


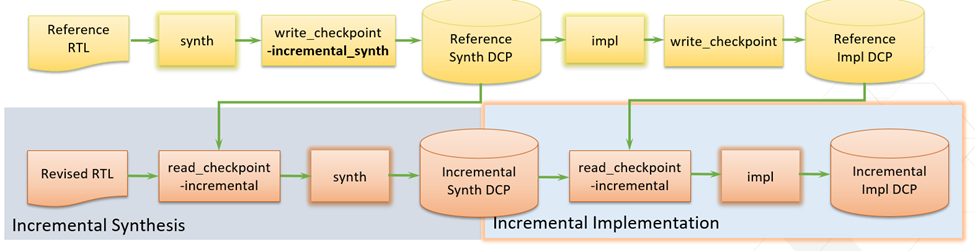
增量實現自從首次獲得支持以來,不斷升級演變,在此過程中已添加了多項針對性能和編譯時間的增強功能。它解決了實現階段針對快速迭代的需求,顯著節省了編譯時間,還能確保所得結果和性能的可預測性。 以下圖表顯示了在一整套困難的設計上采用增量實現流程后,所節省的編譯時間的變化趨勢:
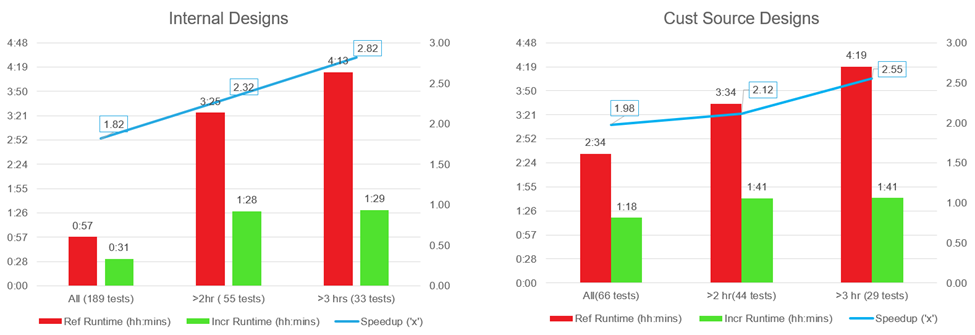
圖 1:2019.1 內部設計和外部設計通過增量實現流程節省的編譯時間
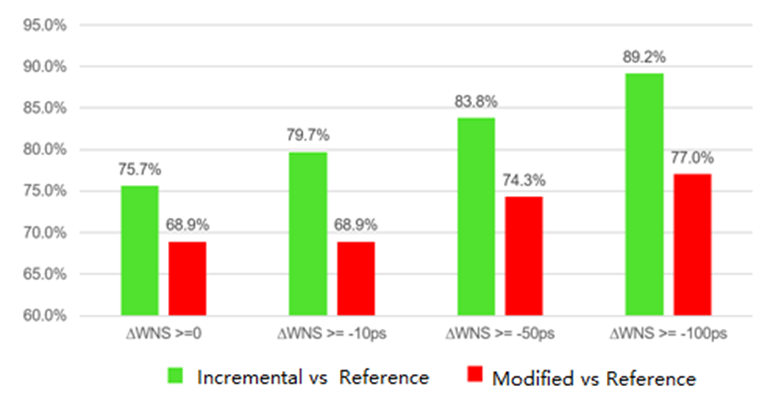
圖 2:2019.1 利用增量實現流程保證 QoR 可預測性
圖 1 顯示,對于運行時間超過 2 小時的設計,使用該流程前的編譯時間平均為使用后編譯時間的 2.12 倍(設計更改最多為 10%),節省編譯時間效果顯著。 圖 2 顯示了少量 RTL 更改的 QoR 可預測性指標。ΔWNS 顯示的是相較于參考運行輪次的 WNS 降幅。顯而易見,相比于默認運行輪次,增量編譯所得 QoR 可預測性更好。例外情況是,設計越小,初始化步驟在編譯總時間中占用時間越多,所以應用增量編譯給設計編譯時間帶來的助益就越少。
流程
工程模式和非工程模式都支持此流程。如果您使用 read_checkpoint -incremental 命令加載參考設計檢查點,并且指向參考 DCP 位置和名稱,那么即可對后續布局布線操作啟用增量編譯設計流程。 在非工程模式下,read_checkpoint -incremental 應晚于 opt_design 而早于 place_design。
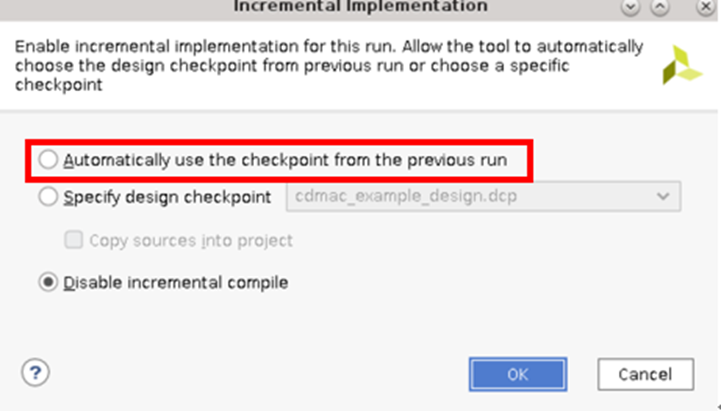
當前,自動模式和非自動模式均受支持。要啟用自動模式,您可打開實現設置,并選中“Automatically use the checkpoint from the previous run”(自動使用上一輪運行的檢查點)選項。如不勾選自動模式,也可將用戶所需的 DCP 指定為參考檢查點,以便指引后續輪次的運行。
何時使用此流程:
如果設計代碼穩定并且可以后續執行少量代碼修改,或者如果您當前正致力于時序收斂的最后沖刺階段并且已接近完成,那么此流程很有用。在這兩種情況下,您可能希望每個實現版本的生成周期都很短。 增量實現流程從參考檢查點讀取布局布線信息,并與當前 opt_design 后網表進行匹配比較。匹配的單元將得到復用,新添加的邏輯經最優化后,將在默認流程中運行。匹配的單元與不匹配的單元之間也將進行交叉最優化。
因此,如果大部分邏輯可復用,并且設計接近滿足時序,那么此流程對編譯時間的助益最大。 另一個用例是,如果您的設計困難,且距離收斂相去甚遠,但您想要在某些級別復用此設計(例如,SLR 級別、塊類型級別、模塊級別),那么也可以使用此流程。在此情況下,您可將增量模式更改為部分復用模式。
例如,以下約束行的效果等同于將所有 RAM 的位置從網表都反標注釋到 XDC 內并在下一輪運行中應用約束: read_checkpoint -incremental routed.dcp -reuse_objects [all_rams] -fix_objects [all_rams]
可能影響增量實現編譯時間的因素:
采用此流程前,請注意以下要點,這些要點有助于您充分發揮增量流程優勢:
選擇正確的檢查點。您需確保參考檢查點與受指引的設計處于同一器件內,實現時采用的 Vivado 版本與當前運行采用的版本相同。如果采用不同版本生成 DCP,可能會導致單元匹配減少,并且節省的編譯時間不及預期。
限制時序關鍵面積內的更改量,確保設計收斂的一致性和時序收斂。設計邏輯中更改過多可能會導致指引的結果欠佳或編譯時間延長。如果不能復用關鍵路徑的布局和布線,則需要做更多工作來保留時序。另外,如果少量設計更改引入了參考設計中不存在的新時序問題,則可能需要增加工作量和運行時間,而且設計可能不滿足時序。請始終確保所用 opt_design 指令匹配,因為更改 opt_design 可能導致更多單元名稱發生更改。
如果啟用自動模式,那么僅當參考運行的時序 >-0.250 ns 時,才會更新參考檢查點,換言之,您的參考檢查點的時序必須足夠好。 參考網表欠佳可能導致編譯時間延長。如果不更新參考檢查點,并且存在來自先前運行的現有檢查點,那么 Vivado 會嘗試使用該現有檢查點作為參考檢查點。否則,不存在參考檢查點時,它會還原為默認實現流程。 遵循默認運行行為時,Vivado 會遵循用戶所選的運行策略,編譯時間與非增量運行接近。
如果運行開始后存在檢查點(無論是更新還是預先存在的參考檢查點),就會運行與設計網表更改相關的第二種檢查算法,僅當滿足所要求的標準時才會使用增量流程。如果這些條件都沒有得到滿足,流程會自動回退到默認實現流程,在讀取檢查點增量后會發出以下信息:
WARNING: [Project 1-964] Cell Matching is less than the threshold needed to run Incremental flow. Switching to default Implementation flow
高復用模式:單元復用百分比高于 75% 時,就進入高復用模式。在高復用模式下,會對布局布線算法進行最優化,以便盡可能提高現有布局布線信息的復用率。高復用模式對于參考檢查點已達成時序收斂并且單元復用率不低于 95% 的設計最有效。舉例來說,在參考設計與當前設計之間存在少量設計更改,或者向設計添加調試核的情況下都是如此。
有 3 條指令可供 place_design 和 route_design 使用:
Default(默認):獲取與參考運行盡可能接近的結果。以參考設計 WNS 為目標。此模式能為典型用例達成最優化的編譯時間。
Explore(探索):嘗試盡可能改善時序。以 0.00 ns WNS 為目標。這會耗費更多編譯時間。
Quick(快速):運行布局布線命令,不調用時序引擎。這可提供最優化的編譯時間,在復用率高達 > 99.5% 的部分設計中,不影響 QoR。
低復用模式:如果設計相較參考檢查點存在大量更改,或者如果用戶對 read_checkpoint 命令使用-only_reuse 開關,指定僅復用參考檢查點中的少量單元,則進入低復用模式。 在低復用模式下,支持所有 place_design 指令和 route_design 指令,并且該工具將以 0.00 ns 的 WNS 為目標。相比于高復用模式,這樣可能會耗用更多編譯時間。低復用模式對于在特定面積內難以完成布局布線的設計最有效。例如,復用正常運行的塊存儲器或 DSP 布局,或者復用間歇性達成時序收斂設計的特定層級。
布局布線運行時間的初始化部分。 在簡短的布局布線運行中,Vivado 布局器和布線器的初始化開銷可能會抵消來自增量布局布線進程的任何增益。對于運行時間較長的設計,初始化在運行時間中所占的比例較小,因此編譯時間增益明顯。
通過啟用多線程可以進一步縮短實現的編譯時間。目前對于 Linux 系統,最大上限是 8 個線程。set_param general.maxThreads 8
生成增量編譯時間節省報告:
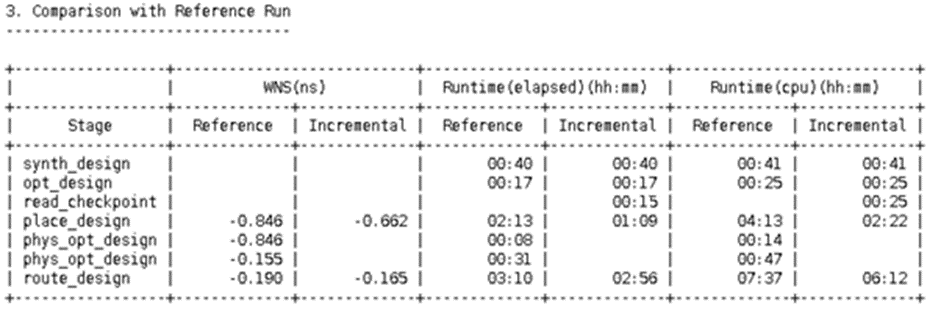
運行 report_incremental_reuse 命令,生成顯示增量復用情況的報告。此報告的第 3 部分列出了編譯時間(elapsed 和 cpu),顯示了每一步耗費的編譯時間。 由于增量運行的指引作用僅從 place_design 階段開始,您需要注意,增量運行所涉時間將包含用于讀入參考檢查點的 read_checkpoint 步驟,并且增量編譯時間的比較應僅從 place_design 開始。 下表顯示了包含 read_checkpoint 在內的每個階段的時間。此外,新網表的更改量對增量運行時間的影響可能更大。 請注意,增量運行中的 phys_opt_design 步驟是可選步驟,在流程中調用該步驟時,它將以默認模式運行,以進一步優化未受指引的路徑或已更改的路徑,對復用的路徑沒有影響。
總結:
通過采用增量實現流程,可以實現快速迭代的實現運行,但在運行此流程時需要考慮編譯時間和 QoR(質量結果)方面的妥協。
審核編輯:湯梓紅
-
Xilinx
+關注
關注
73文章
2185瀏覽量
125528 -
編譯
+關注
關注
0文章
679瀏覽量
34096 -
Vivado
+關注
關注
19文章
835瀏覽量
68872
原文標題:Xilinx Vivado使用增量實現
文章出處:【微信號:Hack電子,微信公眾號:Hack電子】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
關于Xilinx的vivado
下載Xilinx Vivado 2017.1時出錯
Vivado中的Incremental Compile增量編譯技術詳解
用Xilinx Vivado HLS可以快速、高效地實現QRD矩陣分解

Vivado Design Suite 2015.3的新功能介紹
Vivado Design Suite 2015.3新增量編譯功能介紹
如何使用Vivado設計套件配合Xilinx評估板的設計
講述增量編譯方法,提高Vivado編譯效率






 工商網監
工商網監

評論