 KW36 MCU HardFault問題查找和破解方法
KW36 MCU HardFault問題查找和破解方法
一、HardFault產生原因和常規分析方法
在嵌入式開發中,偶爾會遇到Hard Fault死機的異常,常見產生Hard Fault的原因大致有以下幾類:
數組越界和內存溢出,譬如訪問數組時,動態訪問的數組標號超過數組長度或者動態分配內存太小等;
堆棧溢出,例如在使用中,局部變量分配過大,超過棧大小,也會導致程序跑飛;
在外設時鐘開啟前,訪問對應外設寄存器,例如Kinetis中未打開外設時鐘去配置外設的寄存器;
不當的用法操作,例如非對齊的數據訪問、除0操作(默認情況下M3/M4/M7,除0默認都不會觸發Fault,因為ARM內核CCR寄存器DIV_0_TRP位復位值為0,而對M0來說DIV_0_TRP位是reserved的,也不會產生Fault錯誤)、強行訪問受保護的內存區域等;
出現Hardfault錯誤時,問題比較難定位的原因在于此時代碼無法像正常運行時一樣,在debug IDE的stack callback窗口能直接找到出錯時上一級的調用函數,所以顯得無從下手。通常情況下我們都是通過在某個區間打斷點,然后通過單步執行去逐步縮小“包圍圈”去找到產生Hard Fault的代碼位置,接著再去推敲、猜測問題的原因。對于不是很復雜的程序,這種方法是有效的,但是當用戶代碼量進一步增大,再用這種單步+斷點去逐步縮小包圍圈的方式就很難查到問題點,效率也很低。尤其是在有操作系統的應用中,很多代碼的跳轉是由操作系統調度的,不是嚴格的順序執行,所以很難依靠縮小包圍圈的方式去有效找到問題產生的點,進一步增加了定位到Hard Fault觸發原因的難度。
盡管本測試是針對NXP KW36芯片的,但該步驟和方法也適用于其他的Arm Cortex-M內核MCU;
二、HardFault解決方法分析
筆者在實際支持客戶過程中也遇到這種困惑,網上的介紹資料比較零散,理論很多,很少詳細描述實戰操作的步驟,借助同事的點撥,摸索出兩種定位Hard Fault問題的方法,在實際使用中操作性也很強,此處分別做一介紹。
第一種:心里明白徒手分析法,就是在了解Hard Fault出錯原理以及程序調用壓棧出棧原理的基礎上(當然按照本文的練就心法,心里不明白也可以),在Debug仿真模式下徒手去回溯分析CPU通用寄存器(LR/MSP/PSP/PC),然后結合調試IDE去定位到產生Hard Fault的代碼位置;
第二種:CmBacktrace 天龍大法,該方法是朱天龍大神針對 ARM Cortex-M系列MCU開發的一套錯誤代碼自動追蹤、定位、錯誤原因自動分析的開源庫,已開源在Github上,該方法支持在非Debug模式下,自動分析定位到出錯的行號,無需了解復雜的壓棧出棧過程。
兩者的區別在于:前者不需要額外添加代碼,缺點是只能在仿真狀態下調試,需要用戶對程序調用壓棧/出棧原理有清晰的理解,后者的唯一的缺點是需要適當添加代碼,并稍微配置工程和打印輸出,優點就太多了。首先,產品真機調試時可以斷開仿真器,并將錯誤信息輸出到控制臺上,甚至可以將錯誤信息使用 Easy Flash 的 Log 功能保存至 Flash 中,待設備死機后重啟依然能夠讀取上次的錯誤信息。這個功能真的是very very重要了,尤其在有些Hard Fault問題偶發的情況下,很多時候一天可能也復現不了一次問題,但借助CmBacktrace 天龍大法便可以輕松脫離仿真器get每一次錯誤,最后再配合 addr2line 工具進行精確定位出錯代碼的行號,方便用戶進行后續的精確分析。
三、HardFault回溯的原理
為了找到Hard Fault 的原因和觸發的代碼段,就需要深刻理解當系統產生異常時 MCU 的處理過程: 當處理器接收一個異常后,芯片硬件會自動將8個通用寄存器組中壓入當前棧空間里(依次為 xPSR、PC、LR、R12以及 R3~R0),如果異常發生時,當前的代碼正在使用PSP,則上面8個寄存器壓入PSP,否則就壓入MSP。那問題來了,如何找到這個棧空間的地址呢?答案是SP, 但是前面提到壓棧時會有MSP和PSP,如何判斷觸發異常時使用的MSP還是PSP呢?答案是LR。到此確定完SP后,用戶便可以通過堆棧找到觸發異常的PC 值,并與反匯編的代碼對比就能得到哪條指令產生了異常。
總結下來,總體思路就是:首先通過LR判斷出異常產生時當前使用的SP是MSP還是PSP,接著通過SP去得到產生異常時保存的PC值,最后與反匯編的代碼對比就能得到哪條指令產生了異常。
回到前面的第二個問題,如何通過LR判斷當前使用的MSP還是PSP呢?參見如下圖,當異常產生時,LR 會被更新為異常返回時需要使用的特殊值(EXC_RETURN),其定義如下,其高 28 位置 1,第 0 位到第3位則提供了異常返回機制所需的信息,可見其中第 2 位標示著進入異常前使用的棧是 MSP還是PSP。

四、操作分析流程:
理解了以上的Hard Fault回溯的原理,下面按以上提到的兩種思路來實操一下。
1、心里明白徒手分析法
前面提到,為了清晰的展現這個過程以及每個參數之間的關系,盡量把整個流程按照順序整理到一張圖中,如下圖1。示例中使用的是KW36 temp_sensor_freeRTOS例子(什么例子不重要,該方法也適用于其他的MCU系列),在main函數中通過非對齊地址訪問故意制造Hard Fault錯誤,代碼如圖中序號1,當程序試圖訪問讀取非對齊地址0xCCCC CCCC位置時程序就會跳入到Hard Fault Handler中,那具體是如何通過堆棧分析定位到出錯代碼是在n=*p這一行呢?具體步驟如下:
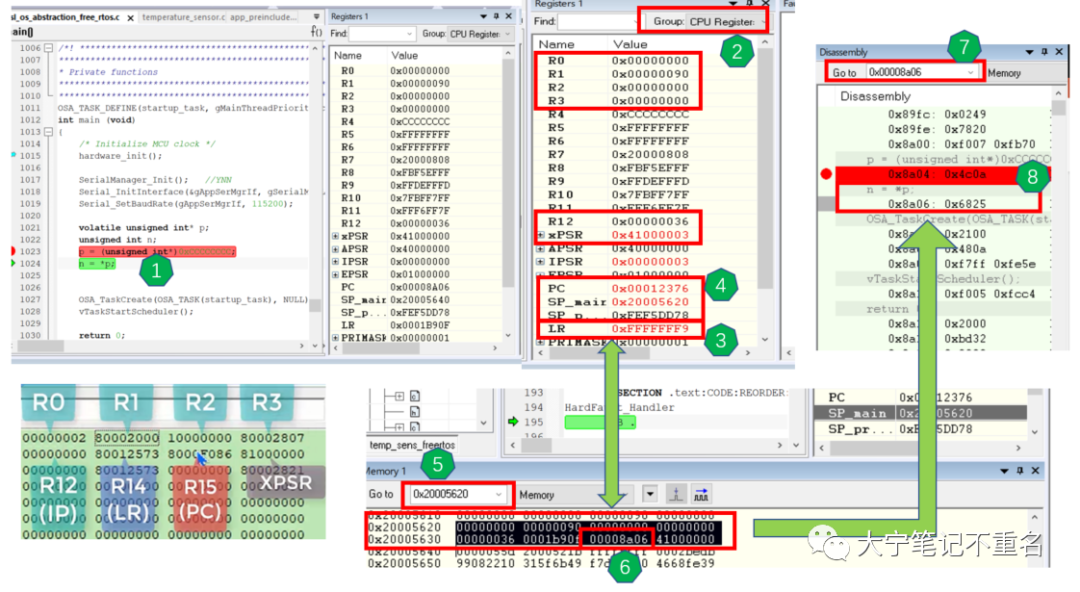
Step1:判斷SP是MSP還是PSP,找出SP地址。在產生Hard Fault異常后,首先在序號2中選擇“ CPU register”,不要使用默認的 “CPU register ”,否則默認只會顯示MSP,不會顯示PSP。然后查看序號3中LR寄存器的值表示判斷當前程序使用堆棧為MSP主進程或PSP子進程堆棧,顯然LR=0xFFFFFFF9 的bit2=0,表示使用的是主棧,于是得到SP=序號4中的SP_main=0x20005620;
Step2:找出PC地址。如序號5演示,打開memory串口,輸入SP的地址可以找到異常產生前壓棧的8個寄存器,依次為 xPSR、PC、LR、R12以及 R3~R0,序號6中便可以找到出錯前PC的地址位0x00008a06;
Step3:找出代碼行數。如序號7演示,打開匯編窗口,在“go to”串口輸入PC地址,便可以找到具體出錯時代碼的位置,如序號8演示,可以發現,輕松愉快的找到了導致Hard Fault的非對齊訪問的代碼行;
2、CmBacktrace 天龍大法
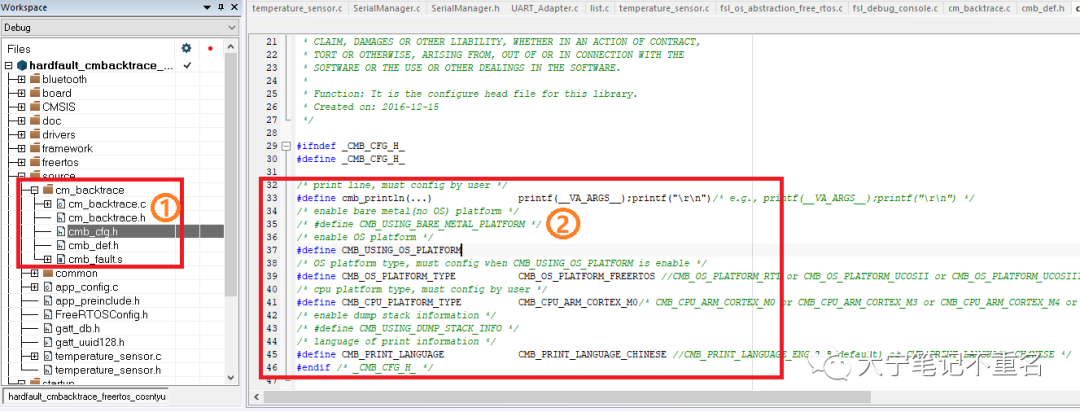
Step1: 從天龍大神的Github下載CmBacktrace的源代碼包,拷貝cm_backtrace目錄下的4個文件以及cmb_fault.s文件到KW36 IAR工程中,如下圖序號2標識,并添加相應的搜索路徑;
Step2: 根據應用修改cmb_cfg.h的配置,需要配置的選項包括print打印信息的重定義,是否需要支持OS,OS的類型(RTT、uCOS以及FreeRTOS),ARM內核的類型,打印輸出語言類型等;本實例中使用了錯誤信息中文打印以及FreeRTOS,所以配置如下圖序號2標識。
Step3: 修改FreeRTOS的task.c文件增加以下3個函數,否則在編譯時會報錯提示這3個函數無定義。最簡單的做法就是直接使用CmBacktrace源代碼包的task.c替代KW36 SDK中的task.c文件。

Step4: 在啟動FreeRTOS啟動任務調度前初始化CmBacktrace庫以及配置信息,并在startup子任務中編寫故意制造錯誤的代碼,代碼如下。

Step5: 配置打印信息的輸出位置,建議的做法是輸出到物理串口,可以方便的離線分析記錄log, 但實驗中為了簡化以及通用(有些時候硬件設計上可能沒有留硬件串口),直接把打印信息輸出到IAR的Terminal IO進行顯示(Kinetis SDK如何修改代碼,使能打印信息輸出到IAR的Terminal IO的做法詳見另外一篇文檔)。
Step6: 運行代碼,觀察打印結果,可以看到打印信息中包含出錯的任務名稱、出錯前的任務壓棧的8個通用寄存器名稱和內容,從圖中可以一目了然的找出出錯的PC指針,如果進一步去結合匯編代碼可以清晰的看到其能夠準確定位到代碼出錯的位置。
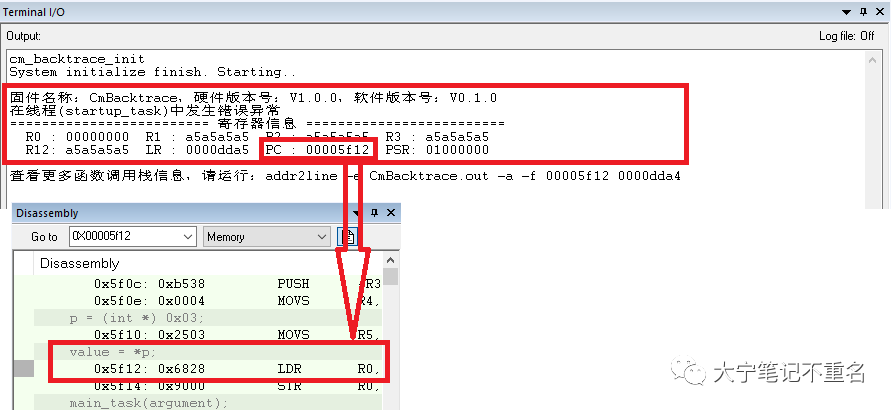
Step7: 盡管在Step6中結合匯編找到了出錯的代碼行,但是前面吹過的一個牛逼還未實現,就是使用CmBacktrace 可以支持不掛仿真器debug狀態下找到出錯的代碼行,那具體如何操作呢?答案其實在Step 5的打印信息中已經揭曉“查看更多函數調用棧信息,請運行:addr2line -e CmBacktrace.out -a -f 00005f12 0000dda4 ”。
于是拷貝工程的.out文件到toolsaddr2linewin64目錄下,在cmd命令行中執行以上命令,結果如下圖的上半部分,可以看到出錯的任務是startup_task,出錯的文件是fsl_os_abstraction_free_rtos.c,出錯行號是135。結合截圖的下半部分的代碼去看,完全驗證了這三個點。
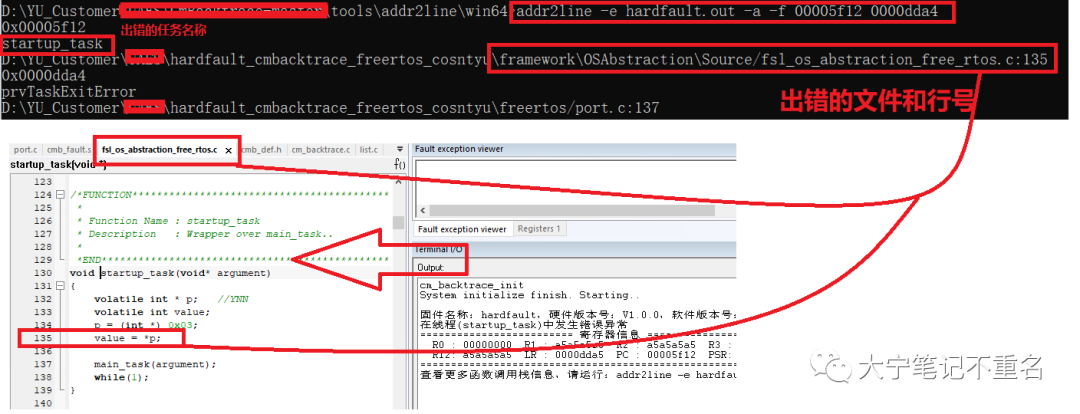
到此,使用CmBacktrace大法不輕松但很愉悅的定位到問題點了。
五、總結:
對于Hard Fault問題,通過以上兩種辦方法可以有效的找到問題點,為后續進一步分析定位問題指明方向。徒手分析法比較簡單,不需要額外添加代碼,缺點是只能在仿真狀態下調試,需要用戶對程序調用壓棧/出棧原理有清晰的理解。CmBacktrace 天龍大法則支持離線調試分析,但繁瑣點在于需要移植代碼,并配置工程和打印輸出,尤其在Hard Fault問題偶發(很多時候一天可能也復現不了一次問題)以及只有離線狀態下才能復現問題的情況下,使用CmBacktrace 的方法去定位問題是非常高效的。至于如何將錯誤信息使用 Easy Flash 的 Log 功能保存至 Flash 中,待設備死機后重啟依然能夠讀取上次的錯誤信息部分,時間關系筆者沒有深入研究,有興趣的可以嘗試實現。
來源:大寧筆記不重名(作者:Const Yu)
審核編輯:湯梓紅
-
mcu
+關注
關注
146文章
17129瀏覽量
351007 -
NXP
+關注
關注
60文章
1278瀏覽量
184062 -
內核
+關注
關注
3文章
1372瀏覽量
40281 -
嵌入式開發
+關注
關注
18文章
1028瀏覽量
47564
發布評論請先 登錄
相關推薦
轉:淺談MCU破解技術
【轉載】快速追蹤和定位產生HardFault原因的方法
使用kw36作為外圍連接另一個設備時,FRDM kw36的BLE自動斷開如何解決?
KW36如何在Vref范圍內降低adc輸入電壓?
KW36 BLE身份地址無法設置的原因?怎么處理?
KW36 jlink調試報錯怎么解決?
請問KW34/KW35/KW36和KW37/38/39是否有客戶杠桿QDID?
MRS_關于HardFault問題查找思路
簡單的MCU加密方法,防破解、防抄襲、防山寨

S32K1XX調試--快速定位HardFault
嵌入式軟件程序HardFault異常的查找方法
怎么查找STM32的硬件錯誤HardFault_Handler?
AT32講堂009 | 基于CmBacktrace庫,如何快速追蹤和定位產生HardFault的原因






 工商網監
工商網監
評論