 MLPerf首次GPT大模型推理放榜 墨芯連續三屆登頂
MLPerf首次GPT大模型推理放榜 墨芯連續三屆登頂
隨著ChatGPT等AIGC應用掀起大模型浪潮,算力層作為基礎設施,成為最先受益的產業。
然而,算力需求大、費用昂貴等問題,已成為企業落地大模型的普通痛點,更可能制約AI向前發展:大模型參數日益增長,而算力供給瓶頸迫在眉睫,二者形成巨大矛盾。
如何探索更好的大模型算力方案,是業界共同關注的焦點。
近日,全球權威測評MLPerf 公布最新推理測評結果,這是MLPerf首度引入GPT大模型推理測試,參與熱度再創紀錄,收到了來自英偉達、英特爾、谷歌、高通等企業提交的13500 多項性能結果。

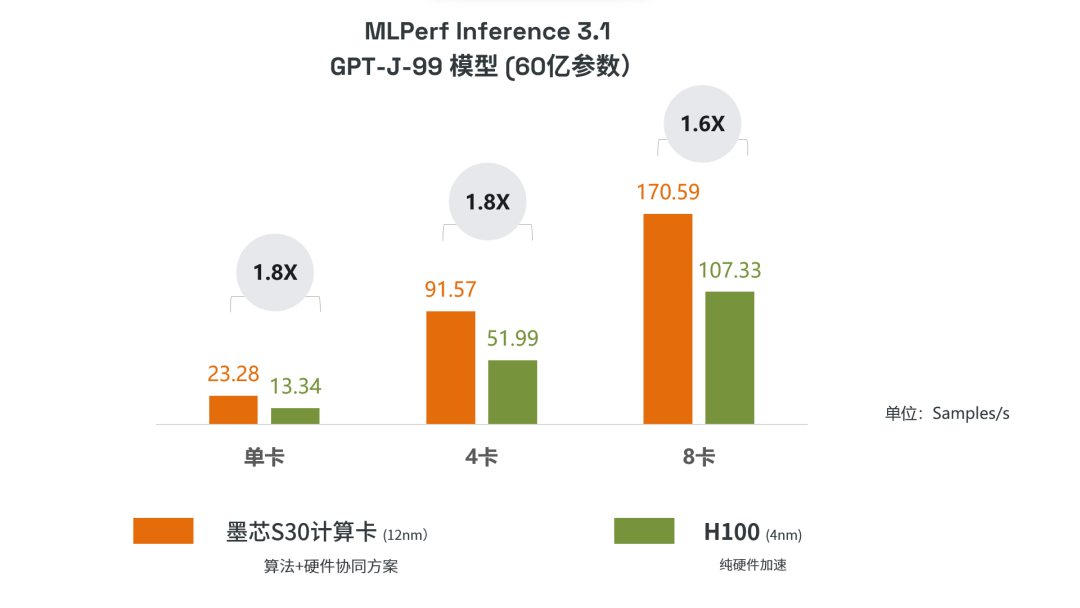
在MLPerf Inference 3.1中,墨芯人工智能(Moffet AI)S30計算卡在大模型GPT-J(60億參數)上,單卡、4卡、8卡的算力均獲得第一。
這是墨芯在MLPerf上連續第三次衛冕。此前墨芯曾在MLPerf Inference 2.0與2.1上,連續兩屆獲得第一。
墨芯的成績,為大模型算力方案帶來了可行的創新方向。
事實證明:結合AI模型與計算平臺的軟硬協同創新,能夠釋放更大的算力潛力。這也再度印證:以稀疏計算為代表的創新技術,將是大模型時代算力發展的關鍵。
墨芯參加的是MLPerf開放分區,據主辦方MLCommons介紹,該分區旨在鼓勵創新。因此參賽者可以通過軟硬協同等方式,探索對算力的提升。在MLPerf中的GPT-J大模型上,與4nm制程的H100純硬件加速方案相比,12nm制程的墨芯S30計算卡通過“原創的雙稀疏算法+硬件協同”方式,取得了高達1.8倍的優勢。
本次測評的GPT-J模型是生成式AI模型,墨芯S30計算卡在8卡、4卡、單卡模式下,性能分別為170.59,91.57,23.28 (Sample/s),達到英偉達H100性能的1.6倍、1.8倍、1.8倍,展現出墨芯產品在AIGC類任務上的能力。
三度奪冠,大模型算力率先“交卷”,軟硬協同持續創新——墨芯的產品實力數次經過MLPerf的嚴格檢驗,也探索出大模型算力發展的新路徑。
1
稀疏計算——大模型“潛力股”
獲得市場認可
墨芯接連的優異成績,主要得益于基于稀疏化算法的軟硬協同設計。
在大模型時代,稀疏計算的重要性不言而喻:AI模型大小與其稀疏化潛力成正比。
也就是說,當模型越大,算法上有更大稀疏的可能性,稀疏計算可加速的幅度也越高。對于一般大型語言模型,稀疏計算可帶來數十倍加速。
墨芯獨創的雙稀疏算法,結合軟硬協同設計,使墨芯Antoum芯片成為全球首款高稀疏倍率AI芯片,支持高達32倍稀疏——這也正是墨芯在本次MLPerf中創新紀錄的關鍵。
模型越大,稀疏計算的優勢越明顯——尤其是在GPT等大模型參數動輒上百億、千億的現狀下,這使得墨芯的護城河更為穩固。
墨芯的產品實力與稀疏計算的大勢所趨,也獲得了市場的認可:墨芯商業化進程接連取得重要突破,助力企業加速AI應用。
就在近日,墨芯成為支持Byte MLPerf的供應商之一。
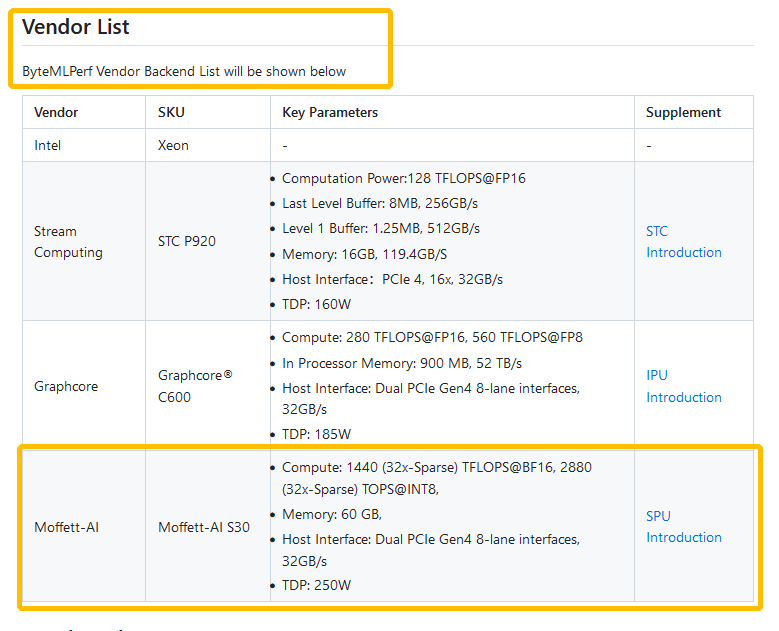
來源:Byte MLPerf網站
當前,墨芯AI計算平臺已能夠支持不同參數級別的大模型,包括 BLOOM, OPT, GPT-J,LLaMA,StableDiffusion等。同時具有高吞吐、低延時、低功耗等特點,緩解算力之困,真正為企業帶來“好用”、“用得起”的大模型算力方案。
2
帶來根本性的算力變革
稀疏計算助力大模型發展
墨芯的稀疏計算方案不僅能夠緩解當前的算力難題,也為AI的持續發展打開新的空間。
稀疏計算減少了AI模型的計算量,這意味著能讓大模型既在參數量上躍升若干個數量級的同時,又不產生過大的計算量,大模型參數增長與算力瓶頸的矛盾有望從根本上得到解決。
同時,由于計算量的減少,大模型的高算力需求、高功耗、高費用等痛點,也一并得到解決,實現“多贏”效果。
墨芯Antoum芯片:全球首款高稀疏倍率AI芯片,支持高達32倍稀疏
連續三屆MLPerf的優異成績,不僅是對墨芯產品實力的證明,也為業界帶來新啟示:在稀疏計算等技術的助力下,大模型的發展與應用有望迎來更廣闊的施展空間,加速AIGC等應用在各行各業遍地開花。
審核編輯:劉清
-
GPT
+關注
關注
0文章
354瀏覽量
15360 -
AI芯片
+關注
關注
17文章
1885瀏覽量
35008 -
ChatGPT
+關注
關注
29文章
1560瀏覽量
7624
原文標題:MLPerf首次GPT大模型推理放榜,墨芯連續三屆登頂
文章出處:【微信號:墨芯人工智能,微信公眾號:墨芯人工智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
立儀科技受邀參加第三屆中國傳感器與應用技術大會

高效大模型的推理綜述

線上逛展 | 沉浸探索第三屆OpenHarmony技術大會五大展區
高燃回顧|第三屆OpenHarmony技術大會精彩瞬間
云知聲山海多模態大模型UniGPT-mMed登頂MMMU測評榜首

第三屆OpenHarmony技術大會亮點紛呈

30s高能速遞 | 第三屆 OpenHarmony技術大會精彩搶鮮看
OpenAI即將發布“草莓”推理大模型
LLM大模型推理加速的關鍵技術
佰維存儲第三屆“Factory Tour”即將啟航,誠邀夢想少年共赴精彩“芯”程!






 工商網監
工商網監
評論