 Elasticsearch存在的各種漏洞問題
Elasticsearch存在的各種漏洞問題
elasticsearch 8
之前使用的一個老系統使用了elasticsearch7.x版本,之后又反應es版本存在各種漏洞
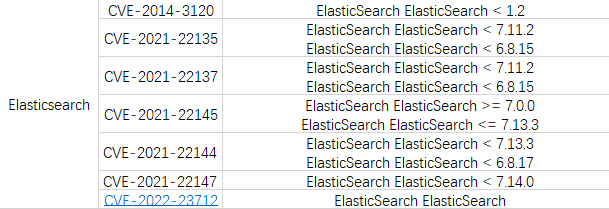
無奈只能做版本升級來解決問題,計劃是將版本升級到8.x,在網上了解了下兩個版本的區別,主要包括以下變化:
- Rest API相比較7.x而言做了比較大的改動(比如徹底刪除_type),為了降低用戶的升級成本,8.x會暫時的兼容7.x的請求。
- 默認開啟安全配置(三層安全),并極大簡化了開啟安全需要的工作量,可以這么說:7.x開啟安全需要10步復雜的步驟比如CA、證書簽發、yml添加多個配置等等,8.x只需要一步即可)。
- 存儲空間優化:更新了倒排索引,對倒排文件使用新的編碼集,對于keyword、match_only_text、text類型字段有效,有3.5%的空間優化提升,對于新建索引和segment自動生效。
- 優化geo_point,geo_shape類型的索引(寫入)效率:15%的提升。
- 新特性:支持上傳pyTorch模型,在ingest的時候使用。比如在寫入電影評論的時候,如果我們想要知道這個評論的感情正負得分,可以使用對應的AI感情模型對評論進行運算,將結果一并保存在ES中。
- 技術預覽版KNN API發布,(K鄰近算法),跟推薦系統、自然語言排名相關。之前的KNN是精確搜索,在大數據集合的情況會比較慢,新的KNN提供近似KNN搜索,以提高速度。
- 對ES內置索引的保護加強了:elastic用戶默認只能讀,如果需要寫權限的時候,需有allow_restrict_access權限。
那么在基于spring-boot的開發時,我們大概需要做些對應的調整了,要包括以下幾點:
- spring-data-elasticsearch版本升級
- 客戶端依賴由elasticsearch-rest-high-level-client調整為elasticsearch-java
- JDK版本升級到17
借著這個機會,重溫下es相關的知識……
創建索引
- 基于Elasticsearch Rest API
PUT localhost:9200/index_novel
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": { "ignore_above": 256, "type": "keyword" }
}
},
"author": { "type": "keyword" },
"category": { "type": "keyword" },
"type": { "type": "keyword" },
"description": { "analyzer": "ik_max_word", "type": "text" },
"content": { "analyzer": "ik_max_word", "type": "text" },
"coverUrl": { "type": "text" },
"insertTime": { "format": "date_time", "type": "date" },
"updateTime": { "format": "date_time", "type": "date" },
"status": { "type": "keyword" }
}
}
}
- 基于SpringBoot創建
- 定義Novel實體
@Data
@Document(indexName = "index_novel")
public class Novel {
}
- 定義Repository
public interface NovelDao extends ElasticsearchDao< Novel, String > { }
- 啟用Elasticsearch Repositories支持
@EnableElasticsearchRepositories
4主要實現在SimpleElasticsearchRepository中:
public SimpleElasticsearchRepository(ElasticsearchEntityInformation< T, ID > metadata,
ElasticsearchOperations operations) {
this.operations = operations;
Assert.notNull(metadata, "ElasticsearchEntityInformation must not be null!");
this.entityInformation = metadata;
this.entityClass = this.entityInformation.getJavaType();
this.indexOperations = operations.indexOps(this.entityClass);
if (shouldCreateIndexAndMapping() && !indexOperations.exists()) {
indexOperations.createWithMapping();
}
}
字段類型
Elasticsearch 支持多種字段類型,每種類型都有其獨特的作用和功能。其中常見的字段類型包括:
- Text:用于存儲文本內容,支持全文搜索、模糊搜索、正則表達式搜索等功能。
- Keyword:用于存儲關鍵詞,支持精確匹配和聚合操作。
- Date:用于存儲日期時間類型的數據,支持日期范圍查詢、日期格式化等功能。
- Numeric:用于存儲數值類型的數據,支持數值范圍查詢、聚合操作等功能。
- Boolean:用于存儲布爾類型的數據,支持精確匹配和聚合操作。
- Geo-point:用于存儲地理位置信息,支持距離計算、地理位置聚合等功能。
- Object:用于存儲復雜的結構化數據,支持嵌套查詢、嵌套聚合等功能。
text
Es中的text類型是一種用于處理長文本的數據類型,適合于全文搜索和分析。當將文本字段映射為text類型時,文本會被分析器分詞處理成一個個單詞, 然后被存儲在倒排索引中,以便后續進行全文搜索。text類型支持多種分析器和過濾器,可以對不同的文本進行不同的分詞處理,以達到最佳的搜索效果。此外, text類型還支持詞項位置信息和偏移量信息的存儲,以便進行精確的搜索和高亮顯示。
keyword
ES把keyword類型的值作為一整體存在倒排索引中,不進行分詞。 keyword適合存結構化數據,如性別、手機號、數據狀態、標簽HttpCode(404,200,500)等。 字段常用來精確查詢、過濾、排序、聚合時,應設為keyword,而不是數值型。 如果某個字段你經常用來做range查詢, 你還是設置為數值型(integer,long),ES對數字的range有優化。 還可以把字段設為multi-field,這樣又有keyword類型又有數值類型,方便多種方式的使用。 最長支持32766個UTF-8類型的字符,但放入倒排索引時,只截取前一段字符串,長度由ignore_above參數決定,默認"ignore_above" : 256。
Auto
在spring中,支持一種auto的數據類型,通過在字段上添加注解實現@Field(type = FieldType.Auto),Auto申明的類型除了生成一個text類型字段外,還會多一個.keyword的keyword類型的字段。
@Field(type = FieldType.Auto)
private String title;
上面對應的mapping:
{
"title": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
fields可以讓同一文本有多種不同的索引方式,比如上面text類型的字段title,可以使用text類型做全文檢索,使用keyword類型做聚合和排序。
通過這種方式,可以實現一個字段運用于不同的場景。要知道字段類型的使用場景是受限的。在mapping中通過添加fields的擴展字段, 讓一個字段擁有多個子字段類型,使得一個字段能夠被多個不同的索引方式進行索引。
查詢
以下是 Elasticsearch 中所有的查詢類型:
Match Query:用于匹配文本類型字段中的文本。
Multi-match Query:用于在多個字段中匹配文本類型字段中的文本。
Term Query:用于匹配非文本類型字段(如數字、布爾值等)中的確切值。
Terms Query:用于匹配非文本類型字段(如數字、布爾值等)中的多個確切值。
Range Query:用于匹配數字、日期等范圍內的值。
Exists Query:用于匹配指定字段是否存在值。
Prefix Query:用于匹配以指定前綴開頭的文本。
Wildcard Query:用于匹配包含通配符的文本。
Regexp Query:用于使用正則表達式匹配文本。
Fuzzy Query:用于匹配類似但不完全匹配的文本。
Type Query:用于匹配指定類型的文檔。
Ids Query:用于根據指定的文檔 ID 匹配文檔。
Bool Query:用于組合多個查詢條件,支持AND、OR、NOT等邏輯操作。
Boosting Query:用于根據指定的查詢條件調整文檔的權重。
Constant Score Query:用于為所有匹配的文檔分配相同的分數。
Function Score Query:用于根據指定的函數為匹配的文檔分配自定義分數。
Dis Max Query:用于在多個查詢條件中選擇最佳匹配的文檔。
More Like This Query:用于根據文檔內容查找相似的文檔。
Nested Query:用于在嵌套對象中查詢。
Geo Distance Query:用于查詢地理坐標范圍內的地點。
Span Term Query:用于匹配指定的單個術語。
Span Multi Term Query:用于匹配指定的多個術語。
Span First Query:用于匹配文檔中的首個匹配項。
Span Near Query:用于匹配多個術語之間的近似距離。
Span Or Query:用于匹配任何指定的術語。
Span Not Query:用于匹配不包含指定術語的文檔。
Script Query:用于根據指定的腳本匹配文檔。
下面看下一些常用的簡單查詢,后面的復合查詢以及聚合查詢都是基于這些簡單查詢來組合嵌套來實現。
URL : POST localhost:9200/index_novel/_search
match
根據關鍵字對某個字段進行檢索,當然傳入的參數會先進行分詞,然后進行匹配
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"match": {
"title": {
"query": "天下",
"minimum_should_match": "30%"
}
}
}
}
match_phrase
詞項匹配(查詢分詞的詞項必須完全匹配到索引分詞的詞項中,并且詞項的相對位置position必須一致),分詞后的相對位置也必須要精準匹配(slop)
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"match_phrase": {
"title" : {"query": "天下", "slop": "1"}
}
}
}
term
根據詞條完全匹配,也就是精確查詢,搜索前不會對搜索詞進行分詞解析,直接對搜索詞進行查找;
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"term": { "author": "淚冠哀歌" }
}
}
復合查詢
bool
query和filter兩種不同的Context
- query context:相關性算分
- filter context:不需要算分 ( yes or no ),可以緩存cache,性能更高
bool一共支持4中查詢,每一種子查詢都可以嵌套多個簡單查詢
- must 必須匹配某些條件才可以返回,計算分值
- must_not 必須不匹配某些條件,不計算分值
- should 當滿足此條件時,計算分值
- filter 必須匹配,不會計算分值
{
"query":{
"bool":{
"filter":{
"term":{ "title":"遮天" }
},
"should":[
{
"match": { "title":"遮天" }
}
],
"must":[
{
"match":{ "title":"遮天" }
}
]
}
}
}
constant_score
查詢返回的相似度分與字段上指定boost參數值相同的數據
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"constant_score": {
"filter": {
"term": {
"description": "天下"
}
},
"boost": 1
}
}
}
dis_max
最大析取(disjunction max) 返回的文檔必須要滿足多個查詢子句中的一項條件; 若一個文檔能匹配多個查詢子句時,則dis_max查詢將為能匹配上查詢子句條件的項增加額外分,即針對多個子句文檔有一項滿足就針對滿足的那一項分配更高分, 這也能打破在多個文檔都匹配某一個或多個條件時分數相同的情況;
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"dis_max": {
"tie_breaker": 0.7,
"queries": [
{
"term": {
"description": "天下"
}
}
]
}
}
}
聚合查詢
聚合(aggregations)可以讓我們極其方便的實現對數據的統計、分析、運算。例如:
語法:
{
"aggs": {
"自定義聚合名稱": {
"聚合類型": {
"聚合參數": "參數值"
}
}
}
}
- 聚合類型
- Terms(詞條聚合):按照字段值進行分組,統計每個分組的文檔數量。
- Sum(求和聚合):計算指定字段的總和。
- Avg(平均值聚合):計算指定字段的平均值。
- Min(最小值聚合):找出指定字段的最小值。
- Max(最大值聚合):找出指定字段的最大值。
- Stats(統計聚合):計算指定字段的統計信息,包括最小值、最大值、總和、平均值和文檔數量。
- Extended Stats(擴展統計聚合):計算指定字段的擴展統計信息,包括最小值、最大值、總和、平均值、標準差和文檔數量。
- Cardinality(基數聚合):計算指定字段的唯一值數量。
- Date Histogram(日期直方圖聚合):按照時間間隔對日期字段進行分組。
- Range(范圍聚合):將文檔按照指定范圍進行分組,例如按照價格范圍、年齡范圍等。
- Nested(嵌套聚合):在嵌套字段上執行子聚合操作。
- 聚合參數
- field(字段):指定要聚合的字段。
- size(大小):限制返回的聚合桶的數量。
- script(腳本):使用腳本定義聚合邏輯。
- min_doc_count(最小文檔數量):指定聚合桶中文檔的最小數量要求。
- order(排序):按照指定字段對聚合桶進行排序。
- include/exclude(包含/排除):根據指定的條件包含或排除聚合桶。
- format(格式):對聚合結果進行格式化。
- precision_threshold(精度閾值):用于基數聚合的精度控制。
- interval(間隔):用于日期直方圖聚合的時間間隔設置。
- range(范圍):用于范圍聚合的范圍定義。
分頁
- from-size
- 查詢優點
- 支持隨機翻頁
- 查詢缺點
- 受制于 max_result_window 設置,不能無限制翻頁。
- 存在深度翻頁問題,越往后翻頁越慢。
- From + size 查詢適用場景
- 第一:非常適合小型數據集或者大數據集返回 Top N(N <= 10000)結果集的業務場景。
- 第二:類似主流 PC 搜索引擎(谷歌、bing、百度、360、sogou等)支持隨機跳轉分頁的業務場景。
- search_after
- search_after 優點
- 不嚴格受制于 max_result_window,可以無限制往后翻頁。 ps:不嚴格含義:單次請求值不能超過 max_result_window;但總翻頁結果集可以超過。
- search_after 缺點
- 只支持向后翻頁,不支持隨機翻頁。
- search_after 適用場景
- 類似:今日頭條分頁搜索 https://m.toutiao.com/search 不支持隨機翻頁,更適合手機端應用的場景。
- scroll
- scroll 查詢優點
- 支持全量遍歷。 ps:單次遍歷的 size 值也不能超過 max_result_window 大小。
- scroll 查詢缺點
- 響應時間非實時。
- 保留上下文需要足夠的堆內存空間。
- scroll 查詢適用場景
- 全量或數據量很大時遍歷結果數據,而非分頁查詢。
- 官方文檔強調:不再建議使用scroll API進行深度分頁。如果要分頁檢索超過 Top 10,000+ 結果時,推薦使用:PIT + search_after。
排序
和關系型數據庫一樣,對關鍵屬性進行升序或降序返回數據。但是要注意,字段不能是text類型
{
"sort": {
"insertTime": { "order": "desc" }
}
}
高亮
我們可能有這樣的需求,在檢索結果中,將檢索關鍵詞進行高亮展示,就像百度搜索的結果,標題和描述中都標記為紅色了,elasticsearch同樣支持這樣的查詢, 返回的高亮內容主要是通過`'元素包裹,當然可以通過配置修改。需要注意的是,設置的高亮字段需要和檢索字段匹配。
{
"highlight": {
"pre_tags": [
""
],
"post_tags": [
""
],
"fields": {
"description": {
"fragment_size": 100,
"number_of_fragments": 5
}
}
}
}
集成
Elasticsearch與SpringBoot的集成非常簡單:
- 引入依賴
< dependency >
< groupId >org.springframework.boot< /groupId >
< artifactId >spring-boot-starter-web< /artifactId >
< /dependency >
< dependency >
< groupId >org.springframework.boot< /groupId >
< artifactId >spring-boot-starter-data-elasticsearch< /artifactId >
< /dependency >
- 編寫文檔對應實體,申明索引信息
通過@org.springframework.data.elasticsearch.annotations.Document注解可以定定義索引信息,比如是否在系統啟動后自動創建
通過@org.springframework.data.elasticsearch.annotations.Field定義各個字段類型等信息
@Data
@Document(indexName = "index_novel")
public class Novel {
// 省略 ...
@Field(type = FieldType.Auto)
private String title;
@Field(type = FieldType.Keyword)
private String author;
@Field(type = FieldType.Keyword)
private String type;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String description;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String content;
// 省略...
}
- 定義DAO抽象接口與代理實現
通過自定義接口方便擴展,當ElasticsearchRepository中提供的方法無法支持時,可以根據業務需求自定義查詢方式
在BaseElasticsearchRepository中,可以基于ElasticsearchOperations自定義各種復雜查詢
public interface ElasticsearchDao< T, ID > extends ElasticsearchRepository< T, ID >{
}
public class BaseElasticsearchRepository< T,ID > extends SimpleElasticsearchRepository< T,ID > implements ElasticsearchDao< T,ID >{
private ElasticsearchEntityInformation entityInformation;
private ElasticsearchOperations elasticsearchOperations;
public BaseElasticsearchRepository(ElasticsearchEntityInformation metadata, ElasticsearchOperations operations) {
super(metadata, operations);
this.entityInformation = metadata;
this.elasticsearchOperations = operations;
}
}
public interface NovelDao extends ElasticsearchDao< Novel, String > {
}
- 啟用Repository并配置DAO的通用實現
@SpringBootApplication
@EnableElasticsearchRepositories(basePackages = "com.sucl.springbootelasticsearch8.dao", repositoryBaseClass = BaseElasticsearchRepository.class)
public class SpringbootElasticsearch8Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootElasticsearch8Application.class, args);
}
}
- 在Service層的使用
@Service
public class NovelService {
private NovelDao novelDao;
public NovelService(NovelDao novelDao) {
this.novelDao = novelDao;
}
}
基于SpringBoot對Elasticsearch的繼承整體比較簡單,由于ES的查詢種類非常多,在Spring中提供了與DSL QUERY對應的API可以使用,只不過沒法通過通用的SimpleElasticsearchRepository中實現。
示例
現在基于ES8做了一個簡單的示例,主要包括以下功能:
- 從起點小說網按類型加載小說到es
- 基于spring-boot-starter-data-elasticsearch實現小說句的檢索
- 起點小說數據加載到elasticsearch,主要實現方式是通過工具jsoup解析小說網站的,并按文檔結構組裝文檔數據,并調用es API將數據存儲到es中,大概有以下幾個過程
- 訪問起點小說網https://www.qidian.com/free/all/,根據傳入的分類與頁碼參數按頁獲取頁面html
- 解析上一步html,分別獲取每個小說目錄html片段,解析成一部小說文檔數據
- 按目錄分別加載每個章節頁面html,按章節分別加載章節小說內容,最后將所有內容拼接到小說文檔數據中
- 調用API將小說數據存儲到elasticsearch
- 篇幅有限,具體實現可以參考下面的github
- 小說查詢相關DAO可以參考上面的集成
略
- 添加service與controller
@Service
public class NovelService {
private NovelDao novelDao;
public NovelService(NovelDao novelDao) {
this.novelDao = novelDao;
}
/**
* 批量保存
* @param novels
* @return
*/
public List< Novel > saveNovels(List< Novel > novels) {
List< Novel > savedNovels = new ArrayList< >();
novels.forEach(this::configureNovel);
novelDao.saveAll(novels).forEach(savedNovels::add);
return savedNovels;
}
/**
* 根據關鍵字在指定字段值檢索
* @param keyword
* @param fields
* @return
*/
public List< Novel > searchNovels(String keyword, String[] fields) {
DslQuery dslQuery = DslQuery.of(DslQuery.Type.MULTI_MATCH, String.join(",",fields), keyword);
return novelDao.commonQuery(dslQuery, null);
}
/**
* 根據主鍵查詢單條數據,按指定字段查找相似數據
* @param novel
* @param fields
* @param pageable
* @return
*/
public Page< Novel > getPageSimilarNovel(Novel novel, String[] fields, Pager pager) {
return novelDao.searchSimilar(novel, fields, PageRequest.of(pager.getPageIndex(), pager.getPageSize()));
}
}
示例內容涉及到Elasticsearch DSL QUERY組裝過程以及上面說到的SimpleElasticsearchRepository不足以支撐業務查詢時的一些擴展方法。 示例使用了起點小說網站加載小說數據,其他網站實現思路一樣。由于篇幅原因,具體代碼實現可以參考:
https://github.com/sucls/springboot-elasticsearch-8
結束語
Elasticsearch版本有7.x升級到8.x時,不僅僅是客戶端的變更,運行環境也有較大的改變,Spring版本也做了大版本升級。最后在項目里僅僅是修改了客戶端用來匹配與es服務交互時,保證請求響應的過程沒有問題。
-
存儲
+關注
關注
13文章
4298瀏覽量
85811 -
模型
+關注
關注
1文章
3229瀏覽量
48813 -
漏洞
+關注
關注
0文章
204瀏覽量
15368 -
自然語言
+關注
關注
1文章
288瀏覽量
13347 -
Elasticsearch
+關注
關注
0文章
28瀏覽量
2827
發布評論請先 登錄
相關推薦
linux安裝配置ElasticSearch之源碼安裝
PCB設計中存在的漏洞有哪些?
ElasticSearch是什么?應用場景是什么?
MySQL數據如何同步Elasticsearch
Elasticsearch保姆級入門
SpringBoot 連接ElasticSearch的使用方式
Python 更新 Elasticsearch 的幾種方法






 工商網監
工商網監
評論