

作為后摩爾時代發(fā)展的必然趨勢之一,存算一體越來越受到行業(yè)的關(guān)注。在存算十問的前六問中,我們梳理了存算一體的技術(shù)路線、挑戰(zhàn)和通用性等問題,這一次我們從技術(shù)的壁壘入手,邀請后摩智能的幾位研發(fā)人員來談?wù)劊瑥膶W(xué)術(shù)到商用,存算一體的技術(shù)壁壘體現(xiàn)在哪里,后摩智能又是如何從IP、電路設(shè)計、架構(gòu)設(shè)計等層面突破技術(shù)難題,形成自己獨有的技術(shù)壁壘。
Q1存算一體芯片是一個壁壘比較高的技術(shù)方向嗎?它的壁壘體現(xiàn)在哪些方面?
存算一體芯片是技術(shù)壁壘很高的一個方向。從芯片底層到軟件劃分的話,主要體現(xiàn)在以下幾個方面:
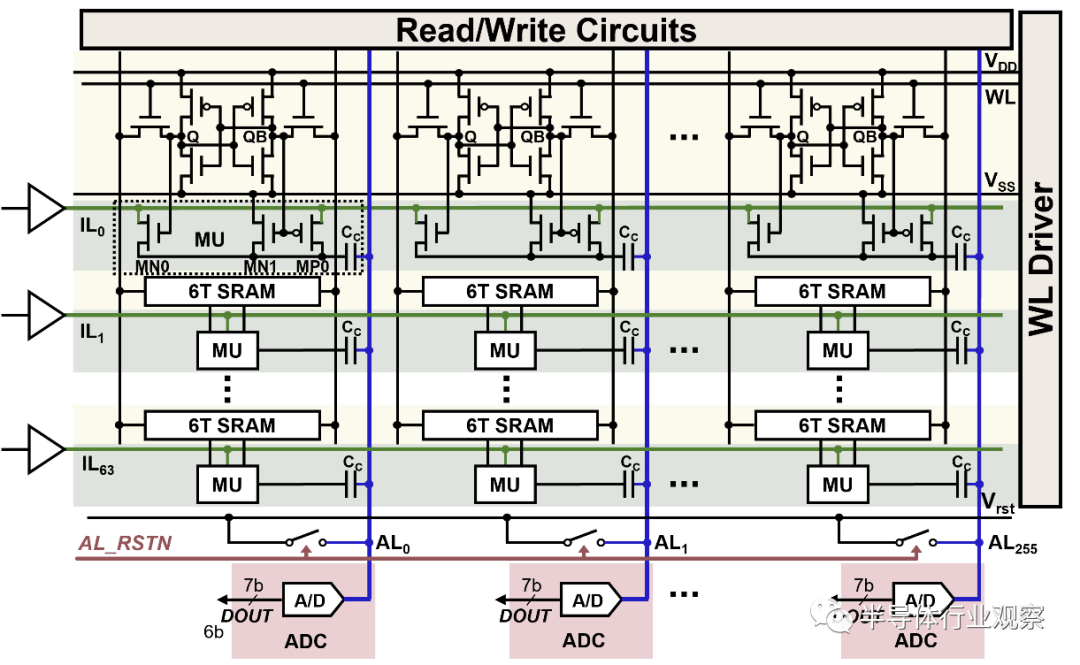
(1)CIM的基本運算單元(即MACRO)的設(shè)計是第一個難點。作為存算一體芯片的基石,存內(nèi)計算IP的功能和性能直接影響存算一體芯片的整體表現(xiàn)。存內(nèi)計算IP依托的存儲介質(zhì)和所采用的計算范式繁多且呈“百花齊放”。
以SRAM CIM MACRO為例,因為需要修改存儲陣列以加入計算的邏輯單元、支持“存儲-計算”雙工作模 式,并且在滿足計算性能的同時還需要保證陣列的規(guī)整性來優(yōu)化面積效率、保證陣列的可靠性、可測試性等。需要SRAM專家針對性的進(jìn)行設(shè)計。值得強調(diào)的是,當(dāng)前的EDA工具不支持設(shè)計流程,必須自主設(shè)計相應(yīng)的EDA工具來配合整個過程,包括margin, aging, EMIR, PPA的分析、Sign-off、PI/S等工具。
(2)當(dāng)完成CIM MACRO設(shè)計后,需要將大量的MACRO高效的組織在一起來處理形式多樣的Tensor運算,同時配合一定的通用算力來滿足各種長尾算子(通常指計算量較小的非Tensor算子)的處理能力。這里涉及到多個MACRO之間的數(shù)據(jù)流組織方式,即如何將一個Tensor的運算分配到多個MACRO協(xié)同處理,完成這個目標(biāo)需要精心進(jìn)行架構(gòu)設(shè)計,并且通常需要一個高效的片上網(wǎng)絡(luò)(NoC)來支持。
另外,通常需要在芯片內(nèi)配置大容量的SRAM來減少片外DRAM的訪存需求,如何組織SRAM,并且配合上述計算流程,也是一個重要的設(shè)計內(nèi)容。
(3)存算一體AI核和SoC的架構(gòu)設(shè)計和實現(xiàn):存內(nèi)計算IP提供了高能效的并行計算模式,但同樣受限于其支持運算類型的局限性,因而對于存算一體AI核和SoC的架構(gòu)設(shè)計的難度和復(fù)雜度要求急劇上升,既要充分利用存內(nèi)計算IP本身運算的高效性,又要減少存內(nèi)計算IP之間的數(shù)據(jù)傳輸,同時還要兼顧支持網(wǎng)絡(luò)算子的通用性和物理實現(xiàn)的可行性。
(4)存算一體軟件編譯器的快速部署和實現(xiàn):軟件工具鏈對于發(fā)揮存算芯片的效率也至關(guān)重要。軟件需要將模型切分成合適的Tensor算子,然后生成相應(yīng)的指令調(diào)用底層硬件來處理。
在后端算子性能優(yōu)化時,需要打破算子的邊界,要解決層間流水,多模型流水并行,結(jié)合存算架構(gòu)的特點完成優(yōu)化。業(yè)界有很多開源框架的 IR 可以參考,像 MLIR 和 TVM 的 Relay 和 TIR,這些開源的 IR 無法很好地處理上述優(yōu)化需求,我們根據(jù)存算架構(gòu) AI Core 的特點,設(shè)計了一層 IR ,更好地解決了數(shù)據(jù)流分析、數(shù)據(jù)依賴分析,可以更方便地進(jìn)行層間調(diào)度和切分等優(yōu)化。
同時,對于自動駕駛等場景,通過算子融合來提升計算和訪存效率是非常關(guān)鍵的一個優(yōu)化目標(biāo),需要工具鏈自動化的完成算子的融合、調(diào)度及對大容量SRAM的高效管理,以同時提升芯片的利用率和應(yīng)用的開發(fā)效率等。
Q2相較于傳統(tǒng)的芯片電路設(shè)計,后摩智能的存算電路架構(gòu)設(shè)計和電路設(shè)計有何特殊性和優(yōu)點?
(1)電路方面:自主設(shè)計的定制CIM MACRO,包括定制的乘法單元、加法樹、讀寫電路、累加器等,進(jìn)一步拉近計算和存儲的距離顯著提升性能和能效,通過SRAM單元替代寄存器實現(xiàn)更高的計算密度、更低的讀寫功耗。相比傳統(tǒng)電路設(shè)計面效提升2倍左右、能效提升一個量級左右;
(2)架構(gòu):層次化的架構(gòu)設(shè)計,將大量MACRO有效組織在一起;CIM MACRO負(fù)責(zé)Tensor計算,自主設(shè)計的RISC-V Vector擴展架構(gòu)配合定制的SFU負(fù)責(zé)長尾算子處理,同時滿足處理效率和通用性的需求;定制化的NoC,滿足多個MACRO和SRAM之間的數(shù)據(jù)通信需求等
后摩智能的存算電路主要采用了基于全數(shù)字域的存算路徑,通過對存儲單元和計算單元的深度定制來實現(xiàn)高能效的計算目的,從而減少訪存開銷,打破存儲墻瓶頸,這種從SPEC到signoff的全定制化流程研發(fā)周期長,且對于研發(fā)迭代效率要求極高。
同時,還需要兼顧大規(guī)模量產(chǎn)和車規(guī)需求,開發(fā)特有的CIM BIST和硬件修復(fù)電路,保障芯片良率和車規(guī)認(rèn)證。
Q3后摩智能自研的芯片IPU架構(gòu),從一代到二代的天樞、天璣,相對于傳統(tǒng)架構(gòu)的優(yōu)點和創(chuàng)新之處是什么?

這張圖就是我們已經(jīng)推出的H30芯片天樞架構(gòu)IPU圖。
我們的芯片里有4個IPU核,都掛在系統(tǒng)總線NoC上。這4個核是完全一樣的設(shè)計。對于每一個Core,又由4個Tile組成,每個Tile就對應(yīng)了一個硬件線程,它們可以獨立進(jìn)行不同的計算,也可以聯(lián)合起來做同一個計算。
每個Tile內(nèi)部有CPU、Tensor Engine,Special Function Unit,Vector Processor和多通道DMA,這些計算單元可以直接共享一個多Bank的共享存儲資源。這樣的架構(gòu)使得AI計算不但不用在多個處理器,例如CPU,GPU,DSP之間分配任務(wù),甚至數(shù)據(jù)不用出AI核,就可以高效的完成全部端到端的AI計算。
這個架構(gòu)里還有一個重要的部分就是數(shù)據(jù)的傳輸。就像我們?nèi)撕腿酥g需要更好的溝通一樣,我們的計算單元之間,也需要很好的共享數(shù)據(jù)和消息。
我們設(shè)計了專用的數(shù)據(jù)傳輸總線,可以靈活的在各個Tile,以及各個Core之間建立高速的直接的數(shù)據(jù)傳輸通道,而不需要通過系統(tǒng)總線和緩存。
CIM macro有計算形式單一、需求輸入數(shù)據(jù)整齊、沒有累加器等缺點。第一代天樞架構(gòu)為這些功能上的缺點做了相應(yīng)的補充,使得CIM macro能夠真正的應(yīng)用在大規(guī)模AI計算中,而不只停留在paper上;另一方面,將CIM macro用于工程上,有BIST,yield,PI/SI等問題需要摸索解決,第一代架構(gòu)也在這方面做了規(guī)劃和適配。
我們下一代的天璇架構(gòu)IPU設(shè)計理念將會是:基于Mesh互聯(lián)的AI cluster。采用Mesh的互聯(lián)結(jié)構(gòu),可以將計算單元的數(shù)量靈活的配置成M行N列,根據(jù)場景需求,AI算力規(guī)模可大可小。
審核編輯:湯梓紅
-
芯片
+關(guān)注
關(guān)注
459文章
51883瀏覽量
433099 -
sram
+關(guān)注
關(guān)注
6文章
778瀏覽量
115499 -
AI
+關(guān)注
關(guān)注
87文章
33411瀏覽量
273936 -
存算一體
+關(guān)注
關(guān)注
0文章
106瀏覽量
4548
發(fā)布評論請先 登錄
相關(guān)推薦
存算一體大算力AI芯片將逐漸走向落地應(yīng)用
比存算一體更進(jìn)一步,“感存算一體化”前景如何?
存算一體技術(shù)路線如何選

知存科技數(shù)模混合存算一體AI芯片專利解析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論