") 為什么重采樣很重要?Pandas中重新采樣的關(guān)鍵問題解析
為什么重采樣很重要?Pandas中重新采樣的關(guān)鍵問題解析
重采樣是時(shí)間序列分析中處理時(shí)序數(shù)據(jù)的一項(xiàng)基本技術(shù)。它是關(guān)于將時(shí)間序列數(shù)據(jù)從一個(gè)頻率轉(zhuǎn)換到另一個(gè)頻率,它可以更改數(shù)據(jù)的時(shí)間間隔,通過上采樣增加粒度,或通過下采樣減少粒度。在本文中,我們將深入研究Pandas中重新采樣的關(guān)鍵問題。
為什么重采樣很重要?
時(shí)間序列數(shù)據(jù)到達(dá)時(shí)通常帶有可能與所需的分析間隔不匹配的時(shí)間戳。例如以不規(guī)則的間隔收集數(shù)據(jù),但需要以一致的頻率進(jìn)行建模或分析。
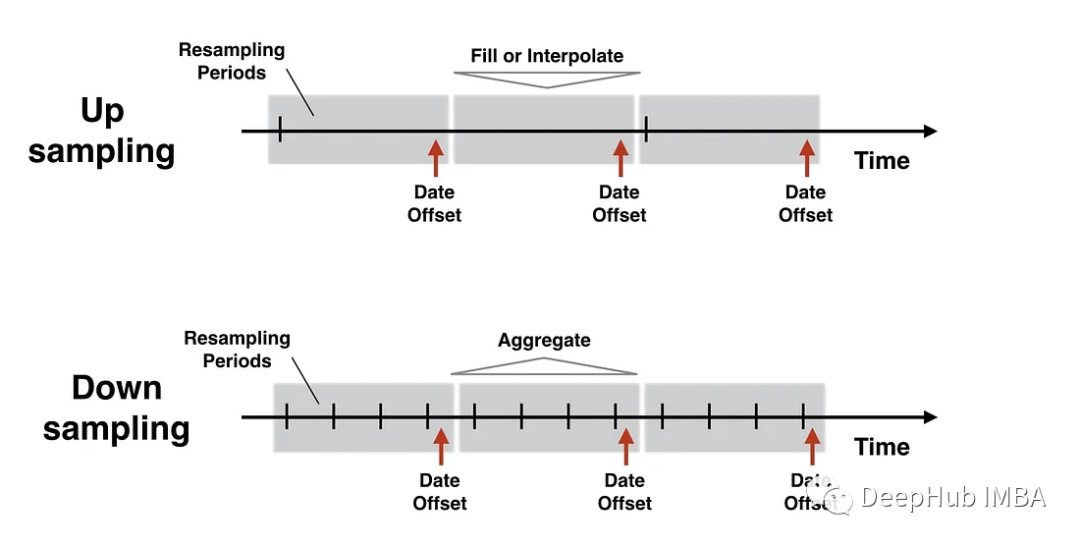
重采樣分類
重采樣主要有兩種類型:
1、Upsampling
上采樣可以增加數(shù)據(jù)的頻率或粒度。這意味著將數(shù)據(jù)轉(zhuǎn)換成更小的時(shí)間間隔。
2、Downsampling
下采樣包括減少數(shù)據(jù)的頻率或粒度。將數(shù)據(jù)轉(zhuǎn)換為更大的時(shí)間間隔。

重采樣的應(yīng)用
重采樣的應(yīng)用十分廣泛:
在財(cái)務(wù)分析中,股票價(jià)格或其他財(cái)務(wù)指標(biāo)可能以不規(guī)則的間隔記錄。重新可以將這些數(shù)據(jù)與交易策略的時(shí)間框架(如每日或每周)保持一致。
物聯(lián)網(wǎng)(IoT)設(shè)備通常以不同的頻率生成數(shù)據(jù)。重新采樣可以標(biāo)準(zhǔn)化分析數(shù)據(jù),確保一致的時(shí)間間隔。
在創(chuàng)建時(shí)間序列可視化時(shí),通常需要以不同的頻率顯示數(shù)據(jù)。重新采樣夠調(diào)整繪圖中的細(xì)節(jié)水平。
許多機(jī)器學(xué)習(xí)模型都需要具有一致時(shí)間間隔的數(shù)據(jù)。在為模型訓(xùn)練準(zhǔn)備時(shí)間序列數(shù)據(jù)時(shí),重采樣是必不可少的。
重采樣過程
重采樣過程通常包括以下步驟:
首先選擇要重新采樣的時(shí)間序列數(shù)據(jù)。該數(shù)據(jù)可以采用各種格式,包括數(shù)值、文本或分類數(shù)據(jù)。
確定您希望重新采樣數(shù)據(jù)的頻率。這可以是增加粒度(上采樣)或減少粒度(下采樣)。
選擇重新采樣方法。常用的方法包括平均、求和或使用插值技術(shù)來填補(bǔ)數(shù)據(jù)中的空白。
在上采樣時(shí),可能會(huì)遇到原始時(shí)間戳之間缺少數(shù)據(jù)點(diǎn)的情況。插值方法,如線性或三次樣條插值,可以用來估計(jì)這些值。
對(duì)于下采樣,通常會(huì)在每個(gè)目標(biāo)區(qū)間內(nèi)聚合數(shù)據(jù)點(diǎn)。常見的聚合函數(shù)包括sum、mean或median。
評(píng)估重采樣的數(shù)據(jù),以確保它符合分析目標(biāo)。檢查數(shù)據(jù)的一致性、完整性和準(zhǔn)確性。
Pandas中的resample()方法
resample可以同時(shí)操作Pandas Series和DataFrame對(duì)象。它用于執(zhí)行聚合、轉(zhuǎn)換或時(shí)間序列數(shù)據(jù)的下采樣和上采樣等操作。
下面是
resample()
方法的基本用法和一些常見的參數(shù):
import pandas as pd
# 創(chuàng)建一個(gè)示例時(shí)間序列數(shù)據(jù)框
data = {'date': pd.date_range(start='2023-01-01', end='2023-12-31', freq='D'),
'value': range(365)}
df = pd.DataFrame(data)
# 將日期列設(shè)置為索引
df.set_index('date', inplace=True)
# 使用resample()方法進(jìn)行重新采樣
# 將每日數(shù)據(jù)轉(zhuǎn)換為每月數(shù)據(jù)并計(jì)算每月的總和
monthly_data = df['value'].resample('M').sum()
# 將每月數(shù)據(jù)轉(zhuǎn)換為每季度數(shù)據(jù)并計(jì)算每季度的平均值
quarterly_data = monthly_data.resample('Q').mean()
# 將每季度數(shù)據(jù)轉(zhuǎn)換為每年數(shù)據(jù)并計(jì)算每年的最大值
annual_data = quarterly_data.resample('Y').max()
print(monthly_data)
print(quarterly_data)
print(annual_data)
在上述示例中,我們首先創(chuàng)建了一個(gè)示例的時(shí)間序列數(shù)據(jù)框,并使用
resample()
方法將其轉(zhuǎn)換為不同的時(shí)間頻率(每月、每季度、每年)并應(yīng)用不同的聚合函數(shù)(總和、平均值、最大值)。
resample()
方法的參數(shù):
- 第一個(gè)參數(shù)是時(shí)間頻率字符串,用于指定重新采樣的目標(biāo)頻率。常見的選項(xiàng)包括
'D'(每日)、'M'(每月)、'Q'(每季度)、'Y'(每年)等。 - 你可以通過第二個(gè)參數(shù)
how來指定聚合函數(shù),例如'sum'、'mean'、'max'等,默認(rèn)是'mean'。 - 你還可以使用
closed參數(shù)來指定每個(gè)區(qū)間的閉合端點(diǎn),可選的值包括'right'、'left'、'both'、'neither',默認(rèn)是'right'。 - 使用
label參數(shù)來指定重新采樣后的標(biāo)簽使用哪個(gè)時(shí)間戳,可選的值包括'right'、'left'、'both'、'neither',默認(rèn)是'right'。 - 可以使用
loffset參數(shù)來調(diào)整重新采樣后的時(shí)間標(biāo)簽的偏移量。 - 最后,你可以使用聚合函數(shù)的特定參數(shù),例如
'sum'函數(shù)的min_count參數(shù)來指定非NA值的最小數(shù)量。
1、指定列名
默認(rèn)情況下,Pandas的resample()方法使用Dataframe或Series的索引,這些索引應(yīng)該是時(shí)間類型。但是,如果希望基于特定列重新采樣,則可以使用on參數(shù)。這允許您選擇一個(gè)特定的列進(jìn)行重新采樣,即使它不是索引。
df.reset_index(drop=False, inplace=True)
df.resample('W', on='index')['C_0'].sum().head()
在這段代碼中,使用resample()方法對(duì)'index'列執(zhí)行每周重采樣,計(jì)算每周'C_0'列的和。
2、指定開始和結(jié)束的時(shí)間間隔
closed參數(shù)允許重采樣期間控制打開和關(guān)閉間隔。默認(rèn)情況下,一些頻率,如'M', 'A', 'Q', 'BM', 'BA', 'BQ'和'W'是右閉的,這意味著包括右邊界,而其他頻率是左閉的,其中包括左邊界。在轉(zhuǎn)換數(shù)據(jù)頻率時(shí),可以根據(jù)需要手動(dòng)設(shè)置關(guān)閉間隔。
df = generate_sample_data_datetime()
pd.concat([df.resample('W', closed='left')['C_0'].sum().to_frame(name='left_closed'),
df.resample('W', closed='right')['C_0'].sum().to_frame(name='right_closed')],
axis=1).head(5)
在這段代碼中,我們演示了將日頻率轉(zhuǎn)換為周頻率時(shí)左閉間隔和右閉間隔的區(qū)別。
3、輸出結(jié)果控制
label參數(shù)可以在重采樣期間控制輸出結(jié)果的標(biāo)簽。默認(rèn)情況下,一些頻率使用組內(nèi)的右邊界作為輸出標(biāo)簽,而其他頻率使用左邊界。在轉(zhuǎn)換數(shù)據(jù)頻率時(shí),可以指定是要使用左邊界還是右邊界作為輸出標(biāo)簽。
df = generate_sample_data_datetime()
df.resample('W', label='left')['C_0'].sum().to_frame(name='left_boundary').head(5)
df.resample('W', label='right')['C_0'].sum().to_frame(name='right_boundary').head(5)
在這段代碼中,輸出標(biāo)簽是根據(jù)在label參數(shù)中指定“l(fā)eft”還是“right”而變化的,建議在實(shí)際應(yīng)用時(shí)顯式指定,這樣可以減少混淆。
4、匯總統(tǒng)計(jì)數(shù)據(jù)
重采樣可以執(zhí)行聚合統(tǒng)計(jì),類似于使用groupby。使用sum、mean、min、max等聚合方法來匯總重新采樣間隔內(nèi)的數(shù)據(jù)。這些聚合方法類似于groupby操作可用的聚合方法。
df.resample('D').sum()
df.resample('W').mean()
df.resample('M').min()
df.resample('Q').max()
df.resample('Y').count()
df.resample('W').std()
df.resample('M').var()
df.resample('D').median()
df.resample('M').quantile([0.25, 0.5, 0.75])
custom_agg = lambda x: x.max() - x.min()
df.resample('W').apply(custom_agg)
上采樣和填充
在時(shí)間序列數(shù)據(jù)分析中,上采樣和下采樣是用來操縱數(shù)據(jù)觀測(cè)頻率的技術(shù)。這些技術(shù)對(duì)于調(diào)整時(shí)間序列數(shù)據(jù)的粒度以匹配分析需求非常有價(jià)值。
我們先生成一些數(shù)據(jù)
import pandas as pd
import numpy as np
def generate_sample_data_datetime():
np.random.seed(123)
number_of_rows = 365 * 2
num_cols = 5
start_date = '2023-09-15' # You can change the start date if needed
cols = ["C_0", "C_1", "C_2", "C_3", "C_4"]
df = pd.DataFrame(np.random.randint(1, 100, size=(number_of_rows, num_cols)), columns=cols)
df.index = pd.date_range(start=start_date, periods=number_of_rows)
return df
df = generate_sample_data_datetime()
上采樣包括增加數(shù)據(jù)的粒度,這意味著將數(shù)據(jù)從較低的頻率轉(zhuǎn)換為較高的頻率。
假設(shè)您有上面生成的每日數(shù)據(jù),并希望將其轉(zhuǎn)換為12小時(shí)的頻率,并在每個(gè)間隔內(nèi)計(jì)算“C_0”的總和:
df.resample('12H')['C_0'].sum().head(10)
代碼將數(shù)據(jù)重采樣為12小時(shí)的間隔,并在每個(gè)間隔內(nèi)對(duì)' C_0 '應(yīng)用總和聚合。這個(gè).head(10)用于顯示結(jié)果的前10行。
在上采樣過程中,特別是從較低頻率轉(zhuǎn)換到較高頻率時(shí),由于新頻率引入了間隙,會(huì)遇到丟失數(shù)據(jù)點(diǎn)的情況。所以需要對(duì)間隙的數(shù)據(jù)進(jìn)行填充,填充一般使用以下幾個(gè)方法:
向前填充-前一個(gè)可用的值填充缺失的值。可以使用limit參數(shù)限制正向填充的數(shù)量。
df.resample('8H')['C_0'].ffill(limit=1)
反向填充 -用下一個(gè)可用的值填充缺失的值。
df.resample('8H')['C_0'].bfill(limit=1)
最近填充 -用最近的可用值填充缺失的數(shù)據(jù),該值可以是向前的,也可以是向后的。
df.resample('8H')['C_0'].nearest(limit=1)
Fillna —結(jié)合了前面三個(gè)方法的功能。可以指定方法(例如,'pad'/' fill', 'bfill', 'nearest'),并使用limit參數(shù)進(jìn)行數(shù)量控制。
df.resample('8H')['C_0'].fillna(method='pad', limit=1)
Asfreq-指定一個(gè)固定的值來填充所有缺失的部分一次。例如,可以使用-999填充缺失的值。
df.resample('8H')['C_0'].asfreq(-999)
插值方法-可以應(yīng)用各種插值算法。
df.resample('8H').interpolate(method='linear').applymap(lambda x: round(x, 2))
一些常用的函數(shù)
1、使用agg進(jìn)行聚合
result = df.resample('W').agg(
{
'C_0': ['sum', 'mean'],
'C_1': lambda x: np.std(x, ddof=1)
}
).head()
使用agg方法將每日時(shí)間序列數(shù)據(jù)重新采樣到每周頻率。并為不同的列指定不同的聚合函數(shù)。對(duì)于“C_0”,計(jì)算總和和平均值,而對(duì)于“C_1”,計(jì)算標(biāo)準(zhǔn)差。
2、使用 apply 聚合
def custom_agg(x):
agg_result = {
'C_0_mean': round(x['C_0'].mean(), 2),
'C_1_sum': x['C_1'].sum(),
'C_2_max': x['C_2'].max(),
'C_3_mean_plus1': round(x['C_3'].mean() + 1, 2)
}
return pd.Series(agg_result)
result = df.resample('W').apply(custom_agg).head()
定義了一個(gè)名為custom_agg的自定義聚合函數(shù),它將DataFrame x作為輸入,并在不同列上計(jì)算各種聚合。使用apply方法將數(shù)據(jù)重新采樣到每周的頻率,并應(yīng)用自定義聚合函數(shù)。
3、使用transform進(jìn)行變換
df['C_0_cumsum'] = df.resample('W')['C_0'].transform('cumsum')
df['C_0_rank'] = df.resample('W')['C_0'].transform('rank')
result = df.head(10)
使用transform 方法來計(jì)算每周組中'C_0'變量的累積和排名。DF的原始索引結(jié)構(gòu)保持不變。
4、使用pipe 進(jìn)行管道操作
result = df.resample('W')['C_0', 'C_1']
.pipe(lambda x: x.cumsum())
.pipe(lambda x: x['C_1'] - x['C_0'])
result = result.head(10)
使用管道方法對(duì)下采樣的'C_0'和'C_1'變量進(jìn)行鏈?zhǔn)讲僮鳌umsum函數(shù)計(jì)算累積和,第二個(gè)管道操作計(jì)算每個(gè)組的'C_1'和'C_0'之間的差值。像管道一樣執(zhí)行順序操作。
總結(jié)
時(shí)間序列的重采樣是將時(shí)間序列數(shù)據(jù)從一個(gè)時(shí)間頻率(例如每日)轉(zhuǎn)換為另一個(gè)時(shí)間頻率(例如每月或每年),并且通常伴隨著對(duì)數(shù)據(jù)進(jìn)行聚合操作。重采樣是時(shí)間序列數(shù)據(jù)處理中的一個(gè)關(guān)鍵操作,通過進(jìn)行重采樣可以更好地理解數(shù)據(jù)的趨勢(shì)和模式。
在Python中,可以使用Pandas庫的
resample()
方法來執(zhí)行時(shí)間序列的重采樣。
-
轉(zhuǎn)換器
+關(guān)注
關(guān)注
27文章
8700瀏覽量
147122 -
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2909文章
44595瀏覽量
372967 -
數(shù)據(jù)處理
+關(guān)注
關(guān)注
0文章
596瀏覽量
28560 -
python
+關(guān)注
關(guān)注
56文章
4795瀏覽量
84646 -
重采樣
+關(guān)注
關(guān)注
0文章
2瀏覽量
1095
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
labview 等角度重采樣
關(guān)于labview中xy圖中波形重采樣的問題
使用FPGA實(shí)現(xiàn)高效并行實(shí)時(shí)上采樣
什么是信號(hào)采樣率?如何更改信號(hào)的采樣率?
任意重采樣濾波器設(shè)計(jì)應(yīng)用說明

過采樣方法在動(dòng)態(tài)軸重式汽車衡中的應(yīng)用
中頻采樣是什么意思?中頻采樣與基帶采樣的區(qū)別
什么是中頻采樣?什么是IQ采樣?中頻采樣和IQ采樣的比較和轉(zhuǎn)換
PCL中基礎(chǔ)下采樣介紹






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論