 Hold住千億參數大模型,Gaudi?2 有何優勢
Hold住千億參數大模型,Gaudi?2 有何優勢
近日在北京舉行的2023年中國國際服務貿易交易會(下文簡稱:服貿會)上,作為英特爾人工智能產品組合的重要成員,Habana Gaudi2實力亮相,它在海內外諸多大語言模型(Large Language Model,下文簡稱:LLM)的加速上,已展現了出眾實力,成為業界焦點。
AI技術飛速發展,LLM風起云涌,但由于AI模型尤其是LLM的訓練與推理需要消耗大量資源和成本,在生產環境部署和使用這些模型變得極具挑戰。如何提升性能降低開銷,使AI技術更快普及,是行業內共同關注的話題。

專為加速LLM的訓練和推理設計
Habana Gaudi2 正是專為高性能、高效率大規模深度學習任務而設計的AI加速器,具備24個可編程Tensor處理器核心(TPCs)、21個100Gbps(RoCEv2)以太網接口、96GB HBM2E內存容量、2.4TB/秒的總內存帶寬、48MB片上SRAM,并集成多媒體處理引擎。該加速器能夠通過性能更高的計算架構、更先進的內存技術和集成RDMA實現縱向擴展,為中國用戶提供更高的深度學習效率與更優性價比。Gaudi2 的計算速度十分出色,它的架構能讓加速器并行執行通用矩陣乘法 (GeMM) 和其他運算,從而加快深度學習工作流。這些特性使 Gaudi2 成為 LLM 訓練和推理的理想選擇,亦將成為大規模部署AI的更優解。

在服貿會上,英特爾展示了Habana Gaudi2 對ChatGLM2-6B的加速能力。ChatGLM2-6B是開源中英雙語對話模型ChatGLM-6B的第二代版本,加強了初代模型對話流暢等優質特性。得益于專為深度學習設計的架構,Habana Gaudi2 可以靈活地滿足單節點、多節點的大規模分布式大語言模型訓練,在ChatGLM2-6B上,能夠支持更長的上下文,并帶來極速對話體驗。
在千億參數大模型上大顯身手
實際上,Habana Gaudi2 的卓越性能早已嶄露頭角。在今年6月公布的MLCommonsMLPerf基準測試中,Gaudi2在GPT-3模型、計算機視覺模型ResNet-50(使用8個加速器)、Unet3D(使用8個加速器),以及自然語言處理模型BERT(使用8個和64個加速器)上均取得了優異結果。近日,MLCommons又繼續公布了針對60億參數大語言模型及計算機視覺與自然語言處理模型GPT-J的MLPerf推理v3.1性能基準測試結果,其中包括基于Habana Gaudi2加速器、第四代英特爾至強可擴展處理器,以及英特爾至強CPU Max系列的測試結果。
數據顯示,Habana Gaudi2在GPT-J-99 和GPT-J-99.9 上的服務器查詢和離線樣本的推理性能分別為78.58 次/秒和84.08 次/秒。該測試采用 FP8數據類型,并在這種新數據類型上達到了 99.9% 的準確率,這無疑再一次印證了Gaudi2的出色性能。此外,基于第四代英特爾至強可擴展處理器的7個推理基準測試也顯示出其對于通用AI工作負載的出色性能。截至目前,英特爾仍是唯一一家使用行業標準的深度學習生態系統軟件提交公開CPU結果的廠商。
另一個讓Habana Gaudi2 大顯身手的模型是BLOOMZ。BLOOM是一個擁有 1760 億參數的自回歸模型,訓練后可用于生成文本序列,它可以處理 46 種語言和 13 種編程語言,而BLOOMZ是與BLOOM架構完全相同的模型,它是BLOOM基于多個任務的調優版本。Habana與著名AI平臺Hugging Face合作進行了 Gaudi2 在BLOOMZ模型上的基準測試1。如圖1所示,對于參數量達1760億的模型 BLOOMZ(BLOOMZ-176B),Gaudi2性能表現出色,時延僅為約3.7 秒;對于參數量為 70 億的較小模型 BLOOMZ-7B,Gaudi2 的時延優勢更加顯著,單設備約為第一代 Gaudi 的37.21%,而當設備數量都增加為8后,這一百分比進一步下降至約24.33%。
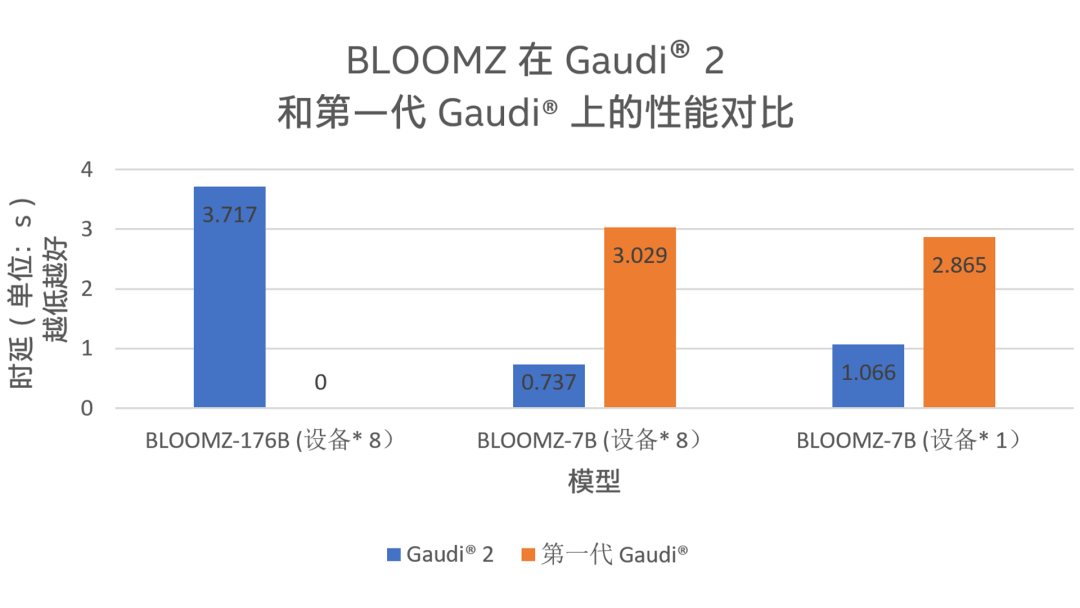
圖 1. BLOOMZ 在 Gaudi2 和第一代 Gaudi 上的推理時延測試結果
此外,在Meta發布的開源大模型Llama 2上,Gaudi2的表現依然出眾。圖2顯示了70億參數和130億參數兩種Llama 2模型的推理性能。模型分別在一臺Habana Gaudi2設備上運行,batch size=1,輸出token長度256,輸入token長度不定,使用BF16精度。報告的性能指標為每個token的延遲(不含第一個)。對于128至2000輸入token,在70億參數模型上Gaudi2的推理延遲范圍為每token 9.0-12.2毫秒,而對于130億參數模型,范圍為每token 15.5-20.4毫秒2。
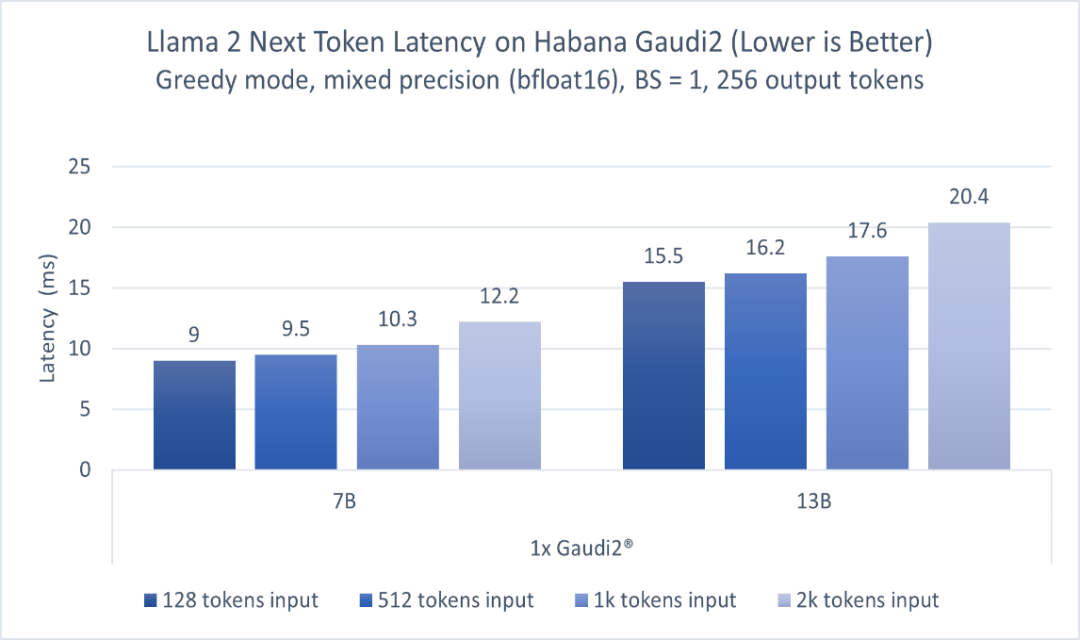
圖 2.基于HabanaGaudi2,70億和130億參數Llama 2模型的推理性能
值得一提的是,Habana 的SynapseAI 軟件套件在模型部署和優化的過程中起到了至關重要的作用。SynapseAI 軟件套件不僅支持使用 PyTorch 和 DeepSpeed 來加速LLM的訓練和推理,還支持 HPU Graph和DeepSpeed-inference,這兩者都非常適合時延敏感型應用。因此,在Habana Gaudi2上部署模型非常簡單,尤其是對LLM等數十億以上參數的模型推理具有較優的速度優勢,且無需編寫復雜的腳本。
LLM的成功堪稱史無前例。有人說,LLM讓AI技術朝著通用人工智能(AGI)的方向邁進了一大步,而因此面臨的算力挑戰也催生了更多技術的創新。Habana Gaudi2 正是在這一背景下應運而生,以其強大的性能和性價比優勢加速深度學習工作負載。Habana Gaudi2的出色表現更進一步顯示了英特爾AI產品組合的競爭優勢,以及英特爾對加速從云到網絡到邊緣再到端的工作負載中大規模部署AI的承諾。英特爾將持續引領產品技術創新,豐富和優化包括英特爾 至強 可擴展處理器、英特爾 數據中心GPU等在內的AI產品組合,助力中國本地AI市場發展。
參考資料:
1.https://huggingface.co/blog/zh/habana-gaudi-2-bloom
2.Habana Gaudi2深度學習加速器:所有測量使用了一臺HLS2 Gaudi2服務器上的Habana SynapseAI 1.10版和optimum-habana 1.6版,該服務器具有八個Habana Gaudi2 HL-225H Mezzanine卡和兩個英特爾 至強 白金8380 CPU@2.30GHz以及1TB系統內存。2023年7月進行測量。
-
英特爾
+關注
關注
61文章
9978瀏覽量
171883 -
cpu
+關注
關注
68文章
10873瀏覽量
212052
原文標題:Hold住千億參數大模型,Gaudi?2 有何優勢
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論