 CPU緩存那些事兒
CPU緩存那些事兒
CPU高速緩存集成于CPU的內部,其是CPU可以高效運行的成分之一,本文圍繞下面三個話題來講解CPU緩存的作用:
-
為什么需要高速緩存?
-
高速緩存的內部結構是怎樣的?
-
如何利用好cache,優化代碼執行效率?
為什么需要高速緩存?
在現代計算機的體系架構中,為了存儲數據,引入了下面一些元件
-
1.CPU寄存器
-
2.CPU高速緩存
-
3.內存
-
4.硬盤
從1->4,速度越來越慢,價格越來越低,容量越來越大。這樣的設計使得一臺計算機的價格會處于一個合理的區間,使得計算機可以走進千家萬戶。
由于硬盤的速度比內存訪問慢,因此我們在開發應用軟件時,經常會使用redis/memcached這樣的組件來加快速度。
而由于CPU和內存速度的不同,于是產生了CPU高速緩存。
下面這張表反應了CPU高速緩存和內存的速度差距。
|
存儲器類型 |
時鐘周期 |
|
L1 cache |
4 |
|
L2 cache |
11 |
|
L3 cache |
24 |
|
內存 |
167 |
通常cpu內有3級緩存,即L1、L2、L3緩存。其中L1緩存分為數據緩存和指令緩存,cpu先從L1緩存中獲取指令和數據,如果L1緩存中不存在,那就從L2緩存中獲取。每個cpu核心都擁有屬于自己的L1緩存和L2緩存。如果數據不在L2緩存中,那就從L3緩存中獲取。而L3緩存就是所有cpu核心共用的。如果數據也不在L3緩存中,那就從內存中獲取了。當然,如果內存中也沒有那就只能從硬盤中獲取了。
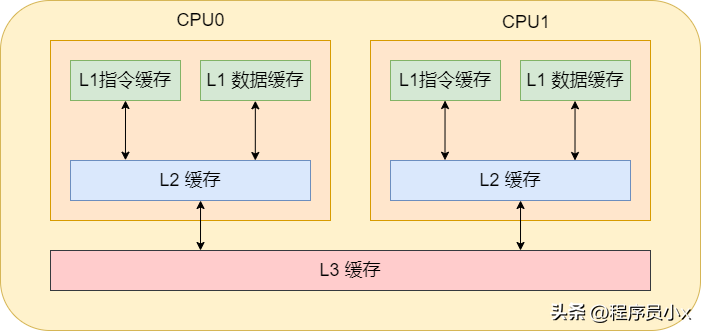
對這樣的分層概念有了了解之后,就可以進一步的了解高速緩存的內部細節。
高速緩存的內部結構
CPU Cache 在讀取內存數據時,每次不會只讀一個字或一個字節,而是一塊塊地讀取,這每一小塊數據也叫CPU 緩存行(CPU Cache Line)。這也是對局部性原理的運用,當一個指令或數據被拜訪過之后,與它相鄰地址的數據有很大概率也會被拜訪,將更多或許被拜訪的數據存入緩存,可以進步緩存命中率。
cache line 又分為多種類型,分別為直接映射緩存,多路組相連緩存,全相連緩存。
下面依次介紹。
直接映射緩存
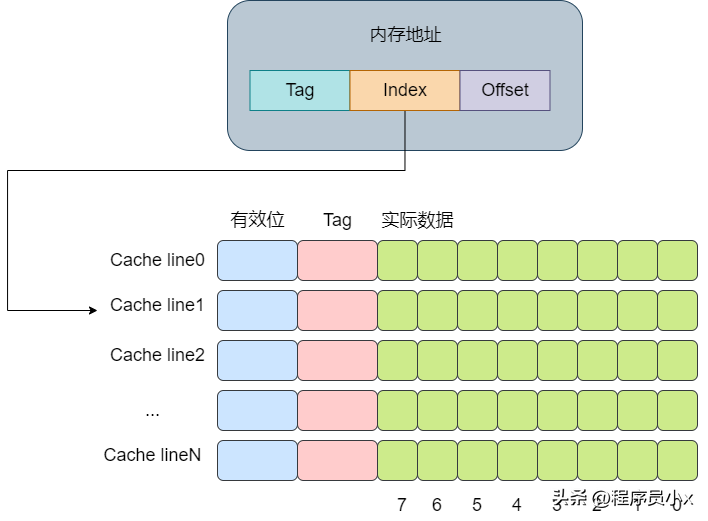
直接映射緩存會將一個內存地址固定映射到某一行的cache line。
其思想是將一個內存地址劃分為三塊,分別是Tag, Index,Offset(這里的內存地址指的是虛擬內存)。將cacheline理解為一個數組,那么通過Index則是數組的下標,通過Index就可以獲取對應的cache-line。再獲取cache-line的數據后,獲取其中的Tag值,將其與地址中的Tag值進行對比,如果相同,則代表該內存地址位于該cache line中,即cache命中了。最后根據Offset的值去data數組中獲取對應的數據。整個流程大概如下圖所示:
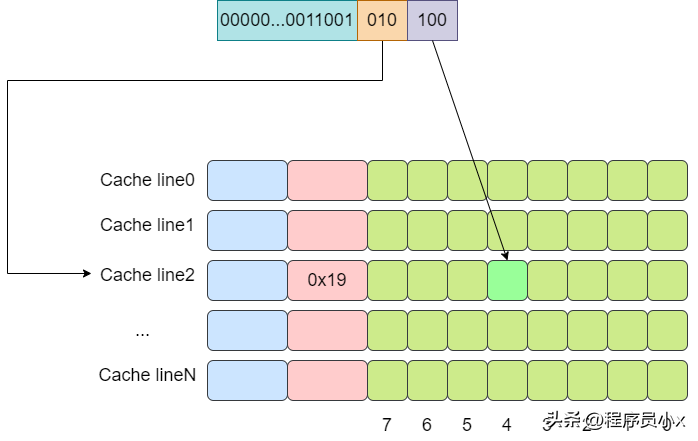
下面是一個例子,假設cache中有8個cache line,
對于直接映射緩存而言,其內存和緩存的映射關系如下所示:
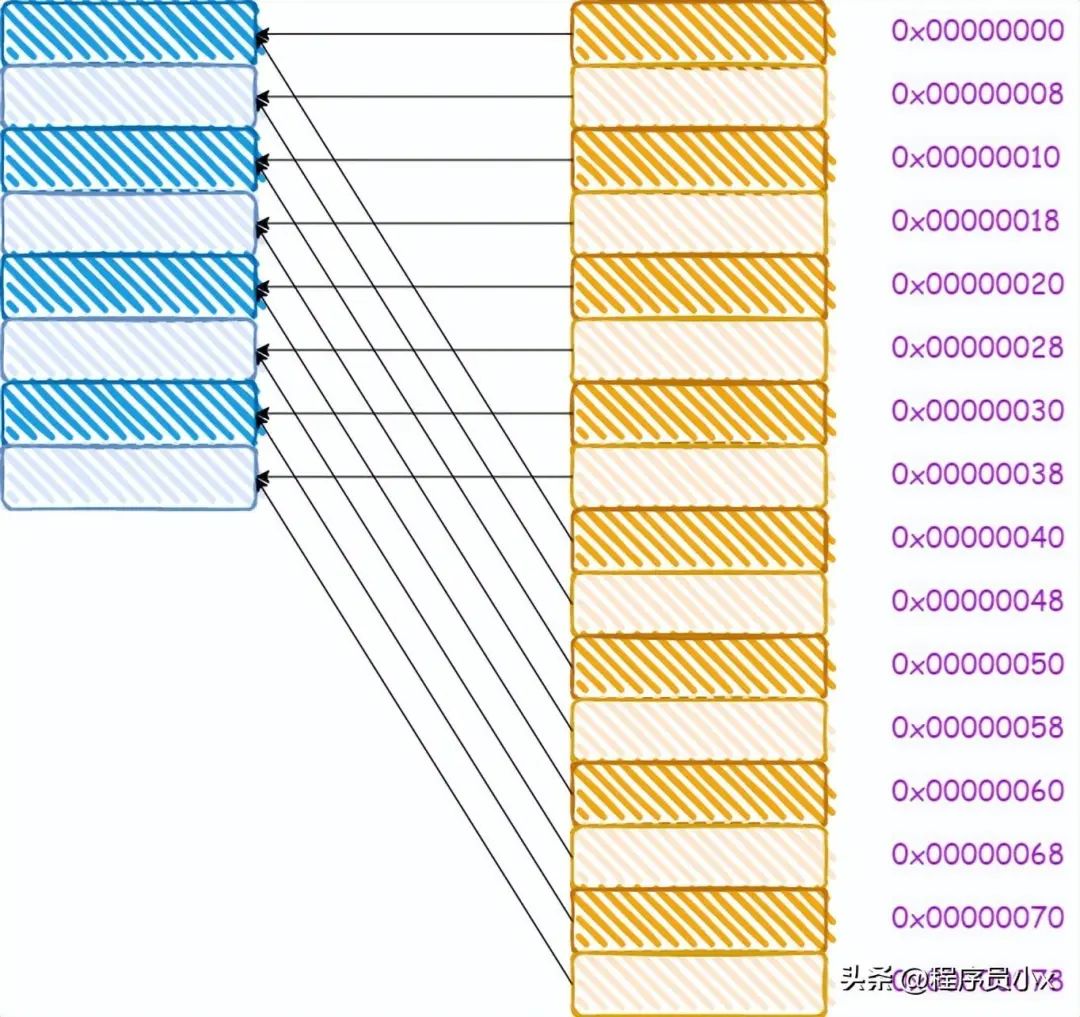
從圖中我們可以看出,0x00,0x40,0x80這三個地址,其地址中的index成分的值是相同的,因此將會被加載進同一個cache line。
試想一下如果我們依次訪問了0x00,0x40,0x00會發生什么?
當我們訪問0x00時,cache miss,于是從內存中加載到第0行cache line中。當訪問0x40時,第0行cache line中的tag與地址中的tag成分不一致,因此又需要再次從內存中加載數據到第0行cache line中。最后再次訪問0x00時,由于cache line中存放的是0x40地址的數據,因此cache再次miss。可以看出在這個過程中,cache并沒有起什么作用,訪問了相同的內存地址時,cache line并沒有對應的內容,而都是從內存中進行加載。
這種現象叫做cache顛簸(cache thrashing)。針對這個問題,引入多路組相連緩存。下面一節將講解多路組相連緩存的工作原理。
多路組相連緩存
多路組相連緩存的原理相比于直接映射緩存復雜一些,這里將以兩路組相連這種場景來進行講解。
所謂多路就是指原來根據虛擬的地址中的index可以唯一確定一個cache line,而現在根據index可以找到多行cache line。而兩路的意思就是指通過index可以找到2個cache line。在找到這個兩個cache line后,遍歷這兩個cache line,比較其中的tag值,如果相等則代表命中了。
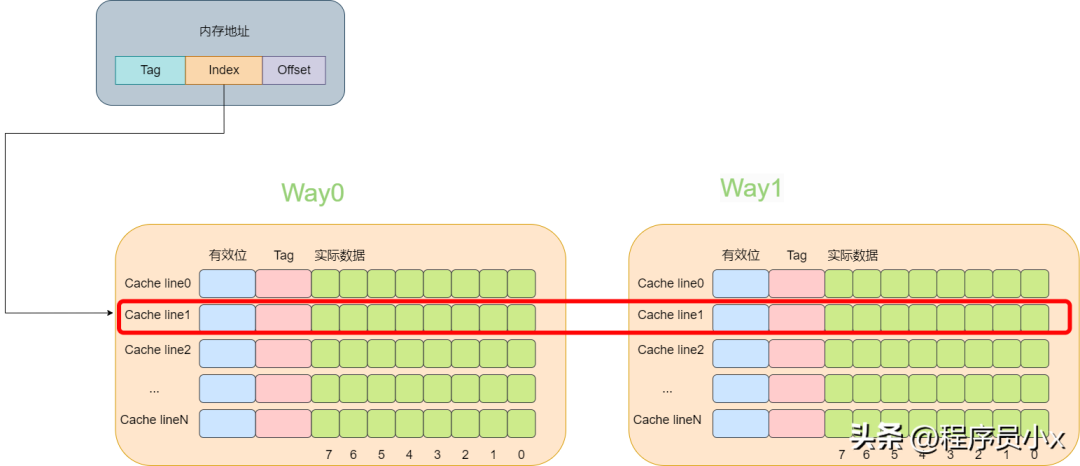
下面還是以8個cache line的兩路緩存為例,假設現在有一個虛擬地址是0000001100101100,其tag值為0x19,其index為1,offset為4。那么根據index為1可以找到兩個cache line,由于第一個cache line的tag為0x10,因此沒有命中,而第二個cache line的tag為0x19,值相等,于是cache命中。
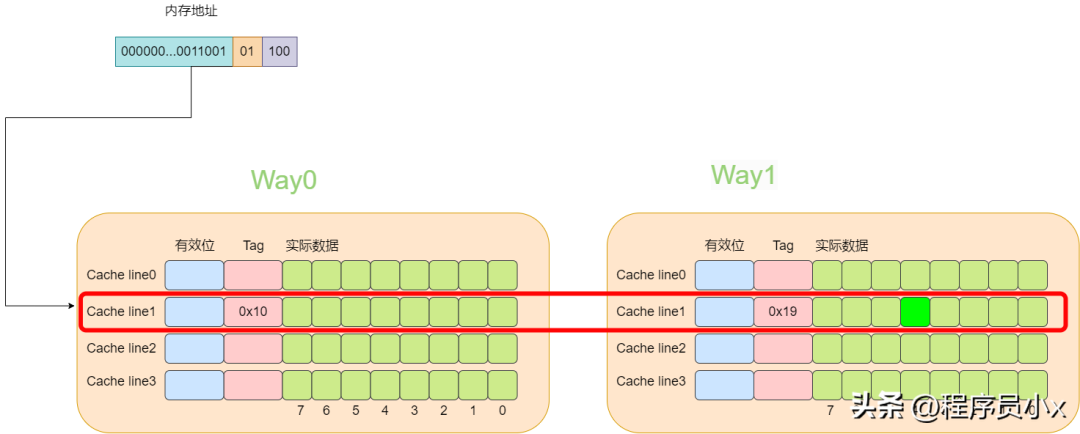
對于多路組相連緩存而言,其內存和緩存的映射關系如下所示:
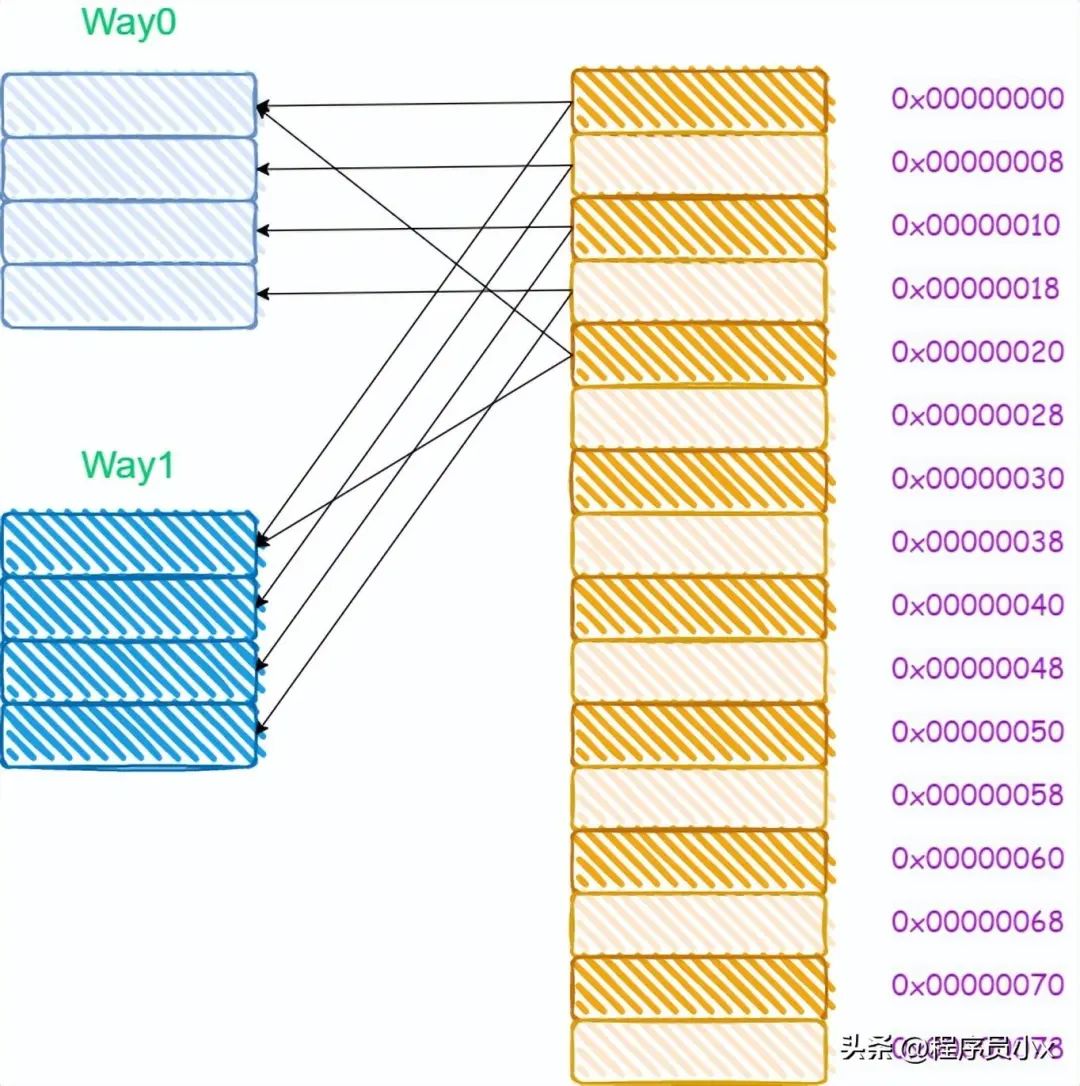
由于多路組相連的緩存需要進行多次tag的比較,對于比直接映射緩存,其硬件成本更高,因為為了提高效率,可能會需要進行并行比較,這就需要更復雜的硬件設計。
另外,如何cache沒有命中,那么該如何處理呢?
以兩路為例,通過index可以找到兩個cache line,如果此時這兩個cache line都是處于空閑狀態,那么cache miss時可以選擇其中一個cache line加載數據。如果兩個cache line有一個處于空閑狀態,可以選擇空閑狀態的cache line 加載數據。如果兩個cache line都是有效的,那么則需要一定的淘汰算法,例如PLRU/NRU/fifo/round-robin等等。
這個時候如果我們依次訪問了0x00,0x40,0x00會發生什么?
當我們訪問0x00時,cache miss,于是從內存中加載到第0路的第0行cache line中。當訪問0x40時,第0路第0行cache line中的tag與地址中的tag成分不一致,于是從內存中加載數據到第1路第0行cache line中。最后再次訪問0x00時,此時會訪問到第0路第0行的cache line中,因此cache就生效了。由此可以看出,由于多路組相連的緩存可以改善cache顛簸的問題。
全相連緩存
從多路組相連,我們了解到其可以降低cache顛簸的問題,并且路數量越多,降低cache顛簸的效果就越好。那么是不是可以這樣設想,如果路數無限大,大到所有的cache line都在一個組內,是不是效果就最好?基于這樣的思想,全相連緩存相應而生。
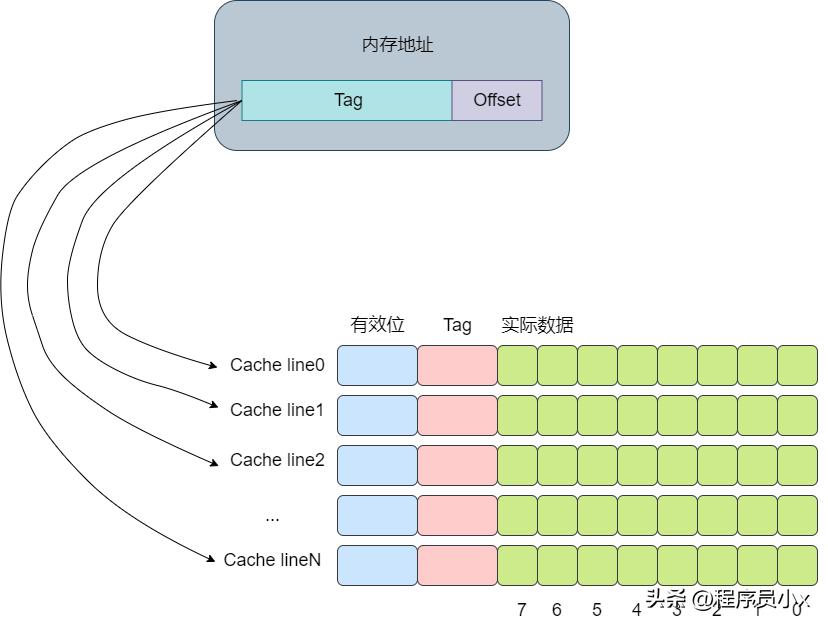
下面還是以8個cache line的全相連緩存為例,假設現在有一個虛擬地址是0000001100101100,其tag值為0x19,offset為4。依次遍歷,直到遍歷到第4行cache line時,tag匹配上。
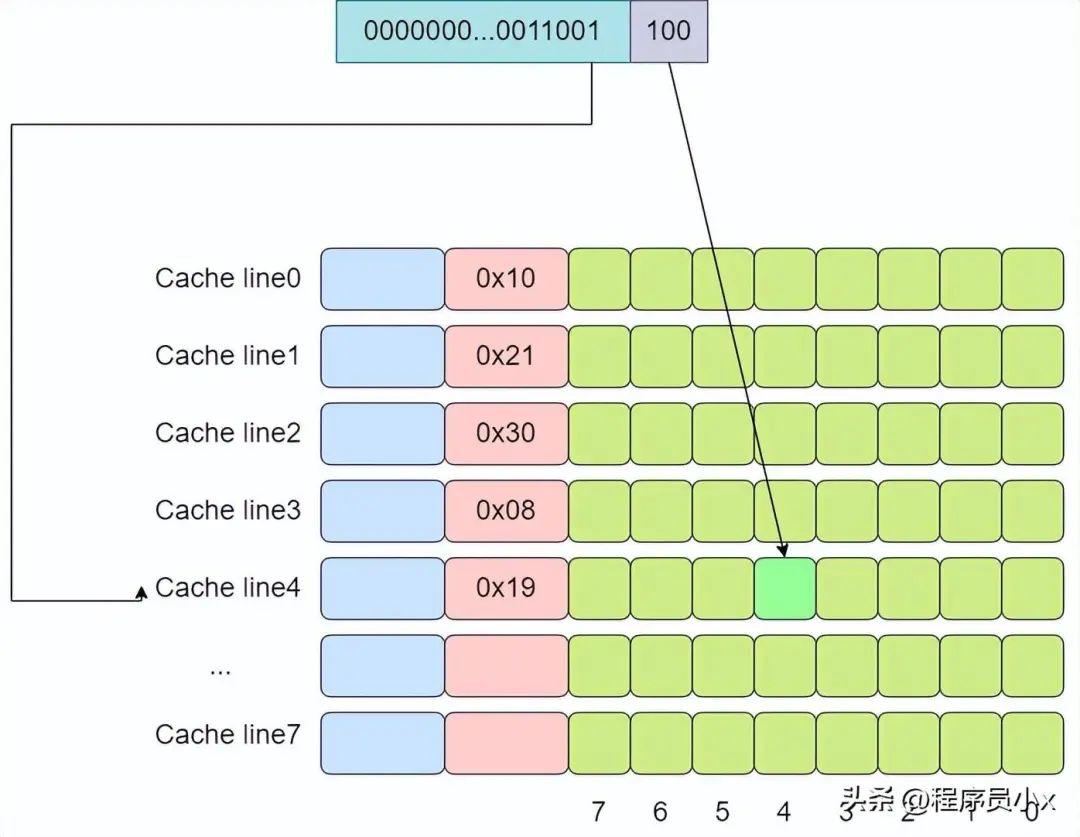
全連接緩存中所有的cache line都位于一個組(set)內,因此地址中將不會劃出一部分作為index。在判斷cache line是否命中時,需要遍歷所有的cache line,將其與虛擬地址中的tag成分進行對比,如果相等,則意味著匹配上了。因此對于全連接緩存而言,任意地址的數據可以緩存在任意的cache line中,這可以避免緩存的顛簸,但是與此同時,硬件上的成本也是最高。
如何利用緩存寫出高效率的代碼?
看下面這個例子,對一個二維數組求和時,可以進行按行遍歷和按列遍歷,那么哪一種速度會比較快呢?
const int row = 1024;
const int col = 1024;
int matrix[row][col];
//按行遍歷
int sum_row = 0;
for (int r = 0; r < row; r++) {
for (int c = 0; c < col; c++) {
sum_row += matrix[r][c];
}
}
//按列遍歷
int sum_col = 0;
for (int c = 0; c < col; c++) {
for (int r = 0; r < row; r++) {
sum_col += matrix[r][c];
}
}
我們分別編寫下面的測試代碼,首先是按行遍歷的時間:
#include
標準輸出打印了:2ms
接著是按列遍歷的測試代碼:
#include
標準輸出打印了:8ms
答案很明顯了,按行遍歷速度比按列遍歷快很多。
原因就是按行遍歷時, 在訪問matrix[r][c]時,會將后面的一些元素一并加載到cache line中,那么后面訪問matrix[r][c+1]和matrix[r][c+2]時就可以命中緩存,這樣就可以極大的提高緩存訪問的速度。
如下圖所示,在訪問matrix[0][0]時,matrix[0][1],matrix[0][2],matrix[0][2]也被加載進了高速緩存中,因此隨后遍歷時就可以用到緩存。
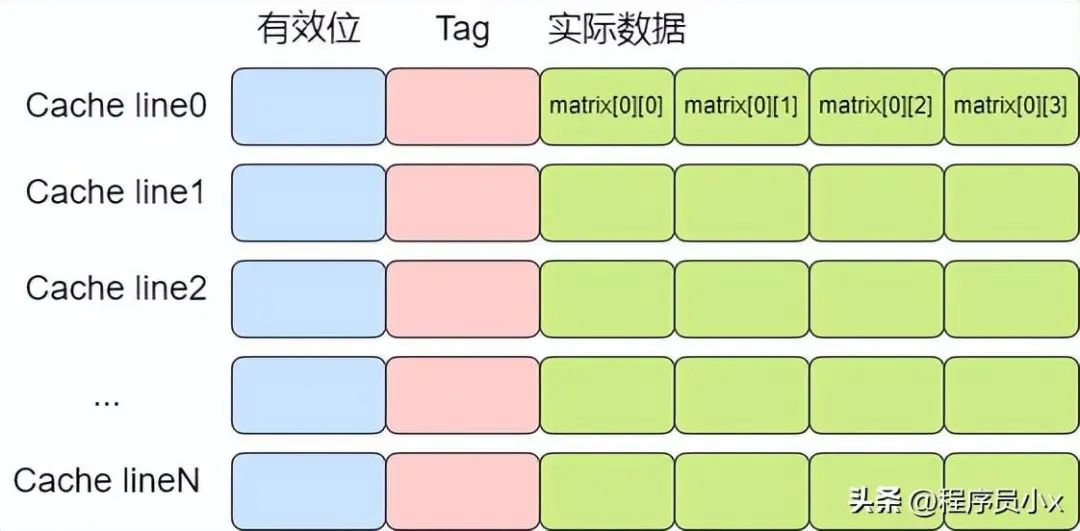
而按列遍歷時,訪問完matrix[0][0]之后,下一個要訪問的數據是matrix[1][0],不在高速緩存中,于是需要再次訪問內存,這就使得程序的訪問速度相較于按行緩存會慢很多。
-
cpu
+關注
關注
68文章
10870瀏覽量
211880 -
內存
+關注
關注
8文章
3028瀏覽量
74077 -
數組
+關注
關注
1文章
417瀏覽量
25957
原文標題:CPU緩存那些事兒
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦








 工商網監
工商網監
評論