") 斯坦福教授Manning長文梳理:十年后的基礎(chǔ)模型能成AGI嗎?
斯坦福教授Manning長文梳理:十年后的基礎(chǔ)模型能成AGI嗎?
【新智元導(dǎo)讀】從手工規(guī)則、神經(jīng)網(wǎng)絡(luò)到Transformer基礎(chǔ)模型,自然語言處理的未來是統(tǒng)一多模態(tài),走向通用人工智能!
過去十年間,僅靠簡單的神經(jīng)網(wǎng)絡(luò)計(jì)算,以及大規(guī)模的訓(xùn)練數(shù)據(jù)支持,自然語言處理領(lǐng)域取得了相當(dāng)大的突破,由此訓(xùn)練得到的預(yù)訓(xùn)練語言模型,如BERT、GPT-3等模型都提供了強(qiáng)大的通用語言理解、生成和推理能力。
前段時(shí)間,斯坦福大學(xué)大學(xué)教授Christopher D. Manning在Daedalus期刊上發(fā)表了一篇關(guān)于「人類語言理解和推理」的論文,主要梳理自然語言處理的發(fā)展歷史,并分析了基礎(chǔ)模型的未來發(fā)展前景。
論文作者Christopher Manning是斯坦福大學(xué)計(jì)算機(jī)與語言學(xué)教授,也是將深度學(xué)習(xí)應(yīng)用于自然語言處理領(lǐng)域的領(lǐng)軍者,研究方向?qū)W⒂诶?a target="_blank">機(jī)器學(xué)習(xí)方法處理計(jì)算語言學(xué)問題,以使計(jì)算機(jī)能夠智能處理、理解并生成人類語言。
Manning教授是ACM Fellow,AAAI Fellow 和ACL Fellow,他的多部著作,如《統(tǒng)計(jì)自然語言處理基礎(chǔ)》、《信息檢索導(dǎo)論》等都成為了經(jīng)典教材,其課程斯坦福CS224n《深度學(xué)習(xí)自然語言處理》更是無數(shù)NLPer的入門必看。
NLP的四個(gè)時(shí)代
第一時(shí)代(1950-1969)
NLP的研究最早始于機(jī)器翻譯的研究,當(dāng)時(shí)的人們認(rèn)為,翻譯任務(wù)可以基于二戰(zhàn)期間在密碼破譯的成果繼續(xù)發(fā)展,冷戰(zhàn)的雙方也都在開發(fā)能夠翻譯其他國家科學(xué)成果的系統(tǒng),不過在此期間,人們對自然語言、人工智能或機(jī)器學(xué)習(xí)的結(jié)構(gòu)幾乎一無所知。
當(dāng)時(shí)的計(jì)算量和可用數(shù)據(jù)都非常少,雖然最初的系統(tǒng)被大張旗鼓地宣傳,但這些系統(tǒng)只提供了單詞級的翻譯查找和一些簡單的、基于規(guī)則的機(jī)制來處理單詞的屈折形式(形態(tài)學(xué))和詞序。
第二時(shí)代(1970-1992)
這一時(shí)期可以看到一系列NLP演示系統(tǒng)的發(fā)展,在處理自然語言中的語法和引用等現(xiàn)象方面表現(xiàn)出了復(fù)雜性和深度,包括Terry Winograd的SHRDLU,Bill Woods的LUNAR,Roger Schank的SAM,加里Hendrix的LIFER和Danny Bobrow的GUS,都是手工構(gòu)建的、基于規(guī)則的系統(tǒng),甚至還可用用于諸如數(shù)據(jù)庫查詢之類的任務(wù)。
語言學(xué)和基于知識的人工智能正在迅速發(fā)展,在這個(gè)時(shí)代的第二個(gè)十年,出現(xiàn)了新一代手工構(gòu)建的系統(tǒng),在陳述性語言知識和程序處理之間有著明確的界限,并且受益于語言學(xué)理論的發(fā)展。
第三時(shí)代(1993-2012)
在此期間,數(shù)字化文本的可用數(shù)量顯著提升,NLP的發(fā)展逐漸轉(zhuǎn)為深度的語言理解,從數(shù)千萬字的文本中提取位置、隱喻概念等信息,不過仍然只是基于單詞分析,所以大部分研究人員主要專注于帶標(biāo)注的語言資源,如標(biāo)記單詞的含義、公司名稱、樹庫等,然后使用有監(jiān)督機(jī)器學(xué)習(xí)技術(shù)來構(gòu)建模型。
第四時(shí)代(2013-現(xiàn)在)
深度學(xué)習(xí)或人工神經(jīng)網(wǎng)絡(luò)方法開始發(fā)展,可以對長距離的上下文進(jìn)行建模,單詞和句子由數(shù)百或數(shù)千維的實(shí)值向量空間進(jìn)行表示,向量空間中的距離可以表示意義或語法的相似度,不過在執(zhí)行任務(wù)上還是和之前的有監(jiān)督學(xué)習(xí)類似。
2018年,超大規(guī)模自監(jiān)督神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)取得了重大成功,可以簡單地輸入大量文本(數(shù)十億個(gè)單詞)來學(xué)習(xí)知識,基本思想就是在「給定前幾個(gè)單詞」的情況下連續(xù)地預(yù)測下一個(gè)單詞,重復(fù)數(shù)十億次預(yù)測并從錯(cuò)誤中學(xué)習(xí),然后就可以用于問答或文本分類任務(wù)。
預(yù)訓(xùn)練的自監(jiān)督方法的影響是革命性的,無需人類標(biāo)注即可產(chǎn)生一個(gè)強(qiáng)大的模型,后續(xù)簡單微調(diào)即可用于各種自然語言任務(wù)。
模型架構(gòu)
自2018年以來,NLP應(yīng)用的主要神經(jīng)網(wǎng)絡(luò)模型轉(zhuǎn)為Transformer神經(jīng)網(wǎng)絡(luò),核心思想是注意力機(jī)制,單詞的表征計(jì)算為來自其他位置單詞表征的加權(quán)組合。
Transofrmer一個(gè)常見的自監(jiān)督目標(biāo)是遮罩文本中出現(xiàn)的單詞,將該位置的query, key和value向量與其他單詞進(jìn)行比較,計(jì)算出注意力權(quán)重并加權(quán)平均,再通過全連接層、歸一化層和殘差連接來產(chǎn)生新的單詞向量,再重復(fù)多次增加網(wǎng)絡(luò)的深度。
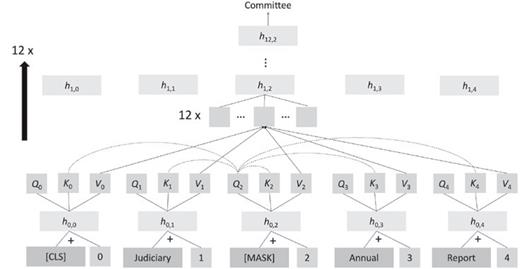
雖然Transformer的網(wǎng)絡(luò)結(jié)構(gòu)看起來不復(fù)雜,涉及到的計(jì)算也很簡單,但如果模型參數(shù)量足夠大,并且有大量的數(shù)據(jù)用來訓(xùn)練預(yù)測的話,模型就可以發(fā)現(xiàn)自然語言的大部分結(jié)構(gòu),包括句法結(jié)構(gòu)、單詞的內(nèi)涵、事實(shí)知識等。
prompt生成
從2018年到2020年,研究人員使用大型預(yù)訓(xùn)練語言模型(LPLM)的主要方法就是使用少量的標(biāo)注數(shù)據(jù)進(jìn)行微調(diào),使其適用于自定義任務(wù)。
但GPT-3(Generative Pre-training Transformer-3)發(fā)布后,研究人員驚訝地發(fā)現(xiàn),只需要輸入一段prompt,即便在沒有訓(xùn)練過的新任務(wù)上,模型也可以很好地完成。
相比之下,傳統(tǒng)的NLP模型由多個(gè)精心設(shè)計(jì)的組件以流水線的方式組裝起來,先捕獲文本的句子結(jié)構(gòu)和低級實(shí)體,然后再識別出更高層次的含義,再輸入到某些特定領(lǐng)域的執(zhí)行組件中。
在過去的幾年里,公司已經(jīng)開始用LPLM取代這種傳統(tǒng)的NLP解決方案,通過微調(diào)來執(zhí)行特定任務(wù)。
機(jī)器翻譯
早期的機(jī)器翻譯系統(tǒng)只能在有限的領(lǐng)域中覆蓋有限的語言結(jié)構(gòu)。
2006年推出的谷歌翻譯首次從大規(guī)模平行語料中構(gòu)建統(tǒng)計(jì)模型;2016年谷歌翻譯轉(zhuǎn)為神經(jīng)機(jī)器翻譯系統(tǒng),質(zhì)量得到極大提升;2020年再次更新為基于Transformer的神經(jīng)翻譯系統(tǒng),不再需要兩種語言的平行語料,而是采用一個(gè)巨大的預(yù)訓(xùn)練網(wǎng)絡(luò),通過一個(gè)特別的token指示語言類型進(jìn)行翻譯。
問答任務(wù)
問答系統(tǒng)需要在文本集合中查找相關(guān)信息,然后提供特定問題的答案,下游有許多直接的商業(yè)應(yīng)用場景,例如售前售后客戶支持等。
現(xiàn)代神經(jīng)網(wǎng)絡(luò)問答系統(tǒng)在提取文本中存在的答案具有很高的精度,也相當(dāng)擅長分類出不存在答案的文本。
分類任務(wù)
對于常見的傳統(tǒng)NLP任務(wù),例如在一段文本中識別出人員或組織名稱,或者對文本中關(guān)于產(chǎn)品的情感進(jìn)行分類(積極或消極),目前最好的系統(tǒng)仍然是基于LPLM的微調(diào)。
文本生成
除了許多創(chuàng)造性的用途之外,生成系統(tǒng)還可以編寫公式化的新聞文章,比如體育報(bào)道、自動摘要等,也可以基于放射科醫(yī)師的檢測結(jié)果生成報(bào)告。
不過,雖然效果很好,但研究人員們?nèi)匀缓軕岩蛇@些系統(tǒng)是否真的理解了他們在做什么,或者只是一個(gè)無意義的、復(fù)雜的重寫系統(tǒng)。
意義(meaning)
語言學(xué)、語言哲學(xué)和編程語言都在研究描述意義的方法,即指稱語義學(xué)方法(denotational semantics)或指稱理論(heory of reference):一個(gè)詞、短語或句子的意義是它所描述的世界中的一組對象或情況(或其數(shù)學(xué)抽象)。
現(xiàn)代NLP的簡單分布語義學(xué)認(rèn)為,一個(gè)詞的意義只是其上下文的描述,Manning認(rèn)為,意義產(chǎn)生于理解語言形式和其他事物之間的聯(lián)系網(wǎng)絡(luò),如果足夠密集,就可以很好地理解語言形式的意義。
LPLM在語言理解任務(wù)上的成功,以及將大規(guī)模自監(jiān)督學(xué)習(xí)擴(kuò)展到其他數(shù)據(jù)模態(tài)(如視覺、機(jī)器人、知識圖譜、生物信息學(xué)和多模態(tài)數(shù)據(jù))的廣泛前景,使得AI變得更加通用。
基礎(chǔ)模型
除了BERT和GPT-3這樣早期的基礎(chǔ)模型外,還可以將語言模型與知識圖神經(jīng)網(wǎng)絡(luò)、結(jié)構(gòu)化數(shù)據(jù)連接起來,或是獲取其他感官數(shù)據(jù),以實(shí)現(xiàn)多模態(tài)學(xué)習(xí),如DALL-E模型,在成對的圖像、文本的語料庫進(jìn)行自監(jiān)督學(xué)習(xí)后,可以通過生成相應(yīng)的圖片來表達(dá)新文本的含義。
我們目前還處于基礎(chǔ)模型研發(fā)的早期,但未來大多數(shù)信息處理和分析任務(wù),甚至像機(jī)器人控制這樣的任務(wù),都可以由相對較少的基礎(chǔ)模型來處理。
雖然大型基礎(chǔ)模型的訓(xùn)練是昂貴且耗時(shí)的,但訓(xùn)練完成后,使其適應(yīng)于不同的任務(wù)還是相當(dāng)容易的,可以直接使用自然語言來調(diào)整模型的輸出。
但這種方式也存在風(fēng)險(xiǎn):
1. 有能力訓(xùn)練基礎(chǔ)模型的機(jī)構(gòu)享受的權(quán)利和影響力可能會過大;
2. 大量終端用戶可能會遭受模型訓(xùn)練過程中的偏差影響;
3. 由于模型及其訓(xùn)練數(shù)據(jù)非常大,所以很難判斷在特定環(huán)境中使用模型是否安全。
雖然這些模型的最終只能模糊地理解世界,缺乏人類水平的仔細(xì)邏輯或因果推理能力,但基礎(chǔ)模型的廣泛有效性也意味著可以應(yīng)用的場景非常多,下一個(gè)十年內(nèi)或許可以發(fā)展為真正的通用人工智能。
-
人工智能
+關(guān)注
關(guān)注
1791文章
47183瀏覽量
238264 -
Agi
+關(guān)注
關(guān)注
0文章
80瀏覽量
10204 -
自然語言處理
+關(guān)注
關(guān)注
1文章
618瀏覽量
13552
原文標(biāo)題:NLP七十年!斯坦福教授Manning長文梳理:十年后的基礎(chǔ)模型能成AGI嗎?
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
臺積電新任CTO由美國斯坦福教授黃漢森出任
斯坦福開發(fā)過熱自動斷電電池
積累的編程知識在十年后將有一半沒用
關(guān)于斯坦福的CNTFET的問題
效率可達(dá)離子電池十倍的輕型紙電池在斯坦福誕生
全球無線電源產(chǎn)品出貨量十年后增至10億
李飛飛重返斯坦福后大動作 布斯坦福開啟以人為中心的AI計(jì)劃
斯坦福開啟以人為中心的AI計(jì)劃
十年后的網(wǎng)絡(luò)將支撐萬億級連接服務(wù)并具有六大特性
預(yù)測十年后光纖傳輸系統(tǒng)技術(shù):干線單波長可達(dá)Tbps 單纖可達(dá)Pbps量級
2021年斯坦福關(guān)于AI的全面報(bào)告
芯片能屯一堆十年后暴漲再賣掉嗎?
GPT-4就是AGI!谷歌斯坦福科學(xué)家揭秘大模型如何超智能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論