 機器學習迅速發展,邊緣設備實現視覺AI應用
機器學習迅速發展,邊緣設備實現視覺AI應用
AI視覺應用
在過去十年,人工智能和機器學習算法有了長足發展。這些發展主要體現在視覺相關的應用上。2012年,AlexNet從ImageNet大規模視覺識別挑戰賽勝出(ILSVRC),成為首個使用反向傳播算法完成訓練的深度神經網絡。與傳統的淺網絡相比,性能產生近10%的成長,預測精度躋身前5位。
這個重大發展是一個轉折點。從那時起,深度神經網絡在性能/精度兩個方面不斷迎來巨大進展。2015年ResNet超越單個人類的分類能力,如圖1所示。就各種目的和用途而言,現今神經網絡的錯誤率已經可以與貝葉斯錯誤率相媲美,可視為解決計算機視覺應用中的圖像分類問題。
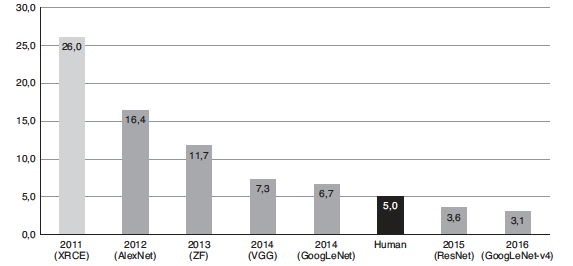
圖1 前5名預測準確性
(來源:https://devopedia.org/imagenet)
有鑒于如此令人振奮的結果,半導體制造商爭相開發組件,支持深度學習部署的高度復雜運算需求。在未來十年,推斷功能的商業化,特別是用深度學習實現的計算機視覺商業化,將繼續高速成長。計算機視覺市場規模預計將以30%的年均復合成長率(CAGR)成長,到2025年將達到262億美元。用深度學習實現的計算機視覺可以廣泛地應用到各類產業市場,包括零售分析、智慧城市、執法、邊境安全、機器人、醫療成像、作物收獲優化、符號語言識別等。在不遠的未來,AI將成為日常生活的內在組成要素,而且有些人認為這樣的未來近在咫尺。
隨著新穎的網絡、層和量化技術被開發出來,采用固定內存架構的硬化Tensor加速器,不再能夠滿足未來的需求。這種狀況已經在MobileNets的發展中表露無遺。在MobileNet骨干網絡中,使用深度卷積能大幅降低運算-內存比。這對于通用CPU這樣的組件來說非常理想。CPU一般受運算約束,但在若因架構受內存所限而導致效率有限,在某種程度上等于浪費寶貴的運算周期,就如數據中心中的待機服務器消耗能量一樣。這種運算-內存比影響著部署網絡時具體Tensor加速器架構的總效率。不幸的是,ASIC和ASSP Tensor加速器架構一般在組件試生產前,至少凍結一年。但在使用賽靈思推論技術時,則不會發生這種情況,該技術能隨時間推移進行調整和優化,以支持神經網絡架構的快速演進發展,進而確保低功耗、高效率。
本文介紹賽靈思產品組合中的Kria K26 SOM,及其在嵌入式視覺應用中的主要優勢。
智能應用除了要求低延遲,還需要具備私密性、低功耗、安全性和低成本。以Zynq MPSoC架構為基礎,產品如Kria K26 SOM提供穩定的單位功耗性能和更低的總體擁有成本,使其成為邊緣設備的較佳選擇。該產品具備硬件可配置能力,也就是說在K26上實現的解決方案是可擴展,同時具備未來兼容能力。
原始運算能力
就在邊緣設備上部署解決方案而言,硬件必須擁有充足的算力,才能處理ML算法工作負載。人們可以使用各種深度學習處理單元(DPU)配置對Kria K26 SOM進行配置,還能根據性能要求,將最適用的配置整合到設計內。例如,運行在300MHz的DPU B3136的峰值性能是0.94TOPS。運行在300MHz的DPU B4096的峰值性能是1.2TOPS,幾乎是Jetson Nano公布的峰值性能472GFLOPS的3倍。
支援更低精度數據類型
深度學習算法正在以極快的速度演進發展,INT8、二進制、三進制等更低精度的數據類型和客制化客制數據正在進入使用。GPU廠商難以滿足當前的市場需求,因為他們必須修改/調整他們的架構,才能適應并支持客制的或者更低精度的數據類型。Kria K26 SOM支持全系列數據類型精度,如PF32、INT8、二進制和其他客制數據類型。此外,根據Mark Horowitz提供的數據點,以較低精度數據類型進行的運算功耗更低,比如在INT8上進行的運算的功耗比在 FP32 上進行的運算低一個數量級。如圖2所示。
圖2 視覺AI入門套件
低延遲與低功耗
一般情況下,對于任何實現在多核心CPU、GPU或者任何SoC上的應用設計而言,功耗可在總體上按如下估算大致進行劃分:
? 核心=30%
? 內部存儲器(L1、L2、L3)=30%
? 外部內存(DDR)=40%
這就是GPU功耗高的主要原因。為改善軟件可程序設計能力,GPU架構需要頻繁存取外部DDR。這種做法非常低效,有時候會對高帶寬設計要求造成瓶頸。相反,Zynq MPSoC架構具有高能效,其可重配置能力便于開發者設計的應用減少或不必存取外部內存。這不僅有助于減少應用的總功耗,也透過降低端到端延遲改善響應能力。圖3所示為一種典型的汽車應用架構,其中GPU與各個模塊的通訊都透過DDR實現,而Zynq MPSoC組件采用的是在設計上避免存取任何DDR的高效率流水線。
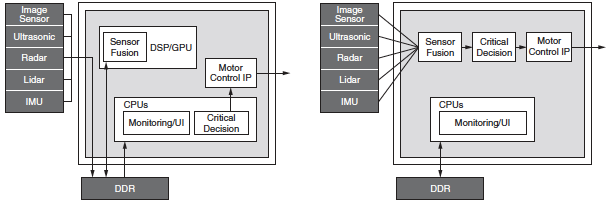
圖3 典型的GPU與MPSoC架構
透過靈活性實現低延遲
與數據流固定的GPU不同,賽靈思的硬件提供靈活性,以重新配置數據路徑,進而實現較大吞吐量并降低延遲。此外,可程序設計的數據路徑也降低了對批處理的需求,而批處理是GPU的一個重大不足,需要在降低延遲或提高吞吐量間做出權衡。Kria SOM的架構已在稀疏網絡中展示巨大潛力。稀疏網絡是當前ML應用中最熱門的趨勢之一。另一個重要特性是任意I/O連接,能進一步提高Kria SOM靈活性,其使K26 SOM在毋需主機CPU的情況下,可以連接到任何設備、網絡或存儲設備。
剪枝優勢降低模型復雜度
賽靈思提供AI優化工具,能進一步增強運行在K26 SOM上的各種神經網絡性能。本文提供的比較資料,到目前為止均是在未經優化或剪枝(Pruning)的原始模型上取得的。大多數神經網絡通常都有過度參數化的情況,存在可以優化的嚴重冗余。賽靈思的AI優化器是一種模型壓縮技術,該工具可在幾乎不影響精度的情況下,將模型復雜度最多降低50倍。
本文引用賽靈思所做的研究案例。這是一個擁有117千兆次運算(Gops)的復雜SSD+VGG模型,其使用賽靈思AI優化器工具迭代進行優化。圖4所示為使用AI優化器工具為模型剪枝帶來的好處。
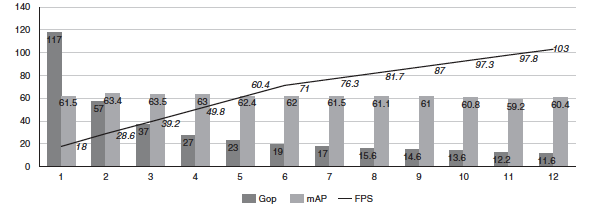
圖4 模型剪枝結果
作為基線,該模型運算量為117Gops,運行在用兩個B4096 DPU配置的Zynq UltraScale+ MPSoC上,最高FPS為18。經過數次剪枝迭代,數據顯示復雜性明顯下降,FPS相應增加,但未對精度(mAP)造成任何影響。在第11次迭代時,復雜性降低10倍,從117Gops降低到11.6Gops;性能提高5倍,從18FPS提高到103FPS;精度僅下降1.1%,從61.55mAP下降到60.4mAP。
到這里,本文已對Kria K26 SOM與GPU的原始性能對比做了介紹。了解這種原始性能在實際用例中的意義至關重要。實際用例結構復雜,涉及流水線中的其他模塊,如任何AI-ML應用所需的預處理和后處理組件。在這類應用中,最大吞吐量由流水線中性能最低的組件決定。
實際應用性能比較
為了分析實際用例,本文選擇一種準確檢測和識別車輛牌照、使用機器學習的應用。賽靈思已與Uncanny Vision合作,旨在為市場提供較佳的汽車牌照(車牌)識別(ANPR)解決方案。這種應用已得到世界上眾多城市的廣泛采用,用于智慧城市的建設中。ANPR的主要應用包括自動收費管理系統、高速公路監測系統、停車場門禁和安全門門禁。ANPR應用是一種使用AI的流水線,內含影片影像譯碼、圖像預處理、機器學習(檢測)和OCR字符識別,如圖5所示。

圖5 ALPR應用的處理區塊
ANPR AI盒應用一般從現貨IP攝影機攝入一個到多個H.264或H.265編碼的RTSP流并進行譯碼(解壓縮)。譯碼的影像幀在被機器學習算法攝入前,先進行預處理(通常是縮放、剪裁、色彩空間轉換和歸一化)。就高性能商用ANPR實現方案而言,通常需要多級AI流水線。第一個網絡的作用是檢測和定位幀內的車輛。這項操作中還結合跨多幀追蹤車輛軌跡的算法和選擇最佳幀曝光,為OCR優化圖像畫質的算法。通常先剪裁和縮放車輛感興趣區域(ROI),然后饋入負責定位車牌的次級檢測網絡。
與車牌ROI有關的像素經過剪裁和縮放,最終被饋送到負責實現OCR預測的最后一個神經網絡。最后一級提供的元數據預測是壓印或印刷在車牌上或是以其他方式可見的字母數字字符。為了進行比較,已部署在GPU和CPU上的Uncanny Vision ANPR應用,為實現在Kria KV260視覺AI入門套件上的部署進行了優化。結果證明,將Uncanny Vision算法在Kria SOM上進行部署后,打破100美元的價格壁壘,而且性能是Uncanny Vision先前同類SOM產品的2到3倍。
這些數據說明,Uncanny Vision的ANPR流水線在針對KV260入門套件進行優化后,實現超過33fps的吞吐量,這種較佳的性能水平為ANPR整合商和OEM廠商提供優于競爭對手的開發靈活性。每多安裝一個AI盒都會直接影響安裝成本,還不考慮相關的布線和導管成本。
根據安裝的具體情況,設計師可以犧牲幀率來換取更大的每盒處理流數。對于停車場安裝(如停停走走、攔車桿和自由通行),推斷和捕獲幀率通常要達到10fps才可滿足要求,還能可靠地采集車牌元數據。這便于設計師將多個攝影機流聚合到單個AI盒,進而節省每個閘門的總體資本支出(CAPEX)和營運成本(OPEX)。在高速應用中,如高速公路收費和執法,較高的幀率確保能夠準確可靠地檢測和識別高速行駛中的車輛。在33fps的吞吐量下,與當今市場上的解決方案相比,K26 SOM能夠更加可靠地為識別和證據收集提供支持。
大多數ANPR系統都需要在環境嚴苛的條件下運行。I級的K26 SOM專為嚴酷環境開發,支持-40至100℃的工作溫度范圍和三年保固。在采用K26I SOM后,與市場解決方案相比,ANPR系統的總體擁有成本顯著降低。
Uncanny Vision的ANPR應用說明,K26 SOM不僅在標準性能比較中表現較佳,并且為開發者提供加速整體AI和視覺流水線所需的原始性能時,效率也更高。透過對比,在標準的基準檢驗領域之外,競爭解決方案效率較低且功耗較高。
賽靈思透過開發各種工具、庫、框架和參考示例,為方便應用做了大量工作,大幅簡化軟件開發者的開發工作。
AI開發工具包
Vitis AI開發環境由賽靈思Vitis AI開發工具包構成,支持該公司SoC、Alveo加速器卡以及Kria SOM。其組成包括經優化的工具、庫和預訓練模型,為開發者部署客制模型鋪平道路。其在設計時便充分考慮到高效率和易用性,在組件上釋放AI加速的潛力。
此外,Vitis AI整合Apache開源TVM項目,TVM依托開源小區和各類大型商業用戶提供的輸入,提供多樣化、緊跟時代、可擴展的機器學習框架支持。TVM自動運行圖形分割和圖形編譯,基本上確保能夠部署來自任何框架的網絡運算符,即使該運算符并非原生地受到Vitis AI開發環境的支持。
事實上在TVM環境中,任何運算符都能編譯到x86和Arm目標組件上。這意謂著開發者可以迅速地部署模型,在賽靈思DPU上為Vitis AI開發環境支持的子圖加速,同時在CPU上部署圖形的其余部分。
SDK
PetaLinux是一種針對賽靈思SoC的嵌入式Linux軟件開發套件(SDK)。PetaLinux使用Yocto,是一種為構建、開發、測試和部署嵌入式Linux系統提供一切必要內容的開發工具。
PetaLinux工具包含:
? Yocto可擴展SDK(eSDK)
? 賽靈思軟件命令行工具(XSCT)和工具鏈
? PetaLinux CLI工具
視覺庫
Vitis視覺庫用戶能在平臺上,開發和部署加速計算機視覺和圖像處理應用,同時在應用層面操作。這些開源庫功能提供使用OpenCV的接口,但專為賽靈思平臺的高性能和低資源耗用進行了優化。此外,它們也提供靈活性,可以滿足用戶視覺系統的自適應吞吐量需求。
影像分析SDK
影像分析SDK是一種建構在開源且被廣泛采用的GStreamer上的應用框架。這種SDK設計上支持跨所有賽靈思平臺的開發,包括FPGA、SoC、Alveo卡以及Kria SOM。使用該SDK,開發者毋需深入掌握FPGA復雜的底層技術,就能裝配視覺分析和影像分析流水線。
此外,該SDK提供的API讓用戶能夠快速開發以GStreamer插件形式存在,能整合至SDK框架的高效客制加速核心。無論是否使用客制加速核心,一般的嵌入式開發者都能簡便輕松地裝配客制加速流水線。
加速應用增強功能
加速應用是Kria SOM解決方案的基本架構。這些應用是完整、可量產的端到端解決方案,專門支持常見的視覺用例。賽靈思加速應用在可程序設計邏輯區域包含一個預優化的視覺流水線加速器。開發者可按原狀使用,也可以進一步優化滿足應用的特定需求。借助具有高可靠性的軟件協議堆棧,只修改韌體或倒換AI模型,用戶就能輕松地客制和增強解決方案功能。
K26 SOM在實際應用下的性能較穩定,提供顯著的性能優勢。該產品的底層硬件功能強大,有助于在降低延遲和減少功耗的情況下為完整的應用提速。對于ANPR應用,K26 SOM性能較佳,憑借更高的吞吐量,用戶能夠在每個組件上處理更多,進而降低總體成本。其具有更高吞吐量、更低延遲、更小功耗等優勢,同時能夠為滿足未來需求提供靈活性和可擴展能力,Kria K26 SOM是在邊緣設備上實現使用視覺AI應用的較佳選擇。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100720 -
二進制
+關注
關注
2文章
795瀏覽量
41643 -
機器學習
+關注
關注
66文章
8408瀏覽量
132569
原文標題:機器學習迅速發展,邊緣設備實現視覺AI應用
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
超低功耗FPGA解決方案助力機器學習
嵌入式視覺和網絡邊緣智能應用市場發展迅速
【HarmonyOS HiSpark AI Camera】邊緣計算安全監控系統
高性能的機器學習讓邊緣計算更給力-iMX8M Plus為邊緣計算賦能
高性能的機器學習讓邊緣計算更給力-iMX8M Plus為邊緣計算賦能
微型機器學習
高性能的機器學習讓邊緣計算更給力-iMX8M Plus為邊緣計算賦能
Arm如何應對不同AI需求層次與發展路徑?
嵌入式AI邊緣智能系統用,加速機器人&機器視覺設備部署 ——2022研華工業物聯網在線論壇

用于邊緣設備上機器學習的安全閃存





 工商網監
工商網監
評論