路上,以保持鏈路的有效均衡。通過這種方式,數(shù)據(jù)包可以不按順序到達目的地。但是,網(wǎng)卡要可以將 RoCE 傳輸層這些不按順序的數(shù)據(jù),轉(zhuǎn)換成有順序的數(shù)據(jù),以透明方式向 GPU 傳輸(譯者注:也就是網(wǎng)卡需要做數(shù)據(jù)的排序工作)。這需要網(wǎng)卡和以太網(wǎng)交換機提供額外的硬件支持。
除上述功能外,網(wǎng)絡內(nèi)聚合(GPU 的梯度可以在交換機內(nèi)聚合)也有助于減少訓練期間的 GPU 間流量。Nvidia 在高端以太網(wǎng)交換機集成軟件支持這一功能。
因此,高端以太網(wǎng)交換機/網(wǎng)卡具有強大的擁塞控制/負載平衡功能和 RDMA 支持。與 IB 交換機相比,它們可以擴展到更大的設計規(guī)模。一些云服務提供商和超級擴展商已經(jīng)開始構(gòu)建基于以太網(wǎng)的 GPU 矩陣,以連接大于 32000(32K)個 GPU。
14
全調(diào)度型矩陣Fully-scheduled fabric(VOQ fabric)
最近,幾家交換機/路由器芯片供應商發(fā)布了支持全調(diào)度或 AI矩陣芯片。全調(diào)度矩陣并不新奇,不過是VOQ矩陣的一種,該技術(shù)十多年來主要用于許多模塊化機箱設計,包括瞻博網(wǎng)絡的 PTX 系列路由器。這種 VOQ矩陣 概念可以擴展到支持分布式系統(tǒng),以及更大規(guī)模的擴展。
在 VOQ 架構(gòu)中,數(shù)據(jù)包只在入口Leaf交換機中緩沖一次,其緩沖隊列與數(shù)據(jù)包需要離開的最終出口Leaf交換機/廣域網(wǎng)端口/輸出隊列是唯一映射的。入口交換機中的這些隊列稱為虛擬輸出隊列(VOQ)。因此,每個入口Leaf交換機都為整個系統(tǒng)中的每個輸出隊列留有緩沖空間。該緩沖區(qū)的大小通常可容納每個 VOQ 大概40-70us 的擁塞數(shù)據(jù)(譯者注:相當于內(nèi)存)。當隊列較小時,VOQ 會留在芯片緩沖區(qū);當隊列開始增加時,VOQ 會轉(zhuǎn)移到外部存儲器中的深度緩沖區(qū)。
· 在入口Leaf交換機上,一旦 VOQ 積累了一些數(shù)據(jù)包,它就會向出口交換機發(fā)出請求,請求允許通過網(wǎng)絡發(fā)送這些數(shù)據(jù)包。這些請求通過網(wǎng)絡到達出口Leaf交換機。
· 出口Leaf交換機的調(diào)度程序會根據(jù)嚴格的調(diào)度層次和淺層輸出緩沖區(qū)的空間來批準這一請求。并授權(quán)速率限制,以避免從矩陣中出口交換機的出口鏈路過載。
· 當授權(quán)批準到達 入口 Leaf 交換機,它就會將一組數(shù)據(jù)包(收到授予的數(shù)據(jù)包)發(fā)送到出口,并將負載均衡到矩陣中的所有可用上行鏈路上(譯者注:上行鏈路即是到達spine的鏈路)。
· 針對特定 VOQ 的數(shù)據(jù)包可以在所有可用的輸出鏈路上均勻分布,以實現(xiàn)完美的負載平衡。這可能會導致數(shù)據(jù)包重新排序。但是需要注意,在這些數(shù)據(jù)包傳輸?shù)?GPU 節(jié)點之前,出口交換機邏輯上是需要把這些數(shù)據(jù)包按順序排列完畢。
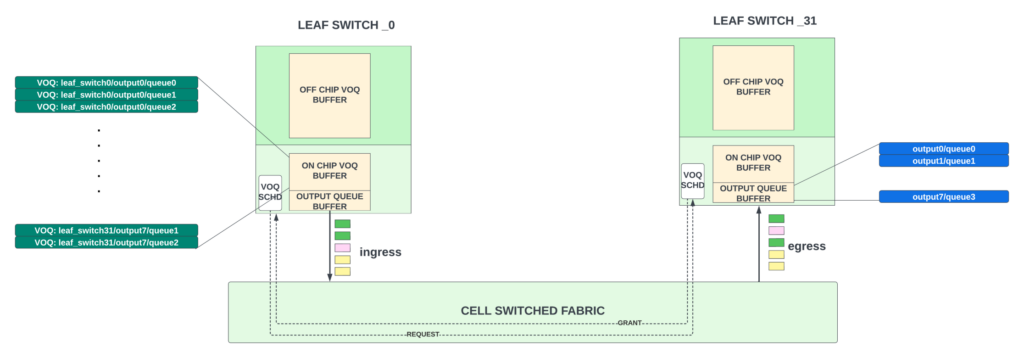
| 圖8 — VOQ 矩陣
為避免鏈路帶寬被超額占用,出口調(diào)度程序會在確保矩陣中交換機轉(zhuǎn)發(fā)數(shù)據(jù)時,對這些數(shù)據(jù)進行計量,確保不會超出。因此它消除了以太網(wǎng)結(jié)構(gòu)中 99% 因非連續(xù)傳輸(許多端口試圖向一個輸出端口發(fā)送流量)而造成的擁塞,并完全消除了 HOL 阻塞。需要注意的是,在這種架構(gòu)中,數(shù)據(jù)(包括請求和授權(quán))仍使用以太網(wǎng)結(jié)構(gòu)傳輸。(譯者注:這段翻譯比較拗口,大家可以參考原文,大概的意思就是VOQ會提前保證帶寬的預留和占用,但是關于控制的信令信息,依然是以太網(wǎng)傳輸)。
還有一些架構(gòu)(包括瞻博網(wǎng)絡的 Express 和 Broadcom 的 Jericho 系列)通過其專有的信元化矩陣(cellified fabric)支持 VOQ。在這種情況下,Leaf交換機將數(shù)據(jù)包劃分為固定大小的單元,并將它們平均發(fā)送到到所有可用的輸出鏈路上。這比在數(shù)據(jù)包層面上進行數(shù)據(jù)負載均衡發(fā)送能能提高鏈路利用率,因為在大小數(shù)據(jù)包混合的情況下,很難保證所有鏈路都得到充分利用。
伴隨信元轉(zhuǎn)發(fā),我們還避免了輸出鏈路的另一個存儲/轉(zhuǎn)發(fā)延遲(輸出以太網(wǎng)接口的延遲)。在信元矩陣中,Spine交換機被可高效轉(zhuǎn)發(fā)信元的定制交換機所取代。這些矩陣信元交換機在功耗和延遲方面都優(yōu)于以太網(wǎng)交換機,因為它們沒有支持 L2 交換的開銷。因此,基于信元的矩陣不僅能提高鏈路利用率,還能減少 VOQ矩陣中的端到端延遲。(譯者注:此處我個人的理解是,把整個交換矩陣理解成一個大cell轉(zhuǎn)發(fā)的交換機,來來實現(xiàn)高速的轉(zhuǎn)發(fā),因為如果是傳統(tǒng)IP架構(gòu),交換機之間轉(zhuǎn)發(fā)數(shù)據(jù)還涉及到二層以太網(wǎng)的封裝和解封裝問題,而cell轉(zhuǎn)發(fā)則簡化了這個步驟,越看越像早期的ATM了,LOL)
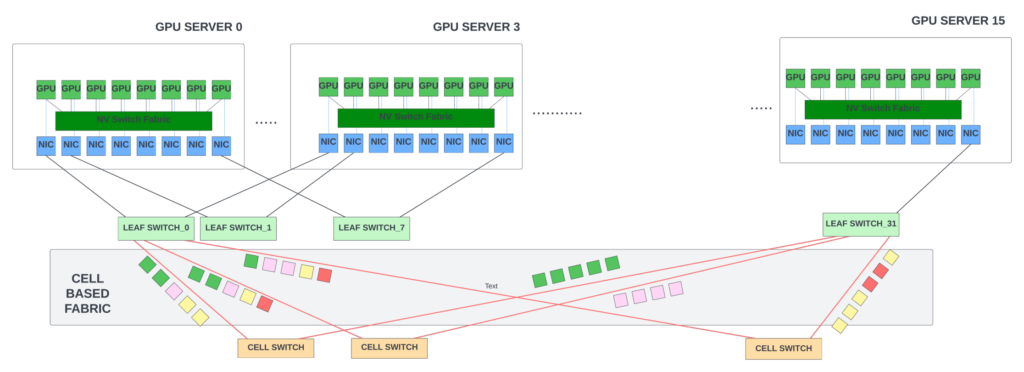
| 圖9 — Leaf交換機和cell交換機組成的基于信元的矩陣
# VOQ 架構(gòu)也有如下局限
· 每個Leaf交換機都需要在入口側(cè)為系統(tǒng)中的所有 VOQ 設置合理的緩沖區(qū),以便在擁塞期間緩沖數(shù)據(jù)包。緩沖區(qū)大小與 GPU 數(shù)量乘以每個 GPU 的優(yōu)先級隊列數(shù)量成正比。更大規(guī)模 GPU 規(guī)模就意味著需要更多的入口緩沖(譯者注:個人覺得也是對Leaf交換機性能和成本的挑戰(zhàn))。
· 出口側(cè)的輸出隊列緩沖區(qū)應留有足夠的空間,以覆蓋通過矩陣的往返延遲 (RTT),這樣這些緩沖區(qū)就不會在請求-授予握手期間空閑。在使用 3 級結(jié)構(gòu)的大型 GPU 集群中,由于光纜較長和交換機的增加,其RTT 可能會增加。如果輸出隊列緩沖區(qū)的大小不適合增加的 RTT,輸出鏈路將無法達到 100% 的利用率,從而降低系統(tǒng)性能。(譯者注:個人理解這意味著緩沖區(qū)空間的計算,不僅僅是數(shù)據(jù)包乘以緩沖延遲的計算,也包括數(shù)據(jù)包在鏈路上的延遲計算得到大小,這樣才能保證數(shù)據(jù)在傳輸過程中100%傳遞,這個確實我以前沒想過)。
· 盡管 VOQ 系統(tǒng)通過出口調(diào)度消除了 HOL 阻塞,大大減少了尾部延遲,但由于入口Leaf交換機在傳輸數(shù)據(jù)包之前必須進行請求-授予握手,因此數(shù)據(jù)包的最小延遲確實會增加一個額外的 RTT(譯者注:為了不擁塞,需要協(xié)商,因為協(xié)商,帶來新的RTT是必然,就看如何RTT有多大,如何tradeoff或優(yōu)化)。
盡管存在這些瓶頸,但完全調(diào)度的 VOQ 結(jié)構(gòu)在減少尾部延遲方面的表現(xiàn)要比典型的以太網(wǎng)流量好得多。如果能使鏈路利用率大于 90%,那么盡管GPU 擴展帶來緩沖區(qū)的增加,因而產(chǎn)生額外成本的增加(價格的增加或者RTT的增加等),這個方案依然值得投資。
另外,供應商鎖定可能是 VOQ矩陣的一個問題,因為每個供應商都有自己的專有協(xié)議,而且很難在同一矩陣中混搭多品牌交換機使用。
15
關于推理/微調(diào)工作負載的一個小說明
LLM 中的推理是使用已完成訓練的模型來生成對用戶提示的響應過程,通常是通過 API 或網(wǎng)絡服務。例如,當我們在 ChatGPT 會話中輸入一個問題時,推理過程會在云端托管的已訓練好的 GPT-3.5 模型副本上運行,從而得到回復。與訓練相比,推理所需的 GPU 資源要少得多。但是,考慮到訓練好的 LLM 模型中有數(shù)十億個參數(shù),推理仍然需要多個 GPU(以分散參數(shù)和計算)。例如,Meta 的 LLaMA 模型通常需要 16 個 A100 GPU 進行推理(而訓練需要 2000 個)。
同理,利用特定領域的數(shù)據(jù)集對已經(jīng)訓練好的模型進行微調(diào)所需的資源也較少,通常不超過100+ H100 規(guī)模的 GPU。基于此,推理和微調(diào)都不需要同一矩陣上的大規(guī)模 GPU 集群。
雖然單個推理工作負載并非計算密集型的,但隨著越來越多的人和組織開始使用 ChatGPT,推理工作負載在不久的將來將呈指數(shù)級增長。這些工作負載可以分布在不同的 GPU 集群/服務器上,每個GPU 集群/服務器都承載著已經(jīng)訓練好的的模型副本。
學術(shù)界和工業(yè)界都在認真研究如何優(yōu)化訓練和推理。量化- Quantization(在訓練和/或推理過程中使用精度較低的浮點數(shù)或整數(shù))和參數(shù)剪枝- parameter pruning(剪除對性能貢獻不大的權(quán)重/層)是用于縮小模型規(guī)模的一些技術(shù)。
Meta 的 LLaMA 模型表明,當使用四倍于 GPT-3 的數(shù)據(jù)集進行訓練時,比 GPT-3 小 3 倍的模型可以提供更好的性能。如果這一趨勢在未來版本的 LLM 模型中得以延續(xù),我們可以預期訓練出來的模型會逐漸變小,從而減輕推理工作量的壓力。
16
總結(jié)/展望
開發(fā)和訓練LLM 需要一支由人工智能/機器學習研究人員、工程師、數(shù)據(jù)科學家組成的高度專業(yè)化的團隊,還需要在云資源上投入巨資。缺乏廣泛的 ML專業(yè)知識的企業(yè)不太可能獨立應對此類挑戰(zhàn)。相反,更多的企業(yè)會尋求利用自己的專有數(shù)據(jù)集對市面上訓練有素的模型進行微調(diào)。云服務提供商可能會為企業(yè)提供這些服務。
因此,模型訓練工作量預計主要來自學術(shù)機構(gòu)、云服務提供商和人工智能研究實驗室。
與人們的預期相反,未來幾年的訓練工作量預計不會減少或停滯不前。為了讓模型產(chǎn)生準確、最新的結(jié)果,而不是產(chǎn)生 "幻覺",必須更頻繁地對模型進行訓練。這將大大增加訓練工作量。
以太網(wǎng)矩陣是構(gòu)建用于訓練的大型 GPU 集群的“不二之選”。目前市面上的所有高端以太網(wǎng)交換機(模塊化/獨立式)都能應對這種大型集群挑戰(zhàn)。通過一些增強型功能,如通過數(shù)據(jù)包級的負載均衡,對 RoCEv2 數(shù)據(jù)包進行重新排序、網(wǎng)內(nèi)聚合和支持直通模式(cut-through),這些交換機可以獲得比 IB 矩陣更為出色的性能。但是,在這些大型以太網(wǎng)矩陣集群部署和廣泛使用之前,IB Fabric 仍將繼續(xù)使用。用于分布式交換機的 VOQ 矩陣方案看起來很有前景,并為這一組合增添了另一種潛在的解決方案!
GPU/網(wǎng)絡交換機的性能和規(guī)模每兩年才翻一番。如果模型的規(guī)模繼續(xù)隨著每個新版本的推出而增加一倍或兩倍,那么它們很快就會撞上硬件墻(譯者注:硬件性能不夠)!AI界必須大力投資研究,使 LLM 更優(yōu)化、更環(huán)保、更可持續(xù)。
總之,這是一個令人激動的研究和創(chuàng)新時代!
Sharada Yeluri是瞻博網(wǎng)絡的高級工程總監(jiān),負責瞻博網(wǎng)絡 PTX 系列路由器中使用的 Express 系列芯片產(chǎn)品。她在 CPU 和網(wǎng)絡領域擁有 12 項以上的專利。
審核編輯:劉清
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238259 -
圖形處理器
+關注
關注
0文章
198瀏覽量
25539 -
TPU
+關注
關注
0文章
140瀏覽量
20720 -
深度神經(jīng)網(wǎng)絡
關注
0文章
61瀏覽量
4524 -
ChatGPT
+關注
關注
29文章
1558瀏覽量
7596
原文標題:大語言模型的硬件互聯(lián)
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的基礎技術(shù)
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的應用
Pytorch模型訓練實用PDF教程【中文】
關于語言模型和對抗訓練的工作

超大Transformer語言模型的分布式訓練框架






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論