 一種融合語義不變量的點線立體SLAM系統
一種融合語義不變量的點線立體SLAM系統
作者:魚骨 | 來源:3D視覺工坊
摘要
傳統的同步定位與制圖(SLAM)系統使用環境的靜態點作為實時定位和制圖的特征。當可用的點特征很少時,系統很難實現。一個可行的解決方案是引入線特征。在包含豐富線段的復雜場景中,線段的描述差別不大,這可能導致線段數據的不正確關聯,從而將誤差引入系統并加劇系統的累積誤差。針對這一問題,本文提出了一種結合語義不變量的點線立體視覺SLAM系統。該系統通過融合線特征和圖像語義不變信息,提高了線特征匹配的準確性。在定義誤差函數時,將語義不變量與重投影誤差函數融合,并應用語義約束減少長期跟蹤過程中姿態的累積誤差。在TartanAir數據集和KITTI數據集的Office序列上的實驗表明,該系統在一定程度上提高了直線特征的匹配精度,抑制了SLAM系統的累積誤差,平均相對位姿誤差(RPE)分別為1.38和0.0593米。
總結:
(1)提出了一種結合語義不變量的點線立體視覺SLAM系統
(2)將語義不變量與重投影誤差函數融合定義誤差函數,并應用語義約束減少長期跟蹤過程中姿態的累積誤差
(3)TartanAir數據集和KITTI數據集
引言
自工業4.0推出以來,機器人主導的智能制造產業已成為工業發展的支柱。視覺同步定位和映射(SLAM)系統是允許機器人探索未知環境、自我定位和構建地圖的核心組件。視覺SLAM依靠廉價的輕型攝像機,可以有效地感知環境的外觀,這使得僅依賴視覺傳感器的SLAM系統成為機器人領域的熱點問題。視覺SLAM系統的框架正在走向成熟。盡管視覺SLAM的研究領域已經取得了很大的進展,然而真實環境的可變性使得數據關聯的準確性不可靠甚至無效。這導致系統的魯棒性降低,難以滿足實際需求。因此,如何提高數據關聯的魯棒性,對于減少視覺SLAM的累積誤差,提高系統的整體魯棒性具有重要意義。根據所采用的跟蹤方法,將視覺SLAM系統分為直接跟蹤和間接跟蹤兩種方法。基于直接跟蹤的方法,如大尺度直接單目SLAM (LSD-SLAM)、直接稀疏里程計(DSO)和半直接單目視覺里程計(SVO),是基于最小化光度投影誤差的姿態估計方法。這些方法對光照變換很敏感,對單個像素的區分很差。相比之下,基于間接跟蹤的方法通過跟蹤圖像的點特征估計相機的姿態。代表性算法有并行跟蹤與映射(PTAM)、ORB-SLAM2、RGBD SLAM-v2等。在強紋理場景中,點特征對光照不敏感,易于提取。然而,在低紋理環境或運動模糊的場景中,提取是困難的。影響系統的魯棒性,嚴重時可能導致系統失效。在實際環境中,有大量的線特征具有與點特征相同的不變光照和視點特征,且易于提取。因此,可以克服低紋理場景造成的干擾,反映環境結構的完整信息。因此,涉及跟蹤線特征的SLAM系統誕生了。線特征對遮擋很敏感,在缺乏紋理或高重復的區域不具有很強的識別能力,這導致匹配失敗,比只依賴點特征的SLAM系統更不可靠的位姿求解。直線特征的跟蹤非常耗時,不能滿足SLAM系統的實時性要求。因此,點和線特征融合被應用到SLAM系統中。
為了減少累積誤差的產生,現有的解決方案是通過在短期內建立多幀圖像之間的約束,對位姿進行局部優化,減少軌跡漂移。當約束失敗時,誤差仍然會累積。另一種解決方案是采用閉環來建立一個長期約束來糾正累積誤差,但這種解決方案嚴格依賴閉環檢測。
近年來計算機圖像技術的快速發展,如深度學習、目標檢測、語義分割等,為機器人提高場景理解提供了更多的可能性。語義分割是一種像素級分類技術。圖像中的每個像素被劃分為相應的類別。在SLAM系統中應用語義分割來提高數據關聯的魯棒性是一個比較熱門的研究課題。在SLAM系統中,隨著時間的推移,相機的運動會導致視點、尺度和光照等特征的變化,但語義描述不會發生變化。比如在汽車上跟蹤線段時,由于距離的變化,線段周圍的像素發生了劇烈的變化,這導致跟蹤失敗。但是這條線段的語義描述屬于汽車類,不受尺度和光照變化的影響。然后將線段的語義描述視為不變的,通過線段語義標簽的一致性約束及其重投影特征建立線段的中期跟蹤。
目前,線段相關的理論發展還不夠成熟,主要表現在線段描述不夠準確,這可能導致在包含許多線段的復雜場景中出現錯誤的數據關聯。這就導致了在基于點-線特征的SLAM系統中引入線段后,線段的匹配精度較低,導致系統誤差積累。
?本文提出了一種結合語義不變量的點和線特征的魯棒立體SLAM系統。
?提出了一種改進的線段匹配方法。將語義分割的結果應用到線段匹配中,提高了線段的數據關聯。
?定義線段的語義重投影誤差函數,并將其應用于位姿優化過程,以提高數據關聯的魯棒性。實現了線段的中期跟蹤,減少了軌跡漂移問題。
系統概述
本文以立體點線SLAM系統為基礎,針對線段引入后,線段的不匹配直接影響數據關聯的準確性,加劇了系統的累積誤差的問題。提出了一種有效的改進方法。該方法使用語義不變量為線段匹配提供約束,減少了線段特征失配的產生。定義了線段的語義重投影誤差函數,實現了線段的中期跟蹤,有效地減少了軌跡漂移,提高了系統的魯棒性。如下圖所示為提出的系統的總體結構。該系統遵循ORB-SLAM2框架,整個SLAM任務按照可視化里程計、局部映射和閉環三個線程并行運行。
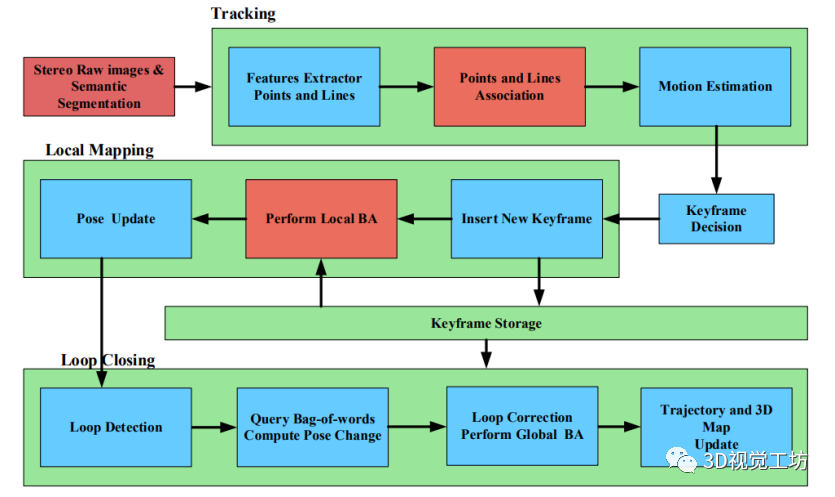
在本文中,語義分割的結果主要應用于視覺里程測量和局部姿態優化。如下圖所示,系統接收到圖像序列,然后進行點和線特征的提取和匹配。由于點特征的提取和匹配方法比線段更完備,語義分割結果只適用于線段的關聯。在現有線段關聯方法的基礎上,利用語義分割的結果對線段進行語義分類。這提供了線段關聯的語義不變約束,減少了不正確的數據關聯。當獲得點特征和線特征的關聯結果時,將局部地圖中的地標(點和線段)分別投影到當前幀及其對應的語義分割圖像中。然后,通過最小化重投影誤差項和重投影誤差項的聯合語義不變量來進行姿態優化。
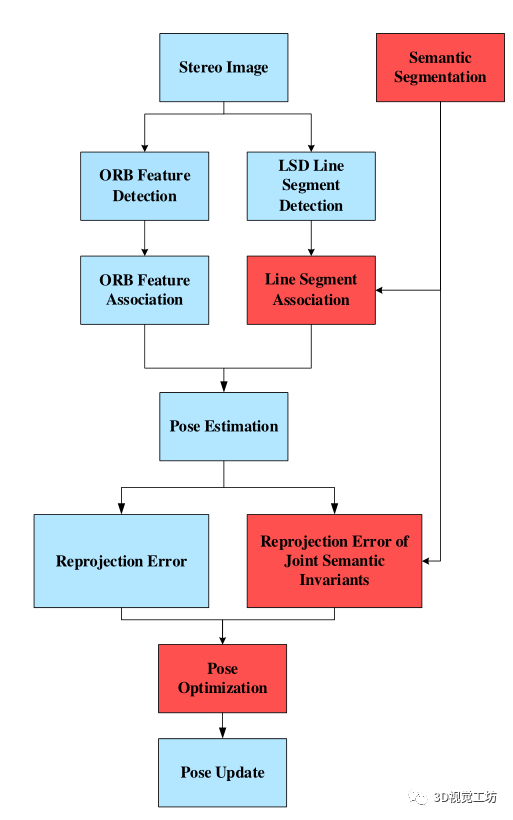
方法
在本節中,我們首先介紹LSD算法提取線段的預處理細節,以及如何應用語義分割的結果約束線段的數據關聯。然后描述了利用語義不變量建立點、線特征的中期數據關聯后,如何進行位姿優化的問題。
1、線段的預處理與關聯
線段提取采用LSD算法。LSD算法是一種局部直線檢測算法,可以在不調整參數的情況下快速提取圖像的局部直線輪廓。然而,由于遮擋或部分模糊等原因,線段被分割成幾條直線。為了解決這一問題,本文采用[18]文獻中的方法對折線段進行合并。折線段是否滿足合并條件由端點之間的距離和線段之間的距離共同決定。刪除合并后不符合長度閾值的線段。當預處理完成后,該方法對線段進行語義分類。線段是否屬于語義范疇的判定原則如下:
(1)檢測到的線段在類別區域的長度大于閾值d;
(2)如果檢測到的線段位于多個語義類別的邊界,則將其標記為概率最高的類別。
利用Detectron2對圖像進行語義分割預測。預測由地面和非地面組成。然后,根據上述規則對線段進行分類。分類結果如圖5所示。

線段的數據關聯應保證線段屬于同一語義類,具有較高的相關性。線段的相關性由線段的局部外觀描述確定,該描述由LBD描述符提供。
2、點和線重投影誤差函數的語義不變量融合
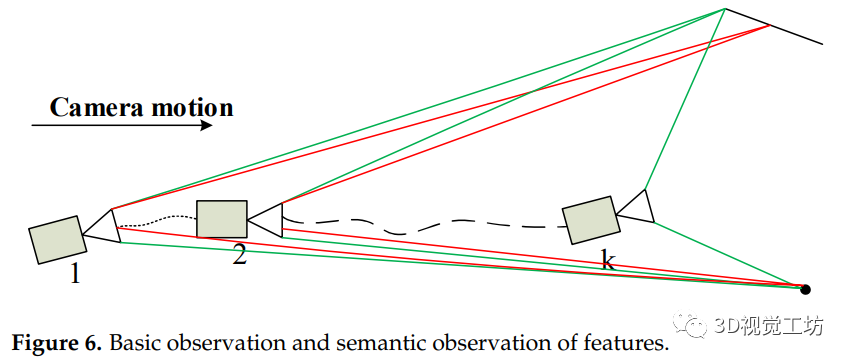
在SLAM系統中,減少軌跡累積誤差主要有兩種方法。一是通過幀間數據關聯優化姿態,減少軌跡漂移,這是一個短期約束。另一種方法依靠閉環檢測進行位姿校正,在圖像框架中建立長期約束。VSO利用圖像的語義分割信息建立點對的中期數據關聯。線段也具有語義不變性。因此,我們的方法利用這一性質來建立線段上的中期數據關聯。圖6給出了攝像機運動過程中點與線特征的數據關聯過程。紅線表示視覺里程計框架中基于外觀的特性約束,綠線表示基于語義的約束。攝像頭1和攝像頭2可以建立基于外觀的特征約束和基于語義的特征約束。在攝像機移動過程中,由于對特征外觀的描述發生了劇烈的變化,在第k個攝像機中只能觀察到特征的語義約束。與基于外觀的約束相比,這種語義約束可以為特征數據關聯提供更長期的約束,這被稱為特征的中期跟蹤。
我們將語義不變量與重投影誤差結合起來定義了一個誤差函數:
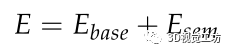
其中Ebase是重投影誤差,Esem是融合語義不變量的誤差函數。通過最小化誤差函數,實現了點特征和線特征的中期跟蹤,減少了軌跡的漂移。
(1)Ebase的定義
基于點線特征的立體SLAM系統通常通過最小化重投影誤差,給定輸入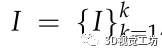 ,對應的位姿
,對應的位姿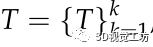 ,三維點
,三維點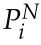 ,三維線段
,三維線段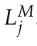 來實現局部姿態優化。重投影誤差函數Ebase定義如下:
來實現局部姿態優化。重投影誤差函數Ebase定義如下:
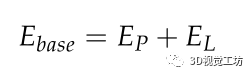
其中Ep和EL分別表示點特征和線段的重投影誤差,Ep是第i個三維點的觀測值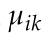 與其在第k個關鍵幀上的投影之間的距離為:
與其在第k個關鍵幀上的投影之間的距離為:
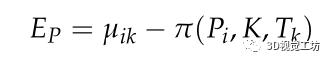
其中π(·)為三維點Pi的重投影坐標,k為攝像機的本征矩陣,Tk是相對運動矩陣。
由于遮擋或其他原因,線段的端點出現了不確定性。因此,線段的重投影誤差函數不能簡單地用觀測線與其重投影之間的坐標距離來定義。更精確的方法是使用文獻[19]中的方法,其中線段的重投影誤差定義為投影線段的端點與被測直線之間的垂直距離之和。如圖7所示,lo表示線段的觀測值,lp表示三維線段的重投影,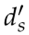 和表示直線重投影誤差。因此,EL定義為:
和表示直線重投影誤差。因此,EL定義為:
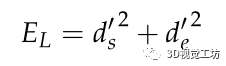
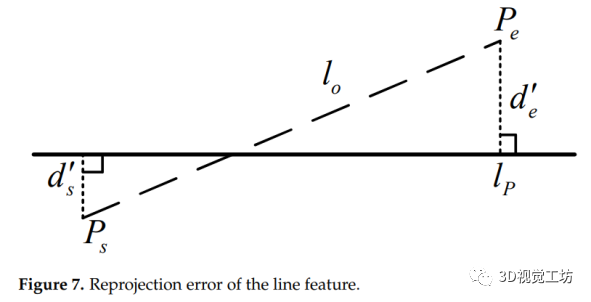
(2)Eseg的定義
融合語義不變量的誤差函數描述了點和線特征在重投影后屬于C類的概率。與VSO中闡述的現象一致,在攝像機運動過程中,由于周圍的像素信息,特征會發生劇烈變化。因此,在數據關聯中,特征的這一部分的約束就消失了。相比之下,特征的語義描述在尺度變化時保持不變。因此,將這種語義不變性應用到數據關聯中,建立特征約束,延長特征的有效跟蹤時間,減少累積誤差的產生。
對于輸入的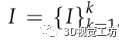 ,進行語義分割,對應的語義分割圖像是
,進行語義分割,對應的語義分割圖像是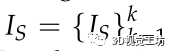 。對于Is中的每一個像素有一個類別C。然后,對于投影到Isk的一個三維點P?i?,投影坐標為μ?i?,投影坐標有一個語義類別μ?i?∈c,其中c是C的一個子類別。在VSO中定義了基于點特征的語義觀測概率模型:
。對于Is中的每一個像素有一個類別C。然后,對于投影到Isk的一個三維點P?i?,投影坐標為μ?i?,投影坐標有一個語義類別μ?i?∈c,其中c是C的一個子類別。在VSO中定義了基于點特征的語義觀測概率模型:
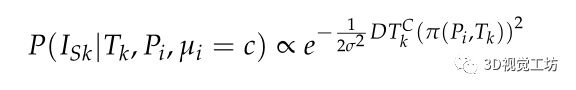
其中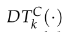 表示從投影坐標μi到語義類別C最近邊界的距離。σ描述語義類別C的不確定性,則點特征融合語義不變量上的誤差函數可定義為:
表示從投影坐標μi到語義類別C最近邊界的距離。σ描述語義類別C的不確定性,則點特征融合語義不變量上的誤差函數可定義為:
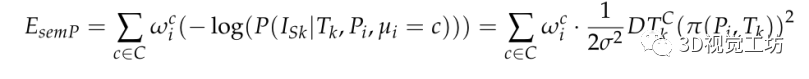
其中,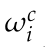 為類別概率向量,描述了Pi被一系列攝像機觀測到的情況,并且類別屬于C。這將導致:
為類別概率向量,描述了Pi被一系列攝像機觀測到的情況,并且類別屬于C。這將導致:
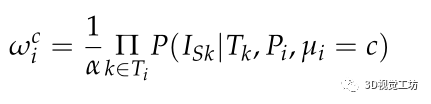
其中α是用于保證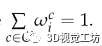 的常數。
的常數。
同樣,對于一個三維線段Lj,它在Isk的投影也會使所投影的線段Lj具有一個語義類別j∈C。通過計算投影線段的兩個端點以及線段中點到語義類C最近邊界的距離來描述重投影線段屬于語義類C的概率。可以確定線段中點離C最近邊界的距離越小,線段屬于C類的可能性越大。為了確保大多數線段屬于C類,到語義區域最近邊界距離最小的端點也應該被聯合考慮。
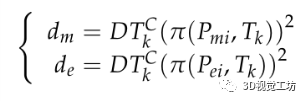
其中,dm和de分別表示從中點和端點到邊界的距離。
因此,投影線段屬于C類的概率用投影線段的中點和端點到C類邊界的距離來描述。線段的語義似然模型定義如下:
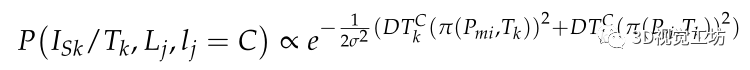
線段融合語義不變量的誤差可定義為:
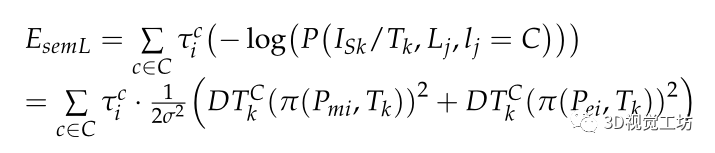
其中為類別概率向量,描述一系列攝像機觀測到的線段Lj,類別屬于C的情況:
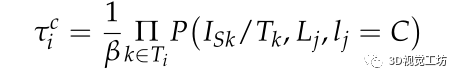
聯合語義不變量的誤差函數定義如下:
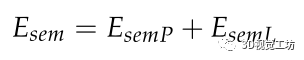
實驗
本節通過一系列的實驗來驗證本文提出的系統的有效性。利用彩色圖像進行語義分割是十分必要的。因此,使用公開可用的TartanAir數據集和KITTI數據集執行驗證,這兩個數據集都提供了ground-truth的顏色序列。TartanAir數據集是一個室內場景數據集,KITTI數據集是一個室外場景數據集。我們將我們的方法與幾種最先進的方法進行了比較,包括ORB-SLAM2和PL-SLAM。所有實驗都是在一臺CPU為Intel i5-4200U、內存為4GB、操作系統為Ubuntu 16.04的筆記本電腦上進行的。語義分割結果是使用Facebook AI Research推出的Detectron2算法得到的。實驗結果表明:
(1)添加語義不變量后,線段之間的不匹配明顯降低,線段匹配的準確率提高。
(2)在沒有動態目標干擾的室內場景中,該方法能較好地抑制軌跡漂移
(3)將語義不變性的結果應用于戶外場景的SLAM系統并不一定能有效地減少系統的軌跡漂移。產生這種結果的原因可能是室外場景的語義分割精度不夠高,語義類別劃分不夠精細,以及受到動態對象的影響。
(4)我們的系統基本能夠滿足實時性的要求。
結論
本文提出了一種融合語義不變量的點線立體SLAM系統。為了提高線段數據關聯的準確性,給出了線段的語義類別標簽。通過聯合語義不變量定義線段上的重投影誤差函數,實現線段的中期跟蹤,使系統在進行局部優化時獲得更好的結果,減少了軌跡中累積誤差的產生。在TartanAir數據集和KITTI數據集上驗證了該方法的有效性。將實驗結果與ORB-SLAM2和PL-SLAM系統進行了比較。結果表明,該算法能有效地提高系統的魯棒性,減少大部分序列的軌跡漂移。但是,由于對語義分割信息進行了預處理,在系統中沒有對原始圖像進行直接的實時分割。因此,后續將考慮實時語義分割的應用,進一步提高系統的完整性。
審核編輯:湯梓紅
-
傳感器
+關注
關注
2550文章
51035瀏覽量
753077 -
機器人
+關注
關注
211文章
28380瀏覽量
206916 -
函數
+關注
關注
3文章
4327瀏覽量
62571 -
SLAM
+關注
關注
23文章
423瀏覽量
31821
原文標題:結合語義不變量的點線立體視覺SLAM系統
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于多模態語義SLAM框架
HOOFR-SLAM的系統框架及其特征提取
一種多徑環境下的調制識別算法
基于不變量的軟錯誤檢測方法
高仙SLAM具體的技術是什么?SLAM2.0有哪些優勢?
一種融合語義模型的二分網絡推薦算法

基于視覺傳感器的ORB-SLAM系統的學習
基于視覺傳感器的SLAM系統學習
一種端到端的立體深度感知系統的設計

一個動態環境下的實時語義RGB-D SLAM系統
一種基于RGB-D圖像序列的協同隱式神經同步定位與建圖(SLAM)系統
一種完全分布式的點線協同視覺慣性導航系統
利用VLM和MLLMs實現SLAM語義增強






 工商網監
工商網監
評論