") 如何在開始碼代碼的時候就考慮時序收斂的問題?
如何在開始碼代碼的時候就考慮時序收斂的問題?
引言
硬件描述語言(verilog,systemVerilog,VHDL等)不同于軟件語言(C,C++等)的一點就是,代碼對應于硬件實現(xiàn),不同的代碼風格影響硬件的實現(xiàn)效果。好的代碼風格能讓硬件“跑得更快”,而一個壞的代碼風格則給后續(xù)時序收斂造成很大負擔。你可能要花費很長時間去優(yōu)化時序,保證時序收斂。拆解你的代碼,添加寄存器,修改走線,最后讓你原來的代碼“遍體鱗傷”。這一篇基于賽靈思的器件來介紹一下如何在開始碼代碼的時候就考慮時序收斂的問題,寫出一手良好的代碼。
1. Counter結構
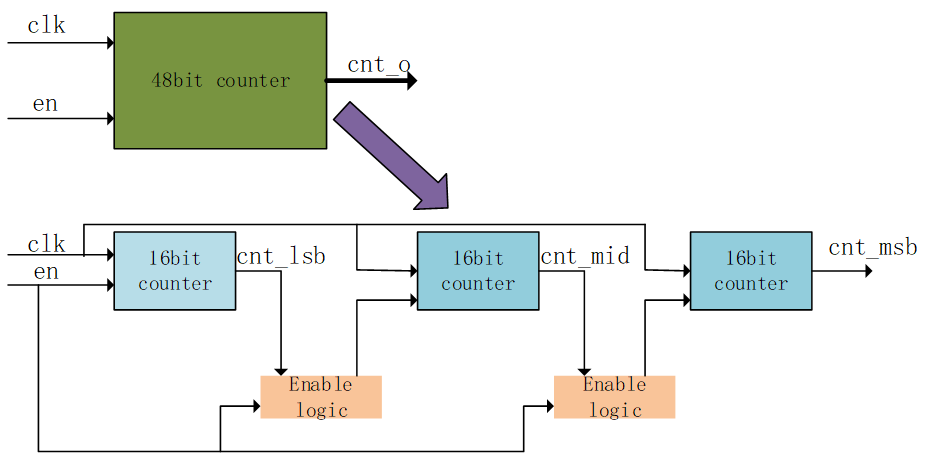
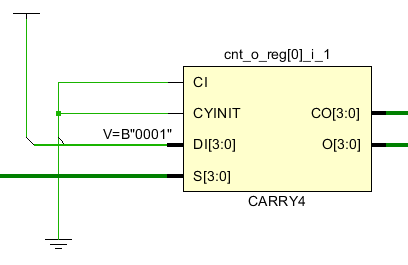
計數(shù)器是在FPGA設計中經(jīng)常要用到的結構,比如在AXI總線中對接收數(shù)據(jù)量的計算,用計數(shù)器來產(chǎn)生地址和last等信號。在計數(shù)器中需要用到進位鏈,進位鏈是影響時序的主要因素。如果進位鏈越長,那么組合邏輯的級數(shù)就越高,組合邏輯延遲越大,能夠支持的最大時鐘頻率就會越低。在一個CLB中通常會含有一個進位鏈結構,比如在ultrascale中是CARRY8,在zynq7系列中是CARRY4,CARRY4可以實現(xiàn)4bit進位。如果是一個48bit計數(shù)器就需要12個這樣的進位結構。一個CARRY4輸出有兩種CO和O,CO是進位bit,用于級聯(lián)到下一級的CARRY4的CI,O是結果輸出。因此我們可以看到在計數(shù)器中最下的進位結構是CARRY4,如果直接讓多個進位結構級聯(lián),那么組合邏輯就會變大,時序延遲就會增大。如果可以將計數(shù)器拆分成小的計數(shù)器,那么時序就可以得到改善。
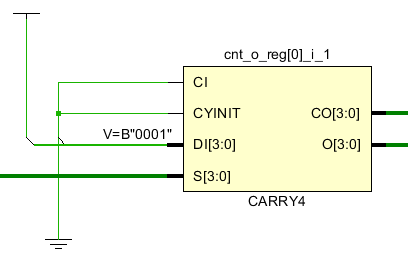
比如一個48bit計數(shù)器拆分成3個16bit計數(shù)器,那么CARRY4的級聯(lián)級別就從原來的12個降低到4個。每4個之間增加了FF來進行時序改善。
always @(posedge clk)begin
if(rst)
cnt_o <= 0;
else
cnt_o <= cnt_o + 1;
end
拆分后代碼為:
genvar i; generate for(i=0;i<3;i=i+1)begin: CNT_LOOP wire trigger_nxt, trigger_pre; if(i == 0)begin always @(posedge clk)begin if(rst) cnt_o[i*16 +: 16] <= 0; else cnt_o[i*16 +: 16] <= cnt_o[i*16 +: 16] + 1; end assign trigger_nxt = (cnt_o[i*16 +: 16] == 16'hFFFF) ? 1 : 0; end//if else begin assign trigger_pre = CNT_LOOP[i-1].trigger_nxt; always @(posedge clk)begin if(rst) cnt_o[i*16 +: 16] <= 0; else if(trigger_pre) cnt_o[i*16 +: 16] <= cnt_o[i*16 +: 16] + 1; end assign trigger_nxt = CNT_LOOP[i-1].trigger_nxt && (cnt_o[i*16 +: 16] == 16'hFFFF); end//else end//for endgenerate
綜合后我們就可以看到它的schematic每4個CARRY4都被FF隔開了,可以降低邏輯延時。但是代價是增加了LUT的數(shù)量,這些LUT是用來判斷前一個16bit計數(shù)器的數(shù)值的,從而驅(qū)動后邊16bit寄存器計數(shù)。
2. 邏輯拆分
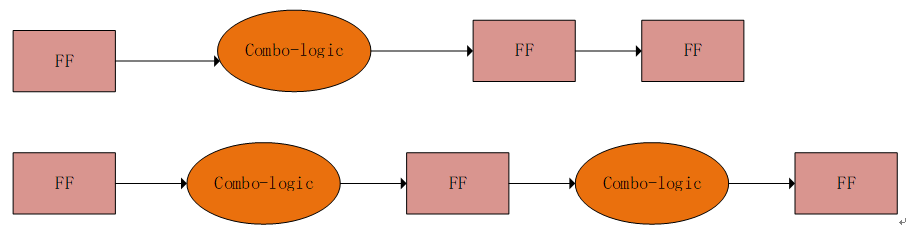
在上一節(jié)中拆解計數(shù)器本質(zhì)上就是在拆分組合邏輯。當一個組合邏輯過大的時候,延時較大。將其拆解成兩個或者兩個以上邏輯,中間增加寄存器可以來提高能跑得時鐘頻率。比如下圖有一個較大的組合邏輯,前邊有一個FF,后邊連續(xù)接2個FF。組合邏輯的延時就成為了整體時鐘頻率的一個關鍵路徑。如果我們可以將其拆分成兩個,中間用一級寄存器連接,這樣總共的時鐘周期還是3個,但是時鐘頻率明顯會好于前一種。
3. 改善扇出
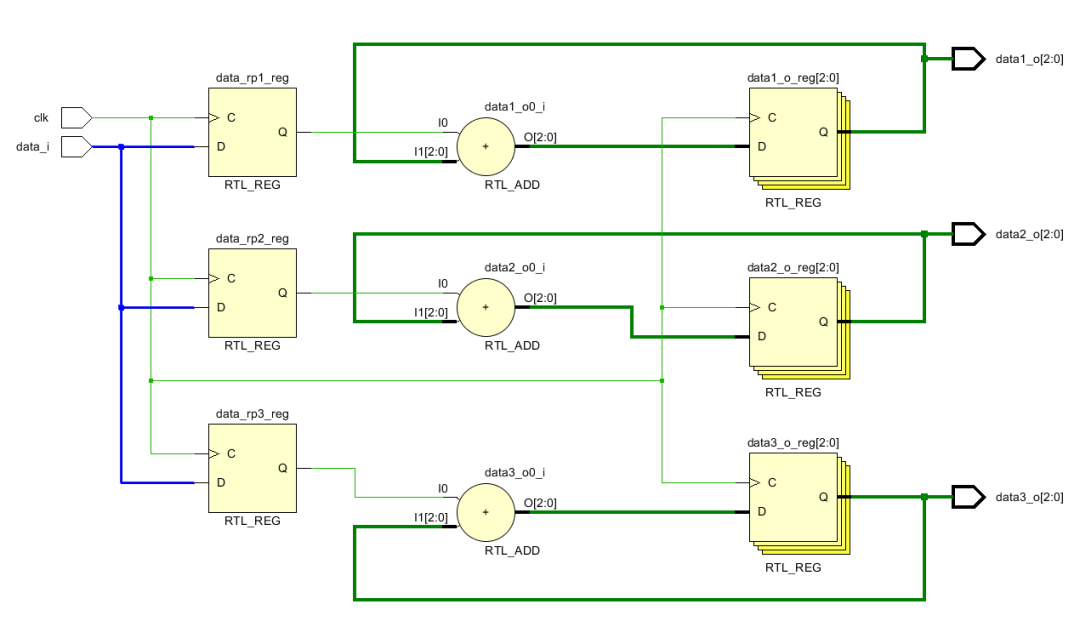
扇出是指某個信號驅(qū)動的信號的數(shù)量。驅(qū)動的信號越多,那么要求其產(chǎn)生的電流越大。學過數(shù)字電路就會知道,當一個信號輸出連接的越多的時候,其輸出負載就會越小,那么輸出電壓就會減小。所以如果信號扇出過大就會影響到高低電平,最終就會導致時序不收斂。另外一個原因是如果信號扇出過大,那么由于FPGA上走線路徑的差異,就可能造成這個信號到達不同地址的延遲不同,造成時序不同步。一種解決辦法是復制,將扇出較大的信號復制幾份,這樣就可以減小扇出。比如一個輸入d_i需要和3個數(shù)進行求和。那么這個信號扇出就是3.如果將其復制3份,給每個數(shù)輸送一份,那么扇出就變?yōu)?。
always @(posedge clk)begin
data1_o <= data_i + data1_o;
data2_o <= data_i + data2_o;
data3_o <= data_i + data3_o;
end
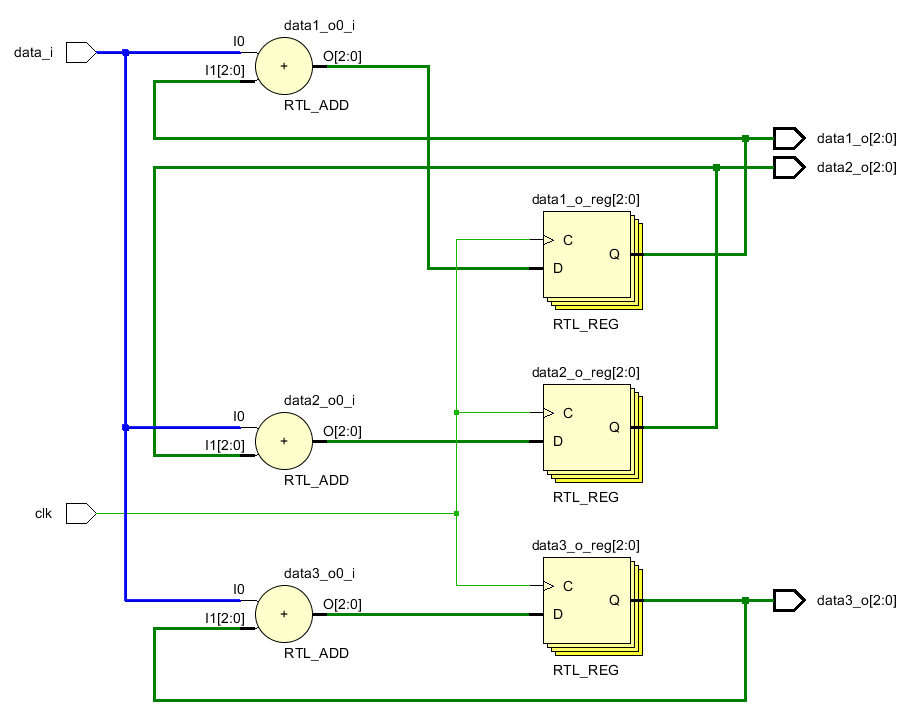
如果我們復制輸入數(shù)據(jù),如下圖,從中可以看出輸入信號復制了三份,分別接給三個加法器。
(* keep = "true" *)reg data_rp1;
(* keep = "true" *)reg data_rp2;
(* keep = "true" *)reg data_rp3;
always @(posedge clk)begin
data_rp1 <= data_i;
data_rp2 <= data_i;
data_rp3 <= data_i;
data1_o <= data_rp1 + data1_o;
data2_o <= data_rp2 + data2_o;
data3_o <= data_rp3 + data3_o;
end
4. URAM和BRAM使用
Xilinx器件中BRAM的大小是36Kbit,如果不使用校驗位,可以配置成1-32bit位寬的存儲。比如32x1K。在RTL代碼中使用存儲的時候,需要適配BRAM大小,這樣可以不浪費BRAM存儲空間。比如你需要使用一個FIFO,那么這個FIFO位寬32bit,那么它的深度512和1024配置,都消耗了一個BRAM。
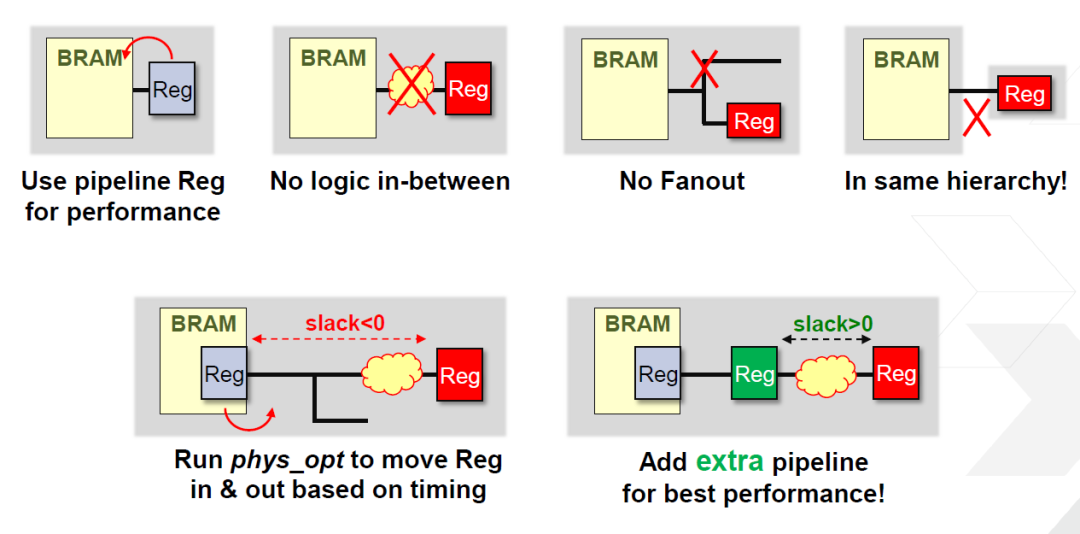
BRAM輸出中最好用register,不要直接接組合邏輯,這樣會增加延時。BRAM中含有register,如果代碼中輸出有用到register,那么這個register在綜合時會被移到BRAM內(nèi)部。如果BRAM外要連接組合邏輯,最好在BRAM的register的外部在添加一個register,這樣有更好的時序。
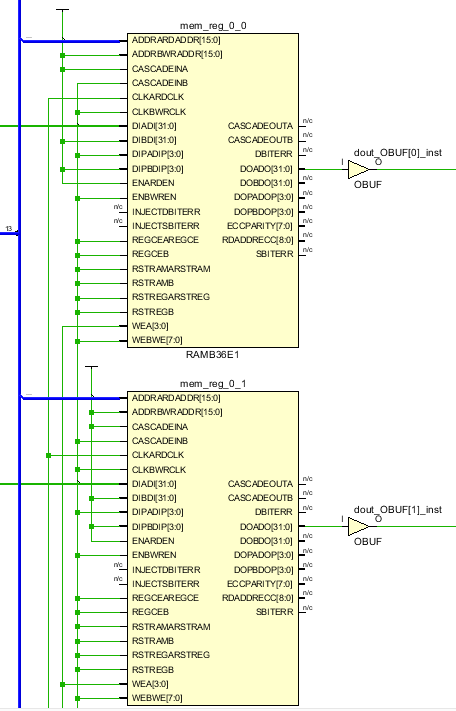
當我們需要的存儲空間和位寬都超過了一個BRAM的時候,就涉及到多個BRAM的級聯(lián)問題。如何選擇單個BRAM的位寬拼接和級聯(lián)BRAM的個數(shù)呢?比如我們要一個32bit位寬,深度為2**15大小的存儲。有兩種極限方式來配置BRAM。一種是將每個BRAM配置為1x32K,那么32個拼接組成32x32K的存儲。另外一種是將每個BRAM設置為32x1K,那么32個級聯(lián)形成32K深度。前一種不需要多余邏輯來對不同BRAM進行選擇操作,但是32個BRAM同時讀寫,這樣會增加power。而后一種32個BRAM級聯(lián)在一起造成延時路徑較長,同時需要增加組合邏輯來選擇不同BRAM。但是每次只讀寫一個BRAM,power較低。可以選擇這兩個極限的中間值來即降低power也不會有太長的邏輯延時。可以通過約束條件來進行設置。如下圖。級聯(lián)設置為4,這樣每次只有8個BRAM同時使能。
(* ram_style = "block", cascade_height = 4 *) reg [31:0] mem[2**15-1:0]; reg [14:0] addr_reg; always @(posedge clk)begin addr_reg <= addr; dout <= mem[addr_reg]; if(we) mem[addr_reg] <= din; end
URAM的使用方式類似,只不過URAM存儲空間比BRAM大,其可以配置為72x64K大小。
5. 其它
1) 進行條件判定的時候,如果條件過多,盡量減少if-else語句的使用,盡可能用case替代。因為if-else是有優(yōu)先級的,而case條件判斷的平等的。前者會用掉更多邏輯;
2) 在一個always塊中盡量對一個信號賦值,不要對具有不同判斷條件的信號同時賦值,這樣可以減少不必要的邏輯;
3) 盡量使用時鐘同步復位,不要使用異步復位。即要用:
always @(posedge clk)begin
If(rst)
End
而不是
always @(posedge clk or posedge rst)
4) 在使用乘法較多的時候,使用DSP原語是最好的。一個DSP除了有乘法功能外,還有前加法器和后加法器,這兩個是經(jīng)常用到的,可以用來計算很多功能。DSP的具體使用可以參考DSP的手冊。
總結
以上總結了幾點在進行RTL代碼設計時,最需要考慮的幾種情況。這些對時序影響很大,需要注意。另外從整體來講,如何選擇一個好的算法,然后設計出一個簡潔的架構更加重要。因為這些是從整體讓你的設計有更多靈活的空間。
審核編輯:劉清
-
寄存器
+關注
關注
31文章
5336瀏覽量
120232 -
計數(shù)器
+關注
關注
32文章
2256瀏覽量
94478 -
LUT
+關注
關注
0文章
49瀏覽量
12502 -
時序收斂
+關注
關注
0文章
14瀏覽量
7602 -
Verilog語言
+關注
關注
0文章
113瀏覽量
8224
原文標題:如何寫出時序收斂的代碼
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦
進行RTL代碼設計需要考慮時序收斂的問題
UltraFast設計方法時序收斂快捷參考指南

如何在IAR Embedded Workbench中配置生成對應代碼區(qū)域的CRC校驗碼
記錄一次時序收斂的過程

FPGA時序收斂學習報告
基于MCMM技術IC時序收斂的快速實現(xiàn)

從已布線設計中提取模塊用于評估時序收斂就緒狀態(tài)
嘮一嘮解決FPGA約束中時序不收斂的問題
UltraFast設計方法時序收斂快捷參考指南(UG1292)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論