

摘要
旋轉(zhuǎn)位置編碼(RoPE)已被證明可以有效地在基于Transformer的語言模型中編碼位置信息。然而,這些模型在超過它們訓(xùn)練的序列長度后無法推廣。我們提出了YaRN(另一種RoPE擴展方法),這是一種計算高效的方法,可以擴展此類模型的上下文窗口,所需token減少10倍,訓(xùn)練步驟減少2.5倍。使用YaRN,我們展示了LLaMA模型可以有效地利用和推斷出比其原始預(yù)訓(xùn)練允許的上下文長度長得多的上下文長度,并且在上下文窗口擴展中達到了SOTA。此外,我們證明YaRN表現(xiàn)出了超越微調(diào)數(shù)據(jù)集有限上下文的能力。
背景知識
旋轉(zhuǎn)位置編碼

位置插值

附加符號

方法
然而,盡管PI在所有RoPE維度上實現(xiàn)了均等的拉伸,但我們發(fā)現(xiàn)PI所描述的理論插值界限在預(yù)測RoPE與LLM內(nèi)部嵌入之間的復(fù)雜動態(tài)時不足夠準確。在接下來的小節(jié)中,我們分別描述了我們在PI中找到的主要問題,并解決了這些問題,以便向讀者提供每種方法的背景、起源和理論依據(jù),以此來獲得完整的YaRN方法。
高頻信息丟失 - “NTK 感知”插值
為了解決在插值RoPE嵌入時丟失高頻信息的問題,[4]中開發(fā)了"NTK-aware"插值。與同樣乘以因子s的方式相比,我們通過在多個維度上縮放高頻率較小并且低頻率較大的方式來分散插值壓力。可以通過多種方式獲得這樣的轉(zhuǎn)換,但最簡單的方式是對θ的值進行基變換。我們希望最低頻率的縮放與線性位置縮放盡可能一致,并且最高頻率保持不變,因此我們需要找到一個新的基b′,使得最后一個維度與具有縮放因子s的線性插值的波長匹配。由于原始的RoPE方法跳過奇數(shù)維度,以便將cos(2πx/λ)和sin(2πx/λ)分量連接為單個嵌入,所以最后一個維度d ∈ D為|D|?2,解b′的值如下:

根據(jù)符號表示法,"NTK-aware"插值方案只需簡單地應(yīng)用基變換公式,即:
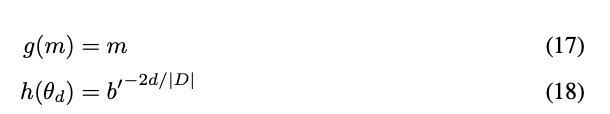
在測試中,與PI方法相比,這種方法在擴展非精調(diào)模型的上下文大小方面表現(xiàn)更好。然而,這種方法的一個主要缺點是,由于它不僅僅是一個插值方案,某些維度會略微外推到“超出界限”的值,因此使用“NTK-aware”插值進行精細調(diào)節(jié)得到的結(jié)果比PI方法更差。此外,由于“超出界限”的值,理論縮放因子s并不能準確描述實際上的上下文擴展比例。在實踐中,為了給定上下文長度的擴展,必須將縮放值s設(shè)得比預(yù)期的縮放值更高。
相對局部距離的損失 - “NTK-by-parts”插值
RoPE嵌入的一個有趣觀察是,給定上下文大小L,在一些維度d中,波長比預(yù)訓(xùn)練期間觀察到的最大上下文長度要長(λ > L),這表明某些維度的嵌入可能在旋轉(zhuǎn)域中分布不均勻。在PI和 “NTK-aware” 插值的情況下,我們將所有的RoPE隱藏維度視為相等。然而,實驗中發(fā)現(xiàn)網(wǎng)絡(luò)對一些維度與其他維度有所不同。如前所述,給定上下文長度L,某些維度的波長λ大于或等于L。考慮到當隱藏維度的波長大于或等于L時,所有位置對編碼唯一的距離,我們假設(shè)絕對位置信息被保留下來,而當波長較短時,網(wǎng)絡(luò)只能獲得相對位置信息。當我們通過縮放因子s或使用基礎(chǔ)變換b′拉伸所有RoPE維度時,所有的標記都會彼此更加接近,因為較小旋轉(zhuǎn)角度下兩個向量的點積較大。這種縮放嚴重影響了LLM理解其內(nèi)部嵌入之間的小而局部關(guān)系的能力。假設(shè)這種壓縮導(dǎo)致模型對接近的標記的位置順序感到困惑,從而損害了模型的能力。為了解決這個問題,根據(jù)我們的觀察,選擇根本不插值較高頻率的維度。
為了確定我們所需要的維度d,在給定某個上下文長度L下,我們可以按照如下的方式擴展方程(14):

我們還提出對于所有滿足r < α的維度d,我們會線性插值一個比例s(就像à一樣,避免任何外推),而對于r>β的維度d,則不進行插值(總是進行外推)。定義斜坡函數(shù)γd為:
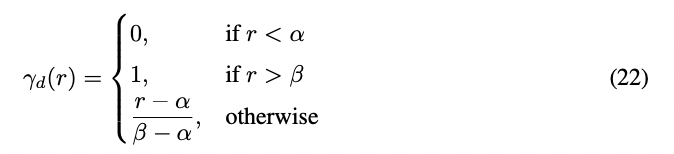
在斜坡函數(shù)的幫助下,我們將新的波長定義為:
α和β的值應(yīng)該根據(jù)具體情況進行調(diào)整。例如,我們經(jīng)實驗證明,對于Llama模型家族而言,α和β的合適取值為α = 1和β = 32。將λd轉(zhuǎn)換為θd后,該方法可以描述為:
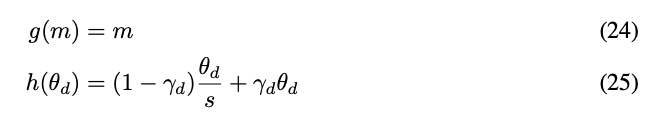
使用本節(jié)中描述的技術(shù),我們發(fā)布了一種名為“NTK-by-parts”插值的改進方法。這個改進的方法比之前的PI和“NTK-aware”插值方法在未微調(diào)模型和微調(diào)模型上的表現(xiàn)都更好。由于該方法避免了在旋轉(zhuǎn)領(lǐng)域中具有不均勻分布的維度進行外推,它避免了之前方法中的所有微調(diào)問題。
動態(tài)縮放 - “動態(tài) NTK”插值
當使用RoPE插值方法來擴展上下文大小而無需進行微調(diào)時,我們希望模型在更長的上下文大小下能夠逐漸降級,而不是在設(shè)置的比所需值更高的比例s時在整個上下文大小上完全降級。回想一下,s = L′/L表示PI中的比例,其中L是訓(xùn)練的上下文長度,L′是新擴展的上下文長度在“動態(tài)NTK”方法中,我們動態(tài)計算比例s如下:

在推理過程中,當上下文大小超過訓(xùn)練的上下文限制L時,動態(tài)改變尺度允許所有模型以平滑方式退化,而不是立即失敗。
在使用動態(tài)尺度調(diào)整和kv緩存時需要注意,因為在某些實現(xiàn)中,RoPE嵌入是被緩存的。正確的實現(xiàn)應(yīng)該在應(yīng)用RoPE之前緩存kv嵌入,因為每個標記的RoPE嵌入在s改變時也會改變。
增加長距離平均最小余弦相似度-YaRN
即使我們解決了在前面描述的局部距離的問題,更大的距離也必須在閾值α處進行插值以避免外推。直觀來說,這似乎不是一個問題,因為全局距離不需要高精度來區(qū)分token的位置。然而,我們發(fā)現(xiàn),由于平均最小距離隨著令牌數(shù)的增加而變得更加接近4,它使得注意力softmax分布變得“更尖銳”(即降低了注意力softmax的平均熵)。換句話說,由于插值導(dǎo)致遠距離衰減的效果減弱,網(wǎng)絡(luò)“更關(guān)注”較多的token。這種分布偏移導(dǎo)致LLM的輸出出現(xiàn)退化,這與之前的問題無關(guān)。
由于在將RoPE嵌入插值到更長的上下文大小時,注意力softmax分布的熵減小,我們的目標是反向減小熵(即增加注意力logits的“溫度”)。這可以通過將中間注意力矩陣乘以一個大于1的溫度t,然后應(yīng)用softmax來實現(xiàn),但由于RoPE嵌入被編碼為旋轉(zhuǎn)矩陣,我們可以簡單地通過一個常量因子√t來調(diào)整RoPE嵌入的長度。這種“長度縮放”技巧使我們避免了對注意力代碼的任何修改,從而顯著簡化了與現(xiàn)有的訓(xùn)練和推斷流程集成的過程,并且具有O(1)的時間復(fù)雜度。
由于我們的RoPE插值方案不均勻地插值RoPE維度,因此很難計算所需的溫度比例t相對于比例s的解析解。幸運的是,我們通過最小化困惑度實驗發(fā)現(xiàn),所有的Llama模型都大致遵循同一擬合曲線:

上面的方程是通過將 perplexity 最低的√t 與比例擴展因子 s 對擬合得到的,在 LLaMA 7b、13b、33b 和 65b 模型上,使用在 3.2 中描述的插值方法。我們還發(fā)現(xiàn),這個方程也適用于Llama 2 模型 (7b、13b 和 70b),只有輕微的差異。這表明增加熵的這個屬性在不同的模型和訓(xùn)練數(shù)據(jù)中是普遍且可推廣的。
外推和遷移學(xué)習(xí)
在Code Llama中,使用了一個包含16k個上下文的數(shù)據(jù)集,并將比例因子設(shè)置為s≈88.6,這對應(yīng)于一個上下文大小為355k。他們表明,網(wǎng)絡(luò)在訓(xùn)練過程中從未見過這些上下文尺寸的情況下,可以推斷出多達100k個上下文。YaRN也支持使用比數(shù)據(jù)集長度更高的比例因子s進行訓(xùn)練。由于計算約束,我們僅測試s=32,通過對具有64k上下文的相同數(shù)據(jù)集進行200個步驟的微調(diào)來進一步調(diào)優(yōu)s=16模型。
我們展示了s=32模型在訓(xùn)練過程中使用僅有64k上下文成功推斷出128k上下文的情況。與以前的“盲目”插值方法不同,YaRN在增加比例因子s時的遷移學(xué)習(xí)效率更高。這證明了從s=16到s=32的成功遷移學(xué)習(xí),而網(wǎng)絡(luò)無需重新學(xué)習(xí)插入的嵌入,因為s = 32模型在整個上下文尺寸上等效于s=16模型,盡管僅在s=32上進行了200個步驟的訓(xùn)練。
評估
長序列語言建模
為了評估長序列語言建模的性能,我們使用了GovReport和Proof-pile數(shù)據(jù)集,這兩個數(shù)據(jù)集都包含許多長序列樣本。對于所有評估,我們只使用了這兩個數(shù)據(jù)集的測試集進行計算。所有困惑度評估都是使用來自的滑動窗口方法進行計算的,其中S=256。
首先,我們評估了模型在上下文窗口增大時的性能。我們從Proof-pile中選擇了10個至少為128k標記長度的隨機樣本,并在從2k標記的序列長度到128k標記的情況下截斷了每個樣本的前2k個步驟,并評估了每個樣本的困惑度。圖1顯示了與其他上下文窗口擴展方法相比的結(jié)果。特別是,我們與Together.ai的公開可用的32k PI模型 和"NTK-aware" Code Llama進行了比較。這些結(jié)果總結(jié)在表1中。
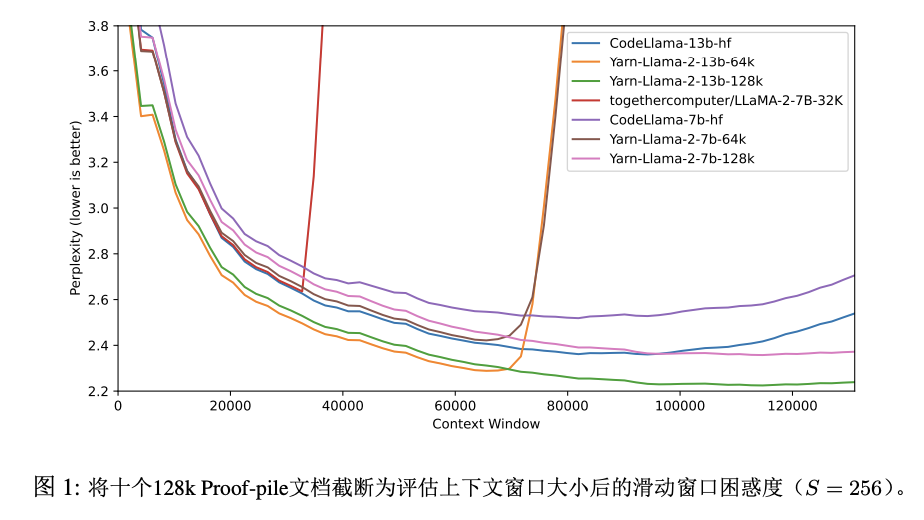
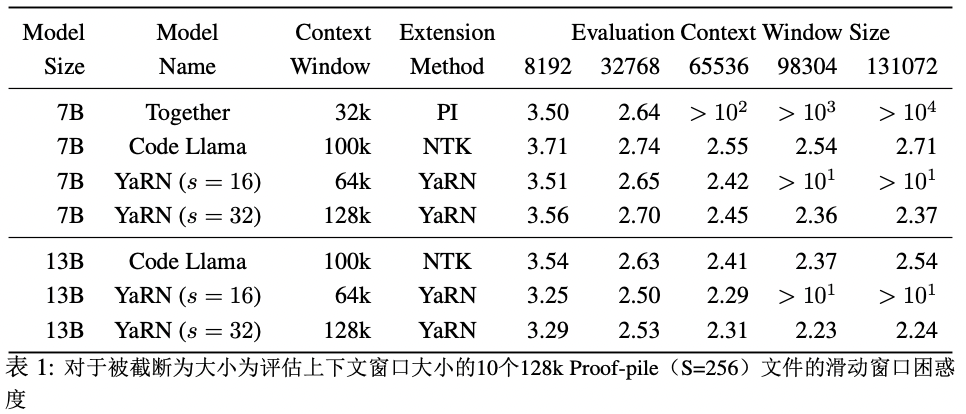
表2顯示了在32k上下文窗口下,對至少含有16k個標記的50個未截斷的GovReport文檔進行評估的最終困惑度。
我們觀察到該模型在整個上下文窗口中表現(xiàn)出色,優(yōu)于所有其他上下文窗口擴展方法。特別值得注意的是YaRN(s=32)模型,在128k中繼續(xù)呈現(xiàn)出下降的困惑度,盡管微調(diào)數(shù)據(jù)僅限于長度為64k的標記。這表明該模型能夠推廣到未見過的上下文長度。
標準化基準
Hugging Face Open LLM排行榜對一系列LLM模型在四個公共基準測試上進行了比較。具體來說,有25-shot ARC-Challenge [9],10-shot HellaSwag,5-shot MMLU和0-shotTruthfulQA。
為了測試模型性能在上下文擴展下的退化情況,我們使用這套測試套件評估了我們的模型,并將其與Llama 2基準模型的已建立分數(shù)以及公開可用的PI和“NTK-aware”模型進行了比較,結(jié)果總結(jié)在表3中。
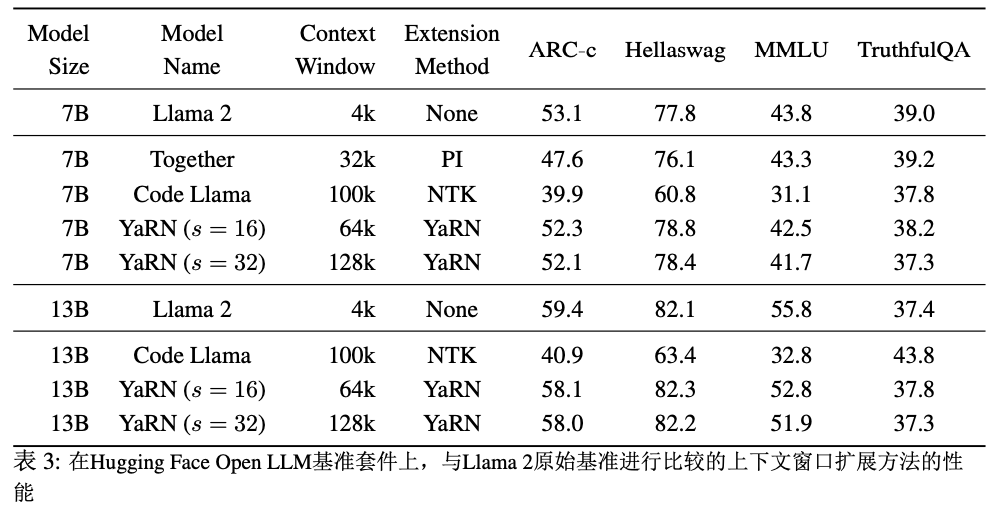
我們觀察到Y(jié)aRN模型和它們相應(yīng)的Llama 2基線之間存在最小的性能下降。我們還觀察到在YaRN s=16和s=32模型之間的平均分數(shù)下降了0.49%。因此我們得出結(jié)論,從64k到128k的迭代擴展導(dǎo)致的性能損失可以忽略不計。
總結(jié)
綜上所述,我們展示了YaRN改進了所有現(xiàn)有的RoPE插值方法,并可以作為PI的替代方案,其沒有缺點且實施起來所需的工作量很小。經(jīng)過微調(diào)的模型在多個基準測試中保留其原有的能力,同時能夠關(guān)注非常大的上下文范圍。此外,在較短的數(shù)據(jù)集上進行微調(diào)的YaRN能夠高效地進行外推,并且能夠利用遷移學(xué)習(xí)實現(xiàn)更快的收斂,這對于計算限制的情況至關(guān)重要。最后,我們展示了YaRN進行外推的有效性,其中它能夠"訓(xùn)練短,測試長"。
-
編碼
+關(guān)注
關(guān)注
6文章
965瀏覽量
55394 -
模型
+關(guān)注
關(guān)注
1文章
3473瀏覽量
49882 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25233
原文標題:YaRN:一種高效RoPE擴展方法,可推理更長上下文并達到SOTA
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
關(guān)于進程上下文、中斷上下文及原子上下文的一些概念理解
進程上下文與中斷上下文的理解
基于交互上下文的預(yù)測方法
新鮮度敏感的上下文推理實時調(diào)度算法
終端業(yè)務(wù)上下文的定義方法及業(yè)務(wù)模型
基于Pocket PC的上下文菜單實現(xiàn)
基于Pocket PC的上下文菜單實現(xiàn)
基于上下文相似度的分解推薦算法
基于時間上下文的跟蹤檢測方法
基于上下文語境的詞義消歧方法
一種上下文信息融合的時序行為提名方法
如何分析Linux CPU上下文切換問題
全新近似注意力機制HyperAttention:對長上下文友好、LLM推理提速50%





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論