 使用APM無法實現真正可觀測性的原因
使用APM無法實現真正可觀測性的原因
作者介紹:向陽,清華大學博士,云杉網絡研發 VP,曾獲網絡測量領域國際頂會 ACM IMC 頒發的第一屆 Community Contribution Award,現負責云原生可觀測性產品 DeepFlow。產品基于 eBPF 等新技術幫助云原生應用快速實現零侵擾、全棧的可觀測性,相關論文被通信領域國際頂會 ACM SIGCOMM 2023 主會錄用。
控制理論中的可觀測性是指:系統可以由其外部輸出確定其內部狀態的程度。在復雜 IT 系統中,具備可觀測性是為了讓系統能達到某個預定的穩定性、錯誤率目標。隨著微服務數量的急速膨脹和云原生基礎設施的快速演進,建設可觀測性已經成為了保障業務穩定性的必要條件。
然而,傳統的 APM 無法實現真正的可觀測性:一方面插樁行為已經修改了原程序,邏輯上已無法實現原程序的可觀測性;另一方面云原生基礎設施組件越來越多,基礎服務難以插樁導致觀測盲點越來越多。實際上,插樁的方式在金融、電信等重要行業的核心業務系統中幾乎無法落地。eBPF 由于其零侵擾的優勢,避免了 APM 插樁的缺點,是云原生時代實現可觀測性的關鍵技術。
本文依次論述 APM 無法實現真正可觀測性的原因,分析為什么 eBPF 是可觀測性的關鍵技術,介紹 DeepFlow 基于 eBPF 的三大核心功能,并進一步闡述如何向 eBPF 的觀測數據中注入業務語義。在此之后,本文分享了 DeepFlow 用戶的九大類真實使用案例,總結了用戶在采用 eBPF 技術前的常見疑問。最后,本文進一步分析了 eBPF 對新技術迭代的重大意義。
01: 使用 APM 無法實現真正的可觀測性
APM 希望通過代碼插樁(Instrumentation)的方式來實現應用程序的可觀測性。利用插樁,應用程序可以暴露非常豐富的觀測信號,包括指標、追蹤、日志、函數性能剖析等。然而插樁的行為實際上改變了原始程序的內部狀態,從邏輯上并不符合可觀測性「從外部數據確定內部狀態」的要求。在金融、電信等重要行業的核心業務系統中,APM Agent 落地非常困難。進入到云原生時代,這個傳統方法也面臨著更加嚴峻的挑戰。總的來講,APM 的問題主要體現在兩個方面:Agent 的侵擾性導致難以落地,觀測盲點導致無法定界。
第一,探針侵擾性導致難以落地。插樁的過程需要對應用程序的源代碼進行修改,重新發布上線。即使例如 Java Agent 這類字節碼增強技術,也需要修改應用程序的啟動參數并重新發版。然而,對應用代碼的改造還只是第一道關卡,通常落地過程中還會碰到很多其他方面的問題:
代碼沖突:當你為了分布式追蹤、性能剖析、日志甚至服務網格等目的注入了多個 Java Agent 時,是否經常遇到不同 Agent 之間產生的運行時沖突?當你引入一個可觀測性的 SDK 時,是否遇到過依賴庫版本沖突導致無法編譯成功?業務團隊數量越多時,這類兼容性問題的爆發會越為明顯。
維護困難:如果你負責維護公司的 Java Agent 或 SDK,你的更新頻率能有多高?就在此時,你們公司的生產環境中有多少個版本的探針程序?讓他們更新到同一個版本需要花多長時間?你需要同時維護多少種語言的探針程序?當企業的微服務框架、RPC 框架無法統一時,這類維護問題還將會更加嚴重。
邊界模糊:所有的插樁代碼嚴絲合縫的進入了業務代碼的運行邏輯中,不分你我、不受控制。這導致當出現性能衰減或運行錯誤時,插樁代碼往往難辭其咎。即使探針已經經過了長時間的實戰打磨,遇到問題時也免不了要求排除嫌疑。
實際上,這也是為什么侵擾性的插樁方案少見于成功的商業產品,更多見于活躍的開源社區。OpenTelemetry、SkyWalking 等社區的活躍正是佐證。而在部門分工明確的大型企業中,克服協作上的困難是一個技術方案能夠成功落地永遠也繞不開的坎。特別是在金融、電信、電力等承載國計民生的關鍵行業中,部門之間的職責區分和利益沖突往往會使得落地插樁式的解決方案成為「不可能」。即使是在開放協作的互聯網企業中,也少不了開發人員對插樁的不情愿、運維人員在出現性能故障時的背鍋等問題。在經歷了長久的努力之后人們已經發現,侵入性的解決方案僅僅適合于每個業務開發團隊自己主動引入、自己維護各類 Agent 和 SDK 的版本、自己對性能隱患和運行故障的風險負責。當然,我們也看到了一些得益于基建高度統一而取得成功的大型互聯網公司案例,例如 Google 就在 2010 年的 Dapper 論文中坦言:
True application-level transparency, possibly our most challenging design goal, was achieved by restricting Dapper’s core tracing instrumentation to a small corpus of ubiquitous threading, control flow, and RPC library code.
再例如字節跳動在 2022 年的對外分享《分布式鏈路追蹤在字節跳動的實踐》中也表示:
得益于長期的統一基建工作,字節全公司范圍內的所有微服務使用的底層技術方案統一度較高。絕大部分微服務都部署在公司統一的容器平臺上,采用統一的公司微服務框架和網格方案,使用公司統一提供的存儲組件及相應 SDK。高度的一致性對于基礎架構團隊建設公司級別的統一鏈路追蹤系統提供了有利的基礎。
第二,觀測盲點導致無法定界。即使 APM 已經在企業內落地,我們還是會發現排障邊界依然難以界定,特別是在云原生基礎設施中。這是因為開發和運維往往使用不同的語言在對話,例如當調用時延過高時開發會懷疑網絡慢、網關慢、數據庫慢、服務端慢,但由于全棧可觀測性的缺乏,網絡、網關、數據庫給出的應答通常是網卡沒丟包、進程 CPU 不高、DB 沒有慢日志、服務端時延很低等一大堆毫無關聯的指標,仍然解決不了問題。定界是整個故障處理流程中最關鍵的一環,它的效率至關重要。
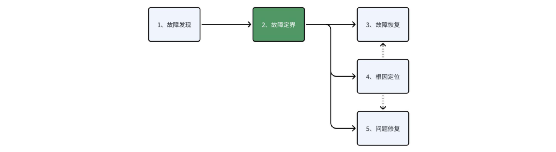
定界在故障處理流程中的核心作用
這里我們想澄清兩個概念:排障邊界和職責邊界。雖然開發的職責邊界是應用程序本身,但排障邊界卻需要延展到網絡傳輸上。舉個例子:微服務在請求 RDS 云服務時偶現高達 200ms 的時延,如果開發以此為依據向云服務商提交工單,得到的應答大概率會是「RDS 沒有觀察到慢日志,請自查」。我們在很多客戶處碰到了大量此類案例,根因有的是 RDS 前的 SLB 導致、有的是 K8s Node 的 SNAT 導致,背后的原因千奇百怪,但若不能在第一時間完成故障定界,都會導致租戶(開發)和云服務商(基礎設施)之間長達數天乃至數周的工單拉鋸戰。從排障邊界的角度來講,若開發能給出「網卡發送請求到收到響應之間的時延高達 200ms」,就能快速完成定界,推動云服務商排查。找對了正確的人,之后的問題解決一般都非常快。我們在后文也會分享幾個真實案例。
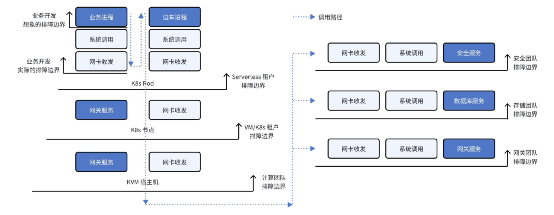
不同角色的排障邊界
上圖中我們對不同場景下的排障邊界進行了總結:如果你是一個業務開發工程師,除了業務本身以外,還應該關心系統調用和網絡傳輸過程;如果你是一個 Serverless 租戶,你可能還需要關注服務網格邊車及其網絡傳輸;如果你直接使用虛擬機或自建 K8s 集群,那么容器網絡是需要重點關注的問題點,特別還需注意 K8s 中的 CoreDNS、Ingress Gateway 等基礎服務;如果你是私有云的計算服務管理員,應該關心 KVM 宿主機上的網絡性能;如果你是私有云的網關、存儲、安全團隊,也需要關注服務節點上的系統調用和網絡傳輸性能。實際上更為重要的是,用于故障定界的數據應該使用類似的語言進行陳述:一次應用調用在整個全棧路徑中,每一跳到底消耗了多長時間。通過上述分析我們發現,開發者通過插樁提供的觀測數據,可能只占了整個全棧路徑的 1/4。在云原生時代,單純依靠 APM 來解決故障定界,本身就是妄念。
02: 為什么 eBPF 是可觀測性的關鍵技術
本文假設你對 eBPF 有了基礎的了解,它是一項安全、高效的通過在沙箱中運行程序以實現內核功能擴展的技術,是對傳統的修改內核源代碼和編寫內核模塊方式的革命性創新。你可訪問 ebpf.io 以了解更多的 eBPF 相關知識,本文聚焦于討論 eBPF 對云原生應用可觀測性的革命性意義。
eBPF 程序是事件驅動的,當內核或用戶程序經過一個 eBPF Hook 時,對應 Hook 點上加載的 eBPF 程序就會被執行。Linux 內核中預定義了一系列常用的 Hook 點,你也可以利用 kprobe 和 uprobe 技術動態增加內核和應用程序的自定義 Hook 點。得益于 Just-in-Time (JIT) 技術,eBPF 代碼的運行效率可媲美內核原生代碼和內核模塊。得益于 Verification 機制,eBPF 代碼將會安全的運行,不會導致內核崩潰或進入死循環。
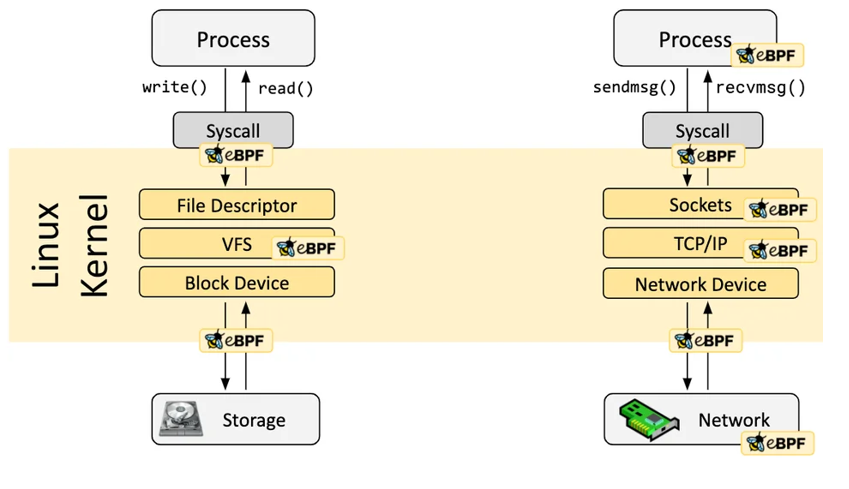
https://ebpf.io/what-is-ebpf/#hook-overview
回到可觀測性上,沙箱機制是 eBPF 有別于 APM 插樁機制的核心所在,「沙箱」在 eBPF 代碼和應用程序的代碼之間劃上了一道清晰的界限,使得我們能在不對應用程序做任何修改的前提下,通過獲取外部數據就能確定其內部狀態。下面我們來詳細分析下為何 eBPF 是解決 APM 代碼插樁缺陷的絕佳解決方案:
第一,零侵擾解決落地難的問題。由于 eBPF 程序無需修改應用程序代碼,因此不會有類似 Java Agent 的運行時沖突和 SDK 的編譯時沖突,解決了代碼沖突問題;由于運行 eBPF 程序無需改變和重啟應用進程,不需要應用程序重新發版,不會有 Java Agent 和 SDK 的版本維護痛苦,解決了維護困難問題;由于 eBPF 在 JIT 技術和 Verification 機制的保障下高效安全的運行,因此不用擔心會引發應用進程預期之外的性能衰減或運行時錯誤,解決了邊界模糊問題。另外從管理層面,由于只需要在每個主機上運行一個獨立的 eBPF Agent 進程,使得我們可以對它的 CPU 等資源消耗進行單獨的、精確的控制。
第二,全棧能力解決故障定界難的問題。eBPF 的能力覆蓋了從內核到用戶程序的每一個層面,因此我們得以跟蹤一個請求從應用程序出發,經過系統調用、網絡傳輸、網關服務、安全服務,到達數據庫服務或對端微服務的全棧路徑,提供充足的中立觀測數據,快速完成故障的定界。
然而,eBPF 并不是一個易于掌握的技術,它需要開發者有一定的內核編程基礎,它獲取的原始數據缺乏結構化信息。下文將會以我們的產品 DeepFlow 為例,介紹如何掃清這些障礙,充分發揮 eBPF 對可觀測性工程的關鍵作用。
03: DeepFlow 基于 eBPF 的三大核心功能
DeepFlow [GitHub] 旨在為復雜的云原生應用提供簡單可落地的深度可觀測性。DeepFlow 基于 eBPF 和 Wasm 技術實現了零侵擾(Zero Code)、全棧(Full Stack)的指標、追蹤、調用日志、函數剖析數據采集,并通過智能標簽技術實現了所有數據的全關聯(Universal Tagging)和高效存取。使用 DeepFlow,可以讓云原生應用自動具有深度可觀測性,從而消除開發者不斷插樁的沉重負擔,并為 DevOps/SRE 團隊提供從代碼到基礎設施的監控及診斷能力。
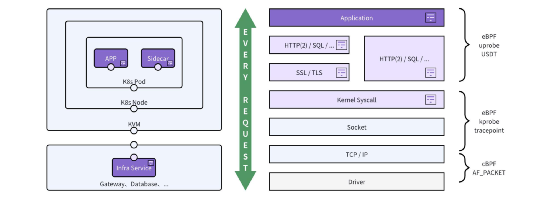
DeepFlow 基于 eBPF 技術實現云原生應用的零侵擾可觀測性
通過利用 eBPF 和 cBPF 采集應用函數、系統調用函數、網卡收發的數據,DeepFlow 首先聚合成 TCP/UDP 流日志(Flow Log);通過應用協議識別,DeepFlow 聚合得到應用調用日志(Request Log),進而計算出全棧的 RED(Request/Error/Delay)性能指標,并關聯調用日志實現分布式追蹤。除此之外,DeepFlow 在流日志聚合過程中還計算了 TCP 吞吐、時延、建連異常、重傳、零窗等網絡層性能指標,以及通過 Hook 文件讀寫操作計算了 IO 吞吐和時延指標,并將所有這些指標關聯至每個調用日志上。另外,DeepFlow 也支持通過 eBPF 獲取每個進程的 OnCPU、OffCPU 函數火焰圖,以及分析 TCP 包繪制 Network Profile 時序圖。所有這些能力最終體現為三大核心功能:
Universal Map for Any Service,任意服務的全景圖
Distributed Tracing for Any Request,任意調用的分布式追蹤
Continuous Profiling for Any Function,任何函數的持續性能剖析

DeepFlow 基于 eBPF 的三大核心功能
核心功能一:任意服務的全景圖。全景圖直接體現出了 eBPF 零侵擾的優勢,對比 APM 有限的覆蓋能力,所有的服務都能出現在全景圖中。但 eBPF 獲取的調用日志不能直接用于拓撲展現,DeepFlow 為所有的數據注入了豐富的標簽,包括云資源屬性、K8s 資源屬性、自定義 K8s 標簽等。通過這些標簽可以快速過濾出指定業務的全景圖,并且可以按不同標簽分組展示,例如 K8s Pod、K8s Deployment、K8s Service、自定義標簽等。全景圖不僅描述了服務之間的調用關系,還展現了調用路徑上的全棧性能指標,例如下圖右側為兩個 K8s 服務的進程在相互訪問時的逐跳時延變化。我們可以很快的發現性能瓶頸到底位于業務進程、容器網絡、K8s 網絡、KVM 網絡還是 Underlay 網絡。充足的中立觀測數據是快速定界的必要條件。
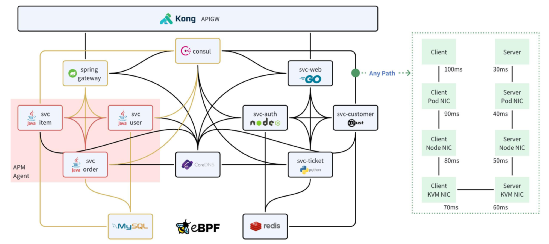
DeepFlow 的全景圖對比 APM Agent 獲取的拓撲圖
核心功能二:任意調用的分布式追蹤。零侵擾的分布式追蹤(AutoTracing)是 DeepFlow 中的一個重大創新,在通過 eBPF 和 cBPF 采集調用日志時,DeepFlow 基于系統調用上下文計算出了 syscall_trace_id、thread_id、goroutine_id、cap_seq、tcp_seq 等信息,無需修改應用代碼、無需注入 TraceID、SpanID 即可實現分布式追蹤。目前 DeepFlow 除了跨線程(通過內存 Queue 或 Channel 傳遞信息)和異步調用以外,都能實現零侵擾的分布式追蹤。此外也支持解析應用注入的唯一 Request ID(例如幾乎所有網關都會注入 X-Request-ID)來解決跨線程和異步的問題。下圖對比了 DeepFlow 和 APM 的分布式追蹤能力。APM 僅能對插樁的服務實現追蹤,常見的是利用 Java Agent 覆蓋 Java 服務。DeepFlow 使用 eBPF 實現了所有服務的追蹤,包括 Nginx 等 SLB、Spring Cloud Gateway 等微服務網關、Envoy 等 Service Mesh 邊車,以及 MySQL、Redis、CoreDNS 等基礎服務(包括它們讀寫文件的耗時),除此之外還覆蓋了 Pod NIC、Node NIC、KVM NIC、物理交換機等網絡傳輸路徑,更重要的是對 Java、Golang 以及所有語言都可無差別支持。
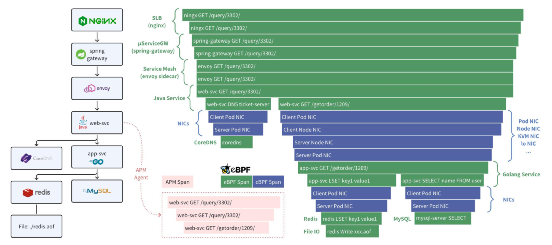
DeepFlow 和 APM 的分布式追蹤對比
注意 eBPF 和 APM 的分布式追蹤能力并不是矛盾的。APM 能用于追蹤應用進程內部的函數調用路徑,也擅長于解決跨線程和異步場景。而 eBPF 有全局的覆蓋能力,能輕松覆蓋網關、基礎服務、網絡路徑、多語言服務。在 DeepFlow 中,我們支持調用 APM 的 Trace API 以展示 APM + eBPF 的全鏈路分布式追蹤圖,同時也對外提供了Trace Completion API使得 APM 可調用 DeepFlow 以獲取并關聯 eBPF 的追蹤數據。
核心功能三:任意函數的持續性能剖析。通過獲取應用程序的函數調用棧快照,DeepFlow 可繪制任意進程的 CPU Profile,幫助開發者快速定位函數性能瓶頸。函數調用棧中除了包含業務函數以外,還可展現動態鏈接庫、內核系統調用函數的耗時情況。除此之外,DeepFlow 在采集函數調用棧時生成了唯一標識,可用于與調用日志相關聯,實現分布式追蹤和函數性能剖析的聯動。特別地,DeepFlow 還利用 cBPF 對網絡中的逐包進行了分析,使得在低內核環境中可以繪制每個 TCP 流的 Network Profile,剖析其中的建連時延、系統(ACK)時延、服務響應時延、客戶端等待時延。使用 Network Profile 可推斷應用程序中性能瓶頸的代碼范圍,我們在后文中也會分享相關案例。
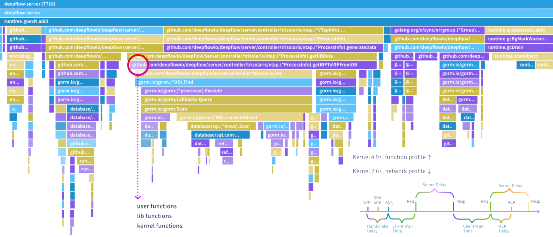
DeepFlow 中的 CPU Profile 和 Network Profile
本文無法完整的解釋這些激動人心的特性背后的原理,DeepFlow 同時也是一個開源項目,您可以閱讀我們的 GitHub 代碼和文檔了解更多信息,也可閱讀我們發表在網絡通信領域頂級會議ACM SIGCOMM 2023上的論文 Network-Centric Distributed Tracing with DeepFlow: Troubleshooting Your Microservices in Zero Code。
04: 向 eBPF 觀測數據中注入業務語義
使用 APM Agent 的另一個訴求是向數據中注入業務語義,例如一個調用關聯的用戶信息、交易信息,以及服務所在的業務模塊名稱等。從 eBPF 采集到的原始字節流中很難用通用的方法提取業務語義,在 DeepFlow 中我們實現了兩個插件機制來彌補這個不足:通過 Wasm Plugin 注入調用粒度的業務語義,通過 API 注入服務粒度的業務語義。
第一、通過 Wasm Plugin 注入調用粒度的業務語義:DeepFlow Agent 內置了常見應用協議的解析能力,且在持續迭代增加中,下圖中藍色部分均為原生支持的協議。我們發現實際業務環境中情況會更加復雜:開發會堅持返回 HTTP 200 同時將錯誤信息放到自定義 JSON 結構中,大量 RPC 的 Payload 部分使用 Protobuf、Thrift 等依賴 Schema 進行解碼的序列化方式,調用的處理流程中發生了跨線程導致 eBPF AutoTracing 斷鏈。為了解決這些問題 DeepFlow 提供了 Wasm Plugin 機制,支持開發者對 Pipeline 中的 ProtocolParser 進行增強。
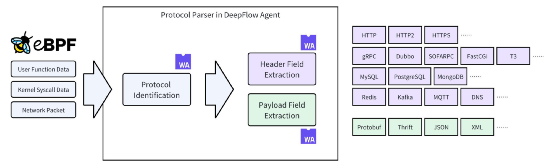
利用 DeepFlow Wasm Plugin 注入調用粒度的業務語義
實際上,我們也觀察到在金融、電信、游戲等行業中,已經存在了「天然」的分布式追蹤標記,例如金融業務中的全局交易流水號,電信核心網中的呼叫 ID、游戲業務中的業務請求 ID 等等。這些 ID 會攜帶在所有調用中,但具體的位置是業務自身決定的。通過 Wasm Plugin 釋放的靈活性,開發者可以很容易的編寫插件支持將這些信息提取為 TraceID。
第二、通過 API 注入服務粒度的業務語義:默認情況下,DeepFlow 的 SmartEncoding 機制會自動為所有觀測信號注入云資源、容器 K8s 資源、K8s 自定義 Label 標簽。然而這些標簽體現的只是應用層面的語義,為了幫助用戶將 CMDB 等系統中的業務語義注入到觀測數據中,DeepFlow 提供了一套用于業務標簽注入的 API。
05: DeepFlow 用戶的真實使用案例
在本章節中,我們將為大家分享 DeepFlow 用戶的九大類實戰案例。這些案例都是一些難以提前預料的疑難雜癥,我們將會看到在僅有 APM 數據時,它們通常持續了數天甚至數周都還找不到方向,而依靠 eBPF 的能力往往能在 5 分鐘之內完成故障定界。在開始介紹它們之前我還想澄清一下,這并不意味著 eBPF 的能力只擅長于解決疑難雜癥,我們現在已經知道 eBPF 能夠零侵擾的采集 Metrics、Request Logs、Profiles 等觀測信號,DeepFlow 也已經基于這些信號實現了通用的全景圖(包括性能指標、調用日志等)、分布式追蹤、持續性能剖析功能。
第一類案例,快速定位引發問題的服務:
案例 1:5 分鐘定位訪問共享服務的 Top 客戶端。MySQL、Redis、Consul 等基礎設施通常被很多微服務共享使用,當它們的負載過高時通常很難判斷是哪些客戶端造成的。這是因為容器 Pod 訪問這些共享服務時通常會做 SNAT,服務端看到的是容器節點的 IP;非容器環境下每個主機上也會有大量進程共享使用主機的 IP。可以想象從服務端的調用日志中分析 IP 地址是十分低效的,而我們也不能寄期望于所有客戶端都注入了 APM Agent。使用 DeepFlow,我們的一個大型銀行客戶在 5 分鐘內從近十萬個 Pod 中快速定位了請求 RDS 集群最高頻的微服務,我們的一個智能汽車客戶在 5 分鐘內從上萬個 Pod 中快速定位了請求 Consul 最高頻的微服務。
案例 2:5 分鐘定位被忽視的共享服務。DeepFlow 的一個大型銀行客戶在進行「分布式核心交易系統」上線測試時,發現由物理環境遷移到私有云上的交易系統性能非常差。經過了兩周的排查、在注入了一大堆 APM Agent 以后,最終只能定位到問題位于名為cr****rs的服務訪問授權交易服務au****in的鏈路上,但這兩個服務在遷移上云之前沒有任何性能問題。開發團隊一度開始懷疑私有云基礎設施,但沒有任何數據支撐。毫無頭緒時找到了 DeepFlow 團隊,在部署 eBPF Agent 以后所有微服務之間的訪問關系和性能指標全部呈現在了眼前,立即發現了在cr****rs訪問授權交易服務au****in時,還會經過 Spring Cloud Gateway,而后者正在以極高的速率請求服務注冊中心 Consul。至此問題明確了,這是由于網關的緩存配置不合理,導致服務注冊中心成為了瓶頸。?案例 3:5 分鐘定位被忽視的背景壓力。在軟件開發過程中,壓力測試環境通常由多人共享,甚至開發、測試等多個團隊也會使用同一套壓測環境。DeepFlow 的一個智能汽車客戶的測試人員在壓測某服務中,發現總是有少量的 HTTP 5XX 錯誤出現,而這將直接導致一次壓測結果作廢。正當測試人員一籌莫展時,打開 DeepFlow 全景圖后馬上發現還有其他服務正在以不可忽視的速率訪問著被測服務。
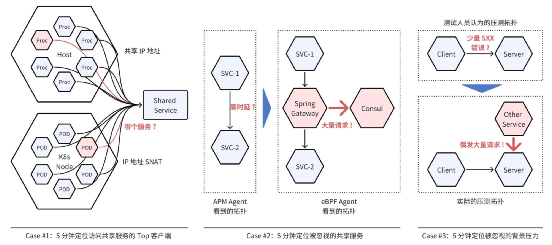
快速定位引發問題的服務
第二類案例,快速定界訪問托管服務的故障:
?案例 1:5 分鐘定界托管云服務故障- SLB 會話遷移。由于托管服務無法插樁,以往通常會給故障排查帶來困難。DeepFlow 的一個智能汽車客戶,充電業務每 10min 發生一次高時延現象。通過 APM Agent 只能定位到問題由充電核心服務訪問 RDS 導致,但公有云服務商在仔細檢查慢日志和 RDS 性能指標之后關閉了工單,因為沒有發現任何異常。這個問題持續了一周仍未解決,而通過 DeepFlow 的全棧指標數據,清晰的看到故障發生時從系統調用、Pod 網卡、Node 網卡觀測到的 RDS 訪問時延均超過了 200ms,并伴隨著網絡指標中的「服務端 RST」數量激增。這些數據使得公有云服務商重新開始排查此問題,最終發現 RDS 之前的 SLB 集群在高并發時觸發會話遷移導致了此問題。可以看到全棧可觀測性是跨團隊排查問題的關鍵。
?案例 2:5 分鐘定界托管云服務故障- K8s SNAT 沖突。這個案例中同樣也出現了 SLB,但根因大不相同。DeepFlow 的一個智能汽車客戶,車控服務在訪問賬戶服務時偶發超時,每個 Pod 每天發生 7 次。公有云服務商同樣也沒有看到任何 SLB 異常指標,此工單持續一個月仍未解決。查看 DeepFlow 全景圖之后又一次快速完成了定界,可以看到故障發生時網絡指標中的「建連異常」數量激增,進一步查看關聯的流日志發現此時 TCP 連接的失敗原因為「SNAT 端口沖突」。可以看到即使對于「沒有調用日志」的超時類故障,利用全棧性能指標也能快速定界故障原因。
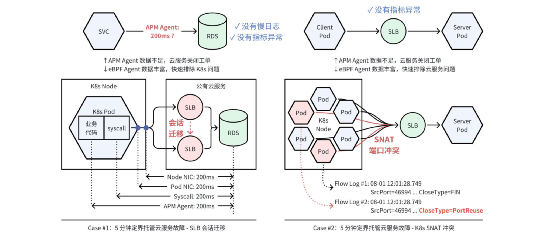
快速定界訪問托管服務的故障
第三類案例,快速定界各類網關和云基礎設施的問題:
?案例 1:5 分鐘定界造成性能瓶頸或故障的網關。為了集中實現負載均衡、安全審計、微服務拆分、限流和熔斷等功能,云原生基礎設施中通常會部署各類網關。DeepFlow 的一個游戲客戶使用 KNative 作為 Serverless 基礎設施,在該環境下任何一個客戶端在訪問微服務時,都要穿越 Envoy Ingress Gateway、K8s Service、Envoy Sidecar、Queue Sidecar 共四種網關。當客戶端側的調用時延遠高于服務端側的調用時延,或者發生 HTTP 5XX 調用故障時,以往客戶主要通過檢索日志文件、tcpdump 抓包來排查問題,而利用 DeepFlow 可以在 5 分鐘內定位網關路徑上的性能瓶頸或故障位置。例如某一次就快速發現了 Envoy Sidecar 配置不合理導致的慢請求問題。
?案例 2:5 分鐘定界私有云基礎設施性能瓶頸。DeepFlow 的一個大型銀行客戶在「分布式核心交易系統」上線私有云之前進行了大量的性能測試,期間發現 K8s 集群中的微服務訪問裸金屬服務器上的 MySQL 服務時,客戶端側的時延(3ms)與 DBA 團隊看到的時延(1ms)有較大的差距,這意味著整個過程中基礎設施的耗時占了 67%,但并不清楚具體是哪個環節引入的。通過 DeepFlow 可以看到,整個訪問過程中的主要時延消耗在 KVM 宿主機上。這些數據反饋到私有云供應商以后進行了快速的排查,發現該環境下宿主機使用了 ARM CPU 和 SRIOV 網卡,并開啟了 VXLAN Offloading,復雜的環境下一些不合理的配置導致流量轉發時延過高。通過修改配置,DeepFlow 觀測到 KVM 處的時延下降了 80%,有效的保障了整個分布式核心交易系統的順利上線。
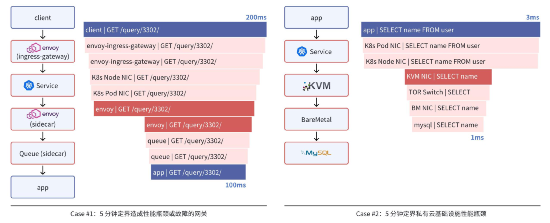
快速定界各類網關和云基礎設施的問題
第四類案例,快速定位代碼問題:
?案例 1:利用調用日志發現祖傳代碼的問題。這里的祖傳代碼指的是那些開發人員已經離職,或者接手它的開發者已經更換了好幾次,又或者是一個外部供應商提供的沒有源代碼的服務。即使客戶想通過插樁的方式提升服務的可觀測性,對此類服務也是力不從心。我們的很多客戶在部署 DeepFlow 的第一天就能立即發現此類服務的一些問題,例如一個游戲客戶發現某個游戲的 Charge API 正在報錯,雖然對玩家沒有任何影響,但卻給公司帶來著持續的經濟損失。例如一個云服務商的開發團隊發現某個服務正在寫入一個不存在的數據庫表,而這個服務的負責團隊已經更換了好幾次,它沒有造成業務的故障,但卻導致了運營數據的錯誤。
?案例 2:利用 Network Profile 發現代碼性能瓶頸。在 Linux 內核 4.9 以上的運行環境中,利用 eBPF Profile 定位代碼性能瓶頸是一個非常方便的能力。而 DeepFlow 的 Network Profile 在更普遍的內核環境下也能實現一部分效果。例如我們的一個游戲客戶在壓測 Redis 托管服務時發現壓測程序打印的時延高達 200ms,查看 DeepFlow 性能指標后顯示主機網卡上觀測到的時延只有不到 3ms。壓測人員并不是壓測程序的編寫者,壓測程序所在的服務器內核也不具備 eBPF 能力。為了弄清楚原因,壓測人員查看通過 cBPF 數據生成的 Network Profile,馬上發現了客戶端等待時延(Client Wait Time)高達 200ms。這意味著壓測程序在兩次調用的間隙中花費了太多的時間,這個信息反饋給壓測程序的開發團隊時對方非常驚喜,立即進行了優化并取得了立桿建議的效果。
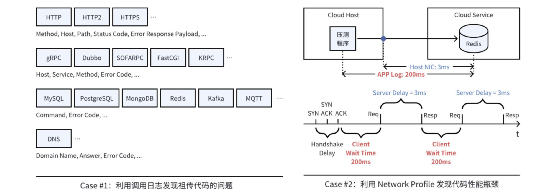
快速定位代碼問題
本章節介紹的所有案例均為 DeepFlow 客戶實際工作中的真實案例,希望能讓你更真實的感受 eBPF 技術對可觀測性的重要性。
06: 使用 eBPF 技術前的常見疑問
問題一,eBPF Agent 能在多大程度上替代 APM Agent?如果我們僅考慮分布式追蹤目的,即使存在跨線程和異步調用,也可在 Wasm Plugin 的加持下,充分利用金融、電信、游戲等典型業務的請求頭中的唯一 ID 字段完成追蹤,同時 Wasm Plugin 也可用于業務語義的提取,因此使用 eBPF Agent 可完全替代 APM Agent。對于追蹤應用內部函數之間調用路徑的需求,一般聚焦在對微服務框架、RPC 框架、ORM 框架的追蹤,由于這類函數相對標準,我們相信未來可實現基于 Wasm plugin 驅動的 eBPF 動態 Hook,以獲取程序內部的 Span 數據。
問題二,eBPF Agent 對內核的要求很高嗎?DeepFlow Agent 中超過一半的能力基于內核 2.6+ 的 cBPF 即可實現,當內核達到 4.9+ 時可支持函數性能剖析功能,當內核達到 4.14+ 時可支持 eBPF AutoTracing 以及 SSL/TLS 加密數據采集功能。另外在 Wasm Plugin 的加持下,AutoTracing 并不是強依賴 4.14+ 內核的,通過提取請求中現有的唯一 ID 字段可以在任何 2.6+ 的內核上實現 AutoTracing。
問題三,采集全棧數據是否會占用大量的存儲空間?四層網關不會改變一個調用的內容,七層網關一般只會修改一個調用的協議頭。因此網絡流量中采集到的調用日志可以非常簡單,僅包含少部分關聯信息和時間戳信息即可,無需保留詳細的請求和響應字段。這樣計算下來,網絡轉發路徑上采集到的 Span 只會增加很小的存儲負擔。
問題四,eBPF 能用于實現 RUM 嗎?eBPF 并不是一項瀏覽器上的技術,因此不適用于 Web 側。eBPF 是一項主機范圍的數據采集技術,因此不適合運行在個人移動設備上采集所有 APP 的數據。但對于由企業完全控制的終端系統來講,eBPF 是有著廣泛的應用場景的,例如基于 Linux 或 Andriod 操作系統的 IoT 終端、智能汽車的車載娛樂系統等。
07: eBPF 對新技術迭代的重大意義
以往 APM Agent 無法實現基礎設施的可觀測性,使得用戶會傾向于追求基礎設施的穩定和低頻變更,但這必然會導致創新被抑制。因此,基于 eBPF 實現可觀測性對新技術的迭代發展有著重大意義。各行各業的創新正在解決業務面臨的痛點,人們看到收益之后也會加快對創新的采納速度,零侵擾的可觀測性是對創新速度的有力保障。
云原生基礎設施的持續創新:以網關為例,云原生環境下微服務接入的網關數量可能會令你大吃一驚,下面這張漫畫非常形象的表達了這個現狀。這些網關正在解決著業務上遇到的實際問題,負載均衡器避免了單點故障;API 網關保障了 API 暴露的安全性;微服務網關讓同一個業務系統中的前端可以很方便的訪問到后端的任意一個微服務;Service Mesh 提供了限流、熔斷、路由能力,減少了業務開發的重復工作。縱使不同的網關可能存在能力的交疊,這也是技術發展過程中不可避免的中間態。另外,不同的網關往往由不同的團隊負責管理,且管理人員通常沒有二次開發能力。若無法實現網關的零侵擾可觀測性,對故障排查會帶來災難性的后果。

微服務接入的各種網關,來自 theburningmonk@twitter
金融核心交易系統的分布式改造:以往金融業務的核心交易系統是由專用硬件來承載的,不易于擴展迭代且價格昂貴。DeepFlow 的銀行、證券、保險客戶近兩年紛紛開啟了核心交易系統的分布式改造,這些系統關系著國計民生,零侵擾的可觀測性正是保障這類系統順利上線的前提。
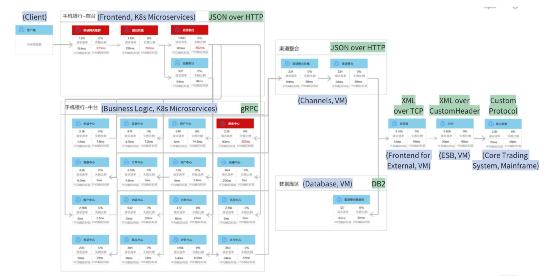
一個手機銀行業務的服務拓撲
電信核心網面向服務的架構改造:與金融類似的是,電信核心網以往也是由專用硬件來承載的。然而從 5G 核心網開始,3GPP 已經明確的提出了面向服務的架構(SBA)規范,核心網網元已經拆分為一系列微服務運行在了 K8s 容器環境中。同樣,零侵擾的可觀測性也是保障電信核心業務系統順利上線的前提。
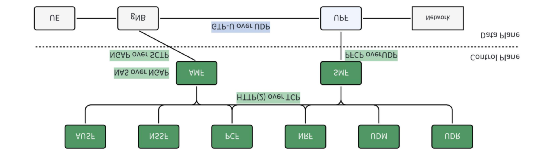
5G 核心網網元及其通信協議,控制面每個網元都采用 SBA 架構
智能網聯汽車的發展:智能汽車網絡由中心云、邊緣云(工廠/園區)、終端(車載系統)組成。為了給用戶帶來持續更新的軟件體驗,整個智能汽車網絡中的服務均采用微服務架構、云原生部署。一個具備可觀測性的基礎設施同樣也是這張大網持續迭代的前提。
智能網聯汽車
對 AIOps 發展的重要意義:以往,AIOps 方案落地之前,觀測數據(通常是指標和日志)需要進行集中和清洗。這是一個漫長的過程,通常耗時數月都難以完成。eBPF 有望對這一現狀進行根本上的改變,由于 eBPF 采集的數據覆蓋了所有服務、具有高度一致的標簽信息和數據格式,將會極大降低 AIOps 解決方案的落地門檻。
08: 總結
APM Agent 由于其侵擾性,難以在金融、電信、電力等行業的核心業務系統中落地,難以在云原生基礎設施中插樁。eBPF 的零侵擾優勢很好的解決了這些痛點,是云原生時代實現可觀測性的關鍵技術。DeepFlow 基于 eBPF 的全景圖、分布式追蹤、持續性能剖析能力已服務于各行各業,幫助金融行業的分布式核心交易系統、電信行業的 5G 核心網、能源行業的分布式電力交易系統、智能網聯汽車、云原生游戲服務等快速實現了零侵擾的可觀測性,保障了新一代業務和基礎設施的持續創新。
審核編輯:湯梓紅
-
JAVA
+關注
關注
19文章
2966瀏覽量
104702 -
代碼
+關注
關注
30文章
4779瀏覽量
68521 -
APM
+關注
關注
1文章
71瀏覽量
13008 -
SDK
+關注
關注
3文章
1035瀏覽量
45900 -
云原生
+關注
關注
0文章
248瀏覽量
7947
原文標題:圖文詳解 | 為什么說eBPF是實現可觀測性的關鍵技術?
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于 eBPF 安全可觀測性,你需要知道的那些事兒
基于拓撲分割的網絡可觀測性分析方法
如何將可觀測性策略與APM工具結合起來
介紹eBPF針對可觀測場景的應用

六大頂級、開源的數據可觀測性工具
基調聽云攜手道客打造云原生智能可觀測性平臺聯合解決方案
華為云應用運維管理平臺獲評中國信通院可觀測性評估先進級
企業應用可觀測性利器!華為云 CodeArts?APM 發布
如何構建APISIX基于DeepFlow的統一可觀測性能力呢?
華為云發布全棧可觀測平臺 AOM,以 AI 賦能應用運維可觀測

【質量視角】可觀測性背景下的質量保障思路
破局新生丨基調聽云可觀測性與應用安全技術研討會在平潭圓滿舉辦






 工商網監
工商網監
評論