 SQL的執行順序圖解
SQL的執行順序圖解
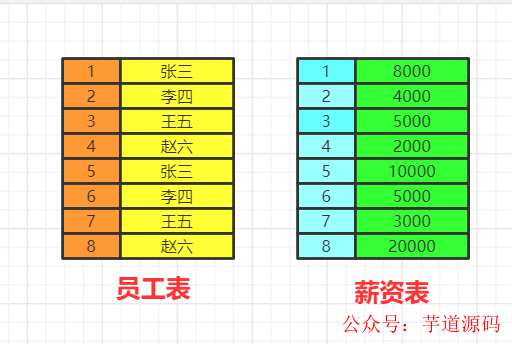
數據的關聯過程
from&join&where
group by
having&where
select
order by
limit
這是一條標準的查詢語句:
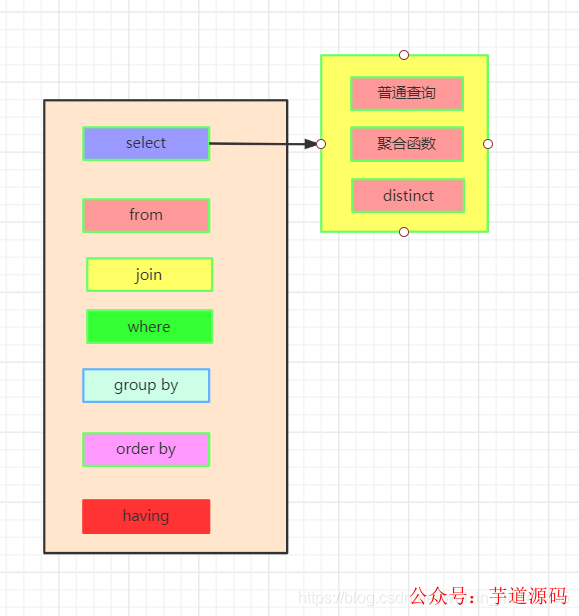
這是我們實際上SQL執行順序:
我們先執行from,join來確定表之間的連接關系,得到初步的數據
where對數據進行普通的初步的篩選
group by 分組
各組分別執行having中的普通篩選或者聚合函數篩選。
然后把再根據我們要的數據進行select,可以是普通字段查詢也可以是獲取聚合函數的查詢結果,如果是集合函數,select的查詢結果會新增一條字段
將查詢結果去重distinct
最后合并各組的查詢結果,按照order by的條件進行排序
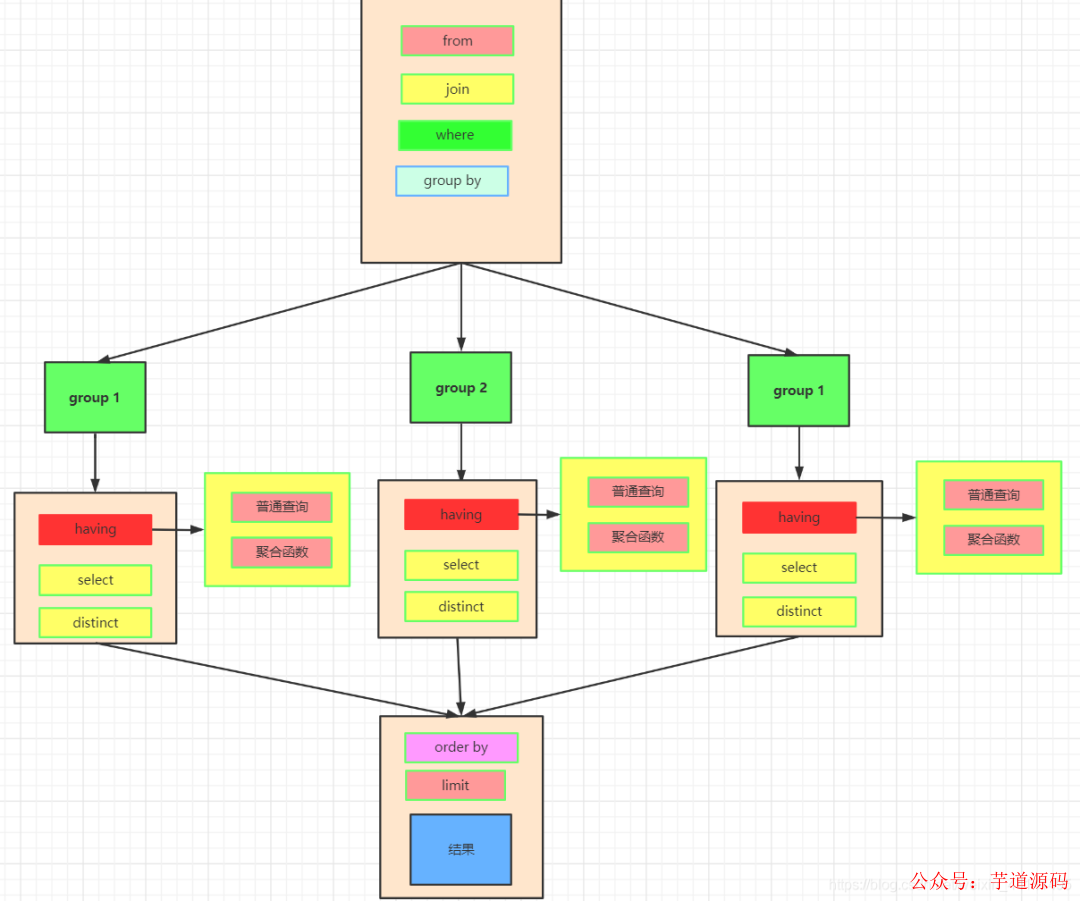
數據的關聯過程
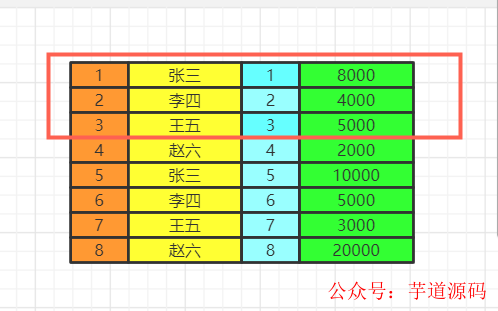
數據庫中的兩張表
from&join&where
用于確定我們要查詢的表的范圍,涉及哪些表。
選擇一張表,然后用join連接
fromtable1jointable2ontable1.id=table2.id
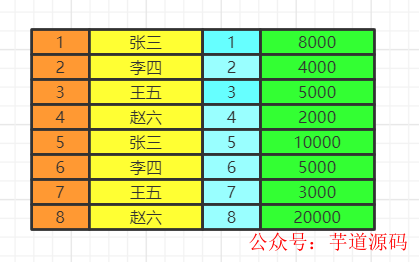
選擇多張表,用where做關聯條件
fromtable1,table2wheretable1.id=table2.id
我們會得到滿足關聯條件的兩張表的數據,不加關聯條件會出現笛卡爾積。
group by
按照我們的分組條件,將數據進行分組,但是不會篩選數據。
比如我們按照即id的奇偶分組
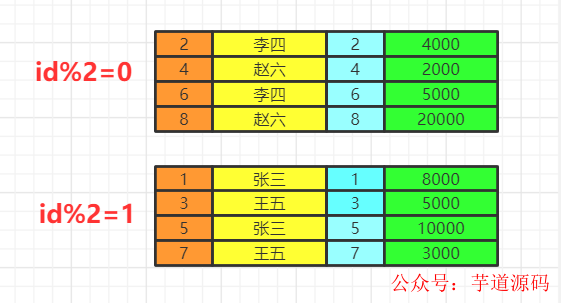
having&where
having中可以是普通條件的篩選,也能是聚合函數。而where只能是普通函數,一般情況下,有having可以不寫where,把where的篩選放在having里,SQL語句看上去更絲滑。
使用where再group by
先把不滿足where條件的數據刪除,再去分組
使用group by再having
先分組再刪除不滿足having條件的數據,這兩種方法有區別嗎,幾乎沒有!
舉個例子:
100/2=50,此時我們把100拆分(10+10+10+10+10…)/2=5+5+5+…+5=50,只要篩選條件沒變,即便是分組了也得滿足篩選條件,所以where后group by 和group by再having是不影響結果的!
不同的是,having語法支持聚合函數,其實having的意思就是針對每組的條件進行篩選。我們之前看到了普通的篩選條件是不影響的,但是having還支持聚合函數,這是where無法實現的。
當前數據分組情況
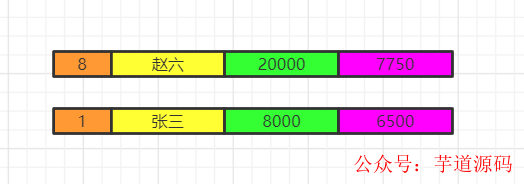
執行having的篩選條件,可以使用聚合函數。篩選掉工資小于各組平均工資的having salary
select
分組結束之后,我們再執行select語句,因為聚合函數是依賴于分組的,聚合函數會單獨新增一個查詢出來的字段,這里用紫色表示,這里我們兩個id重復了,我們就保留一個id,重復字段名需要指向來自哪張表,否則會出現唯一性問題。最后按照用戶名去重。
selectemployee.id,distinctname,salary,avg(salary)
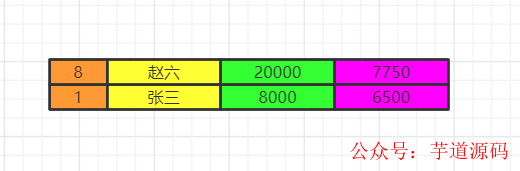
將各組having之后的數據再合并數據。
order by
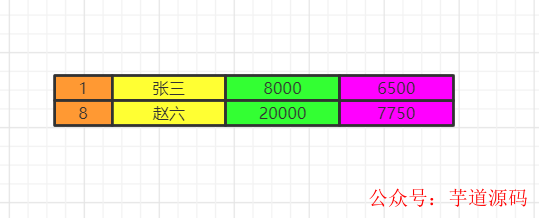
最后我們執行order by 將數據按照一定順序排序,比如這里按照id排序。如果此時有limit那么查詢到相應的我們需要的記錄數時,就不繼續往下查了。
limit
記住limit是最后查詢的,為什么呢?假如我們要查詢年級最小的三個數據,如果在排序之前就截取到3個數據。實際上查詢出來的不是最小的三個數據而是前三個數據了,記住這一點。
我們如果limit 0,3竊取前三個數據再排序,實際上最少工資的是2000,3000,4000。你這里只能是4000,5000,8000了。
編輯:黃飛
-
數據
+關注
關注
8文章
7067瀏覽量
89132 -
SQL
+關注
關注
1文章
766瀏覽量
44165
原文標題:圖解 SQL 的執行順序,一目了然!
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
連接oracle數據庫,封裝sql執行子vi
mfc程序執行流程小結,MFC程序的執行順序

1433端口的SQL TOOL執行命令錯誤應該如何修復詳細說明
如何通過explain來驗證sql的執行順序

一條SQL語句是怎么被執行的
系統上線時SQL腳本的9大坑
sql執行順序優先級是什么





 工商網監
工商網監
評論