 Arm最強處理器架構技術解析
Arm最強處理器架構技術解析
知名媒體nextplatform表示,仍在仔細研究最近在同一時間舉行的 Hot Interconnects、Hot Chips、Google Cloud Next 和 Meta Networking @ Scale 會議上的大量演示。他們打算采取通常的、有條理的方法來尋找有趣的部分并對我們所聽到和看到的內容進行一些分析。
這一次,其將目光投向了即將重新上市的 Arm Ltd. 正式推出的“Demeter”Neoverse V2 內核。
如果 Demeter 核心設計發生在五年前,或者更好的是十年前,這將是一件非常大的事情,因為對于許多想要制造 Arm 服務器芯片的組織來說,設計好的核心非常困難。正如今年 Hot Chips 發布的“Genesis”計算子系統 (CSS) 所示,設計一款好的處理器也許也很困難。超大規模廠商和云構建者一直想做的是針對其工作負載大量定制處理器,而不是設計處理器。大型企業有時也希望如此,并且具有特定工作負載需求的各種規模的企業類別也希望如此。
但處理器銷售商(并非所有銷售商都是制造商,也并非所有制造商都是銷售商)無法提供大規模定制,因為每一代制造多個變體的成本非常昂貴。我們確實看到的變化實際上是關于打開和關閉一些設計中固有的功能,這是由硅片部分的良率所迫使的,因為它是通過功率門控功能人為地創建變化并收取零件費用。
Demeter 核心是第一個實現 2021 年 3 月宣布的 Armv9 架構的核心,是迄今為止 Arm 為服務器設計的最好的核心,這就是為什么 Nvidia 能夠僅授權該核心和其他組件其72 核“Grace”服務器 CPU,它是 Nvidia 系統架構不可或缺的一部分,支持傳統 HPC 仿真和建模工作負載的全 CPU 計算,并提供輔助內存和計算能力。憑借四個 128 位 SVE2 矢量引擎,Demeter 核心肯定會有一個強大的引擎來運行經典的 HPC 工作負載以及某些 AI 推理工作負載(那些不太胖的工作負載,可能不包括大多數LLM),甚至可能是在某些情況下重新訓練人工智能模型。如果設計中可能有 16 到 256 個內核,那么觸發器當然可以堆疊起來。
我們只是想知道除了 Nvidia 之外,還有誰會在他們的 CPU 設計中使用 Demeter 核心。
AWS 很可能會在其未來的 Graviton4 服務器處理器中采用 V2 內核,并在其當前的 Graviton3 處理器中使用“Zeus”V1 內核。
目前尚不清楚谷歌在傳聞中正在開發的一對定制 Arm 服務器芯片中使用了什么內核——其中一個是與 Marvell 合作,如果傳聞屬實的話,另一個是與自己的團隊合作——但如果我們知道的話,我們也不會感到驚訝。其中之一是使用 V2 內核。
AmpereComputing 已在其 192 核“Siryn”AmpereOne 芯片中從 Arm 的“Ares”N1 內核切換為自己的內核(我們稱之為 A1)。
印度高級計算發展中心 (C-DAC) 正在為 HPC 工作負載構建自己的“Aum”處理器,并且它基于Arm的Neoverse V1核心。
正如我們之前指出的,富士通、Arm 和日本 RIKEN 實驗室聯合為“Fugaku”超級計算機使用的48 核 A64FX 處理器打造的定制 Arm 內核中的 512 位向量可以被視為一種Neoverse V0 核心在于 SVE 設計最初是為 A64FX 創建的。
我們還想知道,除了Arm在Hot Chips 2023上推出的N2核心芯片之外,為什么沒有立即推出基于V2核心的CSS服務器芯片設計。為什么CSS設計中不能同時使用N2和V2核心呢?我們意識到一些數據中心運營商需要更多的性價比優化,并且認為他們不需要那么多向量;軟件和工作負載是否正確還有待觀察。
但 AWS 選擇 V1 和 Nvidia 選擇 V2 是一個非常有力的指標。AmpereComputing計算 A1 核心在矢量方面更像是 N2 核心,有兩個 128 位引擎,因此云上胖矢量核心的這種行為并不普遍。
V2 就像火箭
Arm 于 2020 年 9 月將其 Neoverse 核心和 CPU 設計分為三部分,將 V 系列高性能核心(具有雙倍向量引擎)從主線 N 系列核心(專注于整數性能)中分離出來,并添加到 E 系列(入門級)重點關注能源效率和邊緣的芯片。多年來,該路線圖已經擴展和更新了很多次,最新的路線圖(帶有 N2 平臺添加的 CSS 子系統變體)已在 Hot Chips 上展示:
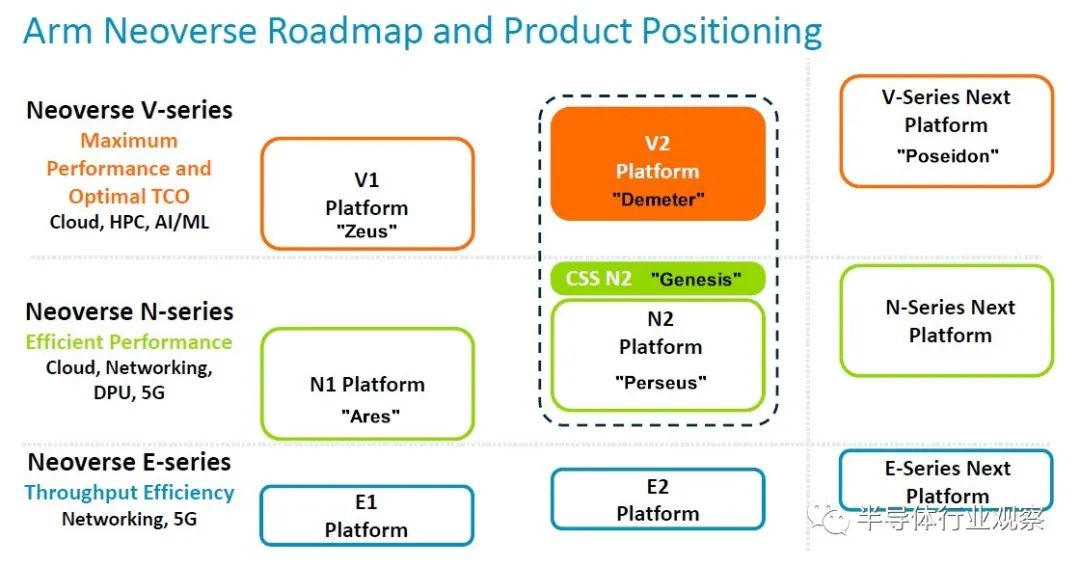
我們在我們熟悉的核心和平臺代號中添加了它們,因為我們喜歡同義詞。
Arm 院士兼首席 CPU 架構師 Magnus Bruce 在 Hot Chips 上介紹了 V2 平臺,談論了該架構以及與 Zeus V1 平臺相比的變化。這張圖表很好地總結了這一點:
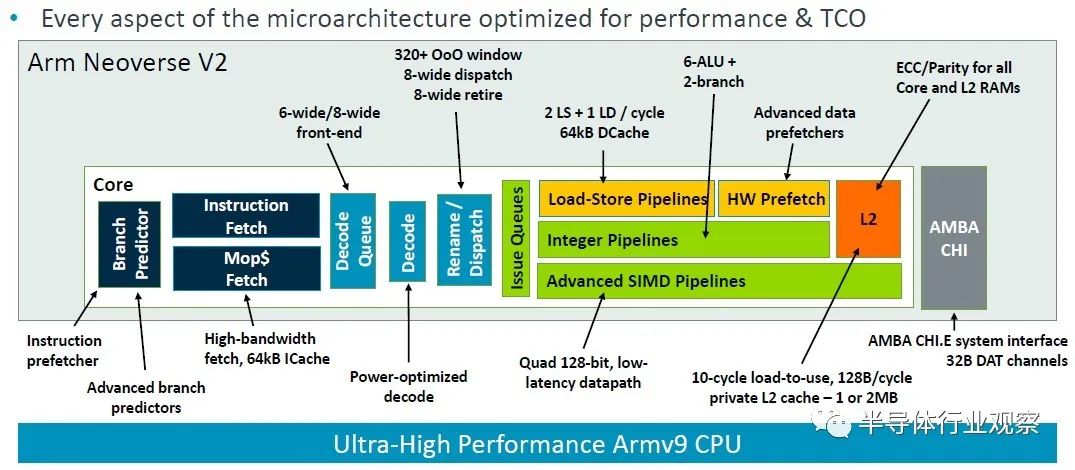
“這個管道的基礎是一個提前運行分支預測器,這個分支預測器充當指令預取器,它將提取與分支分離,”Bruce解釋道。“大型分支預測結構可以覆蓋非常大的現實服務器工作負載。我們使用在發出后讀取的物理寄存器文件,允許非常大的發出隊列,而無需存儲數據的負擔。這是解鎖 ILP [指令級并行性]。我們使用低延遲和私有 L2 緩存、低延遲 L1 和私有 L2 緩存以及最先進的預取算法和積極的存儲到加載轉發,以保持內核的氣泡和停頓最少( bubbles and stalls)。系統的動態反饋機制允許內核調節攻擊性并主動防止系統擁塞。這些基本概念使我們能夠擴大機器的寬度和深度,同時保持快速錯誤預測恢復所需的短管道。”
重要的是,這是一個 Armv9 實現,它旨在顛覆該架構,與十多年來定義 Arm 芯片的多代 Armv8 架構相比,它帶來了性能、安全性和可擴展性增強。
V2 芯片的架構調整很微妙,但顯然很有效。但同樣明顯的是,13% 的性能提升距離 Arm 早在 2019 年設定的每時鐘指令數 (IPC) 30% 的提升目標還有很長的路要走:
無論如何,這里是對 V2 核心的分支預測器和獲取單元以及 L1 緩存的深入分析:

正如您所看到的,V1 核心的很多功能都轉移到了 V2 核心,但 V2 核心也有一些更新。許多隊列、表和帶寬都增加了一倍,但微操作緩存實際上在轉向 V2 設計時減少了。根據使用芯片模擬器為 V1 和 V2 建模的 SPEC CPU 2017 整數基準,對 V2 內核的調整使每個時鐘指令增加了約 2.9%。
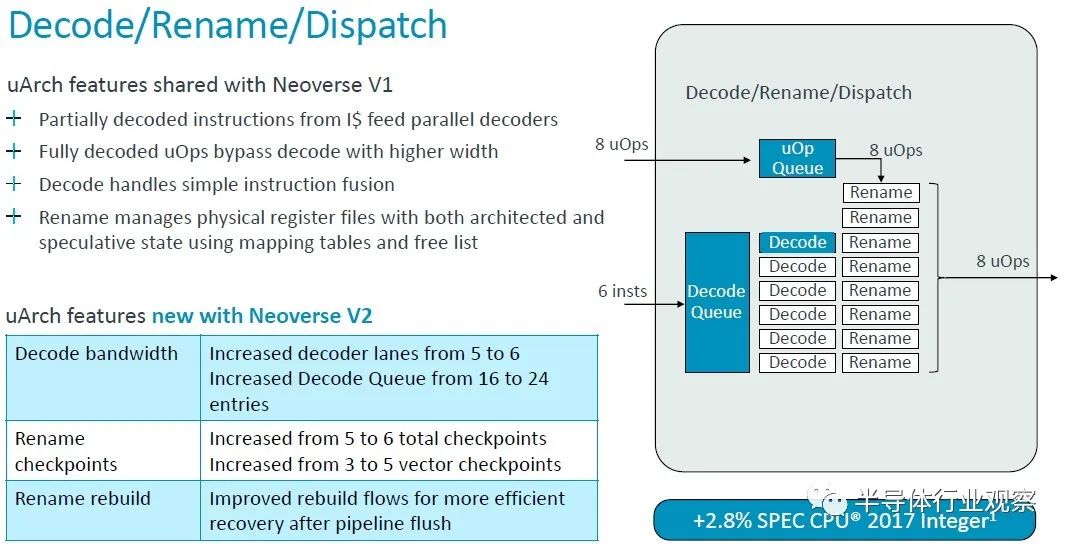
值得一提的是,V1 內核在解碼和指令分派方面的一些微架構優點直接傳遞到 V2 內核,但解碼器通道和隊列有所提升。總體效果是 IPC 提高了 2.9%,這也是通過 SPEC CPU 2017 整數測試來衡量的。(IPC 通常是使用混合測試來計算的,而不僅僅是 SPEC CPU 評級。但這就是我們得到的。)
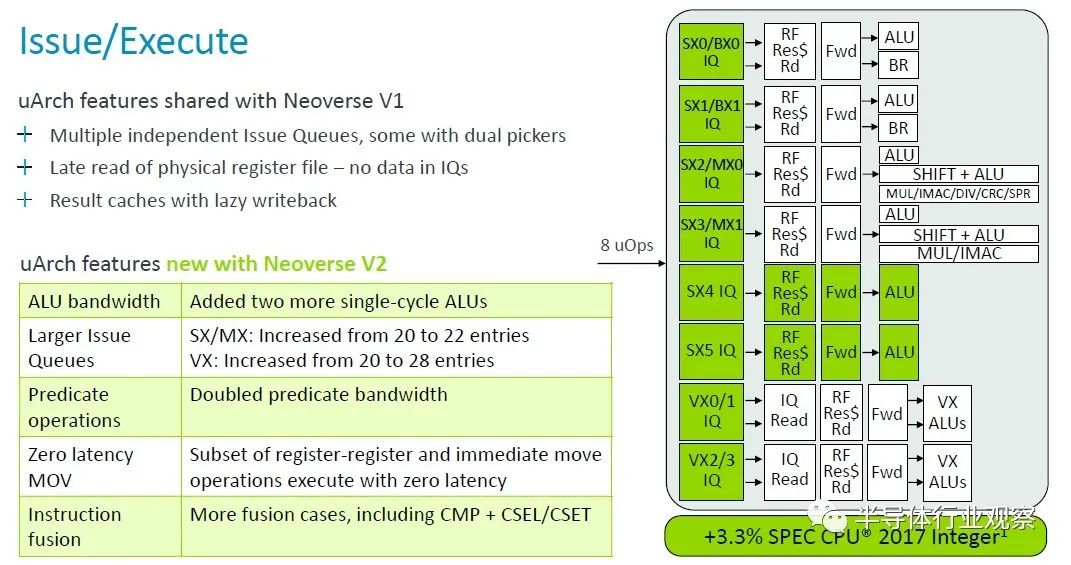
借助 V2 內核,Arm 架構師又添加了兩個單周期算術邏輯單元 (ALU),并增加了問題隊列的大小,并將謂詞運算符的帶寬加倍,這些調整加上其他一些調整,又增加了 3.3%核心性能在 2.8 GHz 下歸一化。
與 V1 核心一樣,V2 核心有兩個加載/存儲管道和一個加載管道,但表后備緩沖區 (TLB) 上的條目增加了 — 從 40 個條目增加到 48 個條目 — 并且各種存儲和讀取隊列也增加了變得更大。
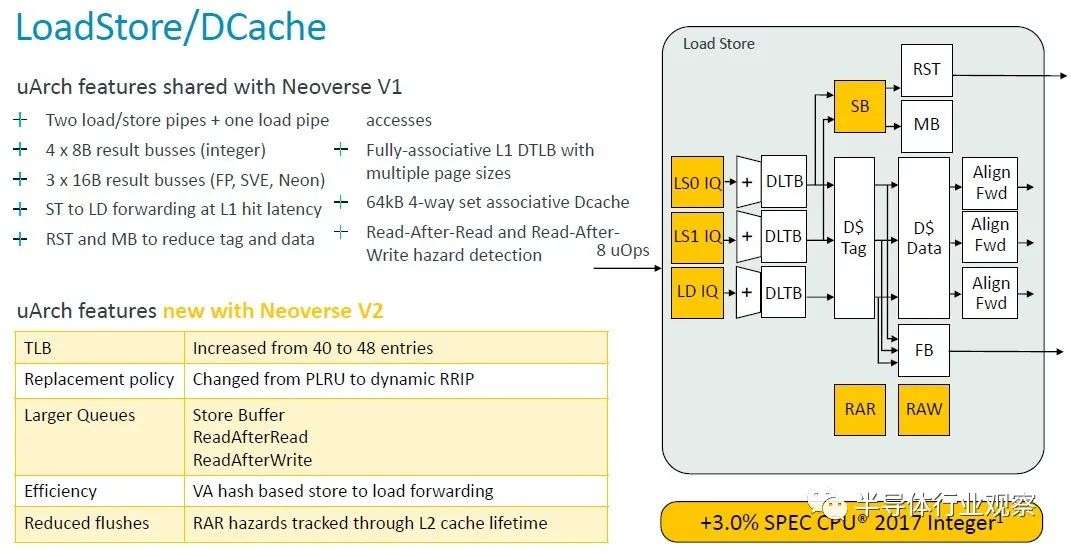
這一變化和其他變化使 V2 核心性能又增加了 3%。
Arm 架構師通過硬件預取數據的變化獲得了最大的性能提升:
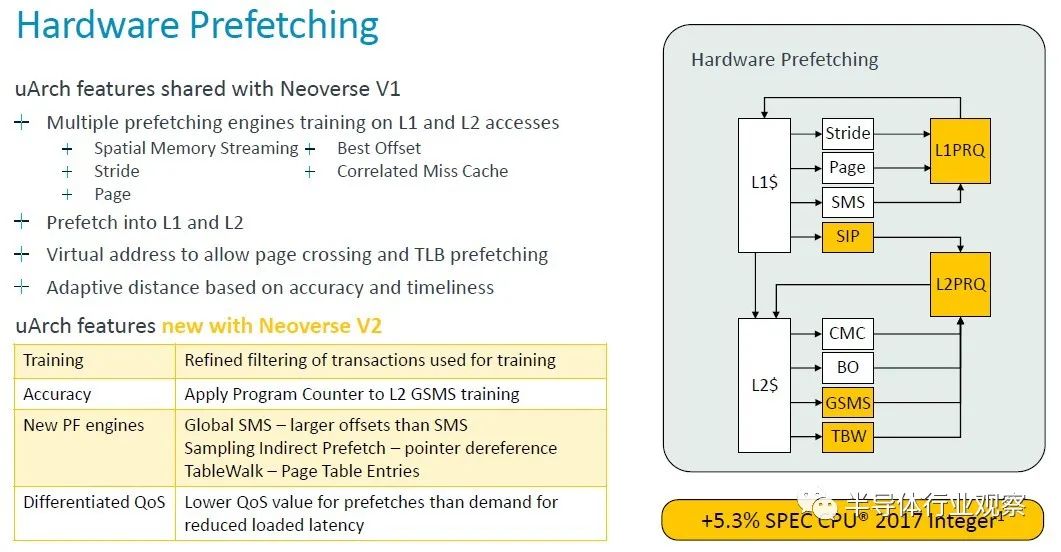
“Neoverse V1 已經具備了最先進的預取功能,”Bruce 解釋道,我們將讓他帶您了解預取增強功能的低級解釋。深吸一口氣。。。。“通過對 L1 和 L2 misses進行多引擎訓練并預取到 L1 和 L2 緩存中,我們的預取器通常使用虛擬地址來允許頁面交叉(page crossing),這使得它們也可以充當 TLB 預取。預取器使用來自互連的動態反饋以及 CPU 內部的準確性和及時性測量來調節其主動性。
V2 建立在 V1 硬件的基礎上,改進了訓練,通過更好的過濾和訓練操作提高準確性,并在更多預取器中使用程序計數器以實現更好的關聯和更好地防止混疊。還添加了新的預取引擎。L2 獲得了全局空間內存流引擎,增加了它可以覆蓋的預取器的偏移范圍,并且比舊的標準 SMS 引擎有了很大的改進。我們添加了一個采樣間接預取器( sampling indirect prefetcher),用于處理指針解除引用場景。
這不是數據預測,而是學習數據消耗模式作為其他負載的指針。我們還添加了一個表遍歷預取器(table walk prefetcher),可以將頁表條目預取(page table entries)到二級緩存中。現在,所有這些添加的預取器及其攻擊性都會造成系統擁塞。特別是在系統級緩存DRAM等共享資源上。我們為需求和預取提供差異化的 QoS 級別。這使我們能夠進行積極的預取,而不會影響需求請求的加載延遲。
動態預取動態反饋將預取器的攻擊性調節到可持續的水平。這些變化加起來使規格管理器增加了 5.3%,但更重要的是,我們同時看到 SLC 缺失減少了 8.2%,因此我們可以用更少的 DRAM 流量獲得更高的性能。”
以下是二級緩存如何發揮其魔力:
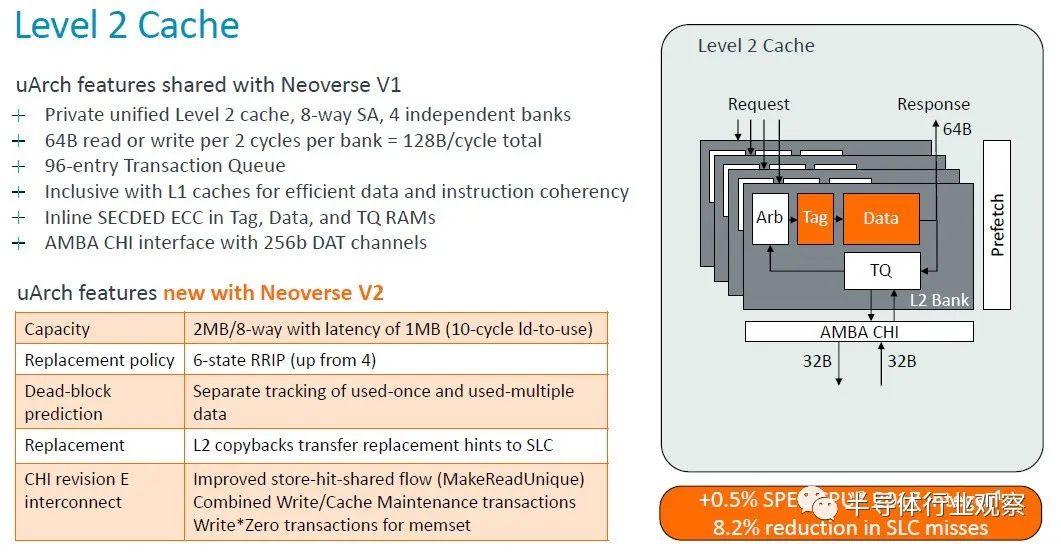
二級緩存加倍對性能來說并沒有太大變化,但系統級緩存misses的減少確實間接提高了性能。
以下是 IPC 的總和:
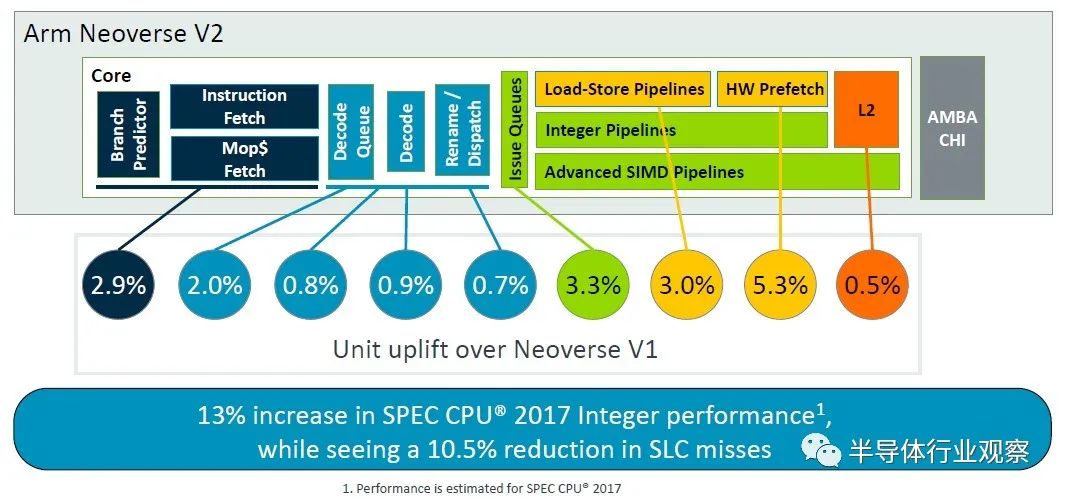
這些是加法效應,而不是乘法效應,V2 核心的整數性能提高了 13%——這也是經過建模的,而且這只是使用 SPEC CPU 2017 整數測試——同時將系統級緩存缺失減少了 10.5%總體百分比。
每當新的核心或芯片問世時,該核心或芯片都會根據性能、功耗和面積的相互作用進行分級。以下是 V1 和 V2 核心的堆疊方式:
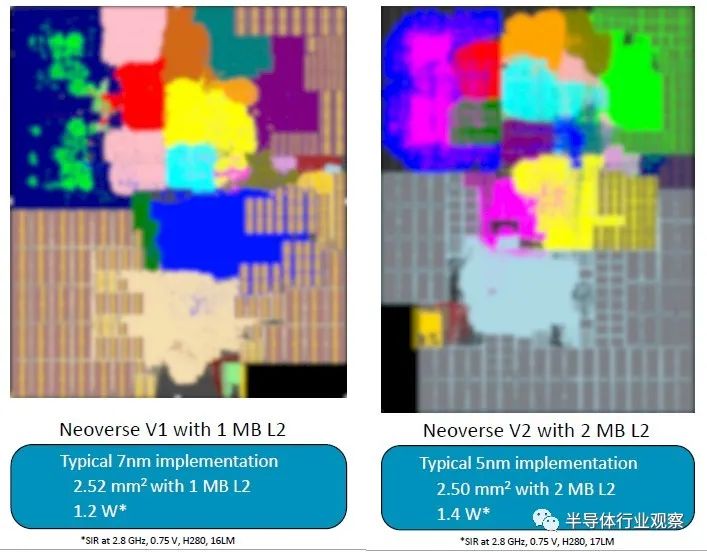
采用 7 納米工藝實現的 V1 核心面積為 2.5 平方毫米,二級緩存為 1 MB,功耗約為 1.2 瓦。V2 核心的面積稍小一些,L2 緩存是 2 MB 的兩倍,功耗提高了 17%。這些比較均以 2.8 GHz 時鐘速度進行標準化。
當然,V2 不僅僅是一個核心,而是一個可以授權的平臺規范:
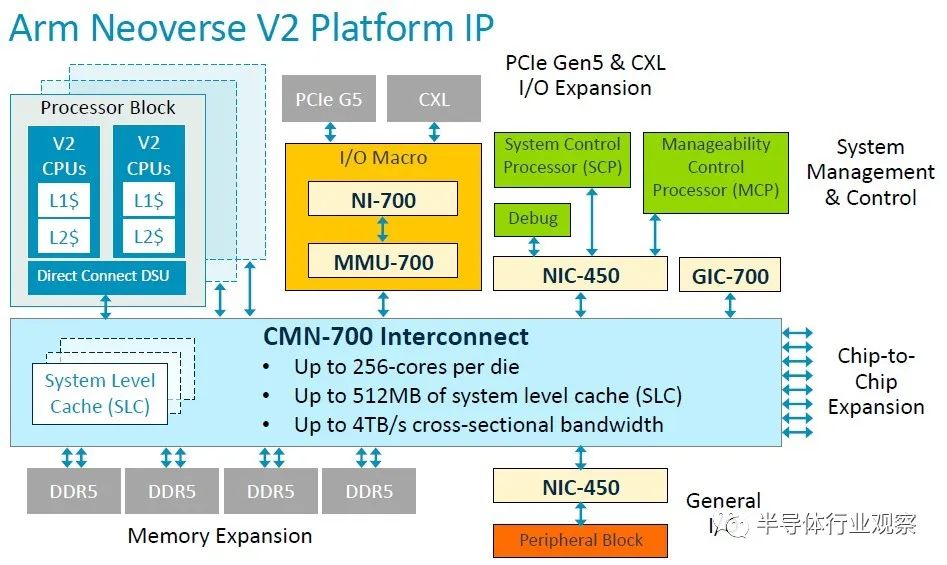
借助 CMN-700 互連,Arm 被許可人可以構建可擴展至 256 個內核和 512 MB 系統級緩存的 V2 CPU,該互連可在所有內核、內存和內存中提供 4 TB/秒的橫截面帶寬。位于網格上的 I/O 控制器。
V2 核心的很多演示都集中在整數方面,但在演講的問答中,Bruce 確實說了一些關于矢量性能的有趣內容。V1 核心有一對 256 位 SVE1 矢量引擎,但 V2 核心有四個 128 位 SVE2 矢量引擎。正如布魯斯所說,這樣做是因為將混合精度數學分散到四個單元比嘗試分散到兩個單元更容易(而且我們認為更有效)。
但正如我們所說,除了 Nvidia 和可能的 AWS 之外,誰將獲得 V2 核心的許可?也許任何打算使用 V2 的人都已經在進行自定義設計,因此沒有理由制作 CSS 變體?
編輯:黃飛
-
處理器
+關注
關注
68文章
19265瀏覽量
229684 -
ARM
+關注
關注
134文章
9088瀏覽量
367413 -
cpu
+關注
關注
68文章
10855瀏覽量
211610 -
服務器
+關注
關注
12文章
9129瀏覽量
85348 -
人工智能
+關注
關注
1791文章
47208瀏覽量
238298
原文標題:Arm最強處理來襲,誰會用
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于ARm架構的嵌入式微處理器
ARM公版架構 真的是麒麟處理器的槽點嗎?







 工商網監
工商網監
評論