


“AI數鋼筋”——通過人工智能技術實現鋼筋數量統計的整體方案解讀。
導讀
在社會智能化的發展趨勢之下,越來越多的傳統行業開始向著數字化的方向轉型,而建筑行業也正經歷著通過人工智能技術實現的改革。
鋼筋是建筑業的重要材料,龐大的數量、工地現場環境復雜以及人工點驗錯漏等現實因素為鋼筋點驗工作制造了難度,那么如何才能快速且準確地完成對于整個建筑施工過程極為重要的鋼筋點驗工作環節呢?今天就帶大家了解一下“AI數鋼筋”——通過人工智能技術實現鋼筋數量統計。
1問題背景
鋼筋數量統計是鋼材生產、銷售過程及建筑施工過程中的重要環節。目前,工地現場是采用人工計數的方式對進場的車輛裝載的鋼筋進行計數,驗收人員需要對車上的鋼筋進行現場人工點根,在對鋼筋進行打捆后,通過不同顏色的標記來區分鋼筋是否計數,在確認數量后鋼筋車才能完成進場卸貨
這種人工計數的方式不僅浪費大量的時間和精力、效率低下,并且工人長時間高強度的工作使其視覺和大腦很容易出現疲勞,導致計數誤差大大增加,人工計數已經不能滿足鋼筋生產廠家自動化生產和工地現場物料盤點精準性的需求,這種現狀促使鋼筋數量統計向著智能化方向發展。
所謂“AI數鋼筋”就是,通過多目標檢測機器視覺方法以實現鋼筋數量智能統計,達到提高勞動效率和鋼筋數量統計精確性的效果。目標檢測算法通過與攝像頭結合,可以實現自動鋼筋計數,再結合人工修改少量誤檢的方式,可以智能、高效地完成鋼筋計數任務。
2算法介紹
2.1 目標檢測介紹
首先,讓我們一起了解一下什么是“目標檢測”。
目標檢測是對圖像分類任務的進一步加深,目標檢測不僅要識別出圖片中各種類別的目標,還要將目標的位置找出來用矩形框框住。

目標檢測結果如上圖所示,將需要檢測的目標檢測出來并用邊界框框出來,同時在框子上面顯示出該目標屬于該分類的一個得分情況。
2.2目標檢測算法的基本流程
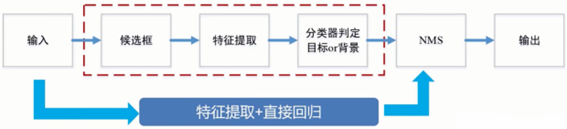
目標檢測實際上是要同時解決定位和識別兩個問題。傳統目標檢測算法的基本流程是,首先給定待檢測圖片,對其進行候選框提取,候選框的提取是通過滑動窗口的方式進行的;再對每個窗口的局部信息進行特征提取;然后對候選區域提取出的特征進行分類判定,判斷當前窗口中的對象是目標還是背景;最后采用非極大值抑制(Non-Maximum Suppression,NMS)方法進行篩選,去除重復窗口,找出最佳目標檢測位置。
2.3算法選擇
本次鋼筋計數任務,將選擇單階段目標檢測YOLO系列算法來完成。YOLO系列算法是目前使用最多的目標檢測算法,它最大的特點就是檢測速度快,并且現在檢測精度(即mAP)也逐步提高,因而成為時下最熱門的目標檢測算法之一。YOLO系列算法一共有5個版本,其中YOLO v1到v3是由同一個作者Joseph設計的,YOLO v4到v5則由其他作者設計,目前YOLO v1到YOLO v4已有相關論文和算法結構設計,而YOLO v5僅有算法結構設計,尚無論文發表,為此我們選擇這一較新的YOLO v5算法作為本次鋼筋計數算法研究的對象。
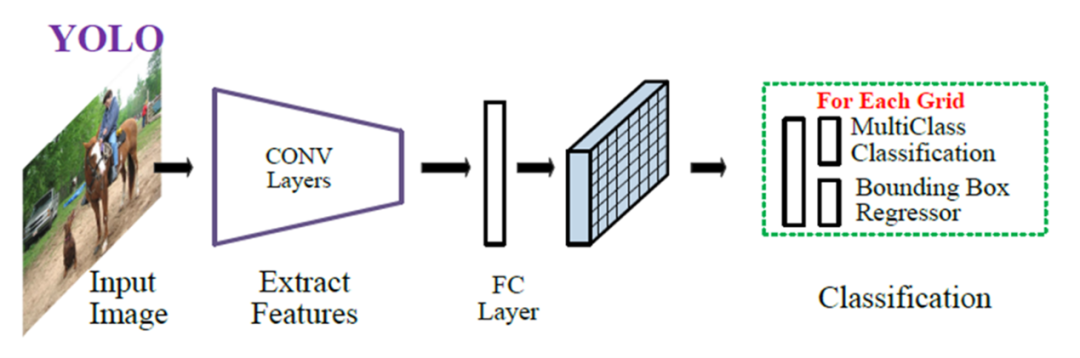
YOLO算法是將目標檢測問題轉化為回歸問題,使用回歸的思想,對給定輸入圖像,直接在圖像的多個位置上回歸出這個位置的目標邊框以及目標類別。給定一個輸入圖像,將其劃分為S*S的網格,如果某目標的中心落于網格中,則該網格負責預測該目標,對于每一個網格,預測B個邊界框及邊界框的置信度,包含邊界框含有目標的可能性大小和邊界框的準確性,此外對于每個網格還需預測在多個類別上的概率。在完成目標窗口的預測之后,根據閾值去除可能性比較低的目標窗口,最后NMS去除冗余窗口即可,整個過程非常簡單,不需要中間的候選框生成網絡,直接回歸便完成了位置和類別的判定。下圖是YOLO v5算法基本框架:
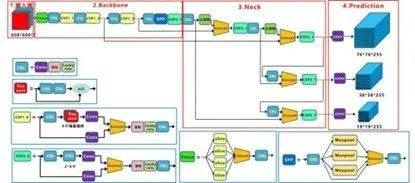
由上圖可知,YOLO v5主要由輸入端、Backbone、Neck以及Prediction四部分組成。其中各部分含義分別為:
Backbone:在不同圖像細粒度上聚合并形成圖像特征的卷積神經網絡。
Neck:一系列混合和組合圖像特征的網絡層,并將圖像特征傳遞到預測層。
Prediction(輸出端):對圖像特征進行預測,生成邊界框和并預測類別。
YOLO v5各組成部分包括的基礎組件有:
CBL:由Conv+BN+Leaky_relu激活函數組成
Res unit:借鑒ResNet網絡中的殘差結構,用來構建深層網絡
CSP1_X:借鑒CSPNet網絡結構,該模塊由CBL模塊、Res unint模塊以及卷積層、Concate組成
CSP2_X:借鑒CSPNet網絡結構,該模塊由卷積層和X個Res unint模塊Concate組成而成
Focus:首先將多個slice結果Concat起來,然后將其送入CBL模塊中
SPP:采用1×1、5×5、9×9和13×13的最大池化方式,進行多尺度特征融合
YOLO v5各組成部分詳細介紹
(1)輸入端
YOLO v5使用Mosaic數據增強操作提升模型的訓練速度和網絡的精度;并提出了一種自適應錨框計算與自適應圖片縮放方法。
Mosaic數據增強
Mosaic數據增強利用四張圖片,并且按照隨機縮放、隨機裁剪和隨機排布的方式對四張圖片進行拼接,每一張圖片都有其對應的框,將四張圖片拼接之后就獲得一張新的圖片,同時也獲得這張圖片對應的框,然后我們將這樣一張新的圖片傳入到神經網絡當中去學習,相當于一下子傳入四張圖片進行學習了。該方法極大地豐富了檢測物體的背景,且在標準化BN計算的時候一下子計算四張圖片的數據,所以本身對batch size不是很依賴。
自適應錨框計算
在YOLO系列算法中,針對不同的數據集,都需要設定特定長寬的錨點框。在網絡訓練階段,模型在初始階段,模型在初始錨點框的基礎上輸出對應的預測框,計算其與GT框之間的差距,并執行反向更新操作,從而更新整個網絡的參數,因此設定初始錨點框是比較關鍵的一環。在YOLO v3和YOLO v4中,訓練不同的數據集,都是通過單獨的程序運行來獲得初始錨點框。而在YOLO v5中將此功能嵌入到代碼中,每次訓練時,根據數據集的名稱自適應的計算出最佳的錨點框,用戶可以根據自己的需求將功能關閉或者打開,指令為:
自適應圖片縮放
在目標檢測算法中,不同的圖片長寬都不相同,因此常用的方式是將原始圖片統一縮放到一個標準尺寸,再送入檢測網絡中。而原始的縮放方法存在著一些問題,由于在實際的使用中的很多圖片的長寬比不同,因此縮放填充之后,兩端的黑邊大小都不相同,然而如果填充的過多,則會存在大量的信息冗余,從而影響整個算法的推理速度。為了進一步提升YOLO v5的推理速度,該算法提出一種方法能夠自適應的添加最少的黑邊到縮放之后的圖片中。具體的實現步驟如下所述:
① 根據原始圖片大小以及輸入到網絡的圖片大小計算縮放比例
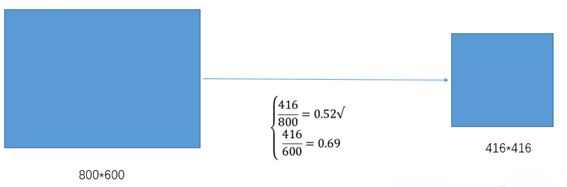
②根據原始圖片大小與縮放比例計算縮放后的圖片大小

③計算黑邊填充數值
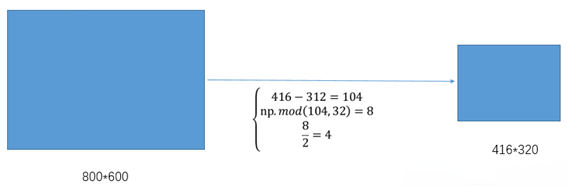
其中,416表示YOLO v5網絡所要求的圖片寬度,312表示縮放后圖片的寬度。首先執行相減操作來獲得需要填充的黑邊長度104;然后對該數值執行取余操作,即104%32=8,使用32是因為整個YOLOv5網絡執行了5次下采樣操作。最后對該數值除以2,也就是將填充的區域分散到兩邊。這樣將416*416大小的圖片縮小到416*320大小,因而極大地提升了算法的推理速度。
(2)Backone 網絡
Focus結構
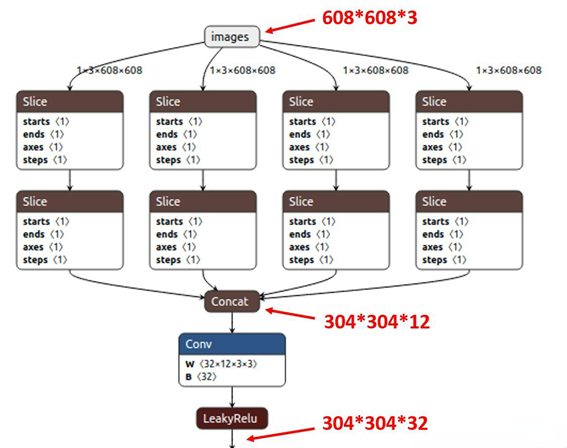
Focus對圖片進行切片操作,具體操作是在一張圖片中每隔一個像素拿到一個值,類似于鄰近下采樣,這樣就拿到了四張圖片,四張圖片互補,長的差不多,但是沒有信息丟失,因此將W、H信息就集中到通道空間,輸入通道擴充了4倍,即拼接起來的圖片相對于原先的RGB三通道模式變成了12個通道,最后將得到的新圖片再經過卷積操作,最終得到了沒有信息丟失情況下的二倍下采樣特征圖。如下圖所示,原始輸入圖片大小為608*608*3,經過Slice與Concat操作之后輸出一個304*304*12的特征映射;接著經過一個通道個數為32的Conv層,輸出一個304*304*32大小的特征映射。
CSP結構
CSPNet主要是將feature map拆成兩個部分,一部分進行卷積操作,另一部分和上一部分卷積操作的結果進行concate。在分類問題中,使用CSPNet可以降低計算量,但是準確率提升很小;在目標檢測問題中,使用CSPNet作為Backbone帶來的提升比較大,可以有效增強CNN的學習能力,同時也降低了計算量。YOLO v5設計了兩種CSP結構,CSP1_X結構應用于Backbone網絡中,CSP2_X結構應用于Neck網絡中。
(3)Neck網絡
在YOLO v4中開始使用FPN-PAN。其結構如下圖所示,FPN層自頂向下傳達強語義特征,而PAN塔自底向上傳達定位特征。
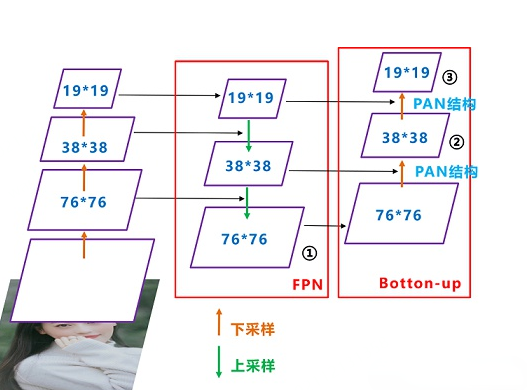
YOLO v5的Neck仍采用了FPN+PAN結構,但是在它的基礎上做了一些改進操作,YOLO v4的Neck結構中,采用的都是普通的卷積操作,而YOLO v5的Neck中,采用CSPNet設計的CSP2結構,從而加強了網絡特征融合能力。
(4)輸出端
YOLO v5采用CIOU_LOSS 作為bounding box 的損失函數,分類分支采用的loss是BCE,conf分支也是BCE。
YOLO v5中最有亮點的改變是對正樣本的定義。在YOLO v3中,其正樣本區域也就是anchor匹配策略非常粗暴:保證每個gt bbox一定有一個唯一的anchor進行對應,匹配規則就是IOU最大,并且某個gt一定不可能在三個預測層的某幾層上同時進行匹配。然而,我們從FCOS等論文中了解到,增加高質量的正樣本anchor能夠加速模型收斂并提高召回。因此,YOLO v5對此做出了改進,提出匹配規則:
采用shape匹配規則,分別將ground truth的寬高與anchor的寬高求比值,如果寬高比例小于設定閾值,則說明該GT和anchor匹配,將該anchor認定為正樣本。否則,該anchor被濾掉,不參與bbox與分類計算。
將GT的中心最鄰近網格也作為正樣本anchor的參考點。因此,bbox的xy回歸分支的取值范圍不再是0-1,而是-0.5-1.5(0.5是網格中心偏移),因為跨網格預測了
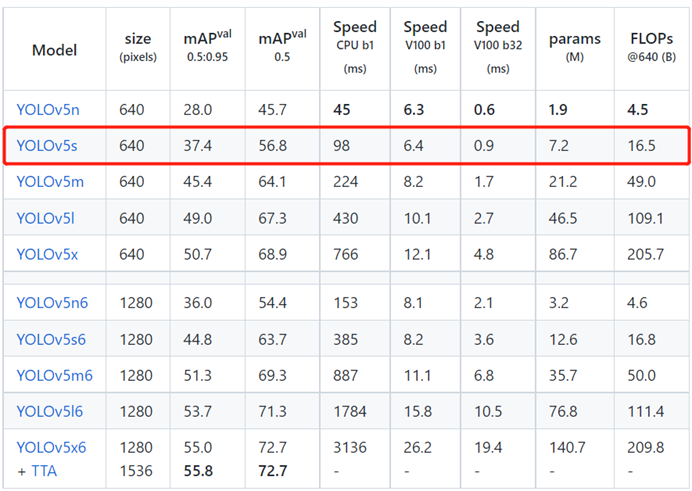
YOLO v5算法目前根據網絡大小分為5n、5s、5m、5l、5x,具體參數量大小、單幀、檢測速度和mAP如下圖所示。

3訓練模型
3.1 數據集選擇
我們選擇公開鋼筋計數數據集進行模型訓練,可以從以下網址中獲取數據集進行測試。https://www.datafountain.cn/competitions/332/datasets
在上述數據集中,鋼筋數據來自現場手機采集。鋼筋車輛進庫時,使用手機拍攝成捆鋼筋的截面(一般保證較小傾角,盡量垂直于鋼筋截面拍攝)。數據會包含直徑從12mm-32mm等不同規格的鋼筋圖片。數據集中用于訓練的圖像集合共250張,用于測試的圖像集合共200張。
由于選擇的數據集規模較小且僅有一類檢測目標(鋼筋),為降低模型訓練難度,防止模型出現過擬合,所以算法模型選擇較小的yolov5s模型。如果選擇不同的數據集,也可根據所選數據集的實際情況來選擇算法模型。
3.2模型訓練
首先在以下網址獲取YOLO v5算法的源碼:https://github.com/ultralytics/yolov5
其中所包含的項目文件有:
data:主要是存放一些超參數的配置文件以及官方提供測試的圖片。
models:里面主要是一些網絡構建的配置文件和函數,其中包含了該項目的五個不同的版本,分別為是5n、5s、5m、5l、5x。
utils:存放的是工具類的函數,里面有loss函數,metrics函數,plots函數等等。
weights:放置訓練好的權重參數。
detect.py:利用訓練好的權重參數進行目標檢測,可以進行圖像、視頻和攝像頭的檢測。
train.py:訓練自己的數據集的函數。
test.py:測試訓練的結果的函數。
requirements.txt:yolov5項目的環境依賴包
YOLO v5各組成部分詳細介紹
接下來就要進行模型訓練的具體操作,訓練主要包括環境搭建、數據集準備及修改數據集配置、修改模型配置參數、下載預訓練模型、開始訓練以及模型測試這幾個步驟。接下來依次對上述步驟展開介紹。
(1)環境搭建
我們需要創建一個虛擬環境,打開conda powershell prompt創建一個用于訓練的虛擬環境:
condacreate-nyolov5python==3.8
然后激活虛擬環境安裝所需模塊(注意安裝之前需要切換工作路徑至yolov5文件夾)
python-mpipinstall-rrequirements.txt-ihttp://pypi.douban.com/simple/--trusted-host=pypi.douban.com/simple
如果沒有安裝cuda默認安裝pytorch-cpu版,如果有gpu可以安裝pytorch-gpu版。
(2)數據集準備及修改數據集配置
首先將下載好的數據集分類并按如下方式存儲:

然后對數據集配置進行修改,修改data目錄下的相應的yaml文件。找到目錄下的coco.yaml文件,將該文件復制一份,將復制的文件重命名。
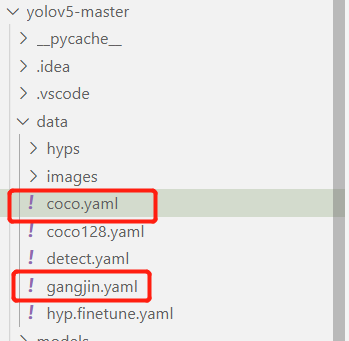
打開這個文件夾修改其中的參數,修改結果如下圖所示:

其中第一個框的位置填寫訓練集測試集和驗證集的目錄地址,第二個框的位置填寫檢測目標類別數,第三個框填寫待檢測類別。
(3)修改模型配置參數
由于我們最后選擇yolov5s這個模型訓練,并且使用官方yolov5s.pt預訓練權重參數進行訓練,所以需要修改模型配置文件。和上述修改data目錄下的yaml文件一樣,最好將yolov5s.yaml文件復制一份,然后將其重命名。
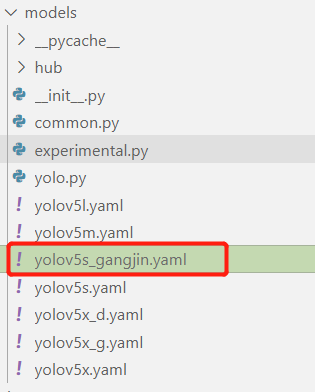
然后對重命名文件進行修改,修改第一行檢測目標類別數。

(4)下載預訓練模型
我們需要在官網下載所需預訓練模型,即在預訓練模型地址(https://github.com/ultralytics/)中選擇所需要的模型下載即可,這里我們選擇下載yolov5s.pt。
模型下載完成后,將模型文件xx.pt復制到yolov5文件夾下。
(5)開始訓練
在Yolov5文件夾下打開終端輸入以下命令:
Pythontrain.py--weightsyolov5s.pt--datadata/gangjin.yaml--workers1--batch-size8
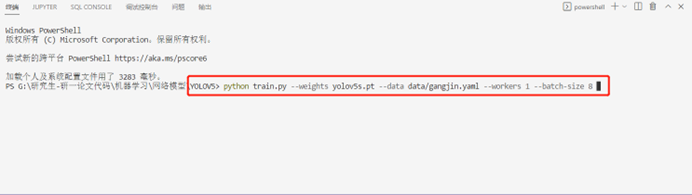
至此,模型訓練正式開始。
(6)模型測試
在模型訓練完成后,將runs/exp/weights下的模型(best.pt)復制到yolov5文件夾下。
然后開始進行模型測試:
pythondetect.py--weightsbest.pt--source../datasets/gangjin/images/val--save-txt
其中,--weights best.pt是訓練好的模型路徑,--source:是測試的數據路徑。測試結果保存在runs/detect/exp文件夾下。
4測試結果及問題分析
4.1 測試結果
本算法的輸入為較為清晰的成捆鋼筋圖片,
算法的輸出結果為result.txt文件與預測結果圖,其中result.txt文件中會顯示圖片中每個檢測框的位置、類別及置信度,并給出檢測框的總個數,從而實現了鋼筋自動計數。
從以上測試結果可以看出,YOLO v5算法對于該場景中的鋼筋計數具有很好的準確性,并且有較大的置信度。
對更多的圖片場景進行鋼筋計數,并將輸入的實際位置與識別出的效果圖進行對比,觀察YOLO v5算法對于該場景的計數效果。
從以上測試結果可以看出,YOLO v5算法對于該場景中的鋼筋計數同樣具有很好的準確性以及較大的置信度。
4.2問題分析
當然YOLO v5算法并非十全十美,它在鋼筋檢測中也存在一定的問題:
算法存在誤判,將其他物體誤判為鋼筋頭:
重復檢測,一個鋼筋頭被多個檢測框標注:
5總結
以上就是對于數鋼筋問題的介紹,主要從問題背景、算法介紹和訓練模型三部分展開。首先簡述了數鋼筋問題的基本背景,然后介紹了目標檢測算法的算法流程和選取的YOLO v5算法的基本知識,最后介紹了模型訓練步驟,并選取一定的數據集,采用YOLO v5算法對輸入的圖像進行目標檢測及計數。
審核編輯:彭菁
-
模型
+關注
關注
1文章
3527瀏覽量
50497 -
目標檢測
+關注
關注
0文章
228瀏覽量
16038 -
數據集
+關注
關注
4文章
1224瀏覽量
25486 -
人工智能技術
+關注
關注
2文章
222瀏覽量
10796
原文標題:
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論