 馬毅團隊新作:白盒ViT成功實現
馬毅團隊新作:白盒ViT成功實現
【導讀】CRATE模型完全由理論指導設計,僅用自監督學習即可實現分割語義涌現。
基于Transformer的視覺基礎模型在各種下游任務,如分割和檢測中都展現出了非常強大的性能,并且DINO等模型經過自監督訓練后已經涌現出了語義的分割屬性。
不過奇怪的是,類似的涌現能力并沒有出現在有監督分類訓練后的視覺Transformer模型中。
最近,馬毅教授團隊探索了基于Transformer架構的模型中涌現分割能力是否僅僅是復雜的自監督學習機制的結果,或者是否可以通過模型架構的適當設計在更通用的條件下實現相同的涌現。

在CVer微信公眾號后臺回復:CRATE,可以下載本論文pdf和代碼
Emergence of Segmentation with Minimalistic White-Box Transformers
代碼:https://github.com/Ma-Lab-Berkeley/CRATE
論文:https://arxiv.org/abs/2308.16271
通過大量的實驗,研究人員證明了當采用白盒Transformer模型CRATE時,其設計明確地模擬并追求數據分布中的低維結構,整體和part級別的分割屬性已經以最小化的監督訓練配方出現。
分層的細粒度分析表明,涌現屬性有力地證實了白盒網絡的設計數學功能。我們的結果提出了一條設計白盒基礎模型的途徑,該模型同時具有高性能和數學上完全可解釋性。
馬毅教授也表示,深度學習的研究將會逐漸從經驗設計轉向理論指導。

白盒CRATE的涌現屬性
DINO的分割涌現能力
智能系統中的表征學習旨在將世界的高維、多模態感官數據(圖像、語言、語音)轉換為更緊湊的形式,同時保留其基本的低維結構,實現高效的識別(比如分類)、分組(比如分割)和追蹤。
深度學習模型的訓練通常采用數據驅動的方式,輸入大規模數據,以自監督的方式進行學習。
在視覺基礎模型中,自監督Transformer架構的DINO模型展現出了令人驚訝的涌現能力,即使沒有經過有監督分割訓練,ViTs也能識別出顯式的語義分割信息。
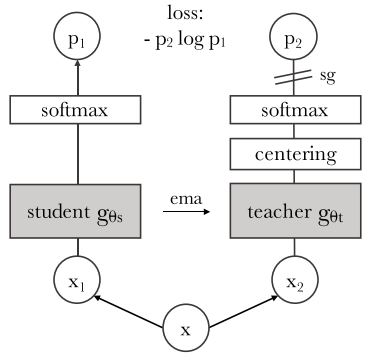
后續有工作研究了如何在DINO模型中利用這種分割信息,并在下游任務中,如分割、檢測等實現了最先進的性能,也有工作證明了用DINO訓練的ViTs中的倒數第二層特征與視覺輸入中的顯著性信息強烈相關,如區分前景、背景和物體邊界,從而提升圖像分割和其他任務的性能。
為了讓分割屬性涌現,DINO需要在訓練期間將自監督學習、知識蒸餾和權重平均巧妙地結合起來。
目前還不清楚DINO中引入的每個組件是否對于分割遮罩的涌現來說必不可缺,盡管DINO也采用ViT架構作為其主干,但在分類任務上訓練的普通有監督ViT模型中,并沒有觀察到分割涌現行為。
CRATE的涌現
基于DINO的成功案例,研究人員想要探究,復雜的自監督學習pipeline對于獲得類似Transformer的視覺模型中的涌現屬性是否是必要的。
研究人員認為,在Transformer模型中促進分割屬性的一種有前途的方法是,在考慮輸入數據結構的情況下設計Transformer模型架構,也代表了表征學習經典方法與現代數據驅動的深度學習框架的結合。

與目前主流的Transformer模型對比,這種設計方法也可以叫做白盒Transformer模型。
基于馬毅教授組之前的工作,研究人員對白盒架構的CRATE模型進行了廣泛的實驗,證明了CRATE的白盒設計是自注意力圖中分割屬性涌現的原因。
定性評估
研究人員采用基于[CLS] token的注意力圖方法對模型進行解釋和可視化,結果發現CRATE中的query-key-value矩陣都是相同的。
可以觀察到CRATE模型的自注意力圖(self-attention map)可以對應到輸入圖像的語義上,模型的內部網絡對每個圖像都進行了清晰的語義分割,實現了類似DINO模型的效果。
相比之下,在有監督分類任務上訓練的普通ViT卻并沒有表現出類似的分割屬性。

遵循之前關于可視化圖像學習的逐塊深度特征的工作,研究人員對CRATE和ViT模型的深度token表征進行主成分分析(PCA)研究。

可以發現,CRATE可以在沒有分割監督訓練的情況下,依然可以捕捉到圖像中物體的邊界。
并且,主成分(principal compoenents)也說明了token和物體中相似部分的特征對齊,例如紅色通道對應馬腿。
而有監督ViT模型的PCA可視化結構化程度相當低。
定量評估
研究人員使用現有的分割和目標檢測技術對CRATE涌現的分割屬性進行評估。
從自注意力圖可以看到,CRATE用清晰的邊界顯式地捕獲了對象級的語義,為了定量測量分割的質量,研究人員利用自注意力圖生成分割遮罩(segmentation mask),對比其與真實掩碼之間的標準mIoU(平均交并比)。
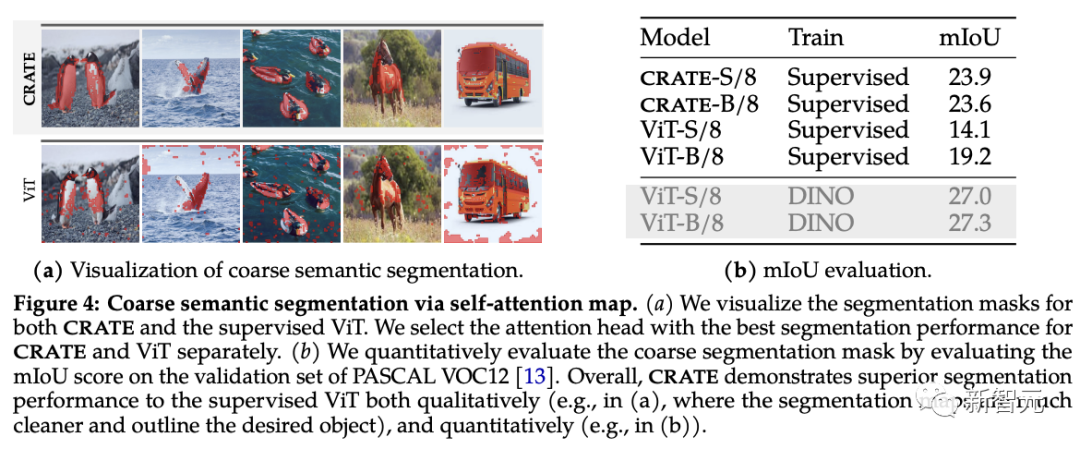
從實驗結果中可以看到,CRATE在視覺和mIOU評分上都顯著優于ViT,表明CRATE的內部表征對于分割掩碼任務生成來說要更有效。
對象檢測和細粒度分割
為了進一步驗證和評估CRATE捕獲的豐富語義信息,研究人員采用了一種高效的目標檢測和分割方法MaskCut,無需人工標注即可獲得自動化評估模型,可以基于CRATE學到的token表征從圖像中提取更細粒度的分割。

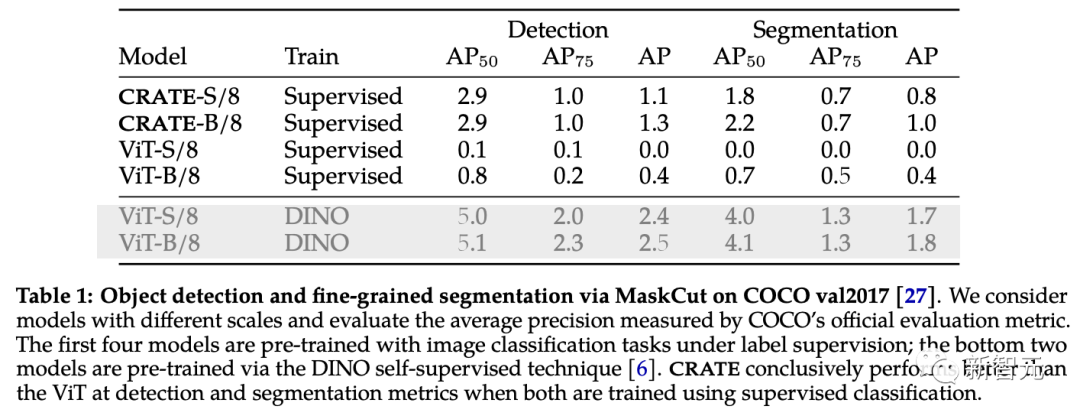
在COCO val2017上的分割結果中可以看到,有CRATE的內部表征在檢測和分割指標上都要好于有監督ViT,有監督ViT特征的MaskCut在某些情況下甚至完全不能產生分割掩碼。
CRATE分割能力的白盒分析
深度在CRATE中的作用
CRATE的每一層設計都遵循相同的概念目的:優化稀疏速率降低,并將token分布轉換為緊湊和結構化的形式。
假設CRATE中語義分割能力的涌現類似于「表征Z中屬于相似語義類別token的聚類」,預期CRATE的分割性能可以隨著深度的增加而提高。
為了測試這一點,研究人員利用MaskCut來定量評估跨不同層的內部表征的分割性能;同時應用PCA可視化來理解分割是如何隨深度加深而涌現的。
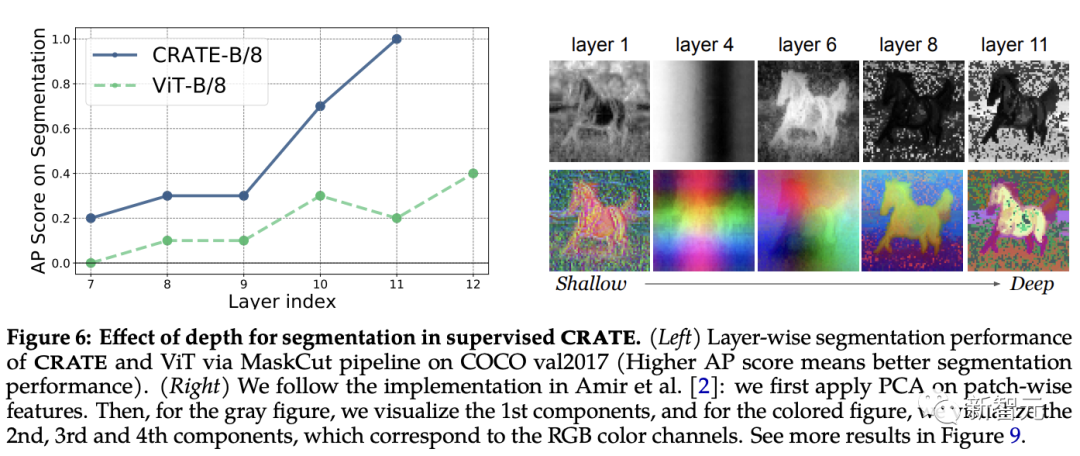
從實驗結果中可以觀察到,當使用來自更深層的表征時,分割分數提高了,與CRATE的增量優化設計非常一致。
相比之下,即使ViT-B/8的性能在后面的層中略有提高,但其分割分數明顯低于CRATE,PCA結果顯示,從CRATE深層提取的表征會逐漸更關注前景對象,并且能夠捕捉紋理級別的細節。
CRATE的消融實驗
CRATE中的注意力塊(MSSA)和MLP塊(ISTA)都不同于ViT中的注意力塊。
為了了解每個組件對CRATE涌現分割屬性的影響,研究人員選取了三個CRATE變體:CRATE, CRATE-MHSA, CRATE-MLP,分別表示ViT中的注意塊(MHSA)和MLP塊。
研究人員在ImageNet-21k數據集上應用相同的預訓練設置,然后應用粗分割評估和遮罩分割評估來定量對比不同模型的性能。
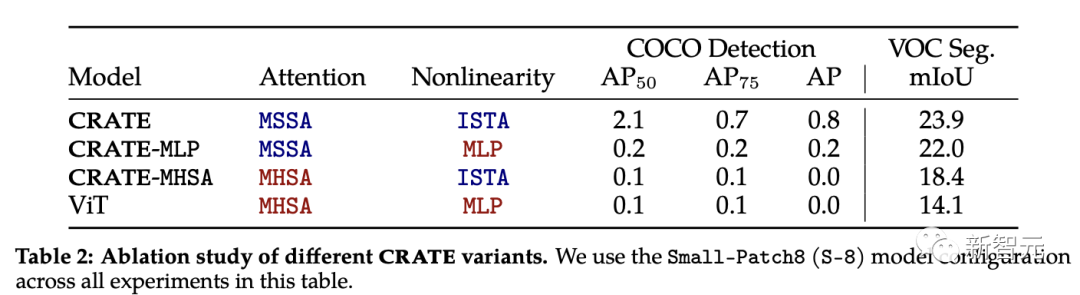
實驗結果顯示,CRATE在所有任務中都明顯優于其他模型架構,可以發現,盡管MHSA和MSSA之間的架構差異很小,但只需要簡單地用CRATE中的MSSA替換ViT中的MHSA,可以顯著改善ViT的粗分割性能(即VOC Seg),證明了白盒設計的有效性。
識別注意頭的語義屬性
[CLS] token和圖像塊token之間的自注意力圖可以看到清晰的分段掩碼,根據直覺,每個注意力頭應該都可以捕捉到數據的部分特征。
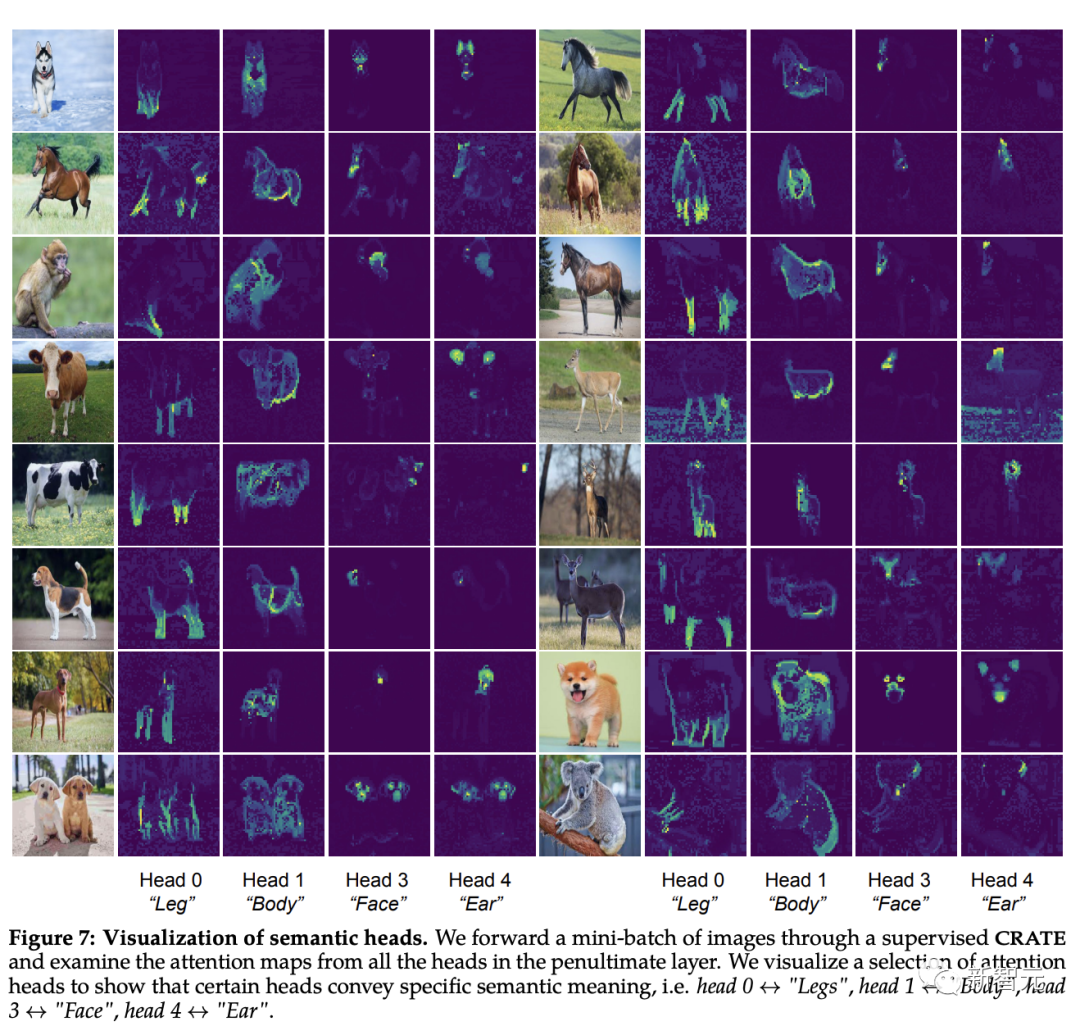
研究人員首先將圖像輸入到CRATE模型,然后由人來檢查、選擇四個似乎具有語義含義的注意力頭;然后在其他輸入圖像上在這些注意力頭上進行自注意力圖可視化。
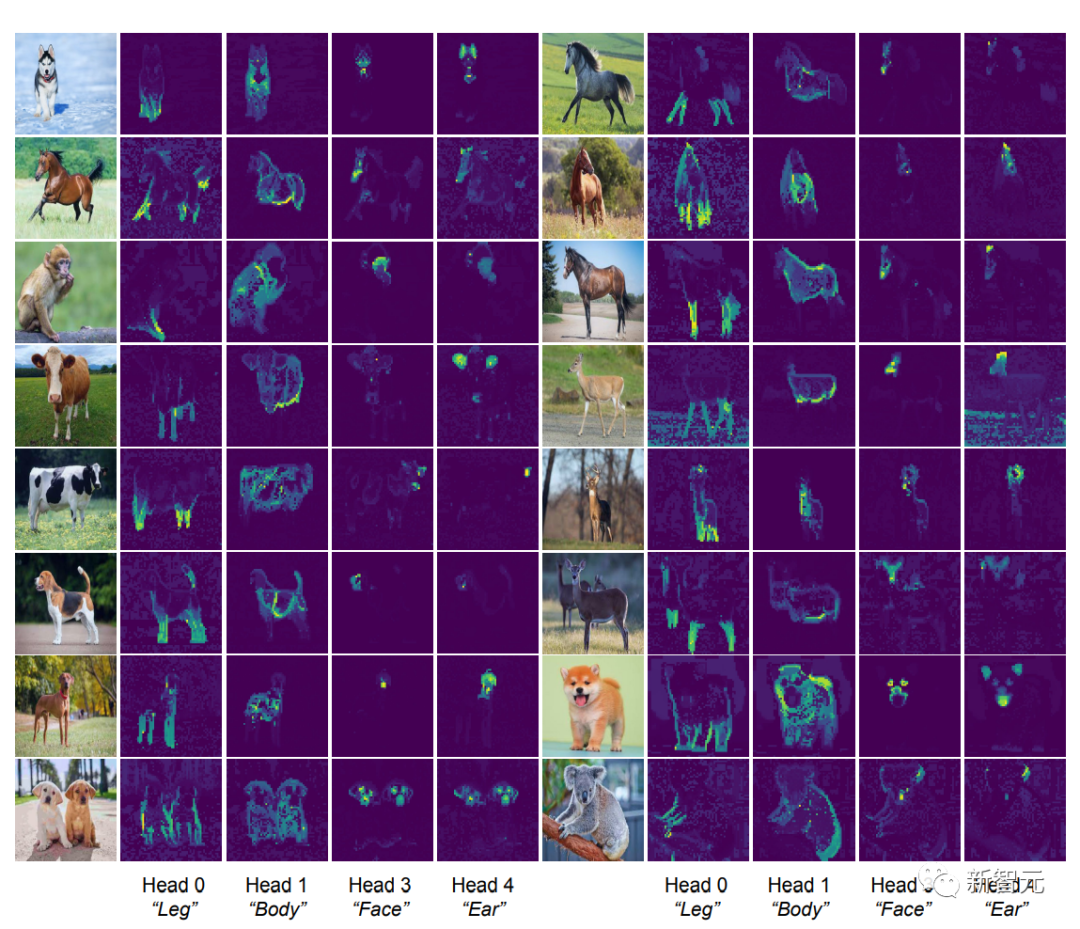
可以發現,每個注意力頭都捕捉到了物體的不同部分,甚至不同的語義:例如第一列中顯示的注意力頭可以捕捉到不同動物的腿,最后一列中顯示的注意力頭捕捉的是耳朵和頭部。
自從可形變部件模型(deformable part model)和膠囊網絡發布以來,這種將視覺輸入解析為部分-整體層次結構的能力一直是識別架構的目標,白盒設計的CRATE模型也具有這種能力。
-
模型
+關注
關注
1文章
3229瀏覽量
48813 -
深度學習
+關注
關注
73文章
5500瀏覽量
121117 -
Transformer
+關注
關注
0文章
143瀏覽量
5997
原文標題:馬毅團隊新作:白盒ViT成功實現"分割涌現"!具有高性能和數學可解釋的特性
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

基于白盒測試的自動化測試平臺實現

白盒高級加密標準的任務規劃系統安全傳輸

白盒交換機展趨勢漸起,新華三坐擁四大優勢有力支撐白盒生態
盒馬成阿里應對美團、京東、拼多多挑戰的棋子?
VectorCAST/QA如何在LiteOS-A內核上實現系統白盒測試





 工商網監
工商網監
評論