 解決醫療大模型訓練數據難題,商湯最新研究成果登「Nature」子刊
解決醫療大模型訓練數據難題,商湯最新研究成果登「Nature」子刊
生成式AI正為醫療大模型迭代按下加速鍵。
近日,商湯科技聯合行業合作伙伴,結合生成式人工智能和醫療圖像數據的多中心聯邦學習發表的最新研究成果《通過分布式合成學習挖掘多中心異構醫療數據》(MiningMulti-Center Heterogeneous Medical Data with Distributed Synthetic Learning),登上國際頂級學術期刊Nature子刊《自然-通訊》(NatureCommunications)。
 研究成果提出一個基于分布式合成對抗網絡的聯邦學習框架DSL(DistributedSynthetic Learning),可利用多中心的多樣性醫療圖像數據來聯合學習圖像數據的生成。
研究成果提出一個基于分布式合成對抗網絡的聯邦學習框架DSL(DistributedSynthetic Learning),可利用多中心的多樣性醫療圖像數據來聯合學習圖像數據的生成。
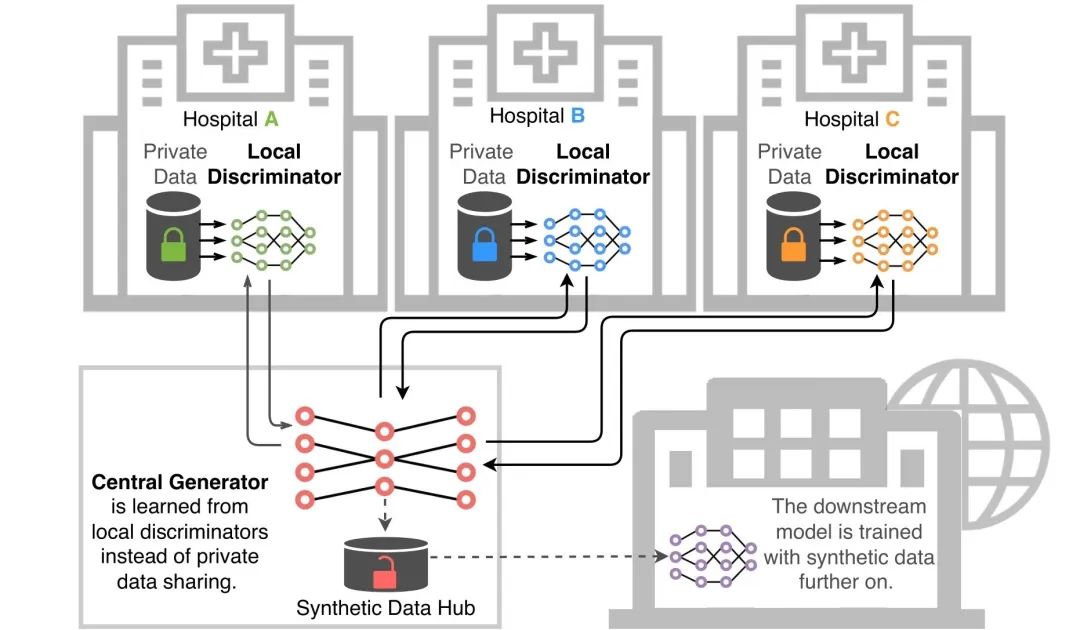 ?DSL框架包含一個中央生成器和多個分布式鑒別器,每個鑒別器位于一個醫療實體中。經過訓練的生成器可以作為“數據生產工廠”,為下游具體任務的學習構建數據庫
?DSL框架包含一個中央生成器和多個分布式鑒別器,每個鑒別器位于一個醫療實體中。經過訓練的生成器可以作為“數據生產工廠”,為下游具體任務的學習構建數據庫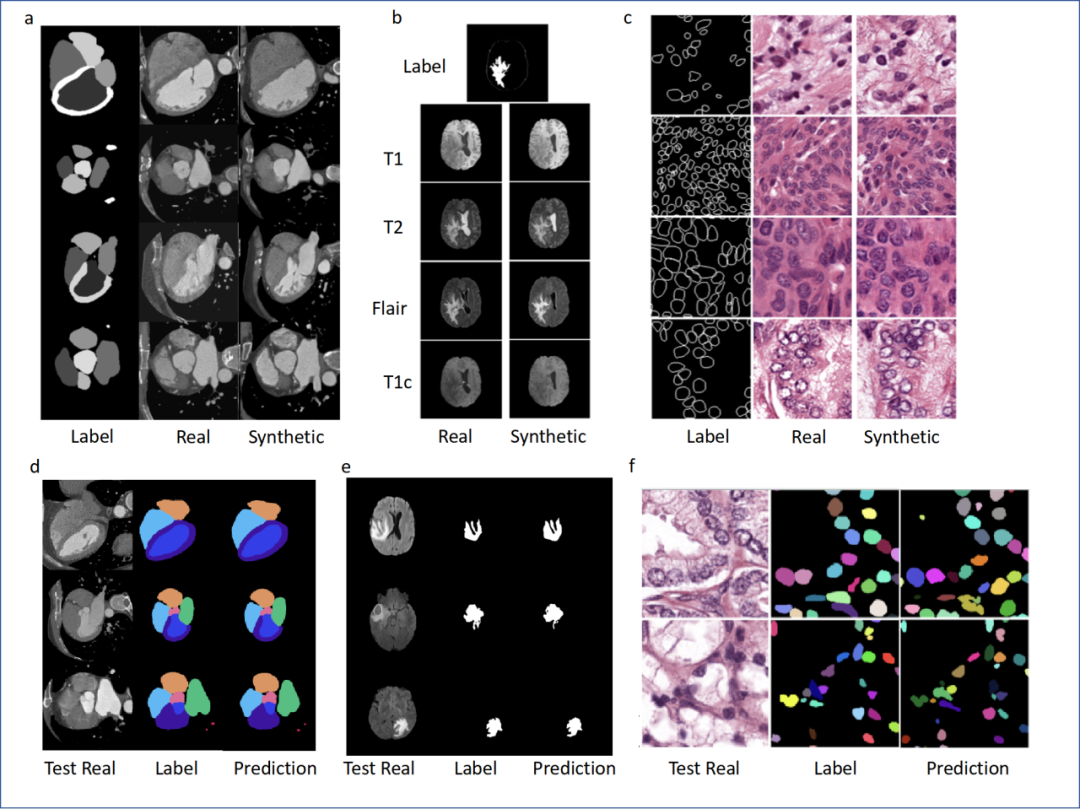 ?不同應用中生成數據示例:(a) 心臟CTA,(b) 大腦多模態MRI,(c) 病理圖像;生成的數據構成大數據庫可用于下游具體任務模型的學習,例如:(d) 全心分割,(e) 腦腫瘤分割,(f) 細胞核分割
?不同應用中生成數據示例:(a) 心臟CTA,(b) 大腦多模態MRI,(c) 病理圖像;生成的數據構成大數據庫可用于下游具體任務模型的學習,例如:(d) 全心分割,(e) 腦腫瘤分割,(f) 細胞核分割 ?WAIC期間商湯科技展示大模型在醫療領域的多個落地應用案例
?WAIC期間商湯科技展示大模型在醫療領域的多個落地應用案例
《自然-通訊》主要發表自然科學各個領域的高質量研究成果,影響因子16.6。
研究成果提出一個基于分布式合成對抗網絡的聯邦學習框架DSL(DistributedSynthetic Learning),可利用多中心的多樣性醫療圖像數據來聯合學習圖像數據的生成。
該分布式框架通過學習得到一個圖像數據生成器,可以更靈活地生成數據,進而可替代多中心的真實數據,用于下游具體機器學習任務的訓練,并具備較強可擴展性。
伴隨大模型快速發展,Model as a Service(MaaS,模型即服務)正成為一大趨勢。MaaS的大模型需要從海量的、多類型的數據中學習通用特征和規則,從而具備較強的泛化能力。
DSL框架能在保護數據隱私的同時,巧妙解決醫療大模型訓練中常見的數據量不足的瓶頸,有效賦能MaaS的大模型訓練。
在這一技術支撐下,商湯“醫療大模型工廠”能夠幫助醫療機構更高效、高質量地訓練針對不同臨床問題的醫療大模型,使大模型在醫療領域的應用半徑得以延伸。
兼顧隱私保護和數據共享
創新聯邦學習模式打造
“數據生產工廠”
深度學習模型需要大量且多樣性的數據“喂養”。
醫療領域對用戶隱私保護有著極高要求,使得模型訓練的醫療數據在多樣性和標注質量上都受到限制,也使多中心的醫療數據收集和醫療AI模型的開發迭代面臨較大挑戰。
如何調和隱私保護和數據共享協作的矛盾?
“聯邦學習提供了全新的解題思路。聯邦學習是一種分布式機器學習方法, 可以在不共享數據的情況下對多中心的數據進行聯合建模,聯合學習某一特定應用模型。”
與主流的聯邦學習模式不同,DSL框架的學習目標是數據生成器,而非具體應用的任務模型。
該分布式架構由一個位于中央服務器的數據生成器和多個位于不同數據中心的數據鑒別器組成。
在學習過程中,中央生成器負責生成“假”的圖像數據,并發送給各個數據中心,各個數據中心用本地的真實數據和“假”數據進行對比后將結果回傳給中央服務器,并基于反饋結果訓練中央生成器生成更仿真的圖像數據。
分布式的合成學習結束后,中央生成器可作為“數據生產工廠”,根據給定的約束條件(標注)生成高質量仿真圖像數據,從而得到一個由生成數據組成的數據庫。
該數據庫可替代真實數據,用于下游具體任務的學習,使下游模型的更新迭代不再受到真實數據可訪問性制約。同時,該方法通過分布式架構和聯邦學習方式保證中央服務器無需接觸數據中心真實數據,也不需要同步各中心的鑒別器模型,有效保障了數據安全和隱私保護。
?DSL框架包含一個中央生成器和多個分布式鑒別器,每個鑒別器位于一個醫療實體中。經過訓練的生成器可以作為“數據生產工廠”,為下游具體任務的學習構建數據庫
賦能MaaS新生態
為醫療大模型開發迭代
按下加速鍵
DSL框架已通過多個具體應用的驗證。
包括:大腦多序列MRI圖像生成及下游的大腦腫瘤分割任務,心臟CTA圖像生成及下游的全心臟結構分割任務,多種器官的病理圖像生成及細胞核實例分割任務等。
在可擴展性方面,該方法還可支持多模態數據中缺失模態數據的生成、持續學習等不同場景。
?不同應用中生成數據示例:(a) 心臟CTA,(b) 大腦多模態MRI,(c) 病理圖像;生成的數據構成大數據庫可用于下游具體任務模型的學習,例如:(d) 全心分割,(e) 腦腫瘤分割,(f) 細胞核分割DSL框架的構建,也有利于推動MaaS服務模式發展。
MaaS的醫療大模型在數據學習過程中,同樣會遇到醫療數據隱私安全保護問題。基于DSL框架,可以有效地從多中心多樣性數據中建立數據集倉庫,通過生成數據,為大模型的開發迭代提供創新思路。
細化到具體應用場景,DSL框架可助力醫療機構高效開展跨中心、跨地域模型訓練工作。
不同區域醫療機構在疾病數據多樣性方面存在明顯地域性差異,過去受限于數據安全和隱私保護要求,使用跨中心醫療數據聯合訓練醫療模型難度大。而借助DSL框架,有望幫助醫療機構更加高效便捷地開展跨中心醫療模型訓練。
在2023 WAIC世界人工智能大會上,商湯科技與行業伙伴合作推出醫療大語言模型、醫療影像大模型、生信大模型等多種垂類基礎模型群,覆蓋CT、MRI、超聲、內鏡、病理、醫學文本、生信數據等不同醫療數據模態。并展示了融入醫療大模型的升級版“SenseCare智慧醫院”綜合解決方案,以及多個醫療大模型落地案例。
借助商湯大裝置的超大算力和醫療基礎模型群的堅實基礎,商湯得以成為“醫療大模型工廠”,幫助醫療機構針對不同臨床問題高效訓練模型,甚至輔助機構實現模型自主訓練。
?WAIC期間商湯科技展示大模型在醫療領域的多個落地應用案例
隨著DSL框架的推出,醫療大模型訓練將有望突破“數據孤島”的桎梏,一定程度上降低醫療大模型的訓練門檻,有助于加速模型開發迭代,使醫療大模型的應用范圍得以覆蓋更多臨床醫療問題。
商湯科技將持續聚焦醫療機構的多樣化需求,推動醫療大模型在更多醫療場景落地。 點擊“閱讀原文“查看論文詳情

相關閱讀,戳這里
《多場景落地!商湯打造“醫療大模型工廠”引領智慧醫療持續創新》
《嘉會醫療與商湯科技達成戰略合作》

原文標題:解決醫療大模型訓練數據難題,商湯最新研究成果登「Nature」子刊
文章出處:【微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
商湯科技
+關注
關注
8文章
508瀏覽量
36083
原文標題:解決醫療大模型訓練數據難題,商湯最新研究成果登「Nature」子刊
文章出處:【微信號:SenseTime2017,微信公眾號:商湯科技SenseTime】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何訓練自己的LLM模型
訓練自己的大型語言模型(LLM)是一個復雜且資源密集的過程,涉及到大量的數據、計算資源和專業知識。以下是訓練LLM模型的一般步驟,以及一些關
SynSense時識科技與海南大學聯合研究成果發布
近日,SynSense時識科技與海南大學聯合在影響因子高達7.7的國際知名期刊《Computers in Biology and Medicine》上發表了最新研究成果,展示了如何用低維信號通用類腦

中移芯昇發布智能可信城市蜂窩物聯網基礎設施研究成果
8月23日,雄安新區RISC-V產業發展交流促進會順利召開,芯昇科技有限公司(以下簡稱“中移芯昇”)總經理肖青發布智能可信城市蜂窩物聯網基礎設施研究成果,為雄安新區建設新型智慧城市賦能增效。該成果

llm模型訓練一般用什么系統
LLM(Large Language Model,大型語言模型)是近年來在自然語言處理領域取得顯著成果的一種深度學習模型。它通常需要大量的計算資源和數據來進行
深度學習模型訓練過程詳解
深度學習模型訓練是一個復雜且關鍵的過程,它涉及大量的數據、計算資源和精心設計的算法。訓練一個深度學習模型,本質上是通過優化算法調整
【大語言模型:原理與工程實踐】大語言模型的預訓練
大語言模型的核心特點在于其龐大的參數量,這賦予了模型強大的學習容量,使其無需依賴微調即可適應各種下游任務,而更傾向于培養通用的處理能力。然而,隨著學習容量的增加,對預訓練數據的需求也相
發表于 05-07 17:10
一種基于AlGaAs/GaAs漸變帶隙pn結探測器的單像素智能微型光譜儀
近日,Nature 子刊《Nature Communications》(IF=16.6)以“Single-pixel p-graded-n junction spectrometers
商湯科技與庫醇科技達成合作 為垂域大模型構建高質量大規模的領域微調數據
數字化轉型,為垂域大模型構建高質量大規模的領域微調數據。 ? 本次合作將基于商湯通用大模型進行二次開發,給模型注入領域知識,

再登Nature!DeepMind大模型突破60年數學難題,解法超出人類已有認知
用大模型解決困擾數學家60多年的問題,谷歌DeepMind最新成果再登 Nature。 作者之一、谷歌DeepMind研究副總裁Pushme






 工商網監
工商網監
評論