 什么是序列化 為什么要序列化
什么是序列化 為什么要序列化
什么是序列化?
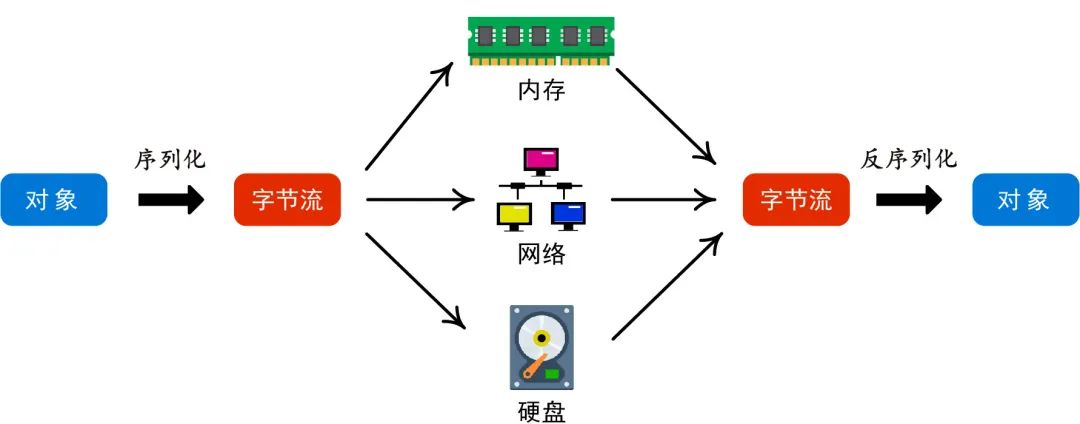
“序列化”(Serialization )的意思是將一個對象轉化為字節流。
這里說的對象可以理解為“面向對象”里的那個對象,具體的就是存儲在內存中的對象數據。
與之相反的過程是“反序列化”(Deserialization )。
雖然掛著機器人的羊頭,但是后面的介紹全部是計算機知識,跟機器人一丁點關系都沒有,序列化就是一個純粹的計算機概念。
序列化的英文Serialize就有把一個東西變成一串連續的東西之意。
形象的描述,數據對象是一團面,序列化就是將面團拉成一根面條,反序列化就將面條捏回面團。
另一個形象的類比是我們在對話或者打電話時,一個人的思想轉換成一維的語音,然后在另一個人的頭腦里重新變成結構化的思想,這也是一種序列化。
面對序列化,很多人心中可能會有很多疑問。
首先,為什么要序列化?或者更具體的說,既然對象的信息本來就是以字節的形式儲存在內存中,那為什么要多此一舉把一些字節數據轉換成另一種形式的、一維的、連續的字節數據呢?
如果我們的程序在內存中存儲了一個數字,比如25。那要怎么傳遞25這個數字給別的程序節點或者把這個數字永久存儲起來呢?
很簡單,直接傳遞25這個數字(的字節表示,即0X19,當然最終會變成二進制表示11001以高低電平傳輸存儲)或者直接把這個數字(的字節表示)寫進硬盤里即可。
所以,對于本來就是連續的、一維的、一連串的數據(例如字符串),序列化并不需要做太多東西,其本質是就是由內存向其它地方拷貝數據而已。
所以,如果你在一個序列化庫里看到memcpy函數不用覺得奇怪,因為你知道序列化最底層不過就是在操作內存數據而已(還有些庫使用了流的ostream.rdbuf()-》sputn函數)。
可是實際程序操作的對象很少是這么簡單的形式,大多數時候我們面對的是包含不同數據類型(int、double、string)的復雜數據結構(比如vector、list),它們很可能在內存中是不連續存儲的而是分散在各處。比如ROS的很多消息都包含向量。
數據中還有各種指針和引用。而且,如果數據要在運行于不同架構的計算機之上的、由不同編程語言所編寫的節點程序之間傳遞,那問題就更復雜了,它們的字節順序endianness規定有可能不一樣,基本數據類型(比如int)的長度也不一樣(有的int是4個字節、有的是8個字節)。
這些都不是通過簡單地、原封不動地復制粘貼原始數據就能解決的。這時候就需要序列化和反序列化了。
所以在程序之間需要通信時(ROS恰好就是這種情況),或者希望保存程序的中間運算結果時,序列化就登場了。
另外,在某種程度上,序列化還起到統一標準的作用。
我們把被序列化的東西叫object(對象),它可以是任意的數據結構或者對象:結構體、數組、類的實例等等。
把序列化后得到的東西叫archive,它既可以是人類可讀的文本形式,也可以是二進制形式。
前者比如JSON和XML,這兩個是網絡應用里最常用的序列化格式,通過記事本就能打開閱讀;
后者就是原始的二進制文件,比如后綴名是bin的文件,人類是沒辦法直接閱讀一堆的0101或者0XC9D23E72的。
序列化算是一個比較常用的功能,所以大多數編程語言(比如C++、Python、Java等)都會附帶用于序列化的庫,不需要你再去造輪子。
以C++為例,雖然標準STL庫沒有提供序列化功能,但是第三方庫Boost提供了[ 2
]谷歌的protobuf也是一個序列化庫,還有Fast-CDR,以及不太知名的Cereal,Java自帶序列化函數,python可以使用第三方的pickle模塊實現。
總之,序列化沒有什么神秘的,用戶可以看看這些開源的序列化庫代碼,或者自己寫個小程序試試簡單數據的序列化,例如這個例子,或者這個,有助于更好地理解ROS中的實現。
-
數據
+關注
關注
8文章
7006瀏覽量
88955 -
編程語言
+關注
關注
10文章
1942瀏覽量
34711 -
ROS
+關注
關注
1文章
278瀏覽量
17004
發布評論請先 登錄
相關推薦
如何使用Serde進行序列化和反序列化
Java序列化的機制和原理
c語言序列化和反序列化有何區別
SpringMVC JSON框架的自定義序列化與反序列化
流序列化的網絡流量分類算法
java序列化和反序列化范例和JDK類庫中的序列化API
C#實現對象序列化的三種方式是什么





 工商網監
工商網監
評論