 基于單張RGB圖像定位被遮擋行人設計案例
基于單張RGB圖像定位被遮擋行人設計案例
摘要
基于單張RGB圖像在3D場景空間中定位行人對于各種下游應用至關重要。目前的單目定位方法要么利用行人的包圍盒,要么利用他們身體的可見部分進行定位。這兩種方法在現實場景中都引入了額外的誤差—擁擠的環境中有多個行人被遮擋。為了克服這一局限性,本文提出了一種新穎的人體姿態感知行人定位框架來模擬被遮擋行人的姿態,從而實現在圖像和地面空間中的精確定位。這是通過提出一個輕量級的神經網絡架構來完成的,確保了快速和準確的預測缺失的身體部分的下游應用。在兩個真實世界的數據集上進行的綜合實驗證明了該框架在預測行人丟失身體部位以及行人定位方面的有效性。
引言
為了緩解以往研究的局限性,本研究的目的是:
(1)從可見身體部位的位置有效地估計出被遮擋的身體部位;
(2)使用該估計器準確地定位地面上被遮擋的行人。為此,受最近關于姿態估和單目行人定位的研究啟發,本文提出了一種新穎的人體姿態感知行人定位框架。
首先提出了一種在圖像空間中模擬被遮擋行人姿態的方法。這是通過基于他們其他可見的身體部位或關節(如鼻子、肩膀、手腕或膝蓋)來估計他們身體缺失部分在圖像中的位置來完成的。為此,我們提出了一個輕量級的前饋神經網絡,并在Microsoft COCO中對被檢測行人的身體結構關鍵點進行訓練,這是行人檢測中廣泛使用的開放基準數據集。受martinez等人(2017)啟發,腳部預測器的輕量化結構使該框架能夠準確有效地估計地面上行人的位置。為了估計行人可見關節,我們使用了OpenPifPaf (Kreiss等人,2019年),一種最先進的人體姿勢檢測器。這為我們提供了圖像空間中行人姿態的抽象表現。然后,對足部位置應用單應性變換,將坐標從圖像平面轉換到地平面。
在兩個真實世界的數據集上進行的實證明了本文提出的方法在估計行人在圖像空間中的位置方面的有效性。我們的評估還表明,與目前最先進的方法相比,本文提出的方法在定位精度方面提高了60%以上。提出的框架是作為一種實用的解決方案,以在常見安裝場景的監控攝像頭中準確地定位行人。然而,正如KITTI數據集所示,它也可以應用于其他相機設置,如自動駕駛汽車中估算單應性變換的實用解決方案。
綜上所述,本文的貢獻如下:
(1)提出了一種基于其他可見部位的方法來估計被遮擋的身體部位(如腳)的位置。
(2)使用真實世界的數據進行了一系列全面的實驗,并證明我們提出的框架可以準確地估計腳的位置,并在定位精度方面優于之前的方法。
方法
本研究旨在利用人體結構,改進基于單一圖像的步行者定位方法。這是通過預測行人丟失的身體部位來實現的。為了實現這一目標,本文提出了一個包括三個主要步驟的框架。如下圖所示,首先使用最先進的姿態檢測方法檢測圖像中的行人可見的身體部位和關節。然后對于每一個被檢測到的行人,我們從可見部分識別并預測他們的腳的位置,從而實現準確定位。最后應用單應性變換來估計被測足的地平面坐標。這些步驟在這個階段是分開的,但是它們有可能形成一個端到端系統。
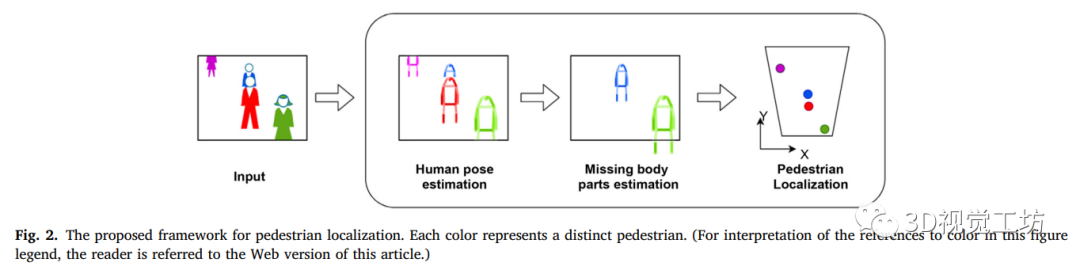
接下來詳細介紹了該框架的三個步驟。
1、行人姿態估計
本文采用了一種名為OpenPifPaf (Kreiss et al.,2019)的最先進的姿勢檢測器來檢測行人,并在圖像空間中找到他們對應的身體部位和關節。讓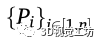 表示為圖像空間中被檢測到的行人的集合。這里,n表示圖像中檢測到的人類總數。每一個
表示為圖像空間中被檢測到的行人的集合。這里,n表示圖像中檢測到的人類總數。每一個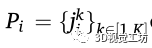 表示身體特定部位或關節在圖像空間中的位置。這里K表示姿勢檢測器可以識別的身體部位和關節的數量——在OpenPifPaf的情況下,最多可以識別17個關節。采用姿勢檢測器的優點是,它通過將腳的位置投射到地平面上,從而便于精確定位。
表示身體特定部位或關節在圖像空間中的位置。這里K表示姿勢檢測器可以識別的身體部位和關節的數量——在OpenPifPaf的情況下,最多可以識別17個關節。采用姿勢檢測器的優點是,它通過將腳的位置投射到地平面上,從而便于精確定位。
為了準確估計行人的位置,我們認為在定位時應考慮行人的腳位置。這是因為在一般情況下,相機可能對現場有一個傾斜的透視視角,考慮到bertoni等人(2019)提出的行人身體的中心點,將會給他們在地面上的估計位置增加一個顯著的誤差。此外,遮擋導致關節可能丟失。為了克服這一挑戰,我們建議從檢測到的關節中估計缺失的位置。
2、估計缺失的身體部位
本文方法可以基于行人在圖像空間中的其他可見身體部位,有效地預測行人缺失關節的位置。這種方法可以幫助我們解決基于包圍盒的定位方法對行人遮擋的局限性,通過可見的關節來估計遮擋的身體部位。該網絡能夠學習和預測身體各部位之間的協同模式,以及不同關節或身體各部位之間的距離。
下圖顯示了所提議的解決方案的總體流程。該網絡以人體可用部位的位置向量作為輸入,并估計缺失部位的位置。為了訓練網絡,我們提供一套完整的關節,讓網絡學習不同身體部位的相對位置。該網絡架構受到martinez等人(2017)的啟發,因為提出的架構受益于深度學習領域的各種改進,同時它仍然保持簡單和輕量級,以確保對下游應用的快速響應。我們進行了消融研究,以發現適合我們應用的最佳網絡架構。在消融研究的基礎上,提出了一個具有兩個線性層和2048輸出特征的深度前饋神經網絡。我們還在每個全連接層后采用了退出(Srivastava等人,2014年)和批處理標準化(Ioffe和Szegedy, 2015年),以防止過擬合。為了給我們的適應網絡添加非線性,我們使用矯正線性單元(ReLus) (Nair和Hinton, 2010)作為神經網絡中最常用的激活函數。
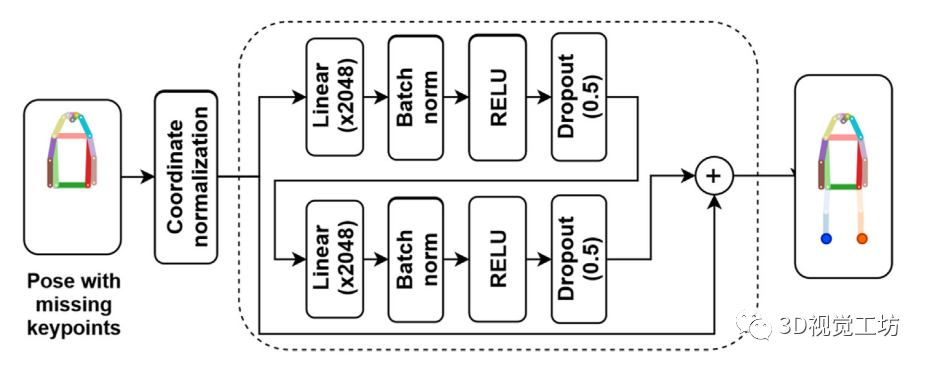
為了在擁擠環境中實現單目行人定位,我們使用該模型來預測行人的腳的位置。在COCO數據集上訓練和評估模,首先選擇數據集中現有腳位置的那些檢測到的行人。接下來,我們開發了一種數據增強技術,并應用于模擬現實場景,在這種場景中,攝像機對身體不同部位和關節的視角可能會被周圍的行人或物體遮擋。因此,我們隨機生成不同的行人解剖關鍵點組合,并將其增加到原始數據集,以豐富訓練,并使網絡適應真實的遮擋場景。通過這種方式,在保留實例的解剖約束的同時,我們設法模擬在真實場景中發生的不同類型的遮擋。然后將所有檢測到的行人的邊界框左上角移動到圖像坐標的原點,對關鍵點坐標進行歸一化,以標準化預測。
作為損失函數,我們利用常用的二范數來學習行人腳在圖像空間中的坐標,從而最小化位置估計誤差。給定一組已知的非腳的關鍵點,如鼻子、左肩或右手腕,以及它們相應的左、右腳踝關鍵點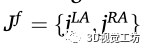 ,表示損失函數為:
,表示損失函數為:
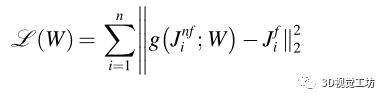
其中,w為網絡的導出權值,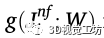 為模型估計的行人i在圖像空間中的腳位置,n是圖像中檢測到的行人數量。
為模型估計的行人i在圖像空間中的腳位置,n是圖像中檢測到的行人數量。
3、地面位置估計
在第三階段,我們對估計的足部位置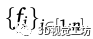 應用單應變換以確定地面空間坐標
應用單應變換以確定地面空間坐標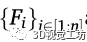 :
:
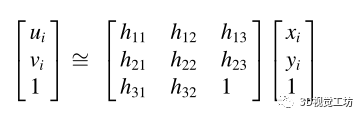
在這里,ui和vi反映了行人i在圖像空間中的位置,xi和yi代表了相應的地面二維坐標。單應矩陣的8個未知參數,可以使用一組在圖像空間和地面空間中手工測量的特征點來估計。
然后將最小二乘模型應用于投影空間中相應的線性方程組,確定估計的單應性變換參數。求解齊次線性投影至少需要四個控制點。最后,給定一個行人的每個腳的位置,即可以在地面空間估計相應的坐標。
實驗
為了準確估計行人丟失的身體部位,我們在2017年COCO訓練數據集(Lin et al.,2014)上訓練我們提出的網絡。此外,在SCS和KITTI兩個數據集上對所提出的框架進行評估。
在這項工作中,我們將提出的框架與Monoloco方法和幾何基線方法進行了比較。為了評估模塊的性能,使用了兩個常用的評估指標,即均方根誤差(RMSE)和平均絕對誤差(MAE)。
下圖顯示了KITTI數據集上被遮擋行人的預測腳位置的三個例子。如圖所示,我們提出的網絡可以有效地預測圖像空間中被遮擋的行人腳的位置(綠圈)。同時,可以看到,在遮擋行人的情況下,包圍框的底部中心點(黃圈)是完全偏離的。

此外,我們研究了估計行人缺失部分位置的誤差分布,這里稱為位置估計誤差。如下圖(a)所示,在圖像空間中,距離攝像機較近的行人的位置估計誤差明顯高于距離平臺較遠的其他行人。這可能是由于相機角度的影響,接近相機的行人看起來更大但更短,這使得估計腳的位置不太準確。
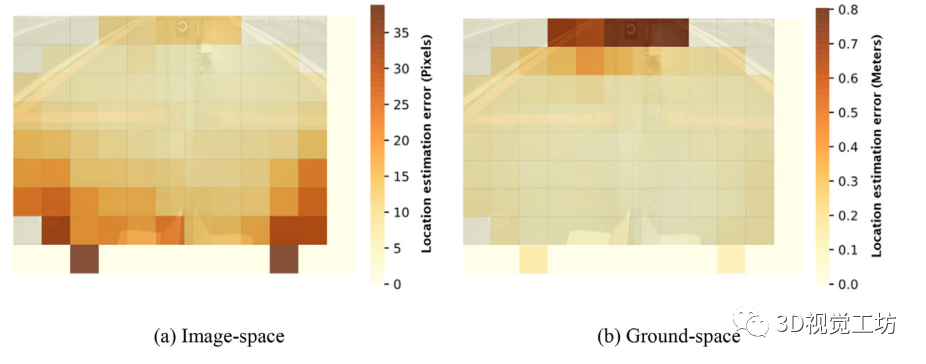
此外,利用單應性變換將誤差投影到地面,在真實尺度上檢測定位誤差。從上圖(b)可以看出,雖然圖像空間的誤差較大,但距離攝像機更近的行人相對于距離更遠的行人,其位置估計誤差較小,在圖像最遠的部分,誤差可達1 m。這是由于傾斜圖像的尺度變化,圖像的尺度在上部較小,導致定位誤差在圖像空間中投影到地面上的誤差更大。
下表比較了我們提出的方法與兩種基線方法在行人定位中的RMSE和MAE。可以觀察到,我們的方法在兩個數據集的評估指標方面都顯著優于Monoloco和幾何基線。

特別是,在行人完全可見的情況下,我們提出的框架實現了幾乎類似或略好于幾何基線的定位精度;在遮擋行人的情況下,我們的方法明顯優于其他兩種基線方法,并且這種改進隨著遮擋程度的提高而增加。
與最先進的基線相比,我們的方法的更好的性能可以通過以下論點來證明。Monoloco將圖像平面中每個實例的邊界框的中心點反向投影到該實例的3D位置。幾何基線也使用實例邊界框的底部中心來定位行人。然而,這種方法可能不是特別準確,因為在許多現實世界的情況下,四肢可能是不對稱的延伸,或者包圍框可能沒有緊緊圍繞行人的輪廓。這種情況加上行人遮擋的情況會在位置估計過程中造成額外的誤差。另一方面,我們的方法不依賴于包圍框,而是使用各種可見關鍵點的共現來估計地面坐標。
結論
本文提出了一種基于單目視覺的行人定位框架,為了解決擁擠環境下行人遮擋的問題,我們使用一種輕量級的深度神經網絡來估計人體姿勢缺失的部分。在兩個真實世界的數據集上進行的實驗表明,與現有的最先進的方法相比,該方法是有效的。我們提出的框架在實際情況下顯示了很好的性能,以準確估計單應性變換。這項工作的一個局限性是缺乏一種方法來估計預測位置的不確定性。因此,未來的研究方向可以是使用熱力圖或貝葉斯深度學習來量化預測位置的不確定性。作為另一個未來方向,可以利用行人在連續幀中的時間相關性來進一步提高人體缺失部位的預測。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100713 -
攝像機
+關注
關注
3文章
1596瀏覽量
60016 -
RGB
+關注
關注
4文章
798瀏覽量
58461 -
SCS
+關注
關注
0文章
19瀏覽量
10548 -
自動駕駛汽車
+關注
關注
4文章
376瀏覽量
40829
原文標題:基于單張RGB圖像定位被遮擋行人
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
RGB數字圖像顯示中錯誤圖像分析
阿里巴巴介紹行人檢測與識別技術
基于多級梯度特征的紅外圖像行人檢測算法
基于視點與姿態估計的視頻監控行人再識別
一種基于RGB-D圖像序列的協同隱式神經同步定位與建圖(SLAM)系統
從單張圖像中揭示全局幾何信息:實現高效視覺定位的新途徑

如何應對UWB室內定位信號被遮擋





 工商網監
工商網監
評論